一 GC做的事情
1 where/whice
堆和方法区
堆:想必都不难理解,存放所有对象,占用最大内存,也是GC主要工作的一块内存
方法区(也叫永久代):主要回收 废弃常量和无用的类
回收废弃常量:与回收java堆中的对象非常类似。以常量池中字面量的回收为例,假如一个字符串“abc”已经进入了常量池中,但是当前系统没有任何一个String对象是叫做“abc”的,换句话说,就是没有任何String对象引用常量池中的“abc”常量,也没有其他地方引用了这个字面量,如果这时候发生内存回收,而且必要的话,这个“abc”常量就会被系统清理出常量池。
回收无用的类:
满足以下3个条件的类称之为无用类
1 该类所所有的对象实例已经被回收,也就是java堆中不存在该类的任何实例
2 加载该类的ClassLoader已经被回收
3 该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
在大量使用反射、动态代理、CGLib等ByteCode框架、动态生成JSP以及OSGI这类频繁自定义ClassLoader的场景都需要虚拟机具备类卸载的功能,以保证永久带不会溢出。
2 when? 内存不足的时候
3 how? 这是接下来主要讲解的点
二 判断对象的存活
1 引用计数法,判断对象的存活
引用计数法的概念:给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。
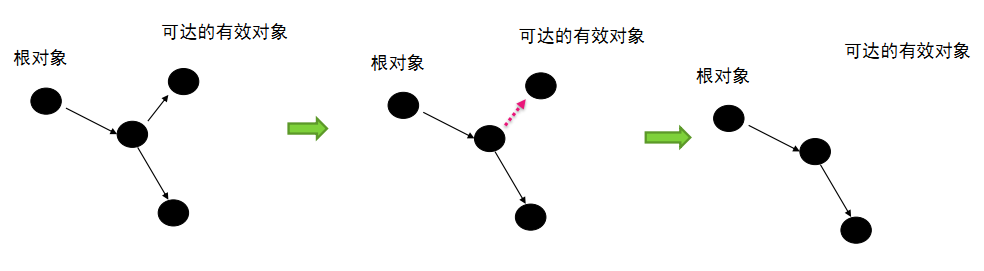
1.1 、使用者举例:
引用计数算法的实现简单,判定效率也高,大部分情况下是一个不错的算法。很多地方应用到它。例如:
微软公司的COM技术:Computer Object Model
使用ActionScript3的FlashPlayer
Python
1.2 缺陷
对象A=对象B
对象B=对象A
2个对象互相引用,形成一个孤岛,引用计数器数量都是1 ,永远不会被回收
2 根搜索算法(可达性分析)算法
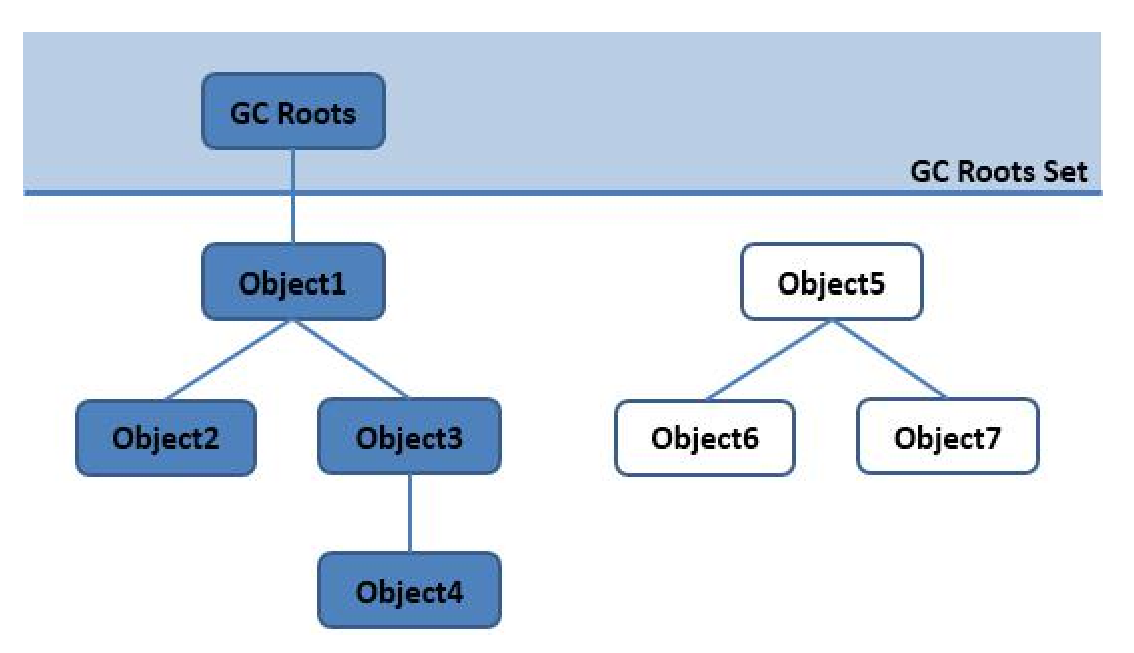
它的处理方式就是,设立若干种根对象(GC root),当任何一个根对象到某一个对象均不可达时,则认为这个对象是可以被回收的。
如上图,Object5,Object6,Object7 均是根对象到达不了的对象,可以被回收
2.1 、哪些对象可以作为根(GC Roots)对象?
1. 栈(栈帧中的本地变量表)中引用的对象。 2. 本地方法栈中JNI(一般说的Native方法)引用的对象。 3. 方法区中的静态成员。 static 修饰 4. 方法区中的常量引用的对象(全局变量) final修饰
总结:栈中引用对象,方法区中静态成员static对象,常量final对象
在现代虚拟机中,在根搜索算法的基础上,衍生出了很多种算法 继续往下看
三 标记-清除算法
1 原理
标记-清除算法是现代垃圾回收算法的思想基础标记-清除算法将垃圾回收分为两个阶段:标记阶段和清除阶段。
标记阶段: 首先通过根节点,标记所有从根节点开始的可达对象。因此,未被标记的对象就是未被引用的垃圾对象;
清除阶段:清除所有未被标记的对象。
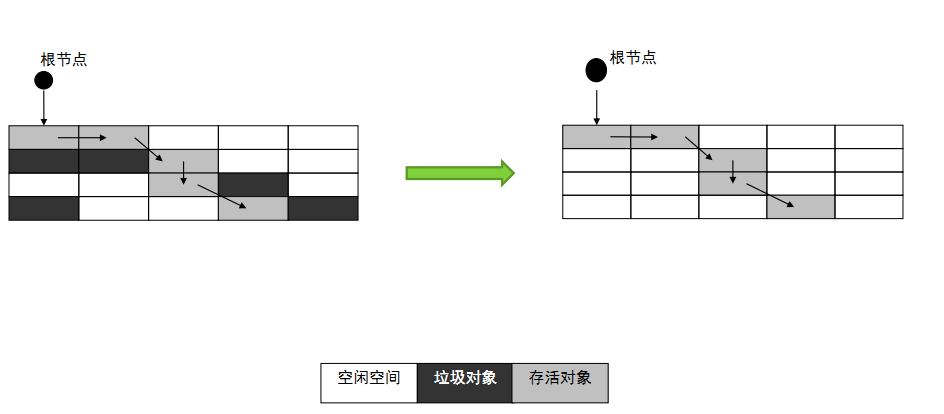
2、标记-清除算法详解:
它的做法是当堆中的有效内存空间(available memory)被耗尽的时候,就会停止整个程序(也被成为stop the world),然后进行两项工作,第一项则是标记,第二项则是清除。
- 标记:标记的过程其实就是,遍历所有的GC Roots,然后将所有GC Roots可达的对象标记为存活的对象。
- 清除:清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
也就是说,就是当程序运行期间,若可以使用的内存被耗尽的时候,GC线程就会被触发并将程序暂停,随后将依旧存活的对象标记一遍,最终再将堆中所有没被标记的对象全部清除掉,接下来便让程序恢复运行。
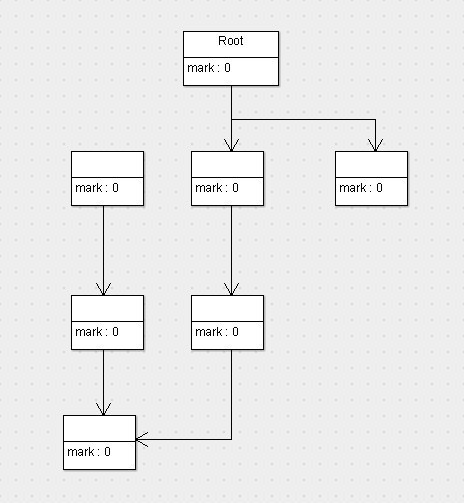
上图代表的是程序运行期间所有对象的状态,它们的标志位全部是0(也就是未标记,以下默认0就是未标记,1为已标记),假设这会儿有效内存空间耗尽了,JVM将会停止应用程序的运行并开启GC线程,然后开始进行标记工作,按照根搜索算法,标记完以后,对象的状态如下图:

上图中可以看到,按照根搜索算法,所有从root对象可达的对象就被标记为了存活的对象,此时已经完成了第一阶段标记。接下来,就要执行第二阶段清除了,那么清除完以后,剩下的对象以及对象的状态如下图所示:
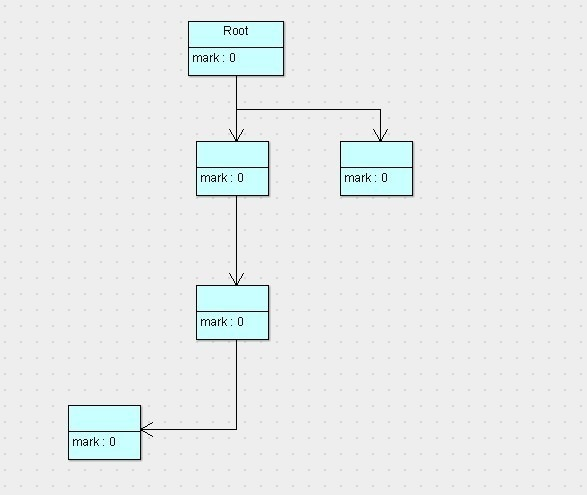
上图可以看到,没有被标记的对象将会回收清除掉,而被标记的对象将会留下,并且会将标记位重新归0。接下来就不用说了,唤醒停止的程序线程,让程序继续运行即可。
疑问:为什么非要停止程序的运行呢?(stop the world)
答:
这个其实也不难理解,假设我们的程序与GC线程是一起运行的,各位试想这样一种场景。
假设我们刚标记完图中最右边的那个对象,暂且记为A,结果此时在程序当中又new了一个新对象B,且A对象可以到达B对象。但是由于此时A对象已经标记结束,B对象此时的标记位依然是0,因为它错过了标记阶段。因此当接下来轮到清除阶段的时候,新对象B将会被苦逼的清除掉。如此一来,不难想象结果,GC线程将会导致程序无法正常工作。
上面的结果当然令人无法接受,我们刚new了一个对象,结果经过一次GC,忽然变成null了,这还怎么玩?
3、标记-清除算法的缺点:
1)首先,它的缺点就是效率比较低(递归与全堆对象遍历),导致stop the world的时间比较长,尤其对于交互式的应用程序来说简直是无法接受。试想一下,如果你玩一个网站,这个网站一个小时就挂五分钟,你还玩吗?
(2)第二点主要的缺点,则是这种方式清理出来的空闲内存是不连续的,这点不难理解,我们的死亡对象都是随即的出现在内存的各个角落的,现在把它们清除之后,内存的布局自然会乱七八糟。而为了应付这一点,JVM就不得不维持一个内存的空闲列表,这又是一种开销。而且在分配数组对象的时候,寻找连续的内存空间会不太好找。
四 复制算法:(新生代的GC)
原理:将原有的内存空间分为两块,每次只使用其中一块,在垃圾回收时,将正在使用的内存中的存活对象复制到未使用的内存块中,之后,
清除正在使用的内存块中的所有对象,交换两个内存的角色,完成垃圾回收。
- 与标记-清除算法相比,复制算法是一种相对高效的回收方法
- 不适用于存活对象较多的场合,如老年代(复制算法适合做新生代的GC)
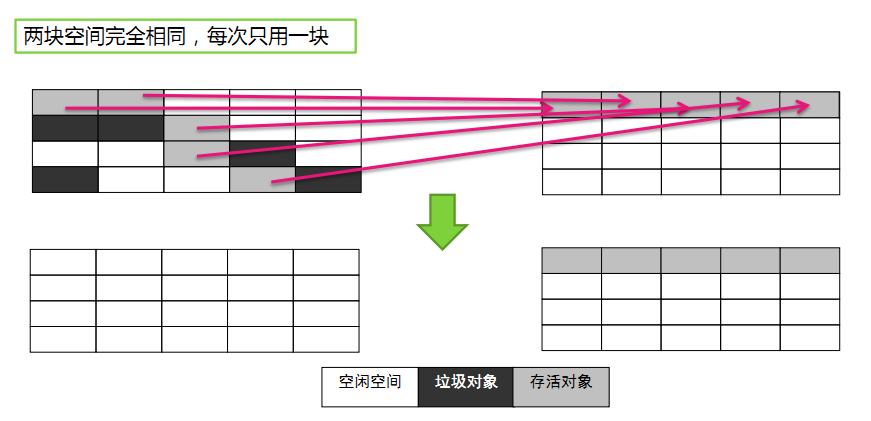
- 复制算法的最大的问题是:空间的浪费
复制算法使得每次都只对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为原来的一半,这个太要命了。
所以从以上描述不难看出,复制算法要想使用,最起码对象的存活率要非常低才行,而且最重要的是,我们必须要克服50%内存的浪费。
现在的商业虚拟机都采用这种收集算法来回收新生代,新生代中的对象98%都是“朝生夕死”的,所以并不需要按照1:1的比例来划分内存空间,而是将内存分为一块比较大的Eden空间和两块较小的Survivor(Survivor1,Survivor2)空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性地复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。
HotSpot虚拟机默认Eden和Survivor的大小比例是8:1:1,也就是说,每次新生代中可用内存空间为整个新生代容量的90%(80%+10%),只有10%的空间会被浪费
当然,98%的对象可回收只是一般场景下的数据,我们没有办法保证每次回收都只有不多于10%的对象存活,当Survivor空间不够用时,需要依赖于老年代进行分配担保,所以大对象直接进入老年代。整个过程如下图所示:
五 标记-整理算法:(老年代的GC)
引入:
如果在对象存活率较高时就要进行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选中这种复制算法。
原理:
标记-整理算法适合用于存活对象较多的场合,如老年代。它在标记-清除算法的基础上做了一些优化。和标记-清除算法一样,标记-压缩算法也首先需要从根节点开始,对所有可达对象做一次标记;但之后,它并不简单的清理未标记的对象,而是将所有的存活对象压缩到内存的一端;之后,清理边界外所有的空间。
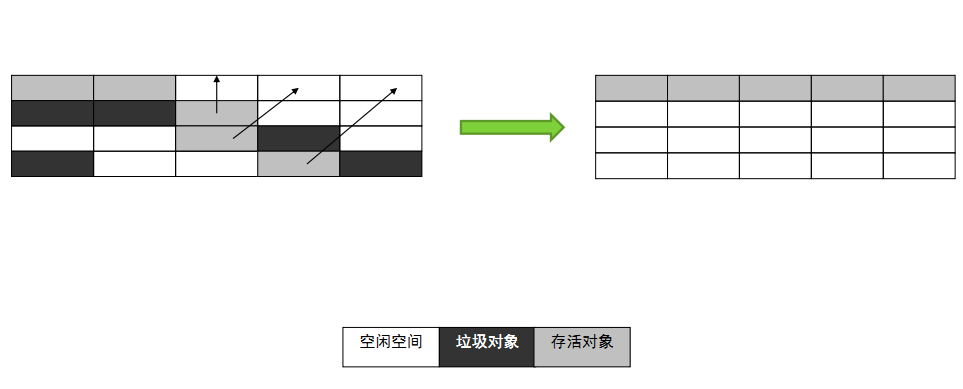
- 标记:它的第一个阶段与标记/清除算法是一模一样的,均是遍历GC Roots,然后将存活的对象标记。
- 整理:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。因此,第二阶段才称为整理阶段。
上图中可以看到,标记的存活对象将会被整理,按照内存地址依次排列,而未被标记的内存会被清理掉。如此一来,当我们需要给新对象分配内存时,JVM只需要持有一个内存的起始地址即可,这比维护一个空闲列表显然少了许多开销。
标记/整理算法不仅可以弥补标记/清除算法当中,内存区域分散的缺点,也消除了复制算法当中,内存减半的高额代价。
- 但是,标记/整理算法唯一的缺点就是效率也不高。
不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上来说,标记/整理算法要低于复制算法。
标记-清除算法、复制算法、标记整理算法的总结:
三个算法都基于根搜索算法去判断一个对象是否应该被回收,而支撑根搜索算法可以正常工作的理论依据,就是语法中变量作用域的相关内容。
因此,要想防止内存泄露,最根本的办法就是掌握好变量作用域,
在GC线程开启时,或者说GC过程开始时,它们都要暂停应用程序(stop the world) 其实本质就是GC-Roots可达性分析期间,必须stop the world
它们的区别如下:(>表示前者要优于后者,=表示两者效果一样)
(1)效率:复制算法>标记/整理算法>标记/清除算法(此处的效率只是简单的对比时间复杂度,实际情况不一定如此)。
(2)内存整齐度:复制算法=标记/整理算法>标记/清除算法。
(3)内存利用率:标记/整理算法=标记/清除算法>复制算法。
注1:可以看到标记/清除算法是比较落后的算法了,但是后两种算法却是在此基础上建立的。
注2:时间与空间不可兼得。
六 分代收集算法:(新生代的GC+老年代的GC) 多种算法混合
当前商业虚拟机的GC都是采用的“分代收集算法”,这并不是什么新的思想,只是根据对象的存活周期的不同将内存划分为几块儿。一般是把Java堆分为新生代和老年代:短命对象归为新生代,长命对象归为老年代。
- 少量对象存活,适合复制算法:在新生代中,每次GC时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成GC。
- 大量对象存活,适合用标记-清理/标记-整理:在老年代中,因为对象存活率高、没有额外空间对他进行分配担保,就必须使用“标记-清理”/“标记-整理”算法进行GC。
注:老年代的对象中,有一小部分是因为在新生代回收时,老年代做担保,进来的对象;绝大部分对象是因为很多次GC都没有被回收掉而进入老年代
七、可触及性:
所有的算法,需要能够识别一个垃圾对象,因此需要给出一个可触及性的定义。
可触及的:
从根节点可以触及到这个对象。
其实就是从根节点扫描,只要这个对象在引用链中,那就是可触及的。
可复活的:
一旦所有引用被释放,就是可复活状态
因为在finalize()中可能复活该对象
不可触及的:
在finalize()后,可能会进入不可触及状态
不可触及的对象不可能复活
要被回收。
finalize方法复活对象的代码举例:
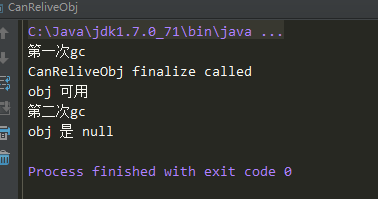
复制代码 1 package test03; 2 3 /** 4 * Created by smyhvae on 2015/8/19. 5 */ 6 public class CanReliveObj { 7 public static CanReliveObj obj; 8 9 //当执行GC时,会执行finalize方法,并且只会执行一次 10 @Override 11 protected void finalize() throws Throwable { 12 super.finalize(); 13 System.out.println("CanReliveObj finalize called"); 14 obj = this; //当执行GC时,会执行finalize方法,然后这一行代码的作用是将null的object复活一下,然后变成了可触及性 15 } 16 17 @Override 18 public String toString() { 19 return "I am CanReliveObj"; 20 } 21 22 public static void main(String[] args) throws 23 InterruptedException { 24 obj = new CanReliveObj(); 25 obj = null; //可复活 26 System.out.println("第一次gc"); 27 System.gc(); 28 Thread.sleep(1000); 29 if (obj == null) { 30 System.out.println("obj 是 null"); 31 } else { 32 System.out.println("obj 可用"); 33 } 34 obj = null; //不可复活 35 System.out.println("第二次gc"); 36 System.gc(); 37 Thread.sleep(1000); 38 if (obj == null) { 39 System.out.println("obj 是 null"); 40 } else { 41 System.out.println("obj 可用"); 42 } 43 } 44 }
我们需要注意第14行的注释。一开始,我们在第25行将obj设置为null,然后执行一次GC,本以为obj会被回收掉,其实并没有,因为GC的时候会调用11行的finalize方法,然后obj在第14行被复活了。紧接着又在第34行设置obj设置为null,然后执行一次GC,此时obj就被回收掉了,因为finalize方法只会执行一次。
finalize方法的使用总结:
- 经验:避免使用finalize(),操作不慎可能导致错误。
- 优先级低,何时被调用,不确定
何时发生GC不确定,自然也就不知道finalize方法什么时候执行
- 如果要使用finalize去释放资源,我们可以使用try-catch-finally来替代它
八、Stop-The-World:
1、Stop-The-World概念:
Java中一种全局暂停的现象。
全局停顿,所有Java代码停止,native代码可以执行,但不能和JVM交互
多半情况下是由于GC引起。
少数情况下由其他情况下引起,如:Dump线程、死锁检查、堆Dump。
2、GC时为什么会有全局停顿?
(1)避免无法彻底清理干净
打个比方:类比在聚会,突然GC要过来打扫房间,聚会时很乱,又有新的垃圾产生,房间永远打扫不干净,只有让大家停止活动了,才能将房间打扫干净。
况且,如果没有全局停顿,会给GC线程造成很大的负担,GC算法的难度也会增加,GC很难去判断哪些是垃圾。
(2)GC的工作必须在一个能确保一致性的快照中进行,否则准确性无法保证
这里的一致性的意思是:在整个分析期间整个执行系统看起来就像被冻结在某个时间点上,不可以出现分析过程中对象引用关系还在不断变化的情况,该点不满足的话分析结果的准确性无法得到保证。
这点是导致GC进行时必须停顿所有Java执行线程的其中一个重要原因。
3、Stop-The-World的危害
长时间服务停止,没有响应(将用户正常工作的线程全部暂停掉)
遇到HA系统,可能引起主备切换,严重危害生产环境。
备注:HA:High Available, 高可用性集群。

比如上面的这主机和备机:现在是主机在工作,此时如果主机正在GC造成长时间停顿,那么备机就会监测到主机没有工作,于是备机开始工作了;但是主机不工作只是暂时的,当GC结束之后,主机又开始工作了,那么这样的话,主机和备机就同时工作了。主机和备机同时工作其实是非常危险的,很有可能会导致应用程序不一致、不能提供正常的服务等,进而影响生产环境。
九 Java引用的四种状态
强引用:
用的最广。我们平时写代码时,new一个Object存放在堆内存,然后用一个引用指向它,这就是强引用。
如果一个对象具有强引用,那垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。
软引用:(SoftReference)
如果一个对象只具有软引用,则内存空间足够时,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。(备注:如果内存不足,随时有可能被回收。)
只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
弱引用: (WeakReference)
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。
每次执行GC的时候,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
虚引用:(PhantomReference)
“虚引用”顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
虚引用主要用来跟踪对象被垃圾回收器回收的活动。
欢迎转载,但请保留文章原始出处→_→
生命壹号:http://www.cnblogs.com/smyhvae/
文章来源:http://www.cnblogs.com/smyhvae/p/4744233.html
完结