一般情况下,我们都认为逻辑回归(LR)用来解决二分类问题,模型输出是y=1的概率值。那逻辑回归能否用来做多分类任务呢,答案是肯定的。
这里有两种方法使得逻辑回归能进行多分类任务:
一、将多分类任务拆解成多个二分类任务,利用逻辑回归分类器进行投票求解;
二、对传统的逻辑回归模型进行改造,使之变为softmax回归模型进行多分类任务求解
-- 多分类任务拆解成多个二分类器
首先了解下进行多分类学习任务的策略,第一种策略是直接采用支持多分类的模型,例如K近邻分类器、决策树等,第二种策略则是利用多个二分类学习期来解决多分类问题。第一种策略中的多分类模型后面会逐一详细介绍,这里重点介绍下第二种策略。
第二种策略的基本思路是“拆解”,将多分类任务拆为多个二分类任务求解,一般有3种拆分策略:
(1)OvO(一对一,One vs One):假如数据D中有N个类别,将N个类别进行两两配对,产生N(N-1)/2 个二分类器,在预测中,将测试样本输入这N(N-1)/2 个二分类器中得到相应个数的预测结果,然后再将被预测结果数最多的(Voting)作为最终分类结果。
下图是一个简单的例子,数据集中有4种类别,两两配对可以产生6个二分类器,将测试样本输入分类器中可得到6个预测结果,通过投票取最多的预测结果类别1作为最后的预测结果。

(2)OvR(一对其余,One vs Rest): 将一个类别作为正例,其余所有类别作为反例,这样N个类别可以产生N个二分类器,将测试样本输入这些二分类器中中得到N个预测结果,如果仅有一个分类器预测为正类,则将对应的预测结果作为最终预测结果。如果有多个分类器预测为正类,则选择置信度最大的类别作为最终分类结果。
下图所示,数据集中共4个类别,产生4个二分类器,类别2对应的分类器2预测结果为正例,则最终预测结果为类别2。

(3)MvM(多对多,Many vs Many):将数据集中的若干个类作为正例,若干个其他类作为反例。MvM的正、反类构造必须有特殊的设计,而不是随意选取,通常采用“纠错输出码(ECOC)”,产生编码矩阵后划分类别。
编码:将N个类做M次划分,每次划分一些是正类,一些是负类。共产生M个二分类器。
解码:M个分类器对新样本测试,其结果组成一个编码,与各个类别的编码比较,返回距离最小的类别为最终结果。
编解码的详细过程可参考周志华的西瓜书。
了解了多分类任务拆分为多个二分类问题的算法原理后,利用sklearn的鸢尾花数据集验证一下,该数据集有4个特征属性,3种分类{'setosa', 'versicolor', 'virginica'},我利用OvR和MvM两种策略进行多分类的学习及预测:
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.multiclass import OneVsRestClassifier
from sklearn.multiclass import OneVsOneClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
data_iris = datasets.load_iris()
x, y = data_iris.data, data_iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3,random_state = 0)
# 使用multiclass的OvO多分类策略,分类器使用LogisticRegression
model = OneVsOneClassifier(LogisticRegression(C=1.0, tol=1e-6))
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(accuracy_score(y_test, y_pred))
============================================
0.9555555555555556
# 使用multiclass的OvR多分类策略,分类器使用LogisticRegression
model = OneVsRestClassifier(LogisticRegression(C=1.0, tol=1e-6))
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(accuracy_score(y_test, y_pred))
============================================
0.8888888888888888
从验证结果上来看,OvO策略和OvR策略类似,在大多数情况分类效果差不多(小数据量和少类别的情况下可能OvO效果更好),OvO训练的分类器数目比OvR多,所以OvO的存储开销和训练时间通常比OvR更大,但由于训练时,OvR的每个分类器需要用到所有训练样例,而OvO的每个分类器只用到两个类别的样例,所以在大数据集和类别较多的情况下,OvO的训练时间开销比OvR更小。
-- softmax回归
softmax回归其实是逻辑回归的一种变形,逻辑回归模型输出的是两种类别的概率,softmax回归输出的K种类别的概率。模型公式如下:
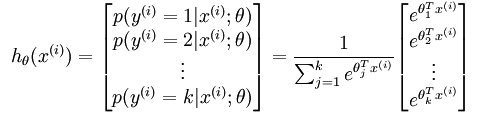
参数θ是一个矩阵,矩阵的每一行可以看做是一个类别所对应分类器的参数,总共有k行,输出的K个数就表示该类别的概率,总和为1。这样,softmax回归模型对于一个测试样本,可以得到多个类别对应的概率值,模型选取概率最高的类别作为最终判定结果。
在sklearn中使用softmax回归还是调用linear.model.LogisticRegression,设置一下multi_class参数即可,内部即会使用softmax函数计算出每个类别的概率。
# 采用softmax回归进行分类
model = LogisticRegression(C=1.0, tol=1e-6, multi_class='multinomial', solver='newton-cg')
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(accuracy_score(y_test, y_pred))
====================================
0.9777777777777777
输出每个测试样例的类别预测概率
print (model.predict_proba(x_test))-- 多个二分类器策略和softmax回归的区别
softmax回归中对一个测试样本得到的属于各类别的概率和一定为1,而多个二分类器策略中,不管是OvO、OvR还是MvM策略,一个样本在多个二分类器上得到的概率和不一定为1。因此当分类之间是互斥的情况下(e.g 数字手写识别、动物识别),通常采用softmax回归;而目标类别不是互斥时(e.g 华语音乐、流行音乐、重金属音乐等)则采用多个二分类器策略进行预测。
作者:华为云专家周捷