前言
[classic_tong: https://www.cnblogs.com/hugetong/p/14386531.html]
围绕着 [openssl] openssl asynch_mode 使用libasan时的OOM问题
以及 https://github.com/intel/QAT_Engine/issues/178 的处理过程,先后尝试了几个内存问题检测的工具和方法,
现将其总结讨论在本文中。
概述
内存问题检测的工具和方法有很多,大概就分两类,一类是编译期介入的,一类是运行时介入的。本文仅有限讨论如下几种:
gperftools,valgrind,libasan,DIY,systemtap,ptrace
比较
借libasan的一个表格,进行一下比较:
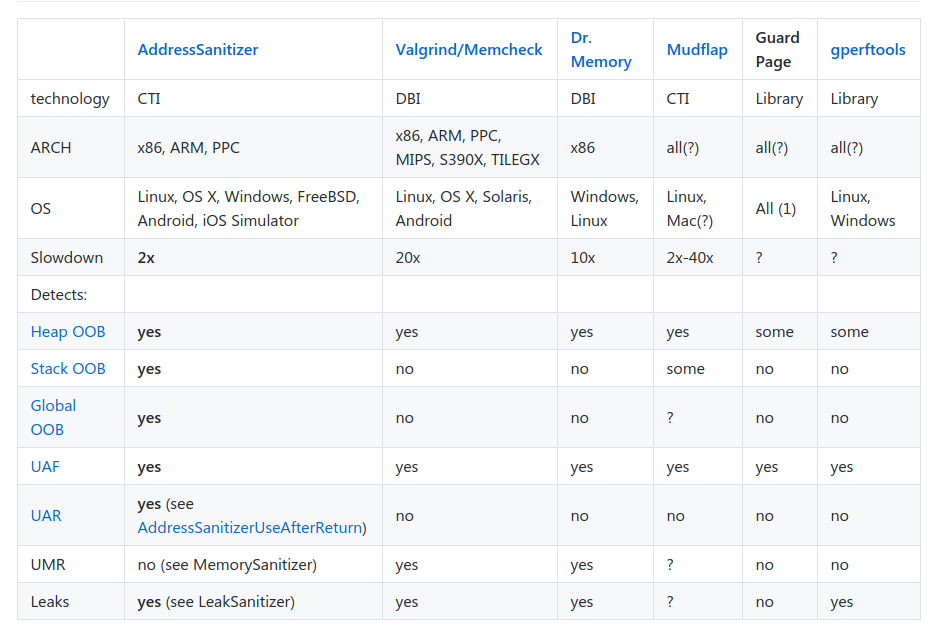
原始表格见: https://github.com/google/sanitizers/wiki/AddressSanitizerComparisonOfMemoryTools
gperftools
是一组google的工具集。我们现在讨论的是其中的一个工具,叫做heap checker。 它依赖tcmalloc,在运行时生效。
有两个办法使heap checker生效。第一,在编译连接时加入-ltcmalloc。第二,在运行是使用LD_PRELOAD。显然在不使用tcmalloc的时候,后者更方便。
heap checker的原理是hook掉标准的malloc和free。然后在里边进行内存的检测。
简单的使用步骤:
1. 安装
yum install gperftools-libs-2.6.1-1.el7.x86_64.rpm
2. 运行
export LD_PRELOAD=/usr/lib64/libtcmalloc.so.4.4.5 export HEAPCHECK=normal HEAPPROFILE="/root/debug/src/test/heapprof.log" ./async
运行后,内存情况,会被周期打印到这个日志文件里.
文档中包含更详细的用法,以及更多配置。
主页:https://github.com/gperftools/gperftools
文档页:https://gperftools.github.io/gperftools/heap_checker.html
valgrind
从我的理解,valgrind就是个模拟器。被调试程序无感的跑在它的上面。程序的所有的读写与指令都写入到模拟器上去。基于这种运行模式
它拥有以下几个特点:
1. 运行速度慢。程序运行速度会下降40倍。所以很多以前出现的问题,可能由于速度变慢而不出现了。
2. 功能强大。因为作为模拟器跑着程序下面。
3. 不准。会有假阳性。因为它把程序看做黑盒,通过对我行为反推。所以会假阳性。( false positive )
使用
valgrind的用法算是最简单的了。把valgrind及其参数放置在本测试程序的前面执行。如下:
[root@T9 ~]# valgrind --log-file=/tmp/valgrind.log --trace-children=yes --read-inline-info=yes --read-var-info=yes -v ./a.out Segmentation fault [root@T9 ~]# ll /tmp/ -rw-r--r-- 1 root root 5258 Jan 25 16:07 valgrind.log -rw------- 1 root root 8470528 Jan 25 16:06 valgrind.log.core.3650 -rw------- 1 root root 8470528 Jan 25 16:07 valgrind.log.core.3658
参数:
1 当使用--log-file参数的时候, valgrind的输出结果将写着这个地方。这对daemon程序的调试十分有用。另外,如果发生了coredump的话,core文件会写着与log文件同一个位置.
不过在我的实践中,这个coredump并不能正常的使用gdb打开,可能需要特殊的方式,目前还不会用。
2 valgrind的功能不仅仅局限于内存检测。它实际上是一组工具集。用--tool=memcheck指定,也可以不指定,因为memcheck是默认工具。
文档:https://valgrind.org/docs/manual/quick-start.html https://valgrind.org/docs/manual/manual.html
这文档,清晰又好读。建议读一下。
libasan
LLVM是一个编译器后端,一般与clang作为前端配合。另外,gcc也可以作为llvm的前端,或者说gcc使用llvm作为其后端。见:https://dragonegg.llvm.org/
什么前端后端?见:https://blog.csdn.net/xhhjin/article/details/81164076
现在进入正题,libasan是llvm的一个组成部分,由google开发。gcc里边有对用的clone。但是只有基本的clone,很多高级功能还不支持。
gcc里的用法:(以下内容仅在gcc4.8.5测试过)
用llvm编译的话,不用单装任何东西,直接用就可以。代码在这个地方:https://github.com/google/sanitizers
gcc sanitize的代码在gcc里边:https://github.com/google/sanitizers。CentOS里作为一个单独的库进行发布,需要单独安装,就是libasan,:
[root@T9 ~]# rpm -qa |grep libasan libasan-static-4.8.5-44.el7.x86_64 libasan-4.8.5-44.el7.x86_64
静态方法
CFLAGS+=-fsanitize=address -fno-omit-frame-pointer -I /root/debug/include/ -static-libasan LDFLAGS+= -fsanitize=address -fno-omit-frame-pointer -lssl -lcrypto -static-libasan
动态方法
CFLAGS+=-fsanitize=address -fno-omit-frame-pointer LDFLAGS+=-fsanitize=address -fno-omit-frame-pointer LDFLAGS+= -lasan
注意:
1. 编译和链接选项都要有这两“-fsanitize=address -fno-omit-frame-pointer”, 不然会在运行时报错。至少在我使用nginx+openssl时,是这样的。
2. 如果openssl是带着libasan选项编译的。那么因为nginx link了openssl的so,所以也要使用libasan的选项编译。不然,一样会运行时报错。
参数和选项
可以配各种参数,这些参数可以在libasan的文档里找到,但是gcc实现里好不好用,还得试试才知道。我用过的几个如下所示
配置日志的方法
1. 环境变量
export ASAN_OPTIONS="log_path=asan.log" ./mytests
注: 在main函数开头,使用setenv设置该环境变量,并不好用.
2. 代码写死
#include <sanitizer/asan_interface.h> __sanitizer_set_report_path("/tmp/asan.log")
3 默认情况全部写入标准错误
参考: https://stackoverflow.com/questions/39686628/how-to-set-asan-ubsan-reporting-output
其他选项
多个用冒号分隔: ASAN_OPTIONS=verbosity=1:malloc_context_size=20 ./a.out
https://github.com/google/sanitizers/wiki/AddressSanitizerFlags
https://github.com/google/sanitizers/wiki/SanitizerCommonFlags
DIY
就是说,自己写程序检测内存问题。主要两方面。
1. 堆内存的泄露
自己实现一个hash表,new的时候插入,free的时候删除。可以同时带上调用栈信息。
最后,程序结束的时候,hash表里剩下的就是内存泄露的。下面是一个我的例子。
https://github.com/tony-caotong/knickknack/blob/master/examples/mem_dbg/mem_dbg.c
2. 堆内存的越界
堆内存的越界检测原理是,在内存的开始和结尾各自多申请一小段,比如前后各4字节。在new时写入特定内容,比如1234
在free时检测是否依然是1234. 如果不是,说头越界或者尾越界了。
更多详细的方法,可以参考libasan的实现,https://github.com/google/sanitizers/wiki/AddressSanitizerAlgorithm
该场景适用于:1, 内存池的泄露检测。2,非标准api申请的内存,比如intel qatdriver的连续内存管理模块就是这样,直接使用内核module分配。
systemtap
这个也属于DIY的范畴,只不过是通过systemtap机制实现。
有关systemtap的简单背景内容,请阅读一下,再回来:[optimize]使用systemtap调试用户态程序
如该文所阐述的方法,我们可以hook一个脚本到被调试程序中,在该脚本中实现上一小结的hash表逻辑,完成同样功能。
与前面方法的对比,有两个异同:
1. 使用systemtap,可以在运行时介入,原程序无感,不需要重新编译,不需要中断运行。随时修改随时上。
2. systemtap的语法脚本有学习门槛。
所以,更推荐用systemtap,能用就用。
另外,提到systemtap就不得不提Dtrace,Dtrace更高级。
DTrace 跟 systemtap功能是一样的. linux内核4.9之后支持DTrace, linux内核3.5之后支持systemtap
ptrace
有些场景,比如某个变量指向的内存,总是被写坏。但是用以上方法又没有发现问题。可以用gdb watchpoint。
但是并不是所有环境都可以方便的使用gdb。我们还可以使用gdb的底层工具ptrace,自行编码实现调试需求。
watchpoint是什么(我也没搞懂):https://sourceware.org/gdb/current/onlinedocs/gdb/Breakpoints.html#Breakpoints
ptrace的文档:https://man7.org/linux/man-pages/man2/ptrace.2.html
更多
还有更高级的,eBPF:http://www.brendangregg.com/blog/2019-01-01/learn-ebpf-tracing.html