参考:http://blog.csdn.net/h952520296/article/details/78873849 (参考)
官网下载:https://www.elastic.co/cn/downloads
下载好以后

上传到服务器:

此处为虚拟机:配置了4G内存,IP:192.168.179.138
这里为了测试模拟 log日志文件,使用了tomcat。
注意:本文将 解压好的文件 复制到 /home/zhanghui 目录下
日志收集方式有多种:这里主要提到两种
1. 将Log4j的日志输出到SocketAppender


log4j.rootLogger=INFO,console
# for package com.demo.elk, log would be sent to socket appender.
log4j.logger.com.demo.elk=DEBUG, socket
# appender socket
log4j.appender.socket=org.apache.log4j.net.SocketAppender
log4j.appender.socket.Port=4567
log4j.appender.socket.RemoteHost=centos2
log4j.appender.socket.layout=org.apache.log4j.PatternLayout
log4j.appender.socket.layout.ConversionPattern=%d [%-5p] [%l] %m%n
log4j.appender.socket.ReconnectionDelay=10000
# appender console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d [%-5p] [%l] %m%n
这里的端口号需要跟Logstash监听的端口号一致,这里是4567。
2. 通过配配置 logstash ,指定log文件目录的方式
input{
file {
path => "/home/zhanghui/apache-tomcat-8.5.20/logs/*.log"
start_position => beginning
ignore_older => 0
sincedb_path =>"/dev/null"
}
}
filter{
}
output{
elasticsearch {
hosts => ["localhost:9200"]
index => "tomcat-log"
}
stdout {}
}
ELK简介
Elasticsearch
Elasticsearch是一个实时的分布式搜索分析引擎, 它能让你以一个之前从未有过的速度和规模,去探索你的数据。它被用作全文检索、结构化搜索、分析以及这三个功能的组合:
* Wikipedia使用Elasticsearch提供带有高亮片段的全文搜索,还有search-as-you-type和did-you-mean的建议。
*卫报 使用Elasticsearch将网络社交数据结合到访客日志中,实时的给它的编辑们提供公众对于新文章的反馈。
* Stack Overflow将地理位置查询融入全文检索中去,并且使用more-like-this接口去查找相关的问题与答案。
* GitHub使用Elasticsearch对1300亿行代码进行查询。
然而Elasticsearch不仅仅为巨头公司服务。它也帮助了很多初创公司,像Datadog和Klout, 帮助他们将想法用原型实现,并转化为可扩展的解决方案。Elasticsearch能运行在你的笔记本电脑上,或者扩展到上百台服务器上去处理PB级数据。
Elasticsearch中没有一个单独的组件是全新的或者是革命性的。全文搜索很久之前就已经可以做到了, 就像早就出现了的分析系统和分布式数据库。革命性的成果在于将这些单独的,有用的组件融合到一个单一的、一致的、实时的应用中。它对于初学者而言有一个较低的门槛, 而当你的技能提升或需求增加时,它也始终能满足你的需求。
Logstash
Logstash是一款强大的数据处理工具,它可以实现数据传输,格式处理,格式化输出,还有强大的插件功能,常用于日志处理。
工作流程
Logstash工作的三个阶段:
input数据输入端,可以接收来自任何地方的源数据。
* file:从文件中读取
* syslog:监听在514端口的系统日志信息,并解析成RFC3164格式。
* redis:从redis-server list中获取
* beat:接收来自Filebeat的事件
Filter数据中转层,主要进行格式处理,数据类型转换、数据过滤、字段添加,修改等,常用的过滤器如下。
* grok:通过正则解析和结构化任何文本。Grok目前是logstash最好的方式对非结构化日志数据解析成结构化和可查询化。logstash内置了120个匹配模式,满足大部分需求。
* mutate:在事件字段执行一般的转换。可以重命名、删除、替换和修改事件字段。
* drop:完全丢弃事件,如debug事件。
* clone:复制事件,可能添加或者删除字段。
* geoip:添加有关IP地址地理位置信息。
output是logstash工作的最后一个阶段,负责将数据输出到指定位置,兼容大多数应用,常用的有:
* elasticsearch:发送事件数据到Elasticsearch,便于查询,分析,绘图。
* file:将事件数据写入到磁盘文件上。
* mongodb:将事件数据发送至高性能NoSQL mongodb,便于永久存储,查询,分析,大数据分片。
* redis:将数据发送至redis-server,常用于中间层暂时缓存。
* graphite:发送事件数据到graphite。http://graphite.wikidot.com/
* statsd:发送事件数据到statsd。
kibana
kibana是一个开源和免费的工具,它可以为Logstash和ElasticSearch提供的日志分析友好的Web界面,可以帮助您汇总、分析和搜索重要数据日志。
################################################################################################################################
一.确保安装了java1.8以上版本 用jdk不用openjdk
Elasticsearch官方建议使用Oracle的JDK8,在安装之前首先要确定下机器有没有安装JDK.
rpm-qa | grep java
如果有,有可能是系统自带的openjdk,而非oracle的jdk。可以使用
rpm–e --nodeps java-1.8.0-openjdk-headless-1.8.0.101-3.b13.el7_2.x86_64
卸载所有带有Java的文件,然后进行重新安装。
检查是否删除
java–version
将jdk-8u131-linux-x64.tar放入/usr/local目录下并解压缩
将以下内容添加至/etc/profile
#set java environment
exportJAVA_HOME=/usr/local/jdk1.8.0_131
exportJRE_HOME=${JAVA_HOME}/jre
exportCLASSPATH=.:${JAVA_HOME}/lib/dt.JAVA_HOME/lib/tools.jar:${JRE_HOME}/lib
exportPATH=${JAVA_HOME}/bin:${PATH}
保存后运行source /etc/profile使环境变量生效
输入java -version确认是否安装成功。
[root@localhostlocal]# java -version
javaversion "1.8.0_131"
Java(TM)SE Runtime Environment (build 1.8.0_131-b13)
JavaHotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
二.修改系统参数,确保系统有足够资源启动ES(很重要,否则启动时候会报错或警告)
2.1设置内核参数
/etc/sysctl.conf
#增加以下参数
vm.max_map_count=655360
执行以下命令,确保生效配置生效:
sysctl–p
2.2设置资源参数
/etc/security/limits.conf
#修改
* soft nofile 65536
* hard nofile 131072
* soft nproc 65536
*hard nproc 131072
注意:以下三行实际操作过程中并没有设置,另外本文中使用的 系统用户是 zhanghui, 提示es和solr都不建议用root用户启动,实际启动中会提示你
vi /etc/security/limits.d/20-nproc.conf
#设置elk用户参数
elk soft nproc 65536
三.安装elasticsearch
3.1 解压到/home/elasticsearch中,修改elasticsearch/config/elasticsearch.yml中:
#这里指定的是集群名称,需要修改为对应的,开启了自发现功能后,ES会按照此集群名称进行集群发现
cluster.name:thh_dev1
#数据目录
path.data:/home/data/elk/data
# log目录
path.logs:/home/data/elk/logs
# 节点名称
node.name: node-1
#修改一下ES的监听地址,这样别的机器也可以访问
network.host:0.0.0.0 注意:此处需要修改或开放,否则在虚拟机的宿主机上无法通过IP:9200访问api
#默认的端口号
http.port:9200
3.2 进入elasticsearch的bin目录,使用./elasticsearch -d命令启动elasticsearch。
使用
ps-ef|grep elasticsearch
查看进程
使用
curl-X GEThttp://localhost:9200
查看信息

注意:es比较吃内存和硬盘,虚拟机启动es时 ,宿主机上监控磁盘使用率都是100%的。 另外es启动会有点慢,耐心等候。
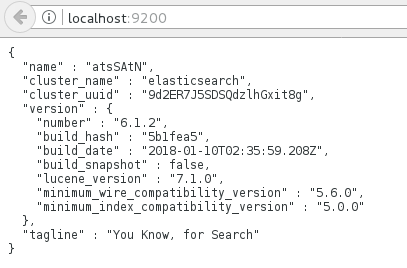
3.3 浏览器访问http://localhost:9200可以看到Elasticsearch的信息
{
name:"bWXgrRX",
cluster_name:"elasticsearch_ywheel",
cluster_uuid:"m99a1gFWQzKECuwnBfnTug",
version:{
number:"6.1.0",
build_hash:"f9d9b74",
build_date:"2017-02-24T17:26:45.835Z",
build_snapshot:false,
lucene_version:"6.4.1"
},
tagline:"You Know, for Search"
}
3.4 客户端网页访问可能需要关掉防火墙:
Systemctl stop firewalld.service
四.安装logstash
4.1 首先将logstash解压到/home/logstash中
4.2 创建配置文件 注意:建议放在 config下,文件名随意
创建logstash-simple.conf文件并且保存到
/home/logstash/config下
完整路径应该是 /home/logstash/config/xxxx.conf
注:这里可以参考我本文最上面的一个配置,实际中是采用上面的配置,这里原文说的比较乱。
#########################################################
input{
file {
path => "/home/parallels/Desktop/data/elk/logs/*.log"
start_position => beginning
ignore_older => 0
sincedb_path =>"/dev/null"
}}
filter{
grok {
match => { "message" =>"%{IPORHOST:clientip} - %{USER:auth} [%{HTTPDATE:timestamp}] "(?:%{WORD:verb}%{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})"%{NUMBER:response} (?:%{NUMBER:bytes}|-)"}
}date {
match => [ "timestamp" ,"dd/MMM/YYYY:HH:mm:ss +0800" ]
}
}
output{
elasticsearch {}
stdout {}
}
##############################################################
其中path => "/home/parallels/Desktop/data/elk/logs/*.log"为日志路径
Grok后面是正则表达式,筛选logstash要读取的关键信息。
读取kafka的消息
################################################################
input {
kafka {
bootstrap_servers => "172.30.3.11:9092"
topics=>["accountrisksvrlog","dealserver_log","estranslog","gatelog","profitsvrlog","sttransserver_log"]
codec => plain
consumer_threads => 4
decorate_events => true
}
}
output {
elasticsearch {
hosts => ["172.30.3.11:9200"]
index => "all-log"
}
}
##################################################################
4.3 进入logstash的bin目录,使用
bin/logstash -f config/XXXXXX.conf
命令读取配置信息并启动logstash。

五.安装kibana:
5.1 解压kibana源码包到/home/kibana
5.2 配置kibana
编辑kibana.yml配置文件
/home/kibana/config/kibana.yml
修改以下参数:
#开启默认端口5601如果5601被占用可用5602或其他
server.port:5601
server.host:“localhost”#站点地址
elasticsearch.url:http://localhost:9200#指向elasticsearch服务的ip地址
kibana.index:“.kibana”
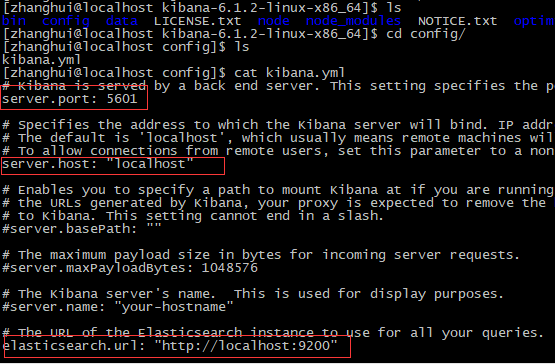
注意:这里主要把 红框内的配置放开即可。
5.3 运行cd /home/parallels/Desktop/kibana/bin运行./kibana

忽略警告
通过kibana窗口观察你的结果:
http://localhost:5601
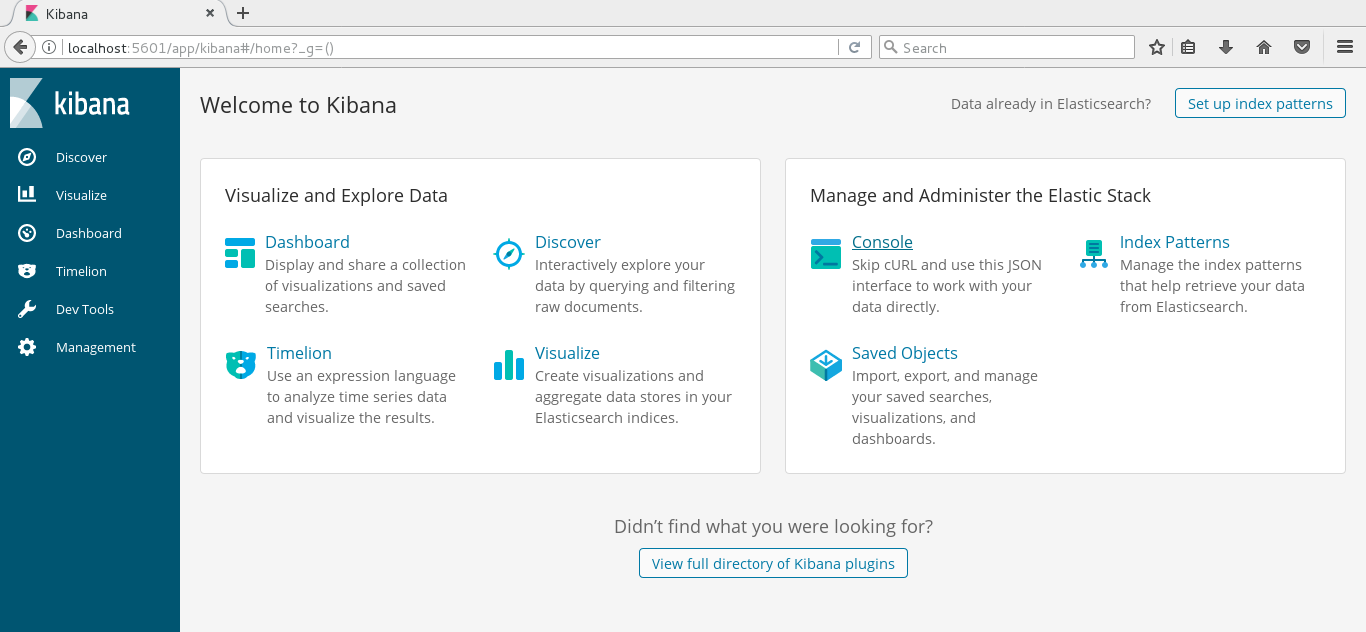
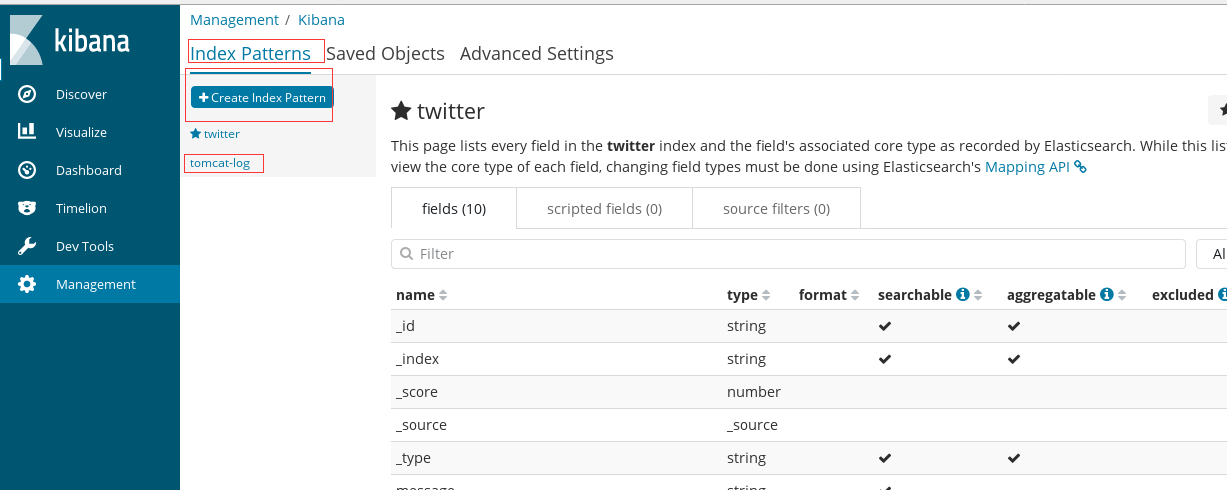
一开始是在setting页面,要你指定访问的index,这里就用缺省的logstash-*就行了。
注意:由于我在logstash配置中指定的 index 是 tomcat-log,所以kibana这里要设置下
默认进来会显示设置界面的,我这里已经配好,但是可以新增其他的。通过下面这种方式,点击左侧 菜单 management
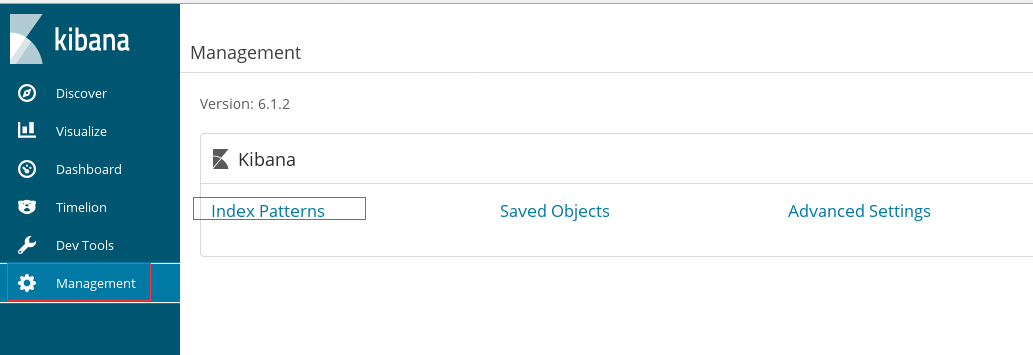

下一页会提示是否使用 Time Filter,我这里不使用。

最后完成,即可。在 左侧菜单Discover 中可以看到配置。
4.4 使用kibana
注意:这里由于是使用tomcat做日志生产者,所以 简单查询下 以供参考。 这里的查询语法界面提示是使用lucene的语法
默认或选择 tomcat-log, 点击查询,会查出 366个hits。
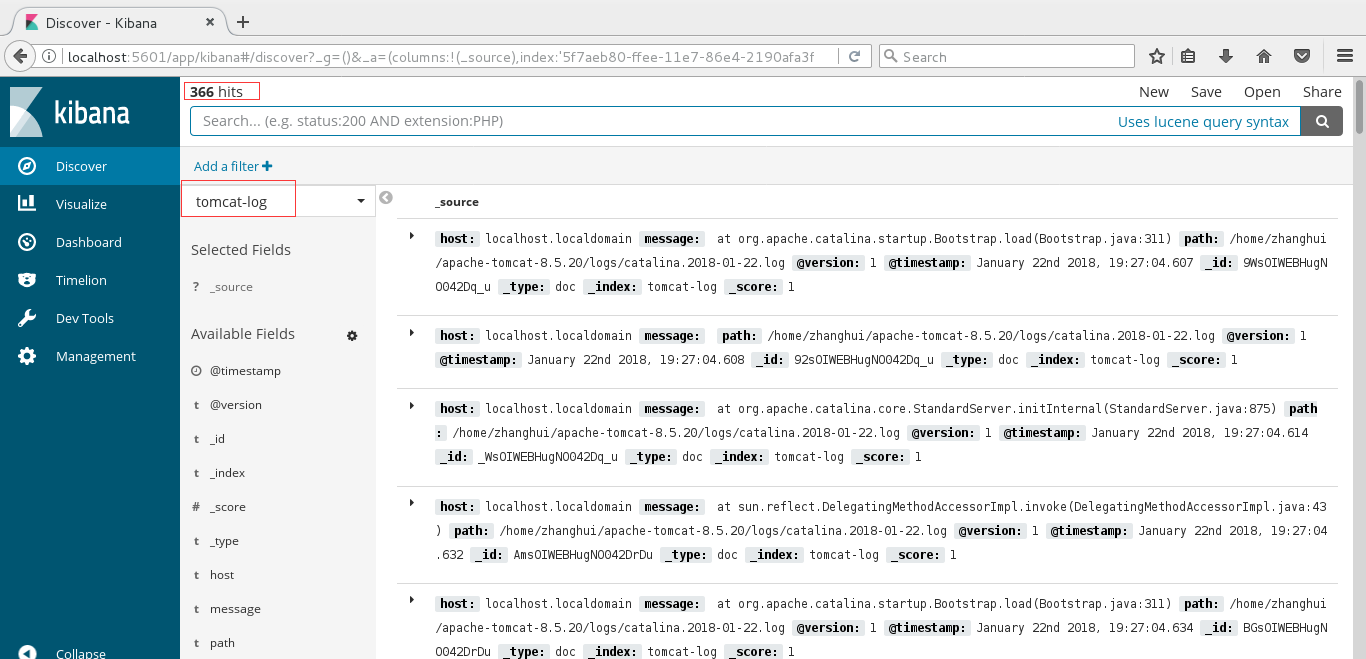
添加过滤条件:

完美收工! 其实入门安装很简单,主要是 未来的微调吧。