摘要:在HDZ城市行广州站中,来自华为云华为云数据库创新Lab向宇从时序数据库的技术角度,解读一下华为云时序数据库GaussDB(for Influx)如何应用在智慧健康养老行业。
本文分享自华为云社区《拥抱时序数据库,构筑IoT时代下智慧康养数据存储底座》,作者: 技术火炬手 。
随着 IoT 技术的快速发展,物联网设备产生的数据呈爆炸式增长。这些数据通常随时间产生,称之为时序数据。这样的一种专门用于管理时序数据的数据库被称为时序数据库。
时序数据库是当前物联网 IoT垂直领域最为合适的数据库解决方案。作为物联网下火热的智慧健康养老应用,时序数据库能为智慧健康养老行业带来哪些贡献?在HDZ城市行广州站中,来自华为云华为云数据库创新Lab向宇从时序数据库的技术角度,解读一下华为云时序数据库GaussDB(for Influx)如何应用在智慧健康养老行业。
时序数据库助力智慧健康养老场景化应用
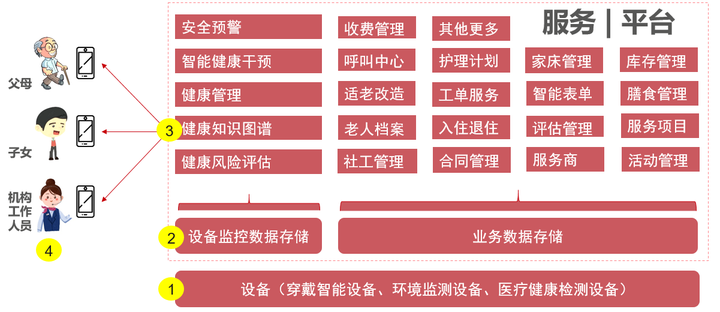
从智慧健康养老的全场景图看到,智慧健康养老整体上分为4个部分:
- 设备:包括穿戴设备(比如手环,可以记录步数和心率)、环境监测设备(比如室内室外温度传感器)和医疗健康设备(比如血压仪、血糖仪)。这些设备产生的数据需要上传到平台或系统服务进行统一存储,为更上层的应用提供基本的数据输入。
- 数据存储层:相同功能但不同厂商的设备产生的数据格式可能不尽相同。再者,随着业务的发展,可能还会接入更多类型设备,数据量也会越来越大。考虑业务变更和数据库性能,为最大程度降低对上层应用的影响,把设备数据与其他业务数据分开存储。
- 服务层:平台对外提供的能力,比如安全预警、健康风险评估、其他养老事务管理功能等。
- 端侧应用:基于平台提供的服务,可以开发出APP,利用APP把老人、子女、机构工作人员三类用户联系起来,例如:子女可以通过手机APP实时查看自己父母的运动情况,健康指标,工作人员可以在终端提交工单等等)。
在物联网等领域,特别是智慧康养场景下,我们发现有这么一些数据,他们都有时间属性,有设备描述信息,有采集的数据指标。举个例子,如下图所示:

第一列是数据产生的时间,第二列是设备编号,后面是采集的数据内容,如体温、心率等。我们把数据划分为三个部分,时间部分称为时间戳,设备编号等描述设备信息的部分称之为数据的标签,剩余部分描述了采集的具体指标,称之为指标项。像这样的数据,我们就称之为时序数据,因为它有明显的时间属性。那么这些时序数据,都是有自己的特点:
- 不变性:时序数据在写入后,一般不会被修改。这个特征非常适用于压缩,不因修改某个数据对整个数据块进行修改。
- 时效性:时间越近的数据被访问的概率大,时间越是久远,数据被访问的概率越低。因此,对于时序的热数据,可以采用压缩和解压速度比较好,压缩率合理的压缩算法,而对于冷数据,非常适合使用更高压缩比的算法。
- 数据量庞大:时序数据的采集类型丰富, 随着采集硬件的普及和采集频率增加,使得数据量出现暴增,比如自动驾驶中每辆车每天就会采集将近 8T 的数据,带宽、实时写入、快速查询、存储、耗电以及维护成本都是挑战。
- 数据使用冷热:用户可能对某些数据源或者时间段的关注远远超过其他,因此在海量数据中偏向某些特殊时间段或某些数据源的数据查询。
时序数据库如何选?
从我们的企业应用的情况来看,目前存放时序数据采用的数据库各种各样,有用关系数据库存放,有用NOSQL数据存储(比如HBASE,Cassandra,MongoDB),还有就是用到了时序数据库。我们总结了一下选型数据库之前需要考虑的一些问题:
- 成本:分为运维成本和存储成本,比如用HBASE存储,它的技术栈很长,底层存储使用的是HDFS。运维就需要一个人既懂时序数据库,又要懂大数据平台,成本比较高。其次,数据量逐渐的增加,存储需要不断的扩容,成本随之上来了。所以,既要选择部署便捷、扩容操作简单,又要能提供数据压缩的数据库。
- 性能:不同的业务对数据库的性能需求是不一样的,需要考虑今后业务规模增加后,数据库能不能支撑预期的设备数量和数据量。
- 业务变更:对于物联网而言,由于缺乏标准,各式各样的设备都有可能接入,有的设备可能只有2列数据,有的设备可能有3列数据,这就要求数据库支持Schemaless。
- 生态:主要是时序数据库上下游接口的问题,选择的数据库需要考虑其技术生态,数据要能进的来,出的去。比如用了SQLServer存时序数据,想用Granfana展示数据就很困难。
- 数据分析:设备数据被存储下来,最终是需要通过数据分析挖掘数据隐藏价值,还要考虑数据库是否支持数据分析平台。
鉴于上述行业中存在的问题,以及对未来物联网发展的信心,华为云自研GaussDB(for Influx) 基于华为自研的计算存储分离架构,兼容InfluxDB生态的云原生NoSQL时序数据库。提供大并发时序数据读写、压缩存储、多维聚合以及一键部署、快速备份恢复、计算存储独立扩容、监控告警等服务能力,可以完全满足康养的需求。
GaussDB(for Influx)时序数据库依靠华为在数据存储领域多年的实践经验,整合华为云的计算、存储、服务保障和安全等方面的能力,大胆在架构、性能和数据压缩等方面进行了技术创新,达到了较好的效果,对内支撑了华为云基础设施服务,对外以服务的形式开放,帮助上云企业解决相关业务问题。
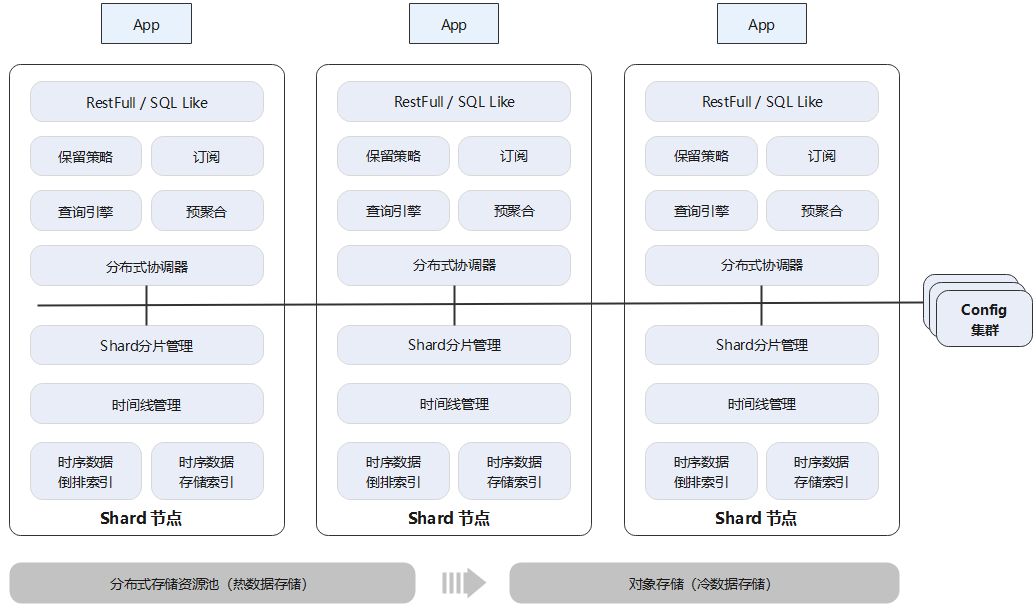
GaussDB(for Influx)接口完全兼容InfluxDB,写入接口兼容OpenTSDB、Prometheus和Graphite。从架构上看,一个时序数据库集群可以分为三大组件。它们分别是:
- Shard节点:节点采用无状态设计,主要负责数据的写入和查询。在节点内,除了分片和时间线管理之外,还支持数据预聚合、数据降采样和TAG分组查询等专为时序场景而优化的功能。
- Config集群:存储和管理集群元数据,采用三节点的复制集模式,保证元数据的高可靠性。
- 分布式存储系统:集中存储持久化的数据和日志,数据采用三副本方式存放,对上层应用透明。存储系统为华为自研,经过多年产品实践检验,系统的高可用和高可靠性都得到了验证。
华为云时序数据库应对智慧康养应用场景有妙招
在面对AIoT物联网典型应用场景中,时序数据库每天会产生数GB甚至数TB的时序数据。如果无法对这些时序数据进行很好的管理和压缩,那将会给企业带来非常高的成本压力。
GaussDB(for Influx)对数据采用列式存储,相同类型的数据被集中存储,更有利于数据压缩。采用自研的时序数据自适应压缩算法,在压缩前对数据进行抽样分析,根据数据量、数据分布以及数据类型选择最合适的数据压缩算法。在压缩算法上,相比原生的InfluxDB,重点针对Float、String、Timestamp这三种数据类型进行了优化和改进。
- Float数据类型: 对Gorilla压缩算法进行了优化,将可以无损转换的数值转为整数,再根据数据特点,选择最合适的数据压缩算法。
- String数据类型:采用了压缩效率更好的ZSTD压缩算法,并根据待压缩数据的Length使用不同Level的编码方法。
- Timestamp数据类型:采用差量压缩方法,最后还针对数据文件内的Timestamp进行相似性压缩,进一步降低时序数据存储成本。
下图是分别采用实际业务场景的事件日志数据(数据集1)和云服务器监控指标数据 (数据集2)与InfluxDB进行了数据压缩效率的性能对比。

节约存储成本并非只有数据压缩一种办法。针对时序数据越旧的数据被访问的概率越低的特点,GaussDB(for Influx)提供了时序数据的分级存储,支持用户自定义冷热数据,实现数据的冷热分离。热数据相对数据量小,访问频繁,被存储在性能更好、成本较高的存储介质上;冷数据相对数据量大,访问概率低,保存时间较久,被存储在成本较低的存储介质上,进而达到节约存储成本的目的。根据实际业务数据测算,相同数据量下存储成本仅有关系型数据库的1/20。
除了产品本身的技术优势特点,GuassDB(for Influx)能够开箱即用,用户只需要关注应用层就可以,不用关注运维。在使用的过程中,不需要去特意学习新的产品技术,会SQL就可以使用。GaussDB(for Influx)还兼容Influx 生态,整个生态下的工具、接口等都可以直接应用。
从数据安全角度看,GaussDB(for Influx)在容灾备份方面,支持异地3AZ,可以让数据存储在不同的城市,这样确保数据的安全性。
在智慧康养场景下,最重要的是如何基于数据分析,来进一步对用户带来更好地产品服务。GuassDB(for Influx)还提供数据分析平台,能够和数据库融合在一起,可以把相关算法以热插拔的方式嵌入到平台中,从数据库直接读取数据进行分析,最终应用在相对应的场景下。这两边是以相互感知的形式,分析感知存储,从而轻量化存储分析开销。不管企业在什么地方,基于GuassDB(for Influx)能够解决康养企业的数据孤岛问题,实现价值共享。
最后,向宇还提前透露了GuassDB(for Influx)的开源计划,开源的名字叫GeminiTSDB,兼容Influx DB接口,采用类SQL查询语言,提供单机和分布式集群两种部署模式,安装简单,部署灵活,无须外部依赖,具有高可用、高性能、低时延、低存储成本、扩展灵活等优点,希望大家多多关注!