引言:
在前面几篇博客介绍中,我们已经了解到fastdfs单机搭建和关于http请求访问的fastdfs+nginx的实现。现在还存在的问题,当我们上传同一个文件时,没有给我们去重,依然上传成功,返回了一个上传标识。这种情况是我们不想看到的,所以,怎么实现文件的去重,作者余庆给我们提供了一种新的技术,fastdht
介绍:
FastDHT是一个基于键值对(Key Value Pair)的高效的分布式Hash系统,她可以用来存储大量的Key Value Pair,比如可以用来存储文件名映射表、session数据、用户相关数据等等。
FastDHT服务器端底层存储采用Berkeley DB,支持大数据量;网络IO采用libevent,支持大并发连接。FastDHT只用到了BDB最基本的存储功能,数据同步是自己实现的,采用了binlog的复制方式
由客户端决定应该选择哪台服务器,为例避免查表,应该根据key的hash code来选择服务器,算法描述如下:
1. 计算出key的hash值(hash_code)
2. group_index = hash_code % group_count
3. new_hash_code = hash_code高16位和低16位互换
4. server_index = new_hash_code % 组内server_count
计算server_index和group_index时使用了不同的hash code,是因为如果group_count和组内server_count相等,例如都等于2,那么对于一个组来说,任何key值都将选中其中一台固定的服务器(server_index == group_index)。
FastDHT中,key由三部分组成:namespace、object ID和key name。这个设计和数据库的层级划分相似:namespace对应database,object Id对应table,而key对应字段。引入namespace的目的是解决多个使用者(如:应用或产品)之间可能存在的数据冲突问题;引入object Id是便于对object相关的数据(如用户资料)进行组织和管理,以提高整体性能。引入namespace和object ID使得系统具有更大的灵活性,在实际使用中,这两个字段可以设置为空值。在计算key的hash code时,如果namespace和object ID不为空,将这二者合并起来作为hash函数的输入;否则将key作为hash函数的输入。
系统扩容时,为了避免重新进行hash分布(rehash),FastDHT引入了逻辑分组的概念。一个物理分组对应一组服务器,一组服务器(物理分组)上可以有多个逻辑分组。FastDHT的一个服务进程支持多个逻辑分组,每个组对应一个BDB的数据文件。这样的设计为以后的扩容提供了便利。在初期估算出今后需要的大致分组数目(逻辑分组数),然后将逻辑分组对应到物理分组中。扩容时,将一个或多个逻辑分组迁移到新增的物理分组上,只需要拷贝对应的BDB数据文件,并修改相应的配置文件,重启服务器端和客户端程序即可。
FastDHT支持超时(timeout),每个key都有超时属性。这样可以使用FastDHT来存储session数据,比传统的数据库存储方案更加高效和简洁。
原理:

安装:
1.下载fastdht和db-18.1.32.tar.gz
2.上传/root/fastdfs/ 并解压
3. 安装BerkeleyDB
在步骤2后。 cd /db-18.1.32 cd build_unix/ ./../dist/configure make && make install
4. 安装fastdht
cd fastdfs/fastdht-master/
./make.sh && ./make.sh install
5. 修改fastdht的配置文件
mkdir /data/fastdht --创建一个文件夹,用来保存fastdht的日志文件
cd /etc/fdht/ -- 切换到fdht配置文件 vi fastd.conf -- 编辑配置文件 base_path=/data/fastdht -- 修改成上面创建的文件夹 vi fdht_servers.conf -- 在修改fdht_severs.conf 将来配置fdht集群的,后续详细介绍。本节只搭建环境 group_count = 1 -- 修改成1 group0 = 192.168.236.130:11411 --修改本节fdht服务器主机地址
6.修改storage.conf
check_file_duplicate=1 -- 修改成1 检测是否已经上传,如果已上传就生成一个链接指向该文件,没有,就上传 keep_alive=1 -- 修改成1 意思是保持长连接 #include /etc/fdht/fdht_servers.conf --指定配置文件 注意。#必须加
7.启动服务:
/usr/local/bin/fdhtd /etc/fdht/fdht -- 启动fdht 服务
fdfs_trackerd /etc/fdfs/tracker.conf restart --重启tracker服务
fdfs_storaged /etc/fdfs/storage.conf restart --重启storage服务
查询服务启动是否完成:

到这,fdht和fastdfs就集成完了,大家注意上面搭建细节
8.测试:
我连续上传同一个文件两次,效果如下:可看到两次返回的标识是不一样的,那实际文件保存情况呢。
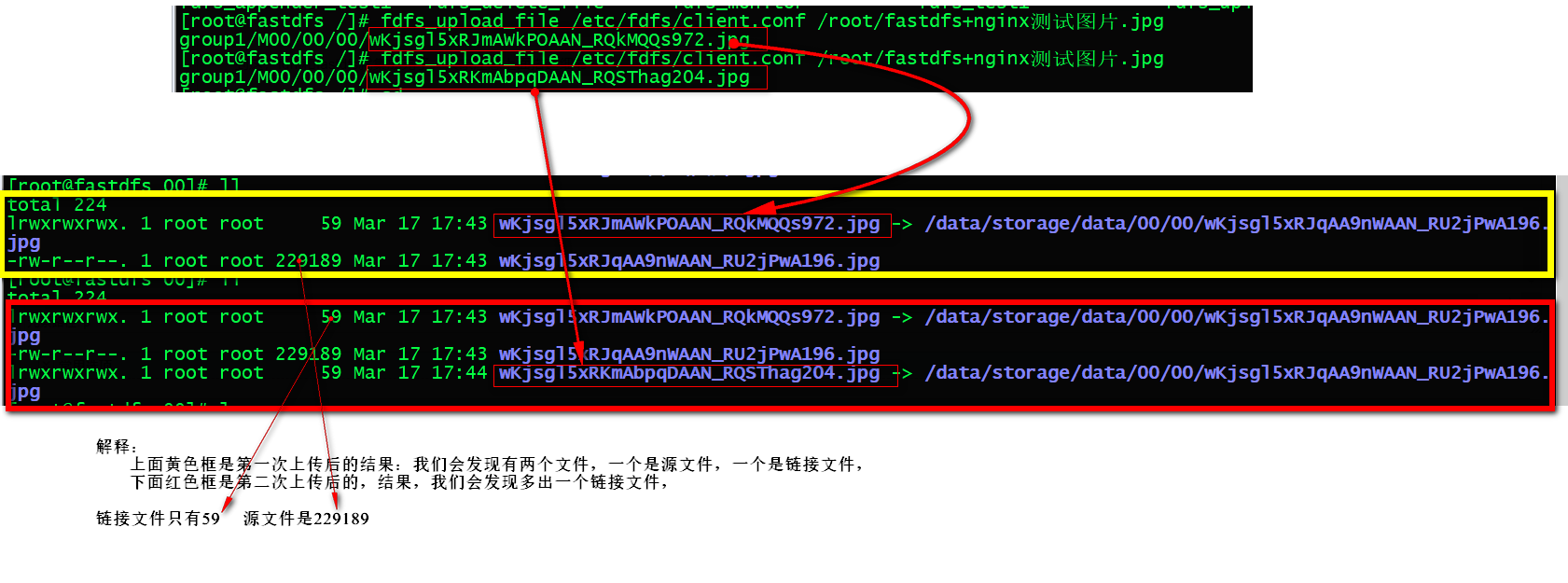
有兴趣的可以搭建一下,这样印象才会深一点