声明:这是一篇超级严肃的技术文章,请本着学习交流的态度阅读,谢谢!
一、网易商品评论爬取
1、评论分析
进入到网易严选官网,搜索“文胸”后,先随便点进一个商品。

在商品页面,打开 Chrome 的控制台,切换至 Network 页,再把商品页面切换到评价标签下,选择一个评论文字,如“还没穿,也不知道合不合身”,在 Network 中搜索。
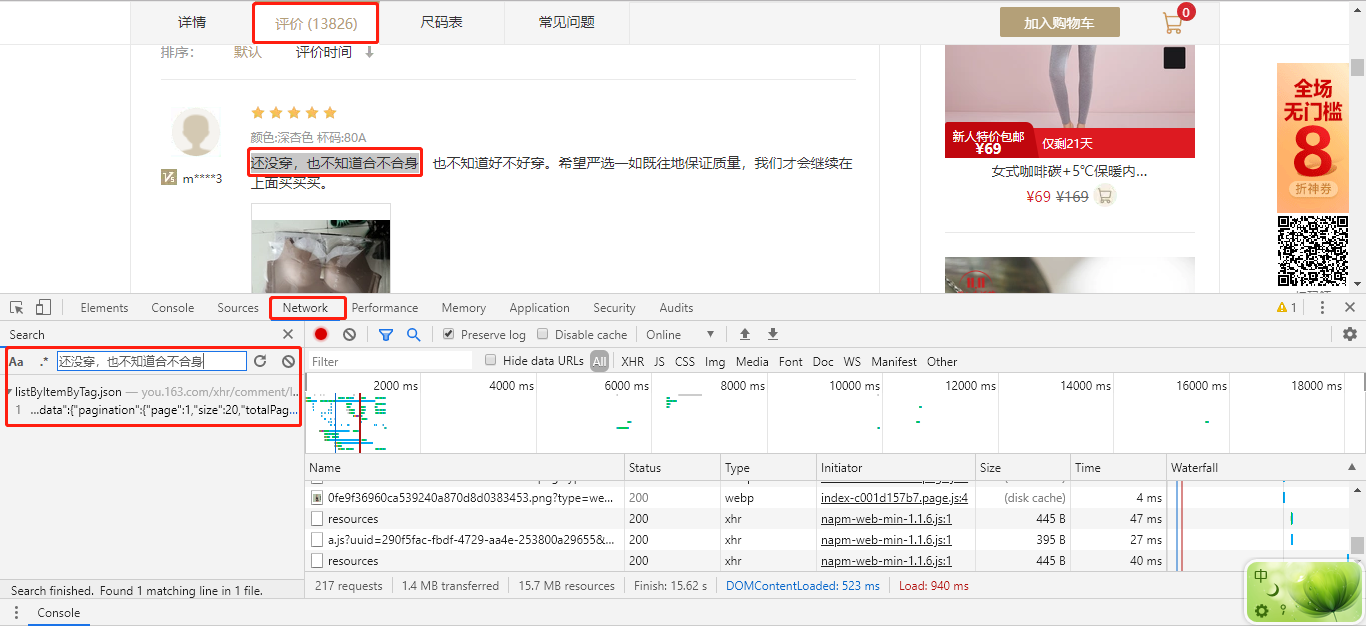
可以发现,评论文字是通过 listByItemByTag.json 传递过来的,点击进入该请求,并拷贝出该请求的 URL:
http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page=1&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0
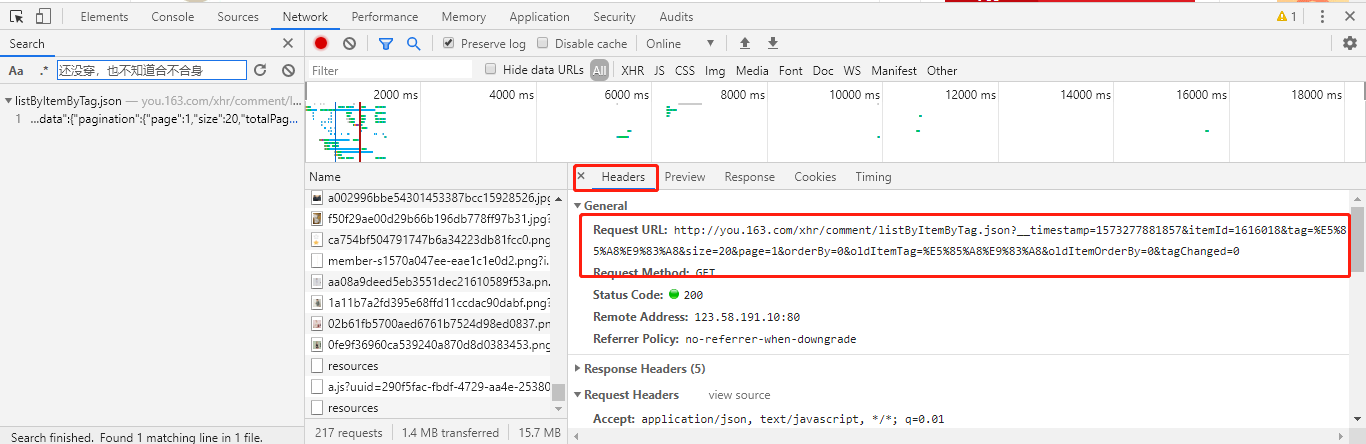
经过上面的步骤,我们就轻松的获取到了评论的请求接口。且知道返回的数据是个json,评论内容都在content中。
2、爬取数据
拿到评论数据接口url之后,我们就可以开始写代码抓取数据了。一般我们会先尝试抓取一条数据,成功之后,我们再去分析如何实现大量抓取。
import requests def spider_comment(): '''爬取网易严选评论数据''' kv = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36' } url = '
http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page=1&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0
' try: result = requests.get(url, headers=kv) result.raise_for_status() # 返回状态码。如果返回4XX或者5XX直接执行except print(result.text) except Exception as e: print(e)
获取到如图所示的数据

3、数据提取
经过上面的分析以及爬取的结果不难发现发现,返回的是json数据。
import json import requests def spider_comment(): '''爬取网易严选评论数据''' kv = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36' } url = '
http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page=1&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0
' try: result = requests.get(url, headers=kv) result.raise_for_status() # 返回状态码。如果返回4XX或者5XX直接执行except result_dict = json.loads(result.text) # 将json转换为字典 result_json_comments = result_dict['data']['commentList'] # print(result_json_comments) for i in result_json_comments: # 真正的评论在'content print(i['content']) except Exception as e: print(e) if __name__ == '__main__': spider_comment()
4.数据保存
数据提取后我们需要将他们保存起来,一般保存数据的格式主要有:文件、数据库、内存这三大类。今天我们就将数据保存为txt文件格式,因为操作文件相对简单同时也能满足我们的后续数据分析的需求。
import json import requests comment_file_path = '163_comment.txt' def spider_comment(): '''爬取网易严选评论数据''' kv = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36' } url = '
http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page=1&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0
' try: result = requests.get(url, headers=kv) result.raise_for_status() # 返回状态码。如果返回4XX或者5XX直接执行except result_dict = json.loads(result.text) # 将json转换为字典 result_json_comments = result_dict['data']['commentList'] # print(result_json_comments) for i in result_json_comments: # 真正的评论在'content with open(comment_file_path, 'a+', encoding='utf-8') as f: f.write(i['content'] + ' ') except Exception as e: print(e) if __name__ == '__main__': spider_comment()
5.批量爬取
我们刚刚完成一页数据爬取、提取、保存之后,我们来研究一下如何批量抓取?
做过web的同学可能知道,有一项功能是我们必须要做的,那便是分页。何为分页?为何要做分页?
我们在浏览很多网页的时候常常看到“下一页”这样的字眼,其实这就是使用了分页技术,因为向用户展示数据时不可能把所有的数据一次性展示,所以采用分页技术,一页一页的展示出来。
让我们再回到最开始的加载评论数据的url:http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&page=1
我们可以大胆的猜测,page就是页数。我们可以通过上面的方法,查找第二页评论的接口为
http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page=2&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0
对比发现page变了,证明我们的猜想是正确的。
import json import os import random import time import requests comment_file_path = '163_comment.txt' def spider_comment(i): '''爬取网易严选评论数据''' kv = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36' } url = 'http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page={}&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0'.format(i) try: result = requests.get(url, headers=kv) result.raise_for_status() # 返回状态码。如果返回4XX或者5XX直接执行except result_dict = json.loads(result.text) # 将json转换为字典 result_json_comments = result_dict['data']['commentList'] # print(result_json_comments) for i in result_json_comments: # 真正的评论在'content with open(comment_file_path, 'a+', encoding='utf-8') as f: f.write(i['content'] + ' ') except Exception as e: print(e) def batch_spider_comment(): # 写入文件之前,先清空之前的数据 if os.path.exists(comment_file_path): os.remove(comment_file_path) for i in range(100): spider_comment(i) # 模拟用户浏览,设置一个爬虫间隔,防止ip被封 time.sleep(random.random() * 5) if __name__ == '__main__': batch_spider_comment()
6.数据清洗以及生成词云。
数据成功保存之后我们需要对数据进行分词清洗,对于分词我们使用著名的分词库jieba。
import jieba
import numpy as np
from PIL import Image
from wordcloud import WordCloud
import matplotlib.pyplot as plt
comment_file_path = '163_comment.txt'
def cut_word():
'''
对数据分词
:return: 分词后的数据
'''
with open(comment_file_path, 'r', encoding='utf-8') as f:
comment_txt = f.read()
wordlist = jieba.cut(comment_txt, cut_all=True)
word_str = ' '.join(wordlist)
#print(word_str)
return word_str
def create_word_cloud():
"""生成词云"""
# 设置词云形状图片
coloring = np.array(Image.open('111.png'))
stop_words = ['之前', '内衣', '质量', '非常']
# 设置词云一些配置,如字体,背景色,词云形状,大小
wc = WordCloud(background_color='white', max_words=2000, mask=coloring, scale=4, stopwords=stop_words,
max_font_size=50, random_state=42, font_path='C:WindowsFontsmsyhbd.ttc')
# 生成词云
wc.generate(cut_word())
# 在只设置mask情况下,会拥有一个图形形状的词云
plt.imshow(wc, interpolation="bilinear")
plt.axis('off')
plt.figure()
plt.show()
if __name__ == '__main__':
create_word_cloud()
