1. 写在前面
在机器学习(Machine learning)领域,监督学习(Supervised learning)、非监督学习(Unsupervised learning)以及半监督学习(Semi-supervised learning)是三类研究比较多,应用比较广的学习技术,wiki上对这三种学习的简单描述如下:
- 监督学习:通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如分类。
- 非监督学习:直接对输入数据集进行建模,例如聚类。
- 半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。
其实很多机器学习都是在解决类别归属的问题,即给定一些数据,判断每条数据属于哪些类,或者和其他哪些数据属于同一类等等。这样,如果我们上来就对这一堆数据进行某种划分(聚类),通过数据内在的一些属性和联系,将数据自动整理为某几类,这就属于非监督学习。如果我们一开始就知道了这些数据包含的类别,并且有一部分数据(训练数据)已经标上了类标,我们通过对这些已经标好类标的数据进行归纳总结,得出一个 “数据-->类别” 的映射函数,来对剩余的数据进行分类,这就属于监督学习。而半监督学习指的是在训练数据十分稀少的情况下,通过利用一些没有类标的数据,提高学习准确率的方法。
2. 什么是active learning?
在真实的数据分析场景中,我们可以获取海量的数据,但是这些数据都是未标注数据,很多经典的分类算法并不能直接使用。那肯定会有人说,数据是没有标注的,那我们就标注数据喽!这样的想法很正常也很单纯,但是数据标注的代价是很大的,及时我们只标注几千或者几万训练数据,标注数据的时间和金钱成本也是巨大的。
在介绍active learning的概念之前,首先先谈一下样本信息的问题。
什么是样本信息呢?简单地来讲,样本信息就是说在训练数据集当中每个样本带给模型训练的信息是不同的,即每个样本为模型训练的贡献有大有小,它们之间是有差异的。
因此,为了尽可能地减小训练集及标注成本,在机器学习领域中,提出主动学习(active learning)方法,优化分类模型。
主动学习(active learning),指的是这样一种学习方法:
有的时候,有类标的数据比较稀少而没有类标的数据是相当丰富的,但是对数据进行人工标注又非常昂贵,这时候,学习算法可以主动地提出一些标注请求,将一些经过筛选的数据提交给专家进行标注。
这个筛选过程也就是主动学习主要研究的地方了。
3. active learning的基本思想
主动学习算法可以由以下五个组件进行建模:
A=(C,L,S,Q,U)A=(C,L,S,Q,U)
其中 CC 为一个或一组分类器;LL 为一组已标注的训练样本集;QQ 为查询函数,用于在未标注的样本中查询信息量大的样本;UU 为整个未标注样本集;SS 为督导者,可以对未标注样本进行标注。
主动学习算法主要分为两阶段:
第一阶段为初始化阶段,随机从未标注样本中选取小部分,由督导者标注,作为训练集 建立初始分类器模型;
第二阶段为循环查询阶段,SS 从未标注样本集 UU 中,按照某种查询标准 QQ,选取一定的未标注样本进行标注,并加到训练样本集 LL 中, 重新训练分类器,直至达到训练停止标准为止。
主动学习算法是一个迭代的过程,分类器使用 迭代时反馈的样本进行训练,不断提升分类效率。
主动学习的实例:qq空间相册中的人脸识别技术
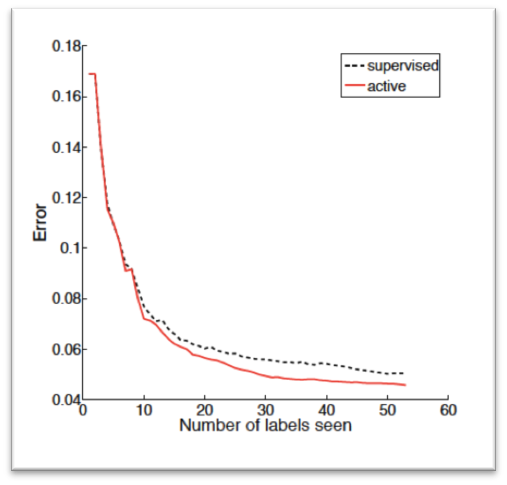
下图为Action learning在相同的标注样本数目下与监督学习算法的比较:
4. active learning与半监督学习的不同
很多人认为主动学习也属于半监督学习的范畴了,但实际上是不一样的,半监督学习和直推学习(transductive learning)以及主动学习,都属于利用未标记数据的学习技术,但基本思想还是有区别的。
如上所述,主动学习的“主动”,指的是主动提出标注请求,也就是说,还是需要一个外在的能够对其请求进行标注的实体(通常就是相关领域人员),即主动学习是交互进行的。
而半监督学习,特指的是学习算法不需要人工的干预,基于自身对未标记数据加以利用。
5. 参考文献
[2] 2012,主动学习算法综述