首先我们要准备如下环境及软件:
win7(64位) cygwin 1.7.9-1 jdk-6u25-windows-x64.zip hadoop-0.20.2.tar.gz
1.在win7系统上正常安装jdk,同时注意设置好java环境的变量:
主要的变量包括:JAVA_HOME,PATH,CLASSPATH
(不会设置的请自备梯子)
2.接下来是安装Hadoop,我目前安装的版本为0.20.2版本,为了方便,
我暂时是直接放到了cygwin64的/home目录下(正常情况下,请放在/usr目录下),
并使用tar命令进行解压操作。
lenovo@lenovo-PC /home $ tar -zxvf hadoop-0.20.2.tar.gz
3.光安装完Hadoop是不够的,还需要一些简单的配置工作,主要的配置文件有4个,
它们位于Hadoop的安装目录的conf子目录下,分别是:
hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml
下面将是如何修改的详细部分:
(1) 修改hadoop-env.sh文件:
这步比较简单,只需要将JAVA_HOME 修改成JDK 的安装目录即可:
红色标出的是修改后的样子。
# Set Hadoop-specific environment variables here. # The only required environment variable is JAVA_HOME. All others are # optional. When running a distributed configuration it is best to # set JAVA_HOME in this file, so that it is correctly defined on # remote nodes. # The java implementation to use. Required. export JAVA_HOME=/cygdrive/d/android/java/jdk1.7.0_15 # Extra Java CLASSPATH elements. Optional. # export HADOOP_CLASSPATH= # The maximum amount of heap to use, in MB. Default is 1000. # export HADOOP_HEAPSIZE=2000 # Extra Java runtime options. Empty by default. # export HADOOP_OPTS=-server # Command specific options appended to HADOOP_OPTS when specified export HADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_NAMENODE_OPTS" export HADOOP_SECONDARYNAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_SECONDARYNAMENODE_OPTS" export HADOOP_DATANODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_DATANODE_OPTS" export HADOOP_BALANCER_OPTS="-Dcom.sun.management.jmxremote $HADOOP_BALANCER_OPTS" export HADOOP_JOBTRACKER_OPTS="-Dcom.sun.management.jmxremote $HADOOP_JOBTRACKER_OPTS" # export HADOOP_TASKTRACKER_OPTS= # The following applies to multiple commands (fs, dfs, fsck, distcp etc) # export HADOOP_CLIENT_OPTS # Extra ssh options. Empty by default. # export HADOOP_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HADOOP_CONF_DIR" # Where log files are stored. $HADOOP_HOME/logs by default. # export HADOOP_LOG_DIR=${HADOOP_HOME}/logs # File naming remote slave hosts. $HADOOP_HOME/conf/slaves by default. # export HADOOP_SLAVES=${HADOOP_HOME}/conf/slaves # host:path where hadoop code should be rsync'd from. Unset by default. # export HADOOP_MASTER=master:/home/$USER/src/hadoop # Seconds to sleep between slave commands. Unset by default. This # can be useful in large clusters, where, e.g., slave rsyncs can # otherwise arrive faster than the master can service them. # export HADOOP_SLAVE_SLEEP=0.1 # The directory where pid files are stored. /tmp by default. # export HADOOP_PID_DIR=/var/hadoop/pids # A string representing this instance of hadoop. $USER by default. # export HADOOP_IDENT_STRING=$USER # The scheduling priority for daemon processes. See 'man nice'. # export HADOOP_NICENESS=10
(注意:这里的路径不能是windows 风格的目录d:javajdk1.7.0_15,而是LINUX 风格/cygdrive/d/java/jdk1.7.0_15)
(2) 修改core-site.xml:
红色标出的是增加的代码。
(3)修改hdfs-site.xml(指定副本为1)
红色标出的是增加的代码。
(4) 修改mapred-site.xml (指定jobtracker)
红色标出的是增加的代码。
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
4.验证安装是否成功,并运行Hadoop
(1) 验证安装
(2) 格式化并启动Hadoop
$ bin/hadoop namenode –format 15/07/09 10:47:51 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = lenovo-PC/192.168.41.1 STARTUP_MSG: args = [▒Cformat] STARTUP_MSG: version = 0.20.2 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20 -r 911707; compiled by 'chrisdo' on Fri Feb 19 08:07:34 UTC 2010 ************************************************************/ Usage: java NameNode [-format] | [-upgrade] | [-rollback] | [-finalize] | [-importCheckpoint] 15/07/09 10:47:51 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at lenovo-PC/192.168.41.1 ************************************************************/
$ bin/start-all.sh starting namenode, logging to /home/hadoop-0.20.2/bin/../logs/hadoop-lenovo-namenode-lenovo-PC.out localhost: /home/hadoop-0.20.2/bin/slaves.sh: line 61: ssh: command not found localhost: /home/hadoop-0.20.2/bin/slaves.sh: line 61: ssh: command not found starting jobtracker, logging to /home/hadoop-0.20.2/bin/../logs/hadoop-lenovo-jobtracker-lenovo-PC.out localhost: /home/hadoop-0.20.2/bin/slaves.sh: line 61: ssh: command not found
(3) 查看Hadoop
命令行查看:
(注意:win7下cygwin中DateNode和TaskTracker进程是无法显示的,应该是cygwin的问题)
现在可以网页查看效果了:
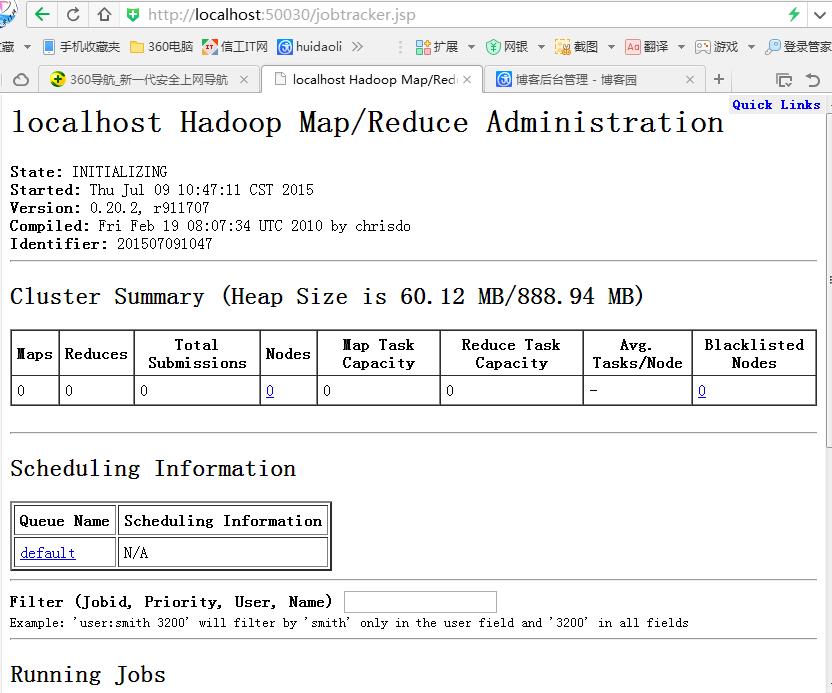
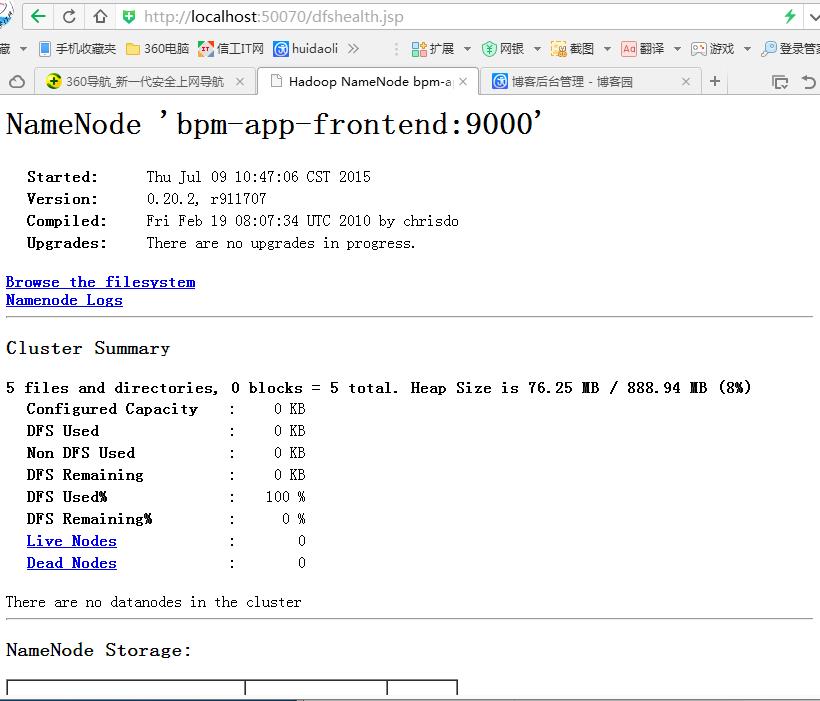
(4) 关闭Hadoop
bin/stop-all.sh
版权申明:本文有部分内容是参考网上的资料,如有疑问请联系,谢谢合作。