摘要:dbeaver是免费和开源为开发人员和数据库管理员通用数据库工具。本文介绍如何配置dbeaver对接FusionInsigth MRS Spark2x。
本文分享自华为云社区《DBeaver对接FusionInsight MRS Spark2x》,作者:晋红轻 。
使用自定义JDBC对接Spark2x
- 在C:\ecotesting\Fiber\conf目录下新建 jaas.conf 文件,内容如下所示:
Client { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab="C:\\ecotesting\\Fiber\\conf\\user.keytab" principal="developuser" useTicketCache=false storeKey=true debug=true; };
注意: 其中keyTab参数以及principal参数为对应的认证用户名以及认证文件路径
- 下载DBeaver软件,并完成安装.
- 指定DBeaver的JDK虚拟机.在DBeaver安装目录下,打开dbeaver.ini设置 -vm 参数的值,参数和值之间需要换行.
示例如下:
-vm C:\java64\jdk\bin 配置文件最后加上: -Djava.security.auth.login.config=C:\\ecotesting\\Fiber\\conf\\jaas.conf -Dzookeeper.sasl.clientconfig=Client -Dzookeeper.auth.type=kerberos -Dzookeeper.server.principal=zookeeper/hadoop.hadoop.com
- 重启DBeaver.
修改dbeaver.ini后需要重启DBeaver才生效.
- (重要 fi6.5.1)准备spark2x jdbc连接驱动jar包
登陆linux端spark2x客户端找到jdbc相关依赖,比如:/opt/145_651hdclient/hadoopclient/Spark2x/spark/jars/jdbc

将该路径下所有的jar包拷贝到windows本地目录,比如E:\145config\spark2xjars, 注意里面含有一个jdbc_pom.xml文件,需要删除
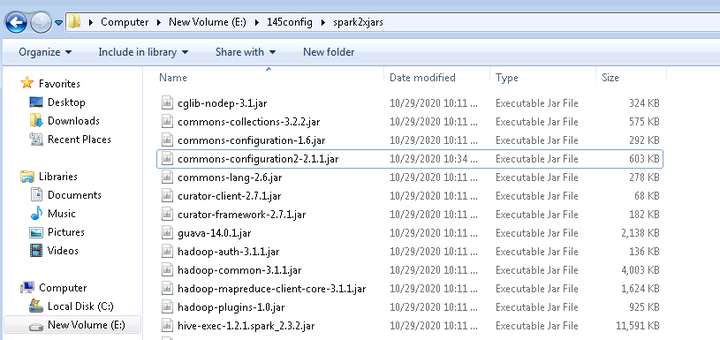
继续登陆linux端spark2x客户端路径/opt/145_651hdclient/hadoopclient/Spark2x/spark/jars,分别找到如下4个jar包,拷贝到windows本地目录,比如E:\145config\spark2xjars
log4j-1.2.17.jar woodstox-core-5.0.3.jar stax2-api-3.1.4.jar commons-configuration2-2.1.1.jar
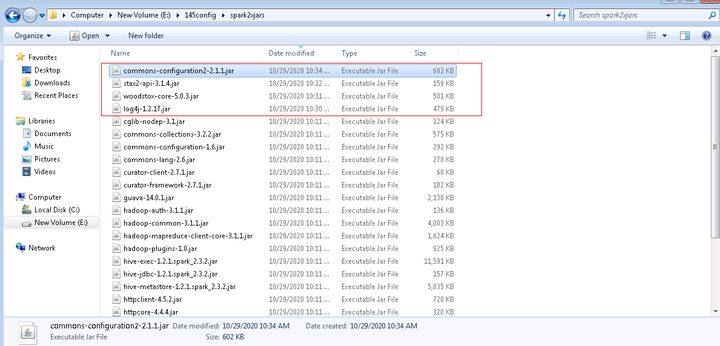
说明: 如果是mrs8.0.2版本准备的依赖为:
- 登陆linux端spark2x客户端找到jdbc相关依赖,比如:/opt/80_135_hadoopclient2/hadoopclient/Spark2x/spark/jars/jdbc下所有依赖
- 继续登陆linux端spark2x客户端路径/opt/80_135_hadoopclient2/hadoopclient/Spark2x/spark/jars,分别找到如下5个jar包
log4j-1.2.17-atlassian-13.jar commons-lang-2.6.jar woodstox-core-5.0.3.jar stax2-api-3.1.4.jar commons-configuration2-2.1.jar
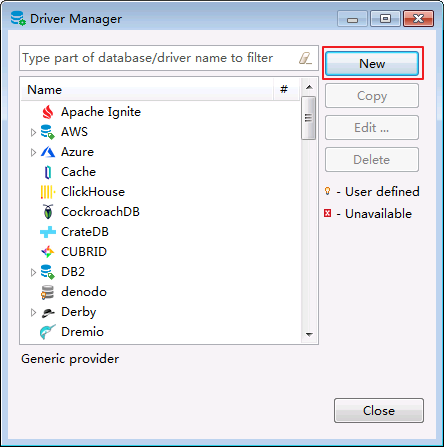
- 进入DBeaver界面,菜单选择Database->DriverManager,在弹出的对话框中点击 New.
- 新建的连接名字为FI-spark2x-651-direct,连接信息如下,完成后点击OK
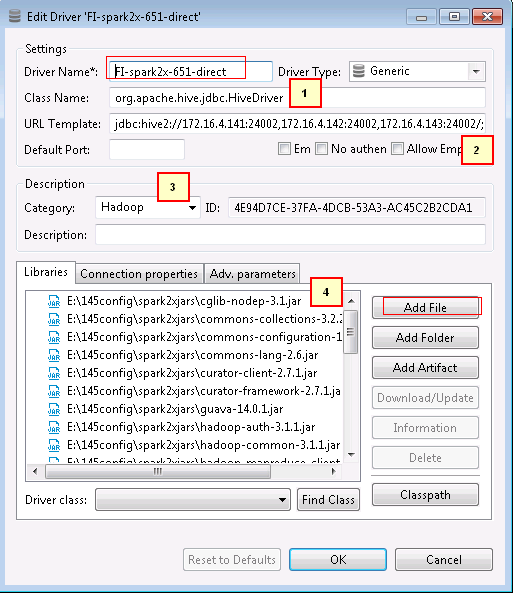
1. org.apache.hive.jdbc.HiveDriver 2. jdbc:hive2://172.16.4.141:24002,172.16.4.142:24002,172.16.4.143:24002/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.hadoop.com@HADOOP.COM;user.principal=developuser;user.keytab=E:/145config/user.keytab 3. Hadoop 4. 点Add File在上述步骤配置好的spark2x连接所有jar包加进去
注意:连接url的user.principal=developuser;user.keytab=E:/145config/user.keytab这两个参数必须加上,并且保证正确
连接url串,可在Linux客户端使用spark-beeline命令获取参考:

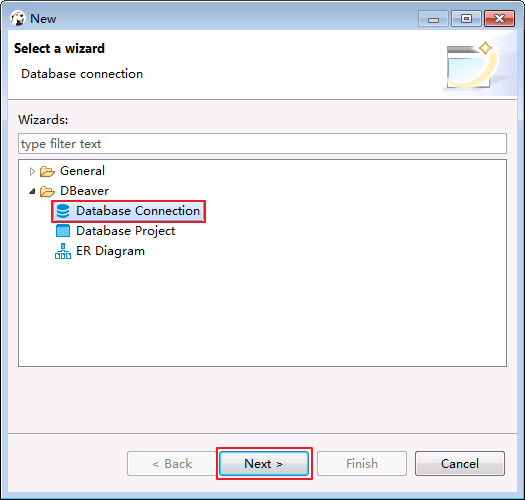
- 菜单栏选择File->New->Database Connection.点击 Next.
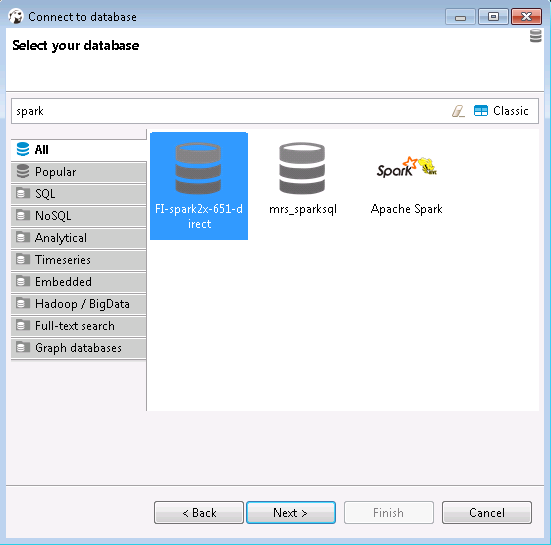
- 选择FI-spark2x-651-direct点击NEXT
- 点击Finish
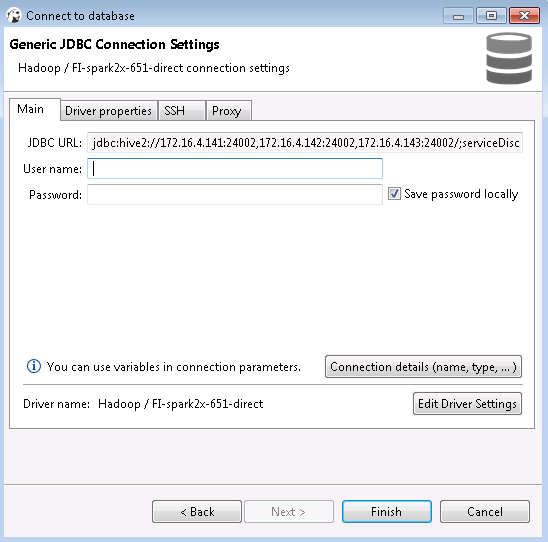
- 右键选择FI-spark2x-651-direct点击Edit Connection
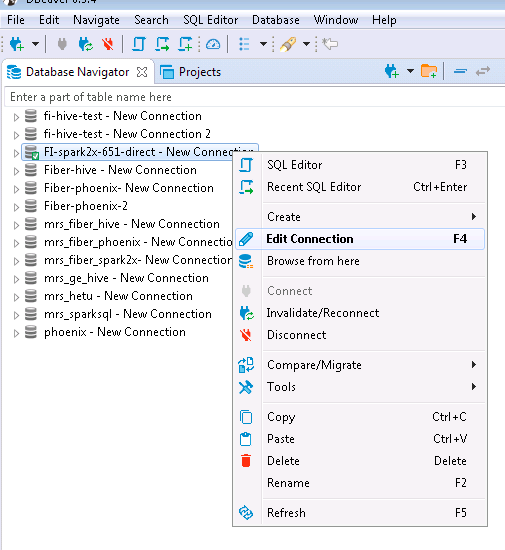
- 点击Test connection
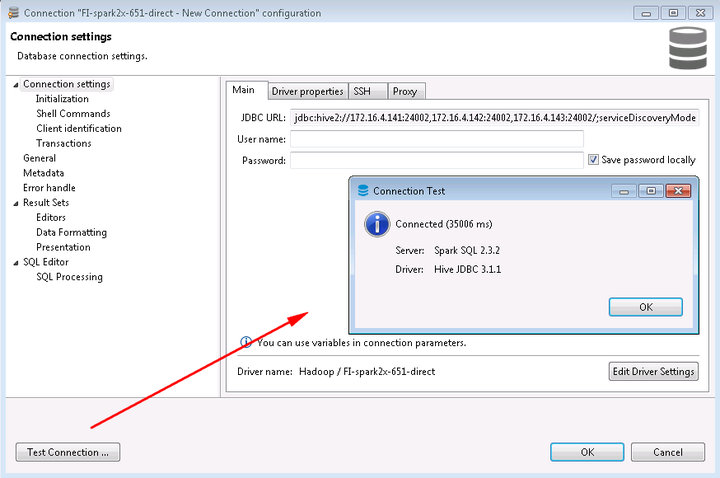
mrs 8.0.2的测试结果如下:
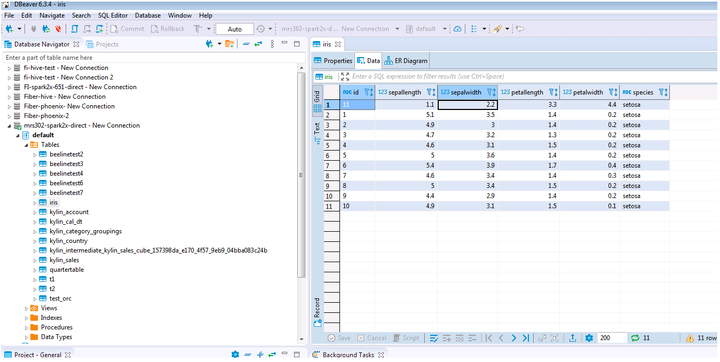
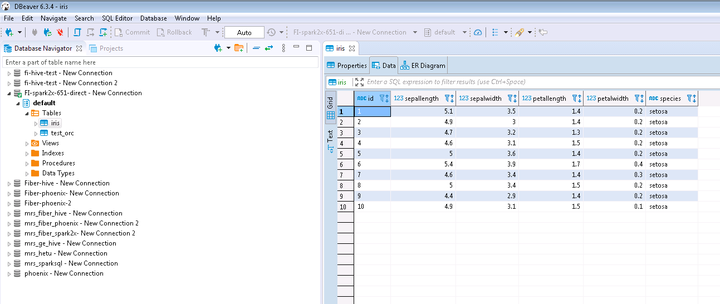
- 查看结果数据
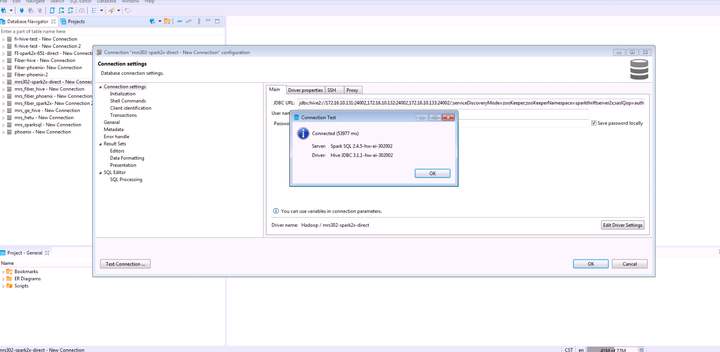
mrs 8.0.2的测试结果如下: