
最近需要做数据分析处理,比较反复,因此在linux下使用shell命令会更加方便高效,有助于工作开展,特作此总结。
参考:https://www.runoob.com/linux/
参考:https://blog.51cto.com/191226139/2060467
0、vim编辑器
- 所有的Unix Like系统都会内建vi文本编辑器,Vim是vi发展出来的一个文本编辑器,具有代码补全、编译及错误跳转等特点。
- vim有三种模式,分别为命令模式、输入模式和底线命令模式。命令模式状态下的操作会被识别为命令,常用命令有i-切换到输入模式、x-删除光标处字符、:-切换到底线命令模式;输入模式就是一般的字符输入,底线命令模式可输入多个字符,在命令模式切换到底线命令模式后即可操作,常用命令有q-退出、w-保存。
参考:https://www.runoob.com/linux/linux-vim.html
1、awk命令(重要)
1.1 基本语法
参考:https://www.runoob.com/linux/linux-comm-awk.html
- awk:是一种处理文本文件的语言,是一个强大的文本分析工具。相当于grep的查找,sed的编辑,简单来说就是awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
- 命令行方式调用awk:
awk [-F field-separator] 'commands' input-file(s),其中commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。
-F: 指定输入文件拆分分隔符;默认为空格。
-v:赋予一个用户定义变量;
-f:从脚本文件中读取awk命令; - 例如:awk -F'|' '{print $2}' 20191111.txt |head ,其中-F表示指定输入文件分隔符为'|',并打印处第二项,输入文件指定问20191111.txt,
|head表示将输出的结果执行head命令,即查看前10个;awk -F'|' '{print $2}' 20191111.txt |sort|uniq -c,表示将awk分析出来的数据线进行排序,然后进行唯一性统计。
参考:https://www.cnblogs.com/ggjucheng/archive/2013/01/13/2858470.html 和 https://www.runoob.com/linux/linux-comm-awk.html
- 命令行方式调用awk:
1.2 基本用法
- test.txt文本内容:
0000842FD3AD2B24DABD5CDB54B4C98A|1|1|2|20008.0||30|30|0|0|206|(_少惹(ωǒ
00008EE9519B8B2289D118C327121FD0|1|1|2|20015.0||18|19|0|0|399|Devin
0000A149C6BA44236E0C7A47152740DE|1|1|2|20017.0||1|1|0|0|411|向冒狙砍
00010625FEB0D71E2FB88F3C1AFD10A0|1|1|2|20013.0||26|28|0|0|1087|JK论
0001659D2D84227A85483D403445E292|1|1|2|20002.0||22|24|0|0|410|多多哟
- (1)用法1:
awk '{[pattern] action}' {filenames}行匹配语句awk ' ' 只能用单引号- 举例1:
awk -F '|' '{print $1,$5}' 20191207.txt | head
- 举例1:
$ awk -F '|' '{print $1,$5}' 20191207.txt | head
0000842FD3AD2B24DABD5CDB54B4C98A 20008.0
00008EE9519B8B2289D118C327121FD0 20015.0
0000A149C6BA44236E0C7A47152740DE 20017.0
00010625FEB0D71E2FB88F3C1AFD10A0 20013.0
0001659D2D84227A85483D403445E292 20002.0
000295610E8C9A2B32706693D49BBEB8 20004.0
- 举例2:格式化输出:`awk -F '|' '{printf "%-40s %-5s
",$1,$4}' 20191202.txt |head`
$ awk -F '|' '{printf "%-40s %-5s
",$1,$4}' 20191202.txt |head
05029748828D6159755581E69C1C8BCA 2
05D2A89B39B38BACF634B2138B612091 2
09870F01A8D18BA9F2F7042042EDE5B8 2
09FAD5B9664DAAE1DD5C6AB2AADE2AAC 2
0CB9496935127969124389655392778A 2
- 举例3:使用内建变量:awk 'BEGIN{FS="|"}' '{print $1,$4}' 20191202.txt |head
出现问题???
- 举例4:使用多个分隔符,先使用空格分隔,然后对分隔结果再使用“,”分隔,最后使用‘|’
$ awk -F '[ ,|]' '{printf "%-40s %-5s
",$1,$4}' 20191202.txt | head -n 5
05029748828D6159755581E69C1C8BCA 2
05D2A89B39B38BACF634B2138B612091 2
09870F01A8D18BA9F2F7042042EDE5B8 2
09FAD5B9664DAAE1DD5C6AB2AADE2AAC 2
0CB9496935127969124389655392778A 2
- (2)用法2:
awk -v #设置变量
$ awk -F '|' -v a=10 '{print $4,$4+a}' 20191202.txt | head -n 5
2 12
2 12
2 12
2 12
2 12
- (3)用法3:
awk -f {awk脚本} {文件名}——一般用不上这个脚本
$ awk -f cal.awk 20191202.txt
1.3 运算符

(1)过滤第2列大于等于2的行:$2>=2(不太清楚为什么|没有被区分开)
$ awk -F '[|]' '$2>=2' 20191202.txt |head -n 5
05029748828D6159755581E69C1C8BCA|4|1|2|80001.0||1|32|0|0|17392|6) 虎牙丶冰焰 虎牙丶冰焰2 虎牙丶冰焰3
0CB9496935127969124389655392778A|3|1|2|80001.0||16|60|0|0|5843|。。。 暂停厌倦 美丽的蔷薇
1269B2D7562A5F04B76C4A3AFB9DFE39|2|1|2|80001.0||23|46|0|0|992|空城 虎牙新游梁少
12CE8AC0AE43CA71767A0F4C274BAB01|2|1|2|80001.0||40|46|0|0|2154|日月 日月.
199183A61470216FDD835F509B885DB6|3|1|2|80001.0||1|44|0|0|2132|安琪拉 纯珍珠(•̀⌄ 迎风破浪一刀斩
(2)过滤第2列等于2的行
$ awk -F '|' '$2==2 {print $1, $2, $5}' 20191202.txt |head -n 5
1269B2D7562A5F04B76C4A3AFB9DFE39 2 80001.0
12CE8AC0AE43CA71767A0F4C274BAB01 2 80001.0
1FB758259951CA17940327806CB5A4BC 2 80001.0
20DC1E4B6E326D9DEA86F47E77E32B68 2 80001.0
21C4B33E879FCC5EADED49D634F58A83 2 80001.0
(3)过滤第2列大于等于2并且第5列等于‘70001’的行
$ awk -F '|' '$2>=2 && $5="70001"' 20191202.txt |head -n 5
05029748828D6159755581E69C1C8BCA 4 1 2 70001 1 32 0 0 17392 6) 虎牙丶冰焰 虎牙丶冰焰2 虎牙丶冰焰3
0CB9496935127969124389655392778A 3 1 2 70001 16 60 0 0 5843 。。。 暂停厌倦 美丽的蔷薇
1269B2D7562A5F04B76C4A3AFB9DFE39 2 1 2 70001 23 46 0 0 992 空城 虎牙新游梁少
12CE8AC0AE43CA71767A0F4C274BAB01 2 1 2 70001 40 46 0 0 2154 日月 日月.
199183A61470216FDD835F509B885DB6 3 1 2 70001 1 44 0 0 2132 安琪拉 纯珍珠(•̀⌄ 迎风破浪一刀斩
(4)格式化输出结果">"
$ awk -F '|' '$2>=2 && $5="70001" {print $1,">", $2,">",$5}' 20191202.txt |head -n 5
05029748828D6159755581E69C1C8BCA > 4 > 70001
0CB9496935127969124389655392778A > 3 > 70001
1269B2D7562A5F04B76C4A3AFB9DFE39 > 2 > 70001
12CE8AC0AE43CA71767A0F4C274BAB01 > 2 > 70001
199183A61470216FDD835F509B885DB6 > 3 > 70001
1.4 内建变量
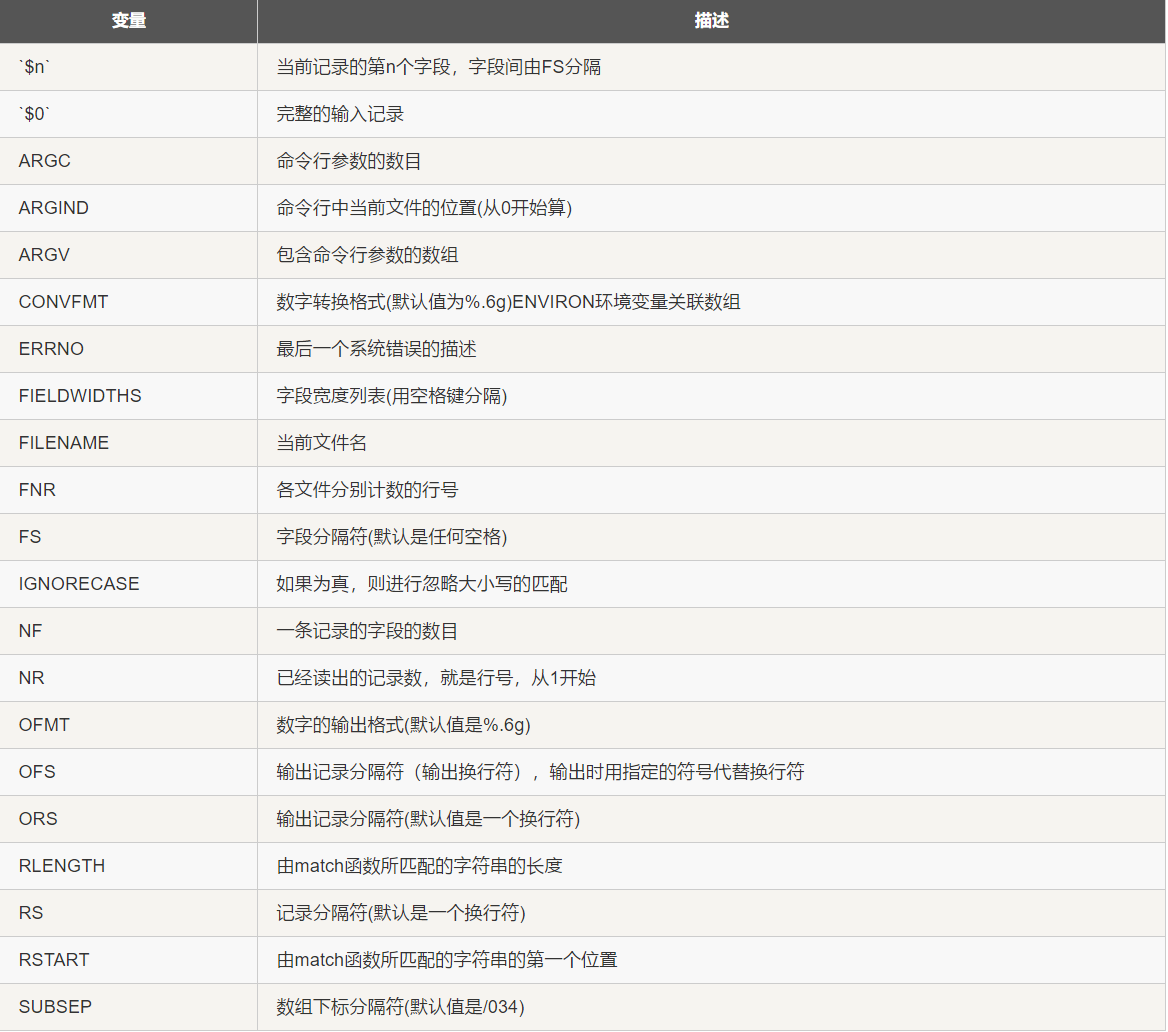
(1)FILENAME,将文件名和第1列、第5列一起输出
# 个性化输出内建变量和文本数据内容(前置字符串长度输出)
$ awk -F '|' 'BEGIN{printf "%s %40s %10s
","FILENAME","uin","worldid"}{printf "%s %40s %10s
", FILENAME, $1, $5}' 20191202.txt | head -n 5
FILENAME uin worldid
20191202.txt 05029748828D6159755581E69C1C8BCA 80001.0
20191202.txt 05D2A89B39B38BACF634B2138B612091 20001.0
20191202.txt 09870F01A8D18BA9F2F7042042EDE5B8 80001.0
20191202.txt 09FAD5B9664DAAE1DD5C6AB2AADE2AAC 80001.0
# 个性化输出(后置字符串长度输出)
$ awk -F '|' 'BEGIN{printf "%-15s %-40s %-10s
","FILENAME","uin","worldid"}{printf "%-15s %-40s %-10s
", FILENAME, $1, $5}' 20191202.txt | head -n 5
FILENAME uin worldid
20191202.txt 05029748828D6159755581E69C1C8BCA 80001.0
20191202.txt 05D2A89B39B38BACF634B2138B612091 20001.0
20191202.txt 09870F01A8D18BA9F2F7042042EDE5B8 80001.0
20191202.txt 09FAD5B9664DAAE1DD5C6AB2AADE2AAC 80001.0
(2)ARGIND,命令行中当前文件的位置
awk 'ARGIND==1{bk[$1]=1}ARGIND>=2{if(bk[$1]==1)print $1}' tt.txt /cephfs/gdata/2602/result/uin_monitor/201909*|sort -u|wc -l
表示在目录/cephfs/gdata/2602/result/uin_monitor/201909*中的所有文件中,第一个文件tt.txt和之后的所有文件进行分析,排序,统计。其中ARGIND1表示第一个文件,{bk[$1]=1}表示将第一个文件中的第一个域字段暂定义为1;{if(bk[$1]1)print $1}表示之后的文件中如果第一个变量的域字段和第一个文件一致,则print $1。awk '{if(ARGIND==1){print "处理a文件"} if(ARGIND==2){print "处理b文件"}}' a b
文件处理的顺序是先扫描完a文件,再扫描b文件。
1.5 其他
(1)使用正则,字符串匹配
~表示模式开始,/str/中的str表示模式。
# 输出满足第12列包含"。"字符串的行的第1、2、12列
$ awk -F '|' '$12 ~ /。/ {print $1, $2, $12}' 20191202.txt | head -n 5
0CB9496935127969124389655392778A 3 。。。 暂停厌倦 美丽的蔷薇
493EA9A54F9416019659F571AB573D5D 4 你的名字? 彼岸花。 彼岸花! 有心人
A0E0EFA7522A693A10EFE66AD75C96EA 1 七缘。
C0F221D5FF0B18E64724E47B0E1E5AE3 1 黑白。
F2E9BFD4C35C27AE651F40ADACFE57BD 1 乔碧萝。
# 输出满足第1列包含"BCA"字符串的行的第1、2、12列
$ awk -F '|' '$1 ~ /BC/ {print $1, $2, $5, $12}' 20191202.txt | head -n 5
05029748828D6159755581E69C1C8BCA 4 80001.0 6) 虎牙丶冰焰 虎牙丶冰焰2 虎牙丶冰焰3
1011902B19BC28EC9755C74E3BCD4C94 1 20001.0 雄壮的北冕
1FB758259951CA17940327806CB5A4BC 2 80001.0 哈喽:小娘子 给爸爸跪下
22707AD961D5BC33CCE6FD0588E06322 2 80002.0 虎牙念安 虎牙熙熙呦
243A53550023BC41B838065FD4AEB6D8 3 80001.0 飘T落 飘o落 飘落
(2)忽略大小写:BEGIN{IGNORECASE=1}匹配
$ awk -F '|' '$1 ~ /bc/ {print $1, $2, $5, $12}' 20191202.txt | head -n 5
o0z0oxD3k7IiSDacbcwqJ3k33RyQ 1 70001.0 ꧁༺柔༒情༻꧂
o0z0oxJk9RcIb7rt8w1jbctLG1J8 1 70002.0 沐沐
awk -F '|' 'BEGIN{IGNORECASE=1} $1 ~ /bc/ {print $1, $2, $5, $12}' 20191202.txt | grep o0z0oxD3k7IiSDacbcwqJ3k33RyQ
o0z0oxD3k7IiSDacbcwqJ3k33RyQ 1 70001.0 ꧁༺柔༒情༻꧂
(3)模式取反:在模式开始的前面加个!,表示模式取反,即不匹配模式的数据
awk -F '|' 'BEGIN{IGNORECASE=1} $1 !~ /bc/ {print $1, $2, $5, $12}' 20191202.txt | head -n 5
05D2A89B39B38BACF634B2138B612091 1 20001.0 雄壮的卡努
09870F01A8D18BA9F2F7042042EDE5B8 1 80001.0 玉兔
09FAD5B9664DAAE1DD5C6AB2AADE2AAC 1 80001.0 霸道小姐姐丫
0CB9496935127969124389655392778A 3 80001.0 。。。 暂停厌倦 美丽的蔷薇
0CD1F8F5BBB0EB846D3450FE2E1707E9 1 80001.0 风萧萧兮易水寒
(4)awk脚本
- 关于awk脚本,我们需要注意两个关键词BEGIN和END
- BEGIN{这里放的是执行前的语句}
- END{这里放的是处理完所有的行后要执行的语句}
- {这里面放的是处理每一行时要执行的语句}
- 假设文件为score.txt,内容如下:
$ cat score.txt
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62
#!/bin/awk -f
#运行前(初始化变量)
BEGIN{
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL
"
printf "------------------------------------
"
}
#运行中(循环运行每一条记录)
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d
", $1, $2, $3, $4, $5, $3+$4+$5
}
#运行后(输出运算后的变量结果)
END{
printf "-------------------------------------
"
printf " TOTAL:%10d %8d %8d
", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f
", math/NR, english/NR, computer/NR
}
$ awk -f cal.awk score.txt
NAME NO. MATH ENGLISH COMPUTER TOTAL
------------------------------------
Marry 2143 78 84 77 239
Jack 2321 66 78 45 189
Tom 2122 48 77 71 196
Mike 2537 87 97 95 279
Bob 2415 40 57 62 159
-------------------------------------
TOTAL: 319 393 350
AVERAGE: 63.80 78.60 70.00
1.6 awk是一门变成语言,支持条件判断、数组、循环等功能。所以我们也可以把awk理解成一个脚本语言解释器。
参考:https://blog.51cto.com/191226139/2060467
grep 、sed、awk被称为linux中的"三剑客"。
这三个"剑客"各有特长。
grep 适合单纯的查找或匹配文本
sed 适合编辑匹配到的文本
awk 适合格式化文本,对文本进行较复杂格式处理。报告生成器,格式化文本输出。
image
- awk程序通常由:BEGIN语句块、program、END语句块共3部分组成。
- program又可以细分为pattern和action。pattern决定动作语句何时触发及触发事件,例如+-*/,或者正则表达式,action是对满足指定条件数据进行处理,放在{}内指明。
- 记录:文件的每一行称为记录;
- 域:由分隔符分隔的字段,对于每个域标记为
$1, $2, ... $n,成为域标识。$0为所有域,也就是整条记录。而shell的$0表示文件名本身。 - 域分隔符变量:FS(field sign);
- awk的工作原理:BEGIN+pattern+END
- BEGIN:执行BEGIN{action;...}语句块中的语句;BEGIN语句块在awk开始从输入流中读取行之前被执行
- pattern:从文件或标准输入(stdin)读取一行,然后执行pattern{action}语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。如果不存在pattern,则默认执行
{print},即打印所有 - END:当读至输入流末尾时,执行END{action;...}。END语句块在awk从输入流中读取完所有的行之后即被执行。
2、cat命令
参考:linux命令大全
参考2:https://www.runoob.com/linux/linux-comm-cat.html
- cat命令用于连接文件并打印到标准输出设备上;
- 语法为:
cat [-Abn] [--help] [--version] -n表示由1开始对所有输出的行数编号;-b只是对与空白行不编号;-a表示显示所有;
- 语法为:
- 例如:
cat -n textfile1 > textfile2表示把textfile1的文档内容加上行号后输入textfile2这个文档里;
cat /dev/null > /etc/test.txt表示清空该文档中的内容;
cat img_file > /dev/fd0表示把ima_file写入到软盘中;
将多个文件内容合并到一个文件:参考:https://blog.csdn.net/Alvin_Lam/article/details/79123882
3、head命令
参考:https://blog.csdn.net/carolzhang8406/article/details/6112707
head命令用来查看具体文件的前面几行的内容,具体格式如下:head <filename>
我们可以通过head命令查看具体文件最初的几行内容,默认为前十行;如果想看前20行,则可以:
head -n 20 test.txt
4、tail命令
参考:https://www.runoob.com/linux/linux-comm-tail.html
tail命令可用于查看文件的尾部内容,又一个常用的参数-f常用于查阅正在改变的日志文件。
tail -f filename会把filename文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要filename更新就可以看到最新的文件内容。
tail -n 20 filename显示尾部20行,tail -c 10 filename显示最后10个字符;
5、sort命令
参考:https://www.runoob.com/linux/linux-comm-sort.html
- linux sort命令用于讲文本文件内容加以排序。sort可针对文本文件的内容,以行为单位来排序。
- 语法:
sort [-cdfmnr] 文件 -c表示检查文件是否已经按照顺序排序。-d表示排序时,处理英文字母、数字及空格字符外,忽略其他的字符。-m表示将几个排序好的文件进行合并。-n表示依照数值的大小排序,-r表示以相反的顺序来排序。
- 语法:
- 例如:
sort testfile表示在使用sort命令以默认的式对文件的行进行排序;
6、uniq命令
参考:https://www.runoob.com/linux/linux-comm-uniq.html
- linux uniq命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。
- 语法:
uniq [-cw] [输入文件] [输出文件] -c表示在每列旁边显示该行重复出现的次数;-w表示指定要比较的字符。-d和--repeated表示仅显示重复出现的行列,-u和--unique表示仅显示出现一次的行列,不加参数时默认为显示所有。
- 语法:
- 例如:
uniq testfile.txt可以将txt文件中相同的行删除;
uniq -c testfile表示检查文件并删除文件中重复出现的行,并在行首显示该行重复出现的次数;
但是当重复的行并不相邻时,uniq命令是不起作用的,需要和sort合并使用,如下:sort testfile1 | uniq;
7、wc命令
参考:https://www.runoob.com/linux/linux-comm-wc.html
- Linux wc命令用于计算字数。利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
- 语法:
wc [-clw] 文件,-c表示只显示Bytes数,-l表示只显示行数,-w表示只显示字数;
- 语法:
- 例如:
$ wc testfile # testfile文件的统计信息
3 92 598 testfile # testfile文件的行数为3、单词数92、字节数598
8、grep命令
参考:https://www.runoob.com/linux/linux-comm-grep.html
- Linux grep 命令用于查找文件里符合条件的字符串。
- 语法为:
grep [字符串] [文件]
- 语法为:
- 例如:
grep test *file表示在在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。
grep test test*表示查找前缀有“test”的文件包含“test”字符串的文件
grep -r update /etc/acpi表示以递归的方式查找符合条件的文件
9、join命令
参考:https://www.runoob.com/linux/linux-comm-join.html
- Linux join命令用于将两个文件中,指定栏位内容相同的行连接起来。找出两个文件中,指定栏位内容相同的行,并加以合并,再输出到标准输出设备。
- 语法:
join [文件1] [文件2] -v跟-a相同,但是只显示文件中没有相同栏位的行;-a除了显示原来的输出内容之外,还显示指令文件中没有相同栏位的行。
- 语法:
- 例如:
(1)join testfile_1 testfile_2表示将两个文件中指定字段的内容相同的行连接起来;
文件testfile_1的内容为:
Hello 95
Linux 85
test 30
文件testfile_2的内容为:
Hello 2005
Linux 2009
test 2006
join testfile_1 testfile_2之后输出的为
Hello 95 2005
Linux 85 2009
test 30 2006
(2)join -v 1 123.txt 124.txt
参考:https://www.cnblogs.com/mfryf/p/3402200.html
123.txt文件为
aa 1 2
bb 2 3
cc 4 6
dd 3 3
124.txt文件为:
aa 2 1
bb 8 2
ff 2 4
cc 4 4
dd 5 5
join -v 1 123.txt 124.txt的结果为:
cc 4 6
dd 3 3
join -a 1 123.txt 124.txt
aa 1 2 2 1
bb 2 3 8 2
cc 4 6
dd 3 3
10、sed命令
参考:https://www.runoob.com/linux/linux-comm-sed.html
- Linux sed 命令是利用脚本来处理文本文件。Sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
- 语法:
sed [-e] [script文件] [文本文件]
- 语法:
- 例如:
sed -e 4a ewLine testfile表示在testfile文件的第四行后添加一行,并将结果输出到标准输出。
11、set命令
参考:https://www.runoob.com/linux/linux-comm-set.html
- Linux set命令用于设置shell。set指令能设置所使用shell的执行方式,可依照不同的需求来做设置。
- 语法:
set [-v],表示执行指令后,会先显示该指令及所下的参数。
- 语法:
12、find命令
参考:https://www.runoob.com/linux/linux-comm-find.html
- Linux find命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
- 语法:
find path -option 字符串
- 语法:
- 例如:
`find . -name "*.c"表示将目前目录及其子目录下所有延伸档名是c的文件列出来。不会讲查找过程显示出来,因此速度相对要快一点。
13、Linux下两个文件求交集、并集和差集
参考:https://www.cnblogs.com/molong1208/p/5358509.html
(1)交集
sort a.txt b.txt | uniq -d
(2)并集
sort a.txt b.txt | uniq
(3)差集
a.txt - b.txt
sort a.txt b.txt | uniq -u
b.txt - a.txt
sort b.txt a.txt a.txt | uniq -u
14、linux中shell变量 $#, $@, $0, $1, $2的含义解释
参考:https://www.cnblogs.com/fhefh/archive/2011/04/15/2017613.html
$$:shell本身的PID;$!:shell最后运行后台Process的PID;$?:最后运行的命令的结束代码;$-:使用Set命令设定的Flag一览 ;$*:所有参数列表。如"$*"用「"」括起来的情况、以"$1 $2 … $n"的形式输出所有参数。$@:所有参数列表。如"$@"用「"」括起来的情况、以"$1" "(2" … ")n" 的形式输出所有参数。$#:添加到Shell的参数个数 ;$0:shell本身的文件名$1~$n:添加到shell的各参数值。$1是第一参数、$2是第2参数。