1、什么是“全文检索”(Full-Text Search)
①全文检索的概念
全文检索首先将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
全文检索(Full-Text Retrieval)是指以文本作为检索对象,找出含有指定词汇的文本。
全面、准确和快速是衡量全文检索系统的关键指标。
关于全文检索,我们要知道:
- 只处理文本。
- 不处理语义。
- 搜索时英文不区分大小写。
- 结果列表有相关度排序。
在信息检索工具中,全文检索是最具通用性和实用性的。
②全文检索的应用场景
我们使用Lucene,主要是做站内搜索,即对一个系统内的资源进行搜索。如BBS、BLOG中的文章搜索,网上商店中的商品搜索等。使用Lucene的项目有Eclipse、Jira等。一般不做互联网中资源的搜索,因为不易获取与管理海量资源(专业搜索方向的公司除外)。
③全文检索与数据库搜索的不同
全文检索不同于数据库的SQL查询。(他们所解决的问题不一样,解决的方案也不一样,所以不应进行对比)。在数据库中的搜索就是使用SQL,如:SELECT * FROM t WHERE content like ‘%ant%’。这样会有如下问题:
-
匹配效果:如搜索ant会搜索出planting这类结果。这样就会搜出很多无关的信息。
-
相关度排序:查出的结果没有相关度排序,不知道我想要的结果在哪一页。我们在使用百度搜索时,一般不需要翻页,为什么?因为百度做了相关度排序:为每一条结果打一个分数,这条结果越符合搜索条件,得分就越高,叫做相关度得分,结果列表会按照这个分数由高到低排列,所以第1页的结果就是我们最想要的结果。
-
速度及效率:全文检索的速度大大快于SQL的like搜索的速度。这是因为查询方式不同造成的,以查字典举例:数据库的like就是一页一页的翻,一行一行的找,而全文检索是先查目录,得到结果所在的页码,再直接翻到这一页。
-
2、什么是Lucene
Lucene是Apache下的一个开源的全文检索引擎工具包。它为软件开发人员提供一个简单易用的工具包(类库),以方便的在目标系统中实现全文检索的功能。
3、Lucene下载及安装
下载地址:Index of /dist/lucene/java
JDK要求:1.7及以上(从版本4.8开始,不支持1.7以下)
入门程序只需要添加以下jar包:
-
- mysql5.1驱动包:mysql-connector-java-5.1.7-bin.jar
- 核心包:lucene-core-4.10.3.jar
- 分析器通用包:lucene-analyzers-common-4.10.3.jar
- 查询解析器包:lucene-queryparser-4.10.3.jar
- junit包:junit-4.9.jar
4、Lucene实现全文检索流程
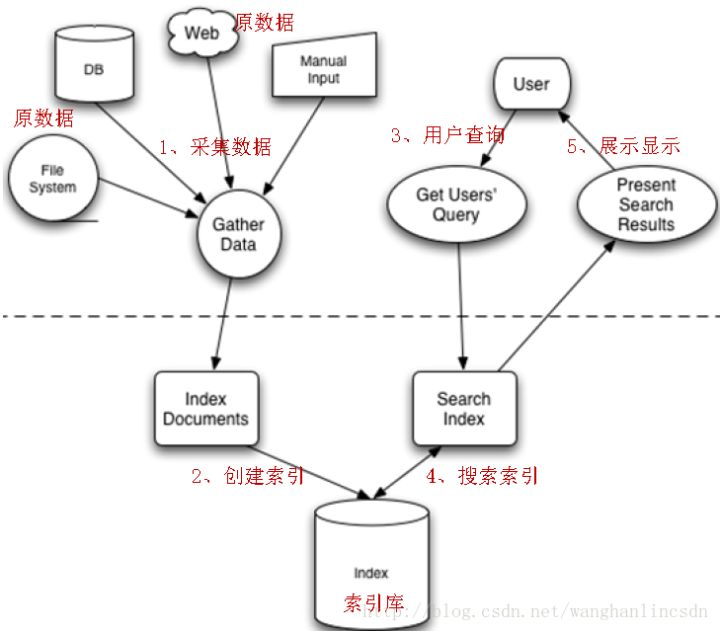
全文检索的流程分为两大部分:索引流程、搜索流程。
-
-
索引流程:即采集数据构建文档对象分析文档(分词)创建索引。
-
搜索流程:即用户通过搜索界面创建查询执行搜索,搜索器从索引库搜索渲染搜索结果。
-
5、Lucene索引源
全文检索要搜索的数据信息格式多种多样,拿搜索引擎(百度, google)来说,通过搜索引擎网站能搜索互联网站上的网页(html)、互联网上的音乐(mp3..)、视频(avi..)、pdf电子书等。
全文检索搜索的这些数据称为非结构化数据。
什么是非结构化数据?
-
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等。
如何对结构化数据搜索?
由于结构化数据是固定格式,所以就可以针对固定格式的数据设计算法来搜索,比如数据库like查询,like查询采用顺序扫描法,使用关键字匹配内容,对于内容量大的like查询速度慢。
①网页采集数据
因为目前搜索引擎主要搜索数据的来源是互联网,搜索引擎使用一种爬虫程序抓取网页( 通过http抓取html网页信息),以下是一些爬虫项目:
-
Solr(Apache Solr -) ,Solr是Apache的一个子项目,支持从关系数据库、xml文档中提取原始数据。
-
Nutch(http://lucene.apache.org/nutch), Nutch是Apache的一个子项目,包括大规模爬虫工具,能够抓取和分辨web网站数据。
-
Jsoup(http://jsoup.org/ ),Jsoup是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
- Heritrix(Heritrix: Internet Archive Web Crawler),Heritrix 是一个由Java开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
-
②数据库
针对大多数站内搜索功能,全文检索的数据源在数据库中,需要通过JDBC访问数据库中表的内容。
例如(取自互联网):

6、Lucene索引文件结构
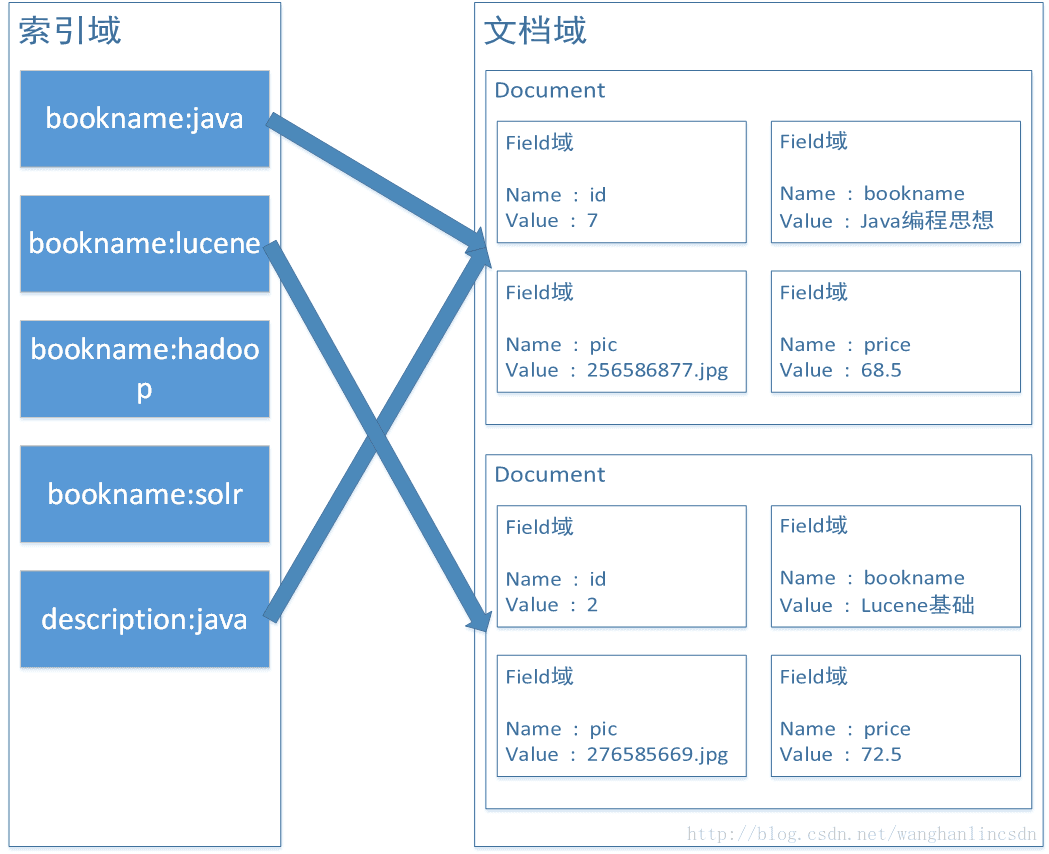
-
文档域:
非结构化的数据统一格式为document文档格式,一个文档有多个field域,不同的文档其field的个数可以不同,建议相同类型的文档包括相同的field。
本例子一个document对应一条book表的记录。 -
索引域:
将Document中的Field的内容进行分词,将分好的词创建索引,索引=Field域名:词。
索引域用于搜索,搜索程序将从索引域中搜索一个一个词,根据词找到对应的文档(Document)。 -
倒排索引表:
传统方法是先找到文件,如何在文件中找内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大就搜索慢。
倒排索引结构是根据内容(词语)找文档,倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它是在索引中匹配搜索关键字,由于索引内容量有限并且采用固定优化算法搜索速度很快,找到了索引中的词汇,词汇与文档关联,从而最终找到了文档。
7、Lucene创建索引过程
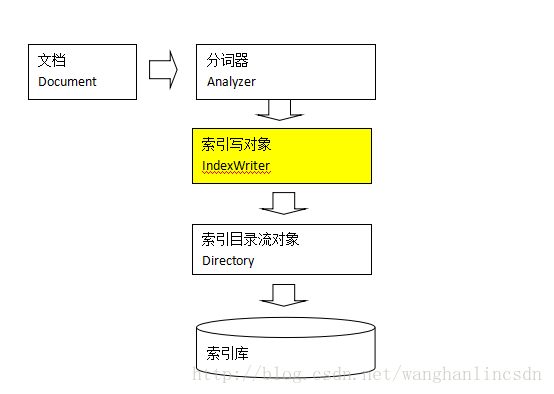
-
IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作。
-
Directory描述了索引的存储位置,底层封装了I/O操作,负责对索引进行存储。它是一个抽象类,它的子类常用的包括FSDirectory(在文件系统存储索引)、RAMDirectory(在内存存储索引)。
8、创建文档(Document)
在Lucene中,采集数据(从网站爬取或连接数据库)就是为了创建索引,创建索引需要先将采集的原始数据加工为文档,再由文档分词产生索引。文档(Document)中包含若干个Field域。
①采集数据
代码实现:
1 // 采集数据。 2 BookDao dao = new BookDaoImpl(); 3 List<Book> list = dao.queryBookList(); 4 5 // Document对象集合。 6 List<Document> docList = new ArrayList<Document>(); 7 8 // Document对象的引用,空指针。 9 Document doc = null; 10 11 for (Book book : list) { 12 13 // 创建Document对象,同时要创建Field对象。 14 doc = new Document(); 15 16 // 根据需求创建不同类型的Field。 17 Field id = new TextField("id", book.getId().toString(), Store.YES); 18 19 Field name = new TextField("name", book.getName(), Store.YES); 20 21 Field price = new TextField("price", book.getPrice().toString(), Store.YES); 22 23 Field pic = new TextField("pic", book.getPic(), Store.YES); 24 25 Field desc = new TextField("description", book.getDescription(), Store.YES); 26 27 // 把域(Field)添加到文档(Document)中。 28 doc.add(id); 29 doc.add(name); 30 doc.add(price); 31 doc.add(pic); 32 doc.add(desc); 33 34 // 将当前的文档对象添加到文档集合(docList)对象中。 35 docList.add(doc); 36 }
②使用文档分词
在对Docuemnt中的内容索引之前需要使用分词器进行分词 ,分词的主要过程就是分词、过滤两步。
-
-
分词就是将采集到的文档内容切分成一个一个的词,具体应该说是将Document中Field的value值切分成一个一个的词。
-
过滤包括去除标点符号、去除停用词(的、是、a、an、the等)、大写转小写、词的形还原(复数形式转成单数形参、过去式转成现在式等)。
-
什么是停用词?
停用词是为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词)。比如语气助词、副词、介词、连接词等,通常自身并无明确的意义,只有将其放入一个完整的句子中才有一定作用,如常见的“的”、“在”、“是”、“啊”等。
Lucene中自带了StandardAnalyzer,它可以对英文进行分词。
StandardAnalyzer结构:
-
-
Tokenizer就是分词器,对输入的语句进行分词。
-
TokenFilter是分词过滤器,比如过滤大小写转换、去除停用词等。
-
举例说明:
分词前:
Java is a world-wide programming language
分词后:
Java, is, a, world-wide, programming, language
-
-
Term是分词、过滤后的词,存在Field域中。对于某个Field域中,Term是具有象征性的,所以注意,在同一个Field域中,Term不能相同,Token可以相同。Term对于Token是一对一或一对多的关系。
-
Token是语汇单元,是经过分词、过滤后的。在同一个Field域中,多个相同的语汇单元
-
总之,不同的域中拆分出来的相同的单词对应不同的Term;相同的域中拆分出来的相同的单词对应相同的Term。
例如:
包含图书名字的Field域中的Java值与包含图书内容描述的Field域的Java值对应的是不同的Term。
③分词+创建索引
代码实现:
1 // 使用StandardAnalyzer对文档进行分词。 2 Analyzer analyzer = new StandardAnalyzer(); 3 4 // 创建索引库目录。 5 Directory directory = FSDirectory.open(new File("E:\index")); 6 7 // 创建IndexWriterConfig对象 8 IndexWriterConfig cfg = new IndexWriterConfig(Version.LATEST, analyzer); 9 10 // 创建IndexWriter对象 11 IndexWriter writer = new IndexWriter(directory, cfg); 12 13 // 通过IndexWriter对象添加文档对象(document) 14 for (Document document : docList) { 15 writer.addDocument(document); 16 } 17 18 // 关闭IndexWriter 19 writer.close();
整理自知乎 Lucene基础教程