1. Param
Spark ML使用一个自定义的Map(ParmaMap类型),其实该类内部使用了mutable.Map容器来存储数据。
如下所示其定义:
|
Class ParamMap private[ml] (private val map.mutable.Map[Param[Any],Any]) |
从上述定义可以看出,ParamMap是用一个Map来存储,key为Param[Any],value为Any。这里的value就是用户设置的参数值,而key是对String的封装,对用户来所其实就是字符串。
如上述的tokenizer类,对调用setInputCol方法来设置输入DataFrame的输入列,其内部实现如下所示:
|
Final val inputCol:Param[String] = new Param[String](this,"inputCol","input column name") def setInputCol(value: String): T = set(inputCol, value).asInstanceOf[T] final def set[T](param:Param[T],value:T):this.type={ set(param->value) } |
2. Transformer
Transformer类是一个抽象类,为了实现从一个DataFrame转换为另一个DataFrame,其子类只需要实现三个方法即可。如下所示的源码:
|
abstract class Transformer extends PipelineStage { /** * Transforms the dataset with optional parameters * @param dataset input dataset * @param firstParamPair the first param pair, overwrite embedded params * @param otherParamPairs other param pairs, overwrite embedded params * @return transformed dataset */ @Since("2.0.0") @varargs def transform( dataset: Dataset[_], firstParamPair: ParamPair[_], otherParamPairs: ParamPair[_]*): DataFrame = { val map = new ParamMap() .put(firstParamPair) .put(otherParamPairs: _*) transform(dataset, map) } /** * Transforms the dataset with provided parameter map as additional parameters. * @param dataset input dataset * @param paramMap additional parameters, overwrite embedded params * @return transformed dataset */ @Since("2.0.0") def transform(dataset: Dataset[_], paramMap: ParamMap): DataFrame = { this.copy(paramMap).transform(dataset) } /** * Transforms the input dataset. */ @Since("2.0.0") def transform(dataset: Dataset[_]): DataFrame override def copy(extra: ParamMap): Transformer } |
-
transform():该方法是用户的API方法,用户直接调用该方法来实现转换;
-
copy():该方法复制了一个Transformer对象;
-
transformSchema:由于Transformer类继承了PipelineStage接口,该接口有这个方法实现。
HasInputCol和HasOutputCol都是接口,它们定义了一种协议。若有输入或有输出参数的Transformer,那么就需要实现这个接口。
|
private[ml] trait HasInputCol extends Params { final val inputCol: Param[String] = new Param[String](this, "inputCol", "input column name") /** @group getParam */ final def getInputCol: String = $(inputCol) } |
|
private[ml] trait HasOutputCol extends Params { final val outputCol: Param[String] = new Param[String](this, "outputCol", "output column name") setDefault(outputCol, uid + "__output") /** @group getParam */ final def getOutputCol: String = $(outputCol) } |
这个类是一元转换的抽象类,其以一个DataFrame列作为输入,然后经过处理后,产生一个新列增加到输入的DataFrame中。
该类的源码如下所示:
|
abstract class UnaryTransformer[IN, OUT, T <: UnaryTransformer[IN, OUT, T]] extends Transformer with HasInputCol with HasOutputCol with Logging { /** API method*/ def setInputCol(value: String): T = set(inputCol, value).asInstanceOf[T] /** API method */ def setOutputCol(value: String): T = set(outputCol, value).asInstanceOf[T] /** * Creates the transform function using the given param map. The input param map already takes * account of the embedded param map. So the param values should be determined solely by the input * param map. */ protected def createTransformFunc: IN => OUT /** * Returns the data type of the output column. */ protected def outputDataType: DataType /** * Validates the input type. Throw an exception if it is invalid. */ protected def validateInputType(inputType: DataType): Unit = {} override def transformSchema(schema: StructType): StructType = { val inputType = schema($(inputCol)).dataType validateInputType(inputType) if (schema.fieldNames.contains($(outputCol))) { throw new IllegalArgumentException(s"Output column ${$(outputCol)} already exists.") } val outputFields = schema.fields :+ StructField($(outputCol), outputDataType, nullable = false) StructType(outputFields) } /** API method */ override def transform(dataset: Dataset[_]): DataFrame = { transformSchema(dataset.schema, logging = true) val transformUDF = udf(this.createTransformFunc, outputDataType) dataset.withColumn($(outputCol), transformUDF(dataset($(inputCol)))) } override def copy(extra: ParamMap): T = defaultCopy(extra) } |
该类提供三个API方法,用户通过使用这些方法来实现转换功能,如下所示:
|
Method |
Description |
|
setInputCol |
指明输入DataFrame中的哪一列是被处理的,输入参数是Dataframe中存在的列名 |
|
setOutputCol |
设置新增加列的名字,及对输入的列变换后悔产生一个新列,该方法设置增加新列的列名 |
|
transform |
用户通过调用该方法实现DataFrame的转换,其实调用该方法是在原来的DataFrame中增加了一个新列,如何增加一个新列,则由createTransformFunc方法来实现。 |
需要特别说明的是transform方法的最后一条语句,其使用了Dataset的如下方法:
Dataset.withColumn(colName:String, col:Column):DataFrame
该方法的功能是通过在遍历dataset中的每一行,然后每行都增加一列,列名为colName,内容为col。
因为UnaryTransformer类是一个抽象类,其没有指明一个输入列如何产生一个新列,这些具体转换工作需要子类来实现。子类需要实现三个方法:
|
Method |
Description |
|
createTransformFunc |
该函数实现了如何将一个输入参数变化后产生一个新数据,即可用将其理解为map操作,即inàout. |
|
outputDataType |
子类实现该方法的目的是返回一个输出列的数据类型; |
|
validataInputType |
验证输入列的类型的合法性。 |
UnaryTransformer抽象类有7个实现类,用户如果需要自定义转换操作也可以继承该类,然后实现相应的操作即可。如下以Tokenizer类进行介绍,如下所示:
|
class Tokenizer @Since("1.4.0") (@Since("1.4.0") override val uid: String) extends UnaryTransformer[String, Seq[String], Tokenizer] with DefaultParamsWritable { //1. 在继承UnaryTransformer类时,指明了createTransformFunc函数的输入参数类型和返回参数类型 @Since("1.2.0") def this() = this(Identifiable.randomUID("tok")) //2. 实现了一个输入值如何进行处理,然后将其返回 override protected def createTransformFunc: String => Seq[String] = { _.toLowerCase.split("\s") } //3. 验证输入参数类型是否合法 override protected def validateInputType(inputType: DataType): Unit = { require(inputType == StringType, s"Input type must be string type but got $inputType.") } //4.返回DataFrame中新增加列的类型 override protected def outputDataType: DataType = new ArrayType(StringType, true) @Since("1.4.1") override def copy(extra: ParamMap): Tokenizer = defaultCopy(extra) } |
通过上述前两节的分析,我们知道在模型训练后,Estimator会生成一个Transformer对象。这种Transformer对象就是Model类的子类,其也是Transformer抽象类的子类。
Model类簇都有特别的功能,其是机器学习模型在训练后的模型,即其能够对输入的DataFrame进行预测,所以都特别有针对性。
3. Estimator
Estimator就是机器学习中的模型,其在Spark ML中有很多实现子类。不同的学习模型都有不同的实现方式。通过前两节分析,我们了解到Estimator在训练后悔产生一个Transformer,这个Transformer其实是Model类。每种Estimator都对应有一种Model。其类图如图 5所示。
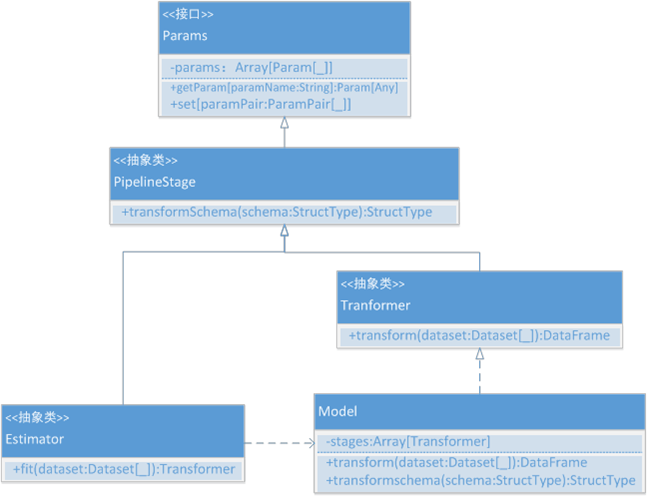
图 5
因为Estimator继承PipelineStage,所以Estimator的实现类需要实现三个方法:
-
copy(extra:ParamMap):实现模型拷贝操作;
-
transformSchema(schema:StructType):实现DataFrame结构的转换;
-
fit(dataset:Dataset[_]):实现模型训练,这个非常重要,是用户的API方法,该方法会返回一个Model实现类。