基础
1、通用设计方法
-
Scale-out(横向扩展):分而治之是一种常见的高并发系统设计方法,采用分布式部署的方式把流量分流开,让每个服务器都承担一部分并发和流量。
-
缓存:使用缓存来提高系统的性能,就好比用“拓宽河道”的方式抵抗高并发大流量的冲击。
-
异步:在某些场景下,未处理完成之前,我们可以让请求先返回,在数据准备好之后再通知请求方,这样可以在单位时间内处理更多的请求。
2、架构分层
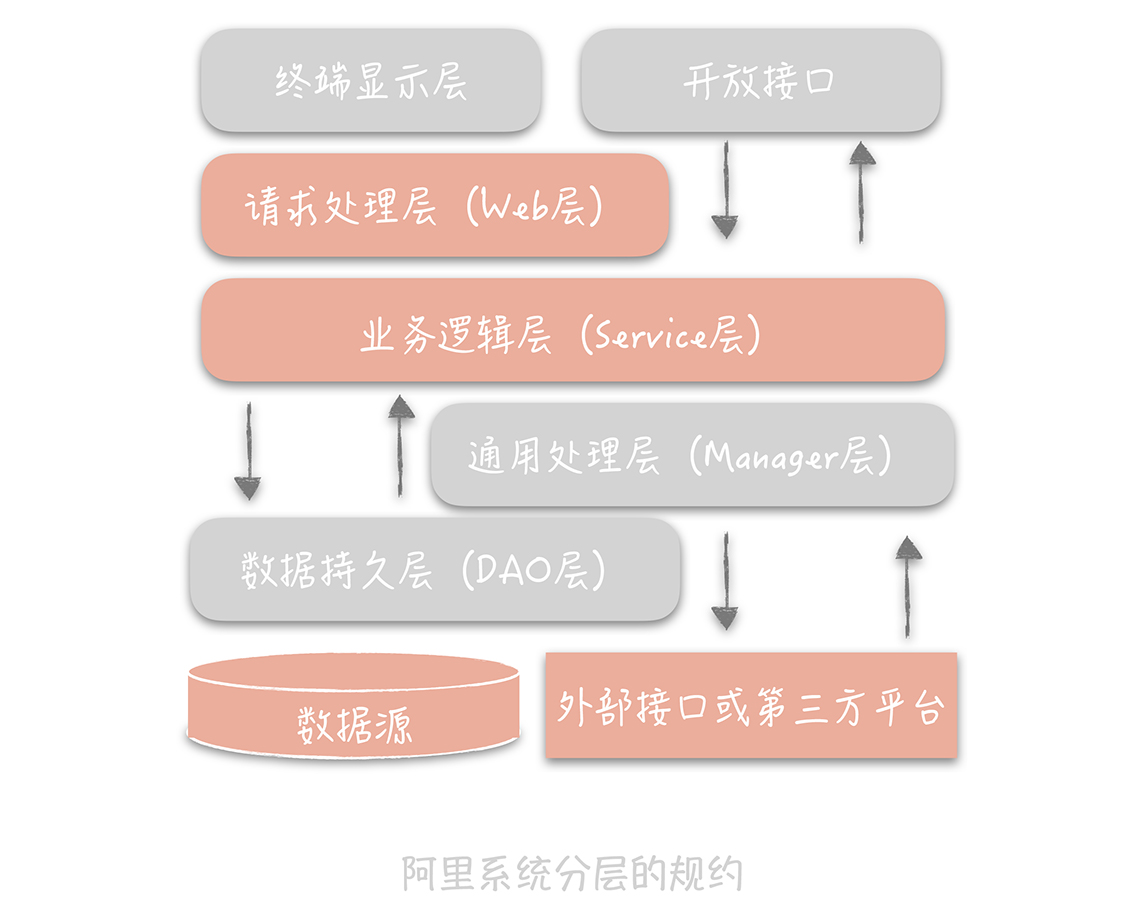
https://yq.aliyun.com/articles/69327
高并发系统3个目标: 高性能、高可用、可扩展
3、 高性能

从用户使用体验的角度来看,200ms 是第一个分界点:接口的响应时间在 200ms 之内,用户是感觉不到延迟的,就像是瞬时发生的一样。而 1s 是另外一个分界点:接口的响应时间在 1s 之内时,虽然用户可以感受到一些延迟,但却是可以接受的,超过 1s 之后用户就会有明显等待的感觉,等待时间越长,用户的使用体验就越差。所以,健康系统的 99 分位值的响应时间通常需要控制在 200ms 之内,而不超过 1s 的请求占比要在 99.99% 以上。
吞吐量 = 并发进程数 / 响应时间
增加系统处理核心数、减少响应时间
4、高可用
度量指标
MTBF(Mean Time Between Failure)是平均故障间隔的意思,代表两次故障的间隔时间,也就是系统正常运转的平均时间。这个时间越长,系统稳定性越高。
MTTR(Mean Time To Repair)表示故障的平均恢复时间,也可以理解为平均故障时间。这个值越小,故障对于用户的影响越小。
Availability = MTBF / (MTBF + MTTR)
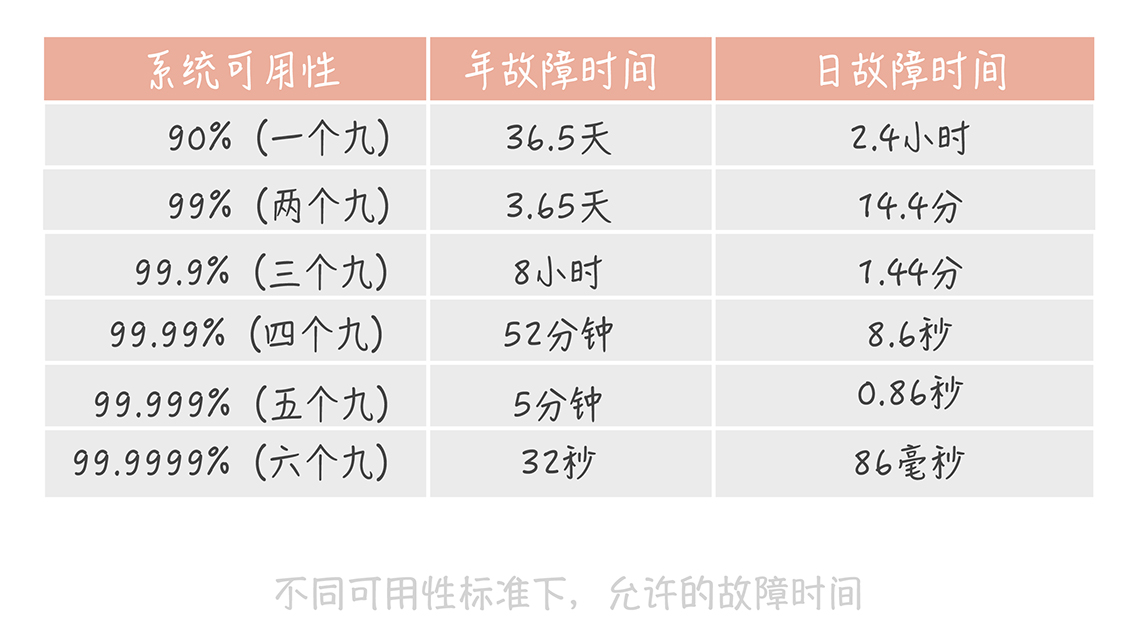
一般来说,我们的核心业务系统的可用性,需要达到四个九,非核心系统的可用性最多容忍到三个九。
设计思路:
系统设计 - “Design for failure”
failover(故障转移):
1. 是在完全对等的节点之间做 failover。
2. 是在不对等的节点之间,即系统中存在主节点也存在备节点。
超时控制
99% 的响应时间
降级
保证核心服务的稳定而牺牲非核心服务的做法
限流
通过对并发的请求进行限速来保护系统
系统运维:
灰度发布、故障演练
5、可扩展
拆分 (方式 水平、垂直)
存储层
业务层
演进-数据库:
池化技术(数据库、线程池)
依据一些云厂商的 Benchmark 的结果,在 4 核 8G 的机器上运 MySQL 5.7 时,大概可以支撑 500 的 TPS 和 10000 的 QPS
主从分离

分库分表
垂直:业务
水平 :属性字段
演进-缓存:
NoSql
Redis 、 Hbase 、 mongodb
缓存策略
Cache Aside(旁路缓存)策略
Read/Write Through
Write Back(写回)策略
你需要关注缓存命中率这个指标(缓存命中率 = 命中缓存的请求数 / 总请求数)。一般来说,在你的电商系统中,核心缓存的命中率需要维持在 99% 甚至是 99.9%,哪怕下降 1%,系统都会遭受毁灭性的打击。
缓存高可用方案
客户端、中间层、服务端
常用一致性hash
缺点
-
缓存节点在圆环上分布不平均,会造成部分缓存节点的压力较大;当某个节点故障时,这个节点所要承担的所有访问都会被顺移到另一个节点上,会对后面这个节点造成压力。严重的会导致雪崩!!! -- 虚拟节点
-
一致性 Hash 算法的脏数据问题。 -- 设置过期时间、减少节点个数
缓存穿透
回种空值
布隆过滤器(存在误判、不支持删除)
CDN

演进-消息队列:
解耦、异步、消峰

消息丢失
网络抖动处理:重发
消息队列服务器宕机:集群
消息重复:使用唯一 ID 保证消息唯一性。
kafka 生产端设置ack
演进-分布式服务:
微服务改造:
1 高内聚低耦合
2 粒度 先粗后细
3 边迭代边拆分
4 接口定义可扩展
PRC框架
1 高内聚低耦合
2 粒度 先粗后细
3 边迭代边拆分
4 接口定义可扩展
RPC框架考虑两个问题:
1 网络传输 - 多路复用
IO模型 两个阶段
请求(等待资源) 阻塞非阻塞
获取(使用资源) 同步异步
2 序列化
JSON protobuf thrift
注册中心
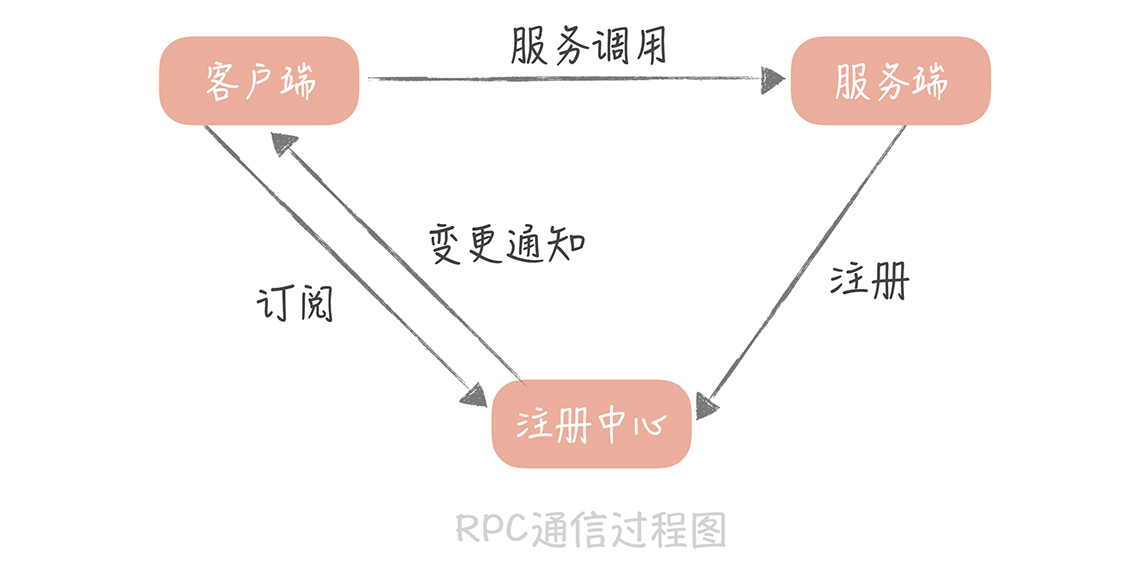
分布式trace
traceid spanid
负载均衡
静态: 不参考后端服务的状态 轮训、带权重轮训
动态: 参考后端服务状态 ,选择负载最小、资源最空闲的服务
网关
架构模式,将一些服务共有的功能整合在一起,独立部署为单独的一层,解决服务治理的问题
入口、出口
性能扩展性:使用多路IO复用和线程池并发处理
多机房部署:
问题 数据延迟
同城双活: 写入跨机房、读取同机房
异地多活:异步数据同步
Service Mesh
SideCar
istio 数据、控制
演进-维护:
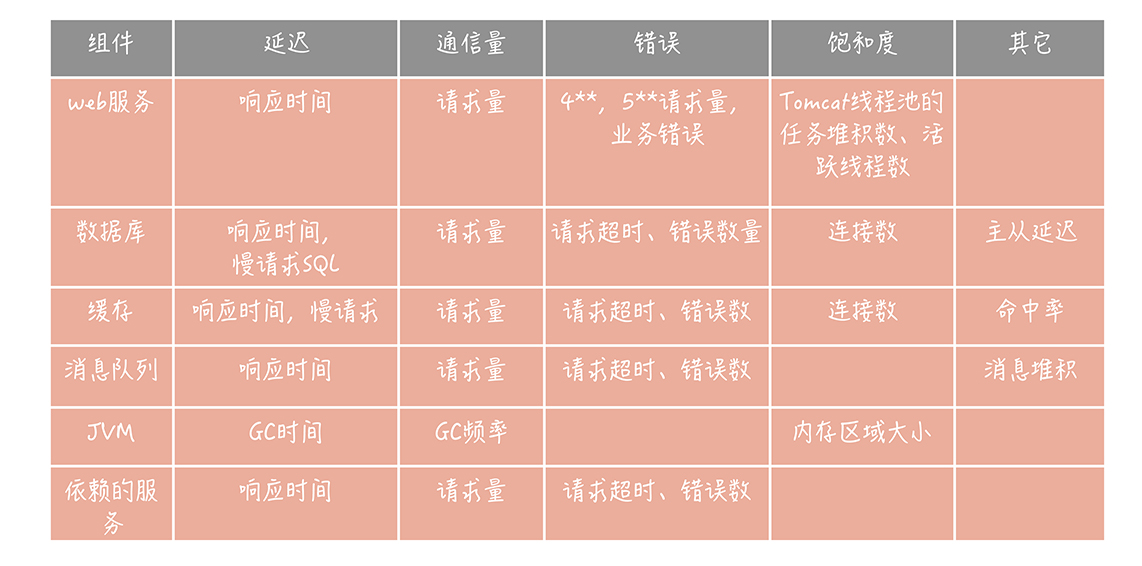
服务端监控:
Google Four Golden Signals:
延迟 响应时间
通信 吞吐量
错误 系统错误
饱和度 资源使用 cpu 内存 io
压测
流程copy、流量染色、影子库、监控熔断
配置中心
存储:
变更通知:轮训-基于md5 长链接
高可用 : 多级缓存 内存 + 文件 降级方案
非核心系统故障- 熔断降级
断路器: 打开 半打开 关闭
降级:
读: 降级数据、降频
写: 异步写
限流:
计数
滑动窗口
漏桶:流量整形
令牌桶:突增流量
演进-实战:
实战
参考:
提纲
