摘要:脏数据对数据计算的正确性带来了很严重的影响。因此,我们需要探索一种方法,能够实现Spark写入Elasticsearch数据的可靠性与正确性。
概述
Spark与Elasticsearch(es)的结合,是近年来大数据解决方案很火热的一个话题。一个是出色的分布式计算引擎,另一个是出色的搜索引擎。近年来,越来越多的成熟方案落地到行业产品中,包括我们耳熟能详的Spark+ES+HBase日志分析平台。
目前,华为云数据湖探索(DLI)服务已全面支持Spark/Flink跨源访问Elasticsearch。而之前在实现过程中也遇到过很多场景化问题,本文将挑选其中比较经典的分布式一致性问题进行探讨。
分布式一致性问题
问题描述
数据容错是大数据计算引擎面临的主要问题之一。目前,主流的开源大数据比如Apache Spark和Apache Flink已经完全实现了Exactly Once语义,保证了内部数据处理的正确性。但是在将计算结果写入到外部数据源时,因为外部数据源架构与访问方式的多样性,始终没能找到一个统一的解决方案来保证一致性(我们称为Sink算子一致性问题)。再加上es本身没有事务处理的能力,因此如何保证写入es数据一致性成为了热点话题。
我们举一个简单的例子来说明一下,图1在SparkRDD中(这里假设是一个task),每一条蓝色的线代表100万条数据,那么10条蓝色的线表示了有1000万条数据准备写入到CSS(华为云搜索服务,内部为es)的某个index中。在写入过程中,系统发生了故障,导致只有一半(500万条)数据成功写入。
task是Spark执行任务的最小单元,如果task失败了,当前task需要整个重新执行。所以,当我们重新执行写入操作(图2),并最终重试成功之后(这次用红色来表示相同的1000万条数据),上一次失败留下的500万条数据依然存在(蓝色的线),变成脏数据。脏数据对数据计算的正确性带来了很严重的影响。因此,我们需要探索一种方法,能够实现Spark写入es数据的可靠性与正确性。

图1 Spark task失败时向es写入了部分数据

图2 task重试成功后上一次写入的部分数据成为脏数据
解决方案
1.写覆盖
从上图中,我们可以很直观的看出来,每次task插入数据前,先将es的index中的数据都清空就可以了。那么,每次写入操作可以看成是以下3个步骤的组合:
- 步骤一 判断当前index中是否有数据
- 步骤二 清空当前index中的数据
- 步骤三 向index中写入数据
换一种角度,我们可以理解为,不管之前是否执行了数据写入,也不管之前数据写入了多少次,我们只想要保证当前这一次写入能够独立且正确地完成,这种思想我们称为幂等。
幂等式写入是大数据sink算子解决一致性问题的一种常见思路,另一种说法叫做最终一致性,其中最简单的做法就是“insert overwrite”。当Spark数据写入es失败并尝试重新执行的时候,利用覆盖式写入,可以将index中的残留数据覆盖掉。
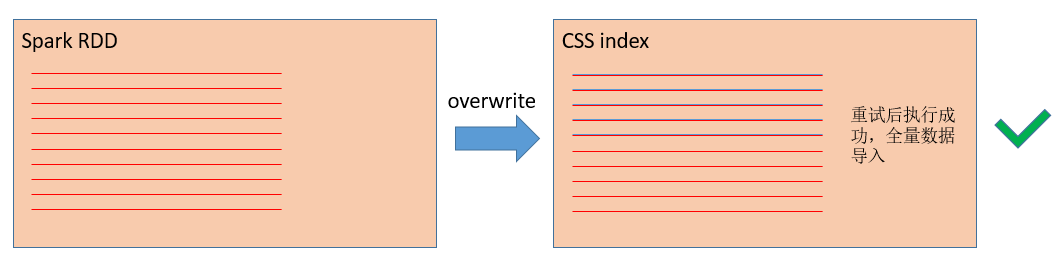
图 使用overwrite模式,task重试时覆盖上一次数据
在DLI中,可以在DataFrame接口里将mode设置成“overwrite”来实现覆盖写es:
val dfWriter = sparkSession.createDataFrame(rdd, schema) // // 写入数据至es // dfWriter.write .format("es") .option("es.resource", resource) .option("es.nodes", nodes) .mode(SaveMode.Overwrite) .save()
也可以直接使用sql语句:
// 插入数据至es sparkSession.sql("insert overwrite table es_table values(1, 'John'),(2, 'Bob')")
2.最终一致性
利用上述“overwrite”的方式解决容错问题有一个很大的缺陷。如果es已经存在了正确的数据,这次只是需要追加写入。那么overwrite会把之前index的正确的数据都覆盖掉。
比如说,有多个task并发执行写入数据的操作,其中一个task执行失败而其他task执行成功,重新执行失败的task进行“overwrite”会将其他已经成功写入的数据覆盖掉。再比如说,Streaming场景中,每一批次数据写入都变成覆盖,这是不合理的方式。

图 Spark追加数据写入es

图 用overwrite写入会将原先正确的数据覆盖掉
其实,我们想做的事情,只是清理脏数据而不是所有index中的数据。因此,核心问题变成了如何识别脏数据?借鉴其他数据库解决方案,我们似乎可以找到方法。在MySQL中,有一个insert ignore into的语法,如果遇到主键冲突,能够单单对这一行数据进行忽略操作,而如果没有冲突,则进行普通的插入操作。这样就可以将覆盖数据的力度细化到了行级别。
es中有类似的功能么?假如es中每一条数据都有主键,主键冲突时可以进行覆盖(忽略和覆盖其实都能解决这个问题),那么在task失败重试时,就可以仅针对脏数据进行覆盖。
我们先来看一下Elasticsearch中的概念与关系型数据库之间的一种对照关系:

我们知道,MySQL中的主键是对于一行数据(Row)的唯一标识。从表中可以看到,Row对应的就是es中的Document。那么,Document有没有唯一的标识呢?
答案是肯定的,每一个Document都有一个id,即doc_id。doc_id是可配置的,index、type、doc_id三者指定了唯一的一条数据(Document)。并且,在插入es时,index、type、doc_id相同,原先的document数据将会被覆盖掉。因此,doc_id可以等效于“MySQL主键冲突忽略插入”功能,即“doc_id冲突覆盖插入”功能。
因此,DLI的SQL语法中提供了配置项“es.mapping.id”,可以指定一个字段作为Document id,例如:
create table es_table(id int, name string) using es options( 'es.nodes' 'localhost:9200', 'es.resource' '/mytest/anytype', 'es.mapping.id' 'id')")
这里指定了字段“id”作为es的doc_id,当插入数据时,字段“id”的值将成为插入Document的id。值得注意的是,“id”的值要唯一,否则相同的“id”将会使数据被覆盖。
这时,如果遇到作业或者task失败的情况,直接重新执行即可。当最终作业执行成功时,es中将不会出现残留的脏数据,即实现了最终一致性。
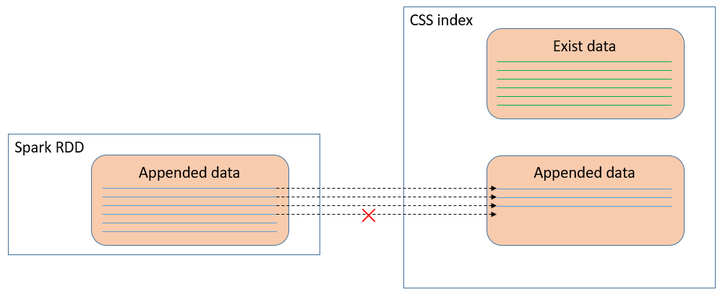

图 在插入数据时将主键设为doc_id,利用幂等插入来实现最终一致性
总结
本文可以一句话总结为“利用doc_id实现写入es的最终一致性”。而这种问题,实际上不需要如此大费周章的探索,因为在es的原生API中,插入数据是需要指定doc_id,这应该是一个基本常识:详细API说明可以参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html)

图 es使用bulk接口进行数据写入
权当消遣,聊以慰藉。
得益于Base理论,最终一致性成为分布式计算中重要的解决方案之一。尽管该解决方案还有一定的限制(比如本文的解决方案中数据必须使用主键),而业界还有很多分布式一致性的解决方案(比如2PC、3PC)。但个人认为,衡量工作量与最终效果,最终一致性是一种很有效且很简约的解决方案。
扩展阅读:Elasticsearch Datasource
简介
Datasource是Apache Spark提供的访问外部数据源的统一接口。Spark提供了SPI机制对Datasource进行了插件式管理,可以通过Spark的Datasource模块自定义访问Elasticsearch的逻辑。
华为云DLI(数据湖探索)服务已完全实现了es datasource功能,用户只要通过简单的SQL语句或者Spark DataFrame API就能实现Spark访问es。
功能描述
通过Spark访问es,可以在DLI官方文档中找到详细资料:https://support.huaweicloud.com/usermanual-dli/dli_01_0410.html。(Elasticsearch是由华为云CSS云搜索服务提供)。
可以使用Spark DataFrame API方式来进行数据的读写:
// // 初始化设置 // // 设置es的/index/type(es 6.x版本不支持同一个index中存在多个type,7.x版本不支持设置type) val resource = "/mytest/anytype"; // 设置es的连接地址(格式为”node1:port,node2:port...”,因为es的replica机制,即使访问es集群,只需要配置一个地址即可.) val nodes = "localhost:9200" // 构造数据 val schema = StructType(Seq(StructField("id", IntegerType, false), StructField("name", StringType, false))) val rdd = sparkSession.sparkContext.parallelize(Seq(Row(1, "John"),Row(2,"Bob"))) val dfWriter = sparkSession.createDataFrame(rdd, schema) // // 写入数据至es // dfWriter.write .format("es") .option("es.resource", resource) .option("es.nodes", nodes) .mode(SaveMode.Append) .save() // // 从es读取数据 // val dfReader = sparkSession.read.format("es").option("es.resource",resource).option("es.nodes", nodes).load() dfReader.show()
也可以使用Spark SQL来访问:
// 创建一张关联es /index/type的Spark临时表,该表并不存放实际数据 val sparkSession = SparkSession.builder().getOrCreate() sparkSession.sql("create table es_table(id int, name string) using es options( 'es.nodes' 'localhost:9200', 'es.resource' '/mytest/anytype')") // 插入数据至es sparkSession.sql("insert into es_table values(1, 'John'),(2, 'Bob')") // 从es中读取数据 val dataFrame = sparkSession.sql("select * from es_table") dataFrame.show()