1. Redis的定义
这个问题的结果影响了我们怎么用Redis。如果你认为Redis是一个key value store, 那可能会用它来代替MySQL;如果认为它
是一个可以持久化的cache, 可能只是它保存一些频繁访问的临时数据。Redis是REmote DIctionary
Server的缩写,在Redis在官方网站的的副标题是A persistent key-value database with built-in net interface written in
ANSI-C for Posix systems,这个定义偏向key value store。还有一些看法则认为Redis是一个memory
database,因为它的高性能都是基于内存操作的基础。另外一些人则认为Redis是一个data structure server,因为Redis支持复杂
的数据特性,比如List, Set等。对Redis的作用的不同解读决定了你对Redis的使用方式。
在redis cookbook书中是这么介绍redis的:Redis is a data structure server with an in-memory dataset for speed.
Itis called a data structure server and not simply a key value store
because Redis implements data structures allowing keys to contain binary safe strings, hashes, sets and sorted
sets, as well as lists.
2.redis的性能
说到redis的性能,很容易让我们把它和memcache做比较。从实现的逻辑中,很多开发者都认为Redis不可能比Memcache快,Memcached完全基于内存,而
Redis具有持久化保存特性,即使是异步的,Redis也不可能比Memcached快。但是测试结果基本是Redis占绝对优势。
原因从两个方面来看:
1. Libevent(是一个异步事件处理软件函式库,以BSD许可证释出) ,Redis并没有选择libevent,Libevent为了迎合通用
性造成代码庞大(目前Redis代码还不到libevent的1/3)及牺牲了在特定平台的不少性
能。Redis用libevent中两个文件修改实现了自己的epoll event loop(4)。业界不少开发者也建议Redis使用另外一个libevent高性
能替代libev,但是作者还是坚持Redis应该小巧并去依赖的思路。一个印象深刻的细节
是编译Redis之前并不需要行./configure。
2.CAS问题。CAS是Memcached中比较方便的一种防止竞争修改资源的方法。CAS实现需要为每个cache key设置一个隐藏的
cas token,cas相当value版本号,每次set会token需要递增,因此带来CPU和内存的双
重开销,虽然这些开销很小,但是到单机10G+ cache以及QPS上万之后这些开销就会给双方相对带来一些细微性能差别(5)。
网上又很多文章说redis vs memcache中,大部分文章涉及到的是memcache完胜,redis vs memcache 这里面提到了性能测试的严谨性。
3.redis的安装
1.windows :
Although Redis is not officially supported on Windows for several reasons—notably the lack of a copy-on-write
fork()—the community provides a few ports. Due to Windows’limitations, Redis MinGWbuilds execute operations such as BGSAVE and
BGREWRITEAOF in the foreground (thus blocking the Redis process) and Cygwin builds don’t use CoW, which makes background operations
very slow, particularly forlarge database sizes. Be sure to disable automatic saving in the config file (especially for MinGW
builds) and use SAVE only when needed.(缺乏一个即写即拷的fork(),fork()这个方法是linux创建子进程的重要方
法,redis的快照功能就是依托于它进行内存的本地化)
下载地址: http://code.google.com/p/servicestack/wiki/RedisWindowsDownload
Redis作者拒绝微软的Windows补丁 :http://antirez.com/post/redis-win32-msft-patch.html
2.linux:
一、下载最新版
二、解压缩
三、安装C/C++的编译组件(非必须)
四、编译
(在redis-2.4.0 之前有个bug,就是在内存达到redis配置的最大值时,会出现个死循环,在redis-2.4.0需要打补丁)
3.mac:
详细安装过程
4.redis的启动
1.windows :
Redis文件夹有以下几个文件
redis-server.exe:服务程序
redis-check-dump.exe:本地数据库检查
redis-check-aof.exe:更新日志检查
redis-benchmark.exe:性能测试,用以模拟同时由N个客户端发送M个 SETs/GETs 查询 (类似于 Apache 的ab 工具).指定redis的配置文件,如没有指定,则使用默认设置
解压目录:>redis-server.exe redis.conf
2.linux:
进入redis文件夹
运行 redis-server ./redis.conf
将Redis 作为 Linux 服务随机启动
vi /etc/rc.local, 使用vi 编辑器打开随机启动配置文件,并在其中加入下面一行代码
/root/4setup/redis-2.2.12/src/redis-server
5.redis的数据类型
作为Key-value 型数据库,Redis 也提供了键(Key)和键值(Value)的映射关系。但是,除了常规的数值或字符串,Redis 的键值还可以是以下形式之一:
· Lists (列表)
· Sets (集合)
· Sorted sets (有序集合)
· Hashes (哈希表)
键值的数据类型决定了该键值支持的操作。Redis 支持诸如列表、集合或有序集合的交集、并集、查集等高级原子操作;同时,如果键值的类型是普通数字,Redis 则提供自增等原子操作。
6.redis的配置
在redis-2.2.12 目录下有一个redis.conf 文件,这个文件即是Redis 的配置文件
·daemonize: 默认情况下,redis 不是在后台运行的,如果需要在后台运行,把该项的值更改为yes
· pidfile: 当Redis 在后台运行的时候,Redis 默认会把pid 文件放在/var/run/redis.pid,你可以配置到其他地址。当运行多个redis 服务时,需要指定不同的pid 文件和端口
· bind : 指定Redis 只接收来自于该IP 地址的请求,如果不进行设置,那么将处理所有请求,在生产环境中最好设置该项
· port : 监听端口,默认为6379
· timeout : 设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接
· loglevel: log 等级分为4 级,debug, verbose, notice, 和warning。生产环境下一般开启notice
· logfile : 配置log 文件地址,默认使用标准输出,即打印在命令行终端的窗口上
· databases: 设置数据库的个数,可以使用SELECT <dbid>命令来切换数据库。默认使用的数据库是0
· save : 设置Redis 进行数据库镜像的频率。
if(在60 秒之内有10000 个keys 发生变化时){
进行镜像备份
}else if(在300 秒之内有10 个keys 发生了变化){
进行镜像备份
}else if(在900 秒之内有1 个keys 发生了变化){
进行镜像备份
}
· rdbcompression 在进行镜像备份时,是否进行压缩
· dbfilename 镜像备份文件的文件名
· dir 数据库镜像备份的文件放置的路径。这里的路径跟文件名要分开配置是因为Redis 在进行备份
时,先会将当前数据库的状态写入到一个临时文件中,等备份完成时,再把该临时文件替换为上面所指定的文件,而
这里的临时文件和上面所配置的备份文件都会放在这个指定的路径当中
· slaveof 设置该数据库为其他数据库的从数据库
· masterauth 当主数据库连接需要密码验证时,在这里指定
· requirepass 设置客户端连接后进行任何其他指定前需要使用的密码。警告:因为redis 速度相当快,所以
在一台比较好的服务器下,一个外部的用户可以在一秒钟进行150K 次的密码尝
· maxclients 限制同时连接的客户数量。当连接数超过这个值时,redis 将不再接收其他连接请求,客户端尝试连接时将收到error 信息。
· maxmemory 设置redis 能够使用的最大内存。当内存满了的时候,如果还接收到set 命令,redis 将先尝试剔除设置过expire 信息的key,而不管该key 的过期时间还没有到达。在删除时,将按照过期时间进行删除,最早将要被过期的key 将最先被删除。的key 都删光了,那么将返回错误。这样,redis 将不再接收写请求,只接收get 请求。的key 都删光了,那么将返回错误。这样,redis 将不再接收写请求,只接收get 请求。
· maxmemory 设置比较适合于把redis 当作于类似memcached 的缓存来使用。
· appendonly 默认情况下,redis 会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频繁,如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失。所以redis 提供了另外一种更加高效的数据库备份及灾难恢复方式。开启append only 模式之后,redis 会把所接收到的每一次写操作请求都追加到appendnoly.aof 文件中,当redis 重新启动时,会从该文件恢复出之前的状态。但是这样会造成appendonly.aof 文件过大,所以redis 还支持了BGREWRITEAOF 指令,对appendonly.aof进行重新整理。所以我认为推荐生产环境下的做法为关闭镜像,开启appendonly.aof,同时可以选择在访问较少的时间每天对appendonly.aof 进行重写 一次。
· appendfsync 设置对appendonly.aof 文件进行同步的频率。always 表示每次有写操作都进行同步,everysec表示对写操作进行累积,每秒同步一次。这个需要根据实际业务场景进行配置
· vm-enabled 是否开启虚拟内存支持。因为redis 是一个内存数据库,而且当内存满的时候,无法接收新的写请求,所以在redis 2.0 中,提供了虚拟内存的支持。但是需要注意的是,redis中,所有的key 都会放在内存中,在内存不够时,只会把value 值放入交换区。这样保证了虽然使用虚拟内存,但性能基本不受影响,同时,你需要注意的是你要把vm-max-memory 设置到足够来放下你的所有的key
· vm-swap-file 设置虚拟内存的交换文件路径
· vm-max-memory 这里设置开启虚拟内存之后,redis 将使用的最大物理内存的大小。默认为0,redis 将把他所有的能放到交换文件的都放到交换文件中,以尽量少的使用物理内存。在生产环境下,需要根据实际情况设置该值,最好不要使用默认的0
· vm-page-size 设置虚拟内存的页大小,如果你的value 值比较大,比如说你要在value 中放置博客、新闻之类的所有文章内容,就设大一点,如果要放置的都是很小的内容,那就设小一点。
· vm-pages 设置交换文件的总的page 数量,需要注意的是,page table 信息会放在物理内存中,每8 个page 就会占据RAM 中的1 个byte。 总的虚拟内存大小= vm-page-size * vm-pages
· vm-max-threads设置VM IO 同时使用的线程数量。因为在进行内存交换时,对数据有编码和解码的过程,所以尽管IO 设备在硬件上本上不能支持很多的并发读写,但是还是如果你所保存的vlaue 值比较大,将该值设大一些,还是能够提升性能的
· glueoutputbuf 把小的输出缓存放在一起,以便能够在一个TCP packet 中为客户端发送多个响应,具体原理和真实效果我不是很清楚。所以根据注释,你不是很确定的时候就设置成yes
· hash-max-zipmap-entries 在redis 2.0 中引入了hash 数据结构。当hash 中包含超过指定元素个数并且最大的元素没有超过临界时,hash 将以一种特殊的编码方式(大大减少内存使用)来存储,这里可以设置这两个临界值
· activerehashing 开启之后,redis 将在每100 毫秒时使用1 毫秒的CPU 时间来对redis 的hash 表进行重新hash,可以降低内存的使用。当你的使用场景中,有非常严格的实时性需要,不能够接受Redis 时不时的对请求有2 毫秒的延迟的话,把这项配置为no。如果没有这么严格的实时性要求,可以设置为yes,以便能够尽可能快的释放内存
7.redis的持久化
通常,Redis 将数据存储于内存中,或被配置为使用虚拟内存。通过两种方式可以实现数据持久化:使用截图的方式,将内存中的数据不断写入磁盘;或使用类似MySQL 的日志方式,记录每次更新的日志。前者性能较高,但是可能会引起一定程度的数据丢失;后者相反。
8.redis的操作
·string string 是最简单的类型,你可以理解成与Memcached 是一模一样的类型,一个key 对应一个value,其上支持的操作与Memcached 的操作类似。但它的功能更丰富。string 类型是二进制安全的,意思是redis 的string 可以包含任何数据,比如jpg 图片或者序列化的对象。
set 设置key 对应的值为string 类型的value。 例如 set name CML
setnx 设置key 对应的值为string 类型的value。如果key 已经存在,返回0,nx 是not exist 的意思。
setex 设置key 对应的值为string 类型的value,并指定此键值对应的有效期。 例如 setex age 10 25
setrange 设置指定key 的value 值的子字符串。 例如 setrange name 2 gmail.com
mset 一次设置多个key 的值,成功返回ok 表示所有的值都设置了,失败返回0 表示没有任何值被设置。
msetnx 一次设置多个key 的值,成功返回ok 表示所有的值都设置了,失败返回0 表示没有任何值被设置,但是不会覆盖已经存在的key。
get 获取key 对应的string 值,如果key 不存在返回nil。 例如 get name
getset 设置key 的值,并返回key 的旧值。
getrange 获取指定key 的value 值的子字符串。
mget 一次获取多个key 的值,如果对应key 不存在,则对应返回nil。
incr 对key 的值做加加操作,并返回新的值。注意incr 一个不是int 的value 会返回错误,incr 一个不存在的key,则设置key 为1
incrby 同incr 类似,加指定值 ,key 不存在时候会设置key,并认为原来的value 是 0
decr 对key 的值做的是减减操作,decr 一个不存在key,则设置key 为-1
decrby 同decr,减指定值。
append 给指定key 的字符串值追加value,返回新字符串值的长度。
strlen 取指定key 的value 值的长度。
· hashes
Redis hash是一个string 类型的field和value的映射表.它的添加、删除操作都是O(1() 平均)。。将一个对象存储在hash 类型中会占用更少的内存,原因是新建一个hash 对象时开始是用zipmap(又称为small hash)来存储的。如果field 或者value的大小超出一定限制后,Redis 会在内部自动将zipmap 替换成正常的hash 实现. 这个限制可以在配置文件中指定 hash-max-zipmap-entries 64 #配置字段最多64 个
hash-max-zipmap-value 512 #配置value 最大为512 字节
hset 设置hash field 为指定值,如果key 不存在,则先创建。
hsetnx 设置hash field 为指定值,如果key 不存在,则先创建。如果field 已经存在,返回0,nx 是not exist 的意思。
hmset 同时设置hash 的多个field。
hget 获取指定的hash field。
hmget 获取全部指定的hash filed。
hincrby 指定的hash filed 加上给定值。
hexists 测试指定field 是否存在。
hlen 返回指定hash 的field 数量。
hdel 返回指定hash 的field 数量。
hkeys 返回hash 的所有field。
hvals 返回hash 的所有value。
hgetall 获取某个hash 中全部的filed 及value。
· list
list 是一个链表结构,主要功能是push、pop、获取一个范围的所有值等等,操作中key 理解为链表的名字。
lpush 在key 对应list 的头部添加字符串元素
rpush 在key 对应list 的尾部添加字符串元素
linsert 在key 对应list 的特定位置之前或之后添加字符串元素
lset 设置list 中指定下标的元素值(下标从0 开始)
lrem 从key 对应list 中删除count 个和value 相同的元素。
ltrim 保留指定key 的值范围内的数据
lpop 从list 的头部删除元素,并返回删除元素
rpop 从list 的尾部删除元素,并返回删除元素
rpoplpush 从第一个list 的尾部移除元素并添加到第二个list 的头部,最后返回被移除的元素值,整个操作是原子的.如果第一个list 是空或者不存在返回nil
lindex 返回名称为key 的list 中index 位置的元素
llen 返回key 对应list 的长度
· set
Redis 的set 是string 类型的无序集合,是通过hash table 实现的 。
sadd 向名称为key 的set 中添加元素
srem 删除名称为key 的set 中的元素member
spop 随机返回并删除名称为key 的set 中一个元素
sdiff 返回所有给定key 与第一个key 的差集
sdiffstore 返回所有给定key 与第一个key 的差集,并将结果存为另一个key
sinter 返回所有给定key 的交集
sinterstore 返回所有给定key 的交集,并将结果存为另一个key
sunion 返回所有给定key 的并集
sunionstore 返回所有给定key 的并集,并将结果存为另一个key
smove 从第一个key 对应的set 中移除member 并添加到第二个对应set 中
scard 返回名称为key 的set 的元素个数
sismember 测试member 是否是名称为key 的set 的元素
srandmember 随机返回名称为key 的set 的一个元素,但是不删除元素
· sorted sets
sorted set 是set 的一个升级版本,它在set 的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset 会自动重新按新的值调整 顺序.可以理解为有两列的mysql 表,一列存value,一列存顺序。操作中key 理解为zset 的名字。
zadd 向名称为key 的zset 中添加元素member,score 用于排序。如果该元素已经存在,则根据score 更新该元素的顺序
zrem 删除名称为key 的zset 中的元素member
zincrby 如果在名称为key 的zset 中已经存在元素member,则该元素的score 增加increment;否则向集合中添加该元素,其score 的值为increment
zrank 返回名称为key 的zset 中member 元素的排名(按score 从小到大排序)即下标
zrevrank 返回名称为key 的zset 中member 元素的排名(按score 从大到小排序)即下标
zrevrange 返回名称为key 的zset(按score 从大到小排序)中的index 从start 到end 的所有元素
zrangebyscore 返回集合中score 在给定区间的元素
zcount 返回集合中score 在给定区间的数量
zcard 返回集合中元素个数
zscore 返回给定元素对应的score
zremrangebyrank 删除集合中排名在给定区间的元素
zremrangebyscore 删除集合中score 在给定区间的元素
9.redis 服务器的命令
·测试连接是否存活
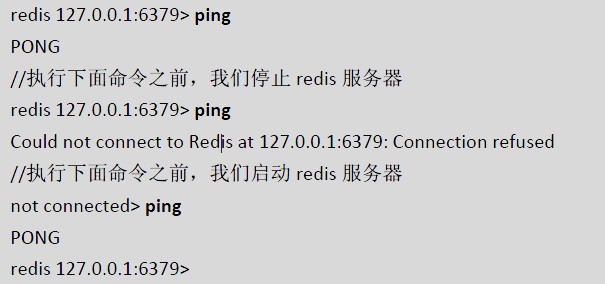
第一个ping 时,说明此连接正常
第二个ping 之前,我们将redis 服务器停止,那么ping 是失败的
第三个ping 之前,我们将redis 服务器启动,那么ping 是成功的
·在命令行打印一些内容

·选择数据库

Redis 数据库编号从0~15,我们可以选择任意一个数据库来进行数据的存取。当选择16 时,报错,说明没有编号为16 的这个数据库
·退出连接。

·返回当前数据库中key 的数目
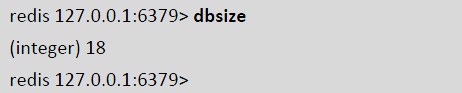
结果说明此库中有18 个key
·获取服务器的信息和统计
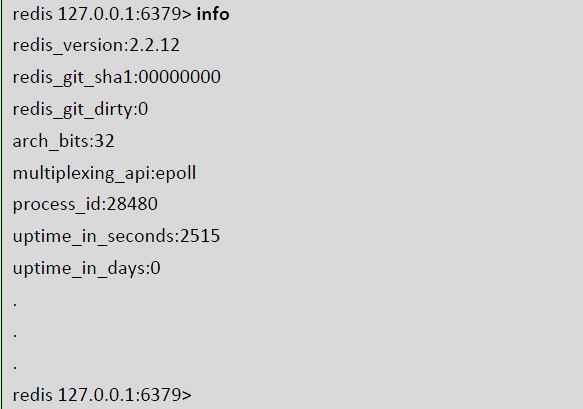
此结果用于说明服务器的基础信息,包括版本、启动时间等。
·实时转储收到的请求

从结果可以看出,此服务器目前接受了命令"keys *"和"get addr"。
·获取服务器配置信息

本例中我们获取了dir 这个参数配置的值,如果想获取全部参数据的配置值也很简单,只需执行”config get *”即可将全部的值都显示出来。
·删除当前选择数据库中的所有key
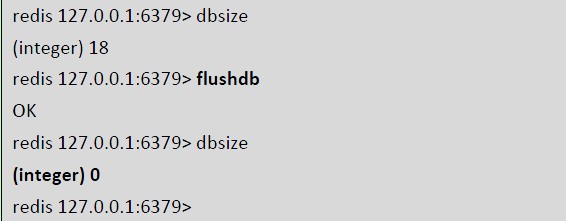
我们将0 号数据库中的key 都清除了
·删除所有数据库中的所有key
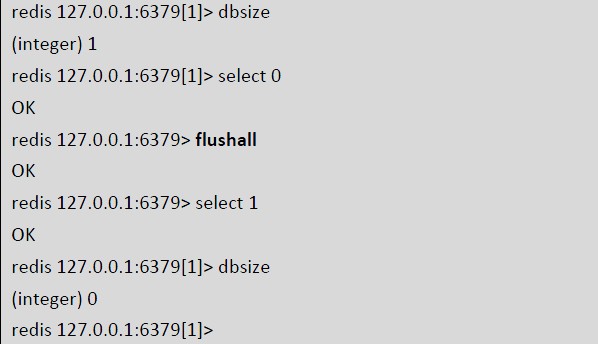
我们先查看了一个1 号数据库中有一个key,然后我切换到0 号库执行flushall 命令,结果1 号库中的key 也被清除了,说是此命令工作正常。
10.redis 高级特性
·事务控制
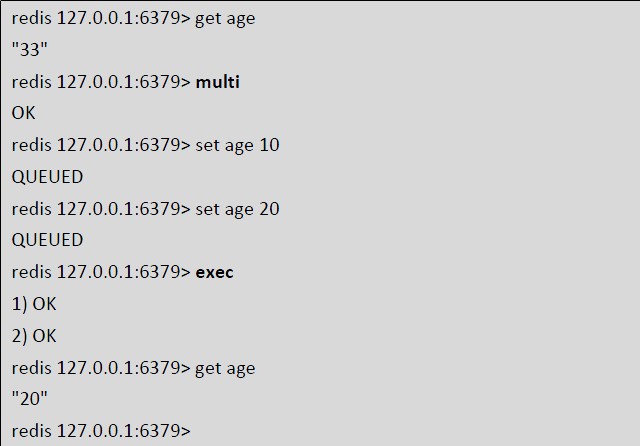
我们可以看到2 个set age 命令发出后并没执行而是被放到了队列中。调用exec后2 个命令才被连续的执行,最后返回的是两条命令执行后的结果。
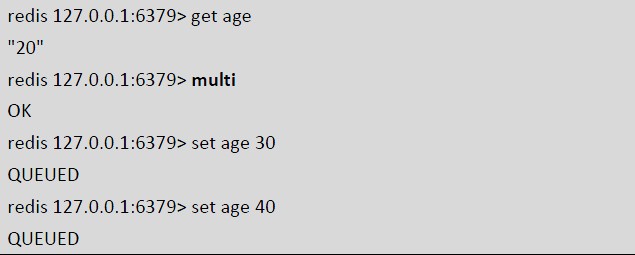
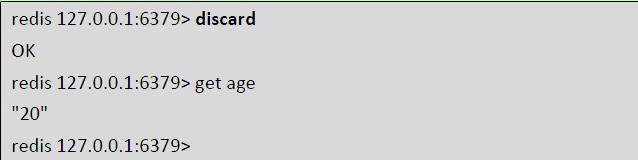
可以发现这次2 个set age 命令都没被执行。discard 命令其实就是清空事务的命令队列并退出事务上下文,也就是我们常说的事务回滚。
· 乐观锁复杂事务控制
乐观锁:大多数是基于数据版本(version)的记录机制实现的。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表添加一个“version”字段来实现读取出数据时,将此版本号一同读出,之后更新时,对此版本号加1。此时,将提交数据的版本号与数据库表对应记录的当前版本号进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
e.g 假设有一个age 的key,我们开2 个session 来对age 进行赋值操作,我们来看一下结果如何。
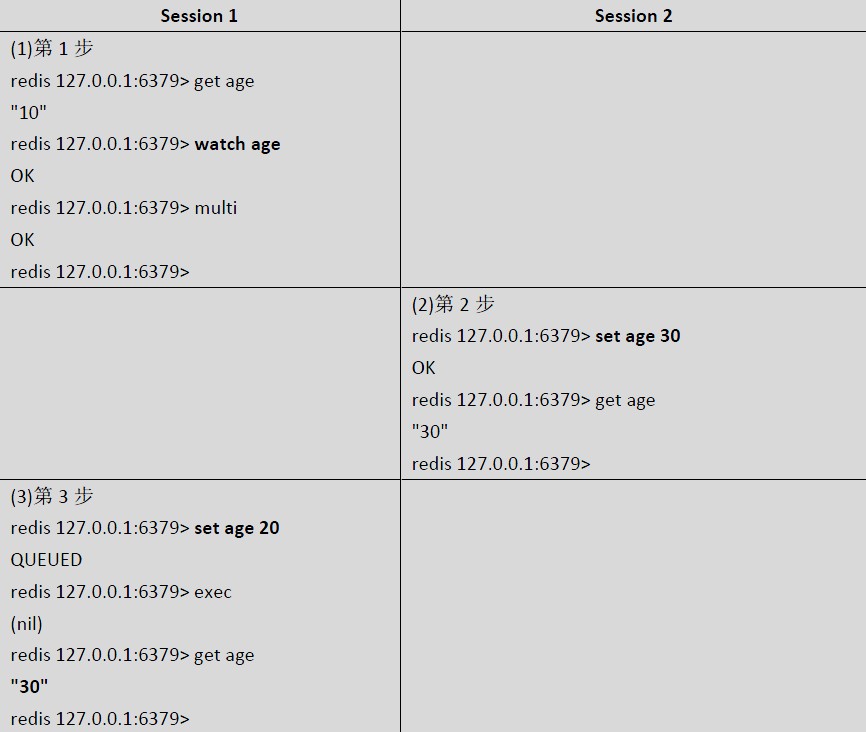
从以上实例可以看到在
第一步,Session 1 还没有来得及对age 的值进行修改
第二步,Session 2 已经将age 的值设为30
第三步,Session 1 希望将age 的值设为20,但结果一执行返回是nil,说明执行失败,之后我们再取`一下age 的值是30。
这是由于Session 1 中对age 加了乐观锁导致的。watch 命令会监视给定的key,当exec 时候如果监视的key 从调用watch 后发生过变化,则整个事务会失败。也可以调用watch 多次监视多个key.这 样就可以对指定的key 加乐观锁了。注意watch 的key 是对整个连接有效的,事务也一样。如果连接断开,监视和事务都会被自 动清除。当然了exec,discard,unwatch 命令都会清除连接中的所有监视。