数据可视化
在可视化工作中,一个基本出发点是将不同的数值映射到不同的可视化 元素的属性上,使其表现出各自不同的视觉特征。
比如:以数组中的每一个值为直径分别创建一个圆,我们得到三个圆:
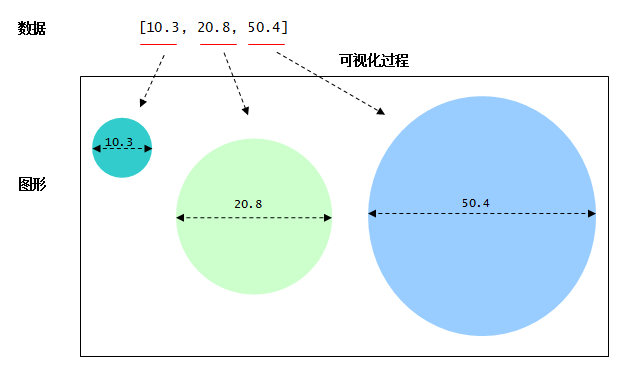
在d3中,可视化元素可以是HTML元素或者SVG元素。比如,我们可以使用一个圆角的 DIV元素表示圆。这样一个数字就对应了一个DIV元素。
data:数据操作符
在d3的处理流水线中,data()操作符使用数据来修剪选择集中的DOM元素:
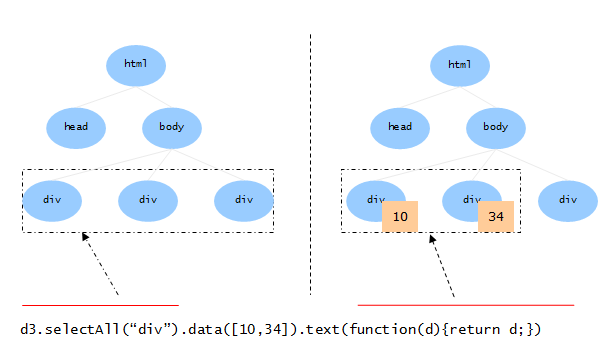
选择集的data()操作符执行后返回的是一个新的选择集,其内容是与数据集 匹配的DOM对象。在图中,data()使用数据集:[10,34]与选择集中的DOM对象 按顺序号依次匹配,并将数字存入对应DOM对象的data属性。显然,第3个div 元素没有对应序号的数据,所以返回的选择集中不包括这个DOM对象。
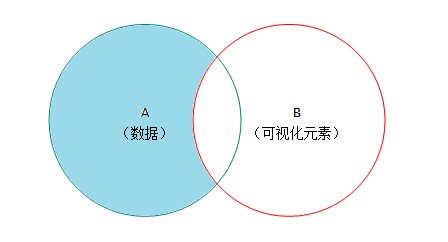
从集合运算的角度,这就像进行两个集合的交集(A∩B)计算,返回两个集合共有的那 部分成员。
enter:获得未匹配数据
如果数据集中的数据比选择集中的DOM元素多,data()会将这部分数据单独保存, 并通过enter()方法提供出来:
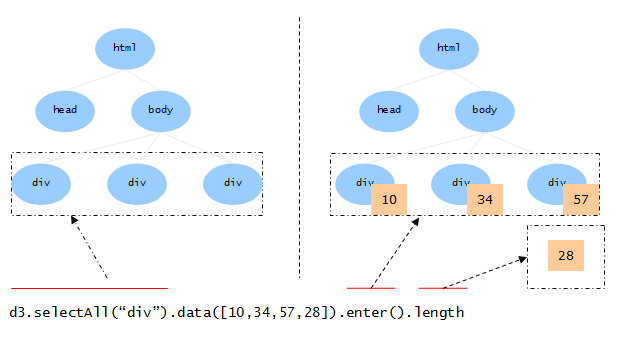
注意enter()返回的也是一个选择集对象,只是这个选择集 不包含任何DOM元素,可将其视为仅包含数据值的伪选择集。
这可以类比于两个集合的差额部分,A-B代表了没有对应 可视化元素的那部分数据:
去掉示例(http://www.hubwiz.com/course/54fd40cfe564e50d50dcf284/ 中关联数据第三页)代码中的enter()行,看看结果有什么变化?体会这里面的含义!
exit:获得未匹配的DOM元素
同样的,如果数据集中的数据比选择集中的DOM元素少,data()会将这部分多出来的DOM元素 单独保存,并通过exit()方法提供出来:
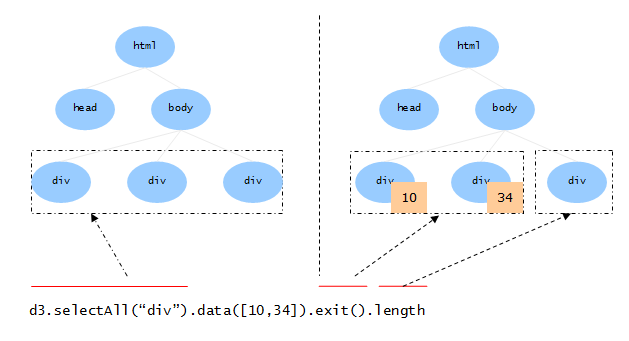
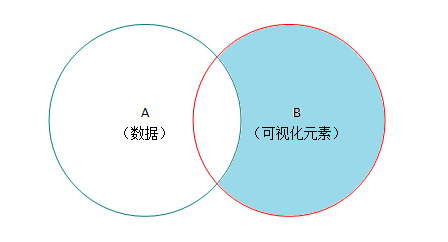
这同样可类比于两个集合的差额部分,B-A代表了没有对应数据的那部分 可视化元素:
去掉示例(http://www.hubwiz.com/course/54fd40cfe564e50d50dcf284/ 中关联数据第四页)代码中的exit()行,看看结果有什么变化?体会这里面的含义!
数据集:使用简单数组
在d3中,数据集是使用数组/array来指定的。
最简单的数组是一组数值,比如:[12.34,27.29,29.39,12.38]。这些数值 可以直接映射成可视化元素的一个属性值(或许需要一些必要的比例缩放, 以便能看得清楚)。
经常用来映射数值的可视化元素的属性包括:
- 坐标位置:对于HTML元素来讲,就是left、top属性
- 宽度:对于HTML元素来讲,就是width属性
- 高度:对于HTML元素来讲,就是height属性。
- 背景颜色:比如,数值越小,颜色越浅。
- 字体颜色
- 字体大写
- ....
这依赖于你的想象力。
数据集:使用对象数组
在实际的应用场景中,数据集中的每一项通常对应着一个业务模型对象,不会只是 一个简单的数值,而是一个有众多属性的JSON对象:
- var repo = [
- {
- name : "Zhang San",
- gender : "Male",
- age : 28,
- friends : [...]
- },
- ...
- ]
但这对于d3不是什么难事,一早提到的访问器函数的作用就体现在这个地方: d3虽然管理DOM元素和数据对象的映射关系,但它并不直接访问数据, 而是通过我们提供的访问器接口才访问数据!
这样的好处是,d3不需要对数据结构进行严格地限制了,每当它 需要访问数据,总是把DOM元素对应的数据传递给我们提供的访问器 函数,由我们负责解析,它只要结果。
数据集:使用数据函数
data()操作符会对传入的参数类型进行判断,如果是一个函数,它就会 执行这个函数,并且使用其返回值(注意:这个函数的返回值必须是一个数组) 作为数据集。
在有些应用场景下,这个功能很实用。比如,你了解数据的生成模式,只需要 一个公式就能产生出大量的数据;或者,你就是像我一样,为了展示一下这个 功能...
(http://www.hubwiz.com/course/54fd40cfe564e50d50dcf284/ 中关联数据第七页)的代码生成了一些随机数据,具有如下的结构:
- {
- x: <随机数>
- y: <随机数>
- value: <随机数>
- }
我们在示例中很直白地将数据的x值映射为DIV元素的left属性,y值映射为DIV元素 的top属性,并在每个DIV中显示value。
每次要将一组数据进行可视化,总有这样一个设计过程。d3简化了从数据变换到图形 的工作,但是,思想,还是来源于我们自己。
请参考代码思考前一段话,并试着改变一下数据属性的映射方案。