前两节我们分别看了FastThreadLocal和ThreadLocal的源码分析,并且在第八节的时候讲到了处理一个客户端的接入请求,一个客户端是接入进来的,是怎么注册到多路复用器上的。那么这一节我们来一起看下客户端接入完成之后,是怎么实现读写操作的?我们自己想一下,应该就是为刚刚读取的数据分配一块缓冲区,然后把channel中的信息写入到缓冲区中,然后传入到各个handler链上,分别进行处理。那Netty是怎么去分配一块缓冲区的呢?这个就涉及到了Netty的内存模型。
当然,我们在第一节的时候,就详细了讲解了NIO的ByteBuffer。但是操作起来及其的繁琐,比如我们从写转到读,要必须执行flip()方法。因此,Netty看不下去了,自己写了一个ByteBuf。这里也简单看下这个ByteBuf吧,看看方便在哪里?看下ByteBuf的javadoc
* {@link ByteBuf} provides two pointer variables to support sequential * read and write operations - {@link #readerIndex() readerIndex} for a read * operation and {@link #writerIndex() writerIndex} for a write operation * respectively. The following diagram shows how a buffer is segmented into * three areas by the two pointers: * * <pre> * +-------------------+------------------+------------------+ * | discardable bytes | readable bytes | writable bytes | * | | (CONTENT) | | * +-------------------+------------------+------------------+ * | | | | * 0 <= readerIndex <= writerIndex <= capacity * </pre>
上面英文的大体意思就是, 说ByteBuf提供了两个指针变量去支持读和写操作。 readerIndex 是针对读操作, writerIndex 是针对写操作, 上面的图就是又这个两个指针分割成的三部分。左边是读过的区域,可以认为是作废的区域,中间是写完但是没有读的区域,右边是待写的区域。 readerIndex 代表 读到的位置, writerIndex 代表写到的位置, capacity 最大容量。再看一个图,理解一个方法。
* <pre> * BEFORE discardReadBytes() // 执行 discardReadBytes() 方法之前 , 假如是下面这样 * * +-------------------+------------------+------------------+ * | discardable bytes | readable bytes | writable bytes | * +-------------------+------------------+------------------+ * | | | | * 0 <= readerIndex <= writerIndex <= capacity * * * AFTER discardReadBytes() // 执行之后 , 写索引 =- 读索引 ; 读索引变成 0 * * +------------------+--------------------------------------+ * | readable bytes | writable bytes (got more space) | * +------------------+--------------------------------------+ * | | | * readerIndex (0) <= writerIndex (decreased) <= capacity * </pre>
* <pre> * BEFORE clear() // 执行clear()方法之前假如是下面这样 * * +-------------------+------------------+------------------+ * | discardable bytes | readable bytes | writable bytes | * +-------------------+------------------+------------------+ * | | | | * 0 <= readerIndex <= writerIndex <= capacity * * * AFTER clear() // 执行之后 读索引和写索引都会变成0 , 那么整个缓冲区都会变成可写区域。 * * +---------------------------------------------------------+ * | writable bytes (got more space) | * +---------------------------------------------------------+ * | | * 0 = readerIndex = writerIndex <= capacity * </pre>
ByteBuf 先介绍到这, 有个读写索引之后,就会方便很多,不需要再执行flip类似的操作。
我们继续按照之前的节奏来debug, 我们先启动服务端,然后启动一个客户端。 断点打在哪里呢? 就先打在NioEventLoop的 processSelectedKey() 方法处理accept和read操作的那个判断那里。就是下面这里

public final void read() { final ChannelConfig config = config(); // channel的配置,前面涉及到了,不说了 if (shouldBreakReadReady(config)) { clearReadPending(); return; } final ChannelPipeline pipeline = pipeline(); // 获取channel对应的pipeline final ByteBufAllocator allocator = config.getAllocator(); // 获取缓冲区分配器 ,这里是PooledByteBufAllocator final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle(); // 获取之前在创建channel配置器的时候传入的AdaptiveRecvByteBufAllocator,创建时候的代码如下图 allocHandle.reset(config); // 重置一些变量 ByteBuf byteBuf = null; boolean close = false; try { do { byteBuf = allocHandle.allocate(allocator); // 这里是重点,分配缓冲区,后面铺开讲。 allocHandle.lastBytesRead(doReadBytes(byteBuf)); // 将channel中的数据读取到刚刚申请的缓冲区中,然后对刚刚读取的字节数进行一下记录,方便下一次对获取缓冲区的大小进行动态的调节 if (allocHandle.lastBytesRead() <= 0) { // 没有读取到数据,则释放缓冲区 // nothing was read. release the buffer. byteBuf.release(); byteBuf = null; close = allocHandle.lastBytesRead() < 0; if (close) { // There is nothing left to read as we received an EOF. readPending = false; } break; } allocHandle.incMessagesRead(1); // 读取的总信息++ readPending = false; pipeline.fireChannelRead(byteBuf); // handler链表开始执行channelRead方法。 byteBuf = null; } while (allocHandle.continueReading()); allocHandle.readComplete(); pipeline.fireChannelReadComplete(); // handler链表开始执行channelReadComplete方法。 if (close) { closeOnRead(pipeline); } } catch (Throwable t) { handleReadException(pipeline, byteBuf, t, close, allocHandle); } finally { // Check if there is a readPending which was not processed yet. // This could be for two reasons: // * The user called Channel.read() or ChannelHandlerContext.read() in channelRead(...) method // * The user called Channel.read() or ChannelHandlerContext.read() in channelReadComplete(...) method // // See https://github.com/netty/netty/issues/2254 if (!readPending && !config.isAutoRead()) { removeReadOp(); } } } }
创建channel配置类的时候传入的AdaptiveRecvByteBufAllocator()

上面重要的地方,我们展开来讲,先看 PooledByteBufAllocator 。我们跟下去。发现这个分配器其实是给了一个默认的实例

继续跟下去,我们看到了一段静态代码块,那么我们直接debug看下

根据配置,给到了一个池化的分配器。继续进去,进入到了 PooledByteBufAllocator 的构造函数。

发现创建了一个线程级别的 PoolThreadLocalCache , 并且传入了true ,代表所有的线程都使用Cache。 既然看到了这里,就直接看着这个缓存是啥。
final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> { // 继承了 FastThreadLocal, 存储的内容是 PoolThreadCache 。上节我们刚刚一起看了这个,这里就很舒服了。 private final boolean useCacheForAllThreads; PoolThreadLocalCache(boolean useCacheForAllThreads) { this.useCacheForAllThreads = useCacheForAllThreads; } @Override protected synchronized PoolThreadCache initialValue() { // 在执行get方法的时候会执行initialValue()方法,来初始化数据。 final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas); // 堆内存Arena; 这里涉及到PoolArena ,我们后面会重点讲, 这里是比较所有PoolArena看下哪个被使用最少,找到最少那个,
// 使得线程均等使用Arena。 final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas); // 直接内存Arena; 原理跟上面一样 Thread current = Thread.currentThread(); if (useCacheForAllThreads || current instanceof FastThreadLocalThread) { // 线程是FastTreadLocalTread 这里在NioEventLoop初始化的时候线程就被封装过了。 return new PoolThreadCache( // 创建一个PoolTreadCache实例 heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize, DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL); } // No caching so just use 0 as sizes. return new PoolThreadCache(heapArena, directArena, 0, 0, 0, 0, 0); } @Override protected void onRemoval(PoolThreadCache threadCache) { // 释放的时候,为子类提供的空方法 threadCache.free(); } private <T> PoolArena<T> leastUsedArena(PoolArena<T>[] arenas) { if (arenas == null || arenas.length == 0) { return null; } PoolArena<T> minArena = arenas[0]; for (int i = 1; i < arenas.length; i++) { PoolArena<T> arena = arenas[i]; if (arena.numThreadCaches.get() < minArena.numThreadCaches.get()) { minArena = arena; } } return minArena; } }
再继续说 PoolThreadCache 就说不下去了,一会再说,然后我们先看一个模型,涉及到的名词有:PoolArena 、 Chunk、 Page、 subPage。
先看Chunk的模型,使用了和jemalloc一样的分配算法,伙伴分配算法。

看上面的图,把Chunk分割成了2048个Page, chunk 的大小是 16M, 那么 每个Page 就是 8k, 树的每个最左子节点 编号都是 2 的 层数 次方, 比如 11 层 第一个就是 2 ^ 11 = 2048 。
当然 page 的大小是 8k, 那么能不能更加细粒度呢? 当然可以,那就是subPage, 最小单位,不能再分,最小切分单位为16B, 当然这里 page 是怎么划分成subPage的呢? 其实是根据该Page第一次分配的大小决定的,比如 第一次是 16B, 那么 就会被切分成 8k / 16B = 512 个SubPage, 如果第一次是 32B, 分成 8k / 32B = 256 个SubPage。
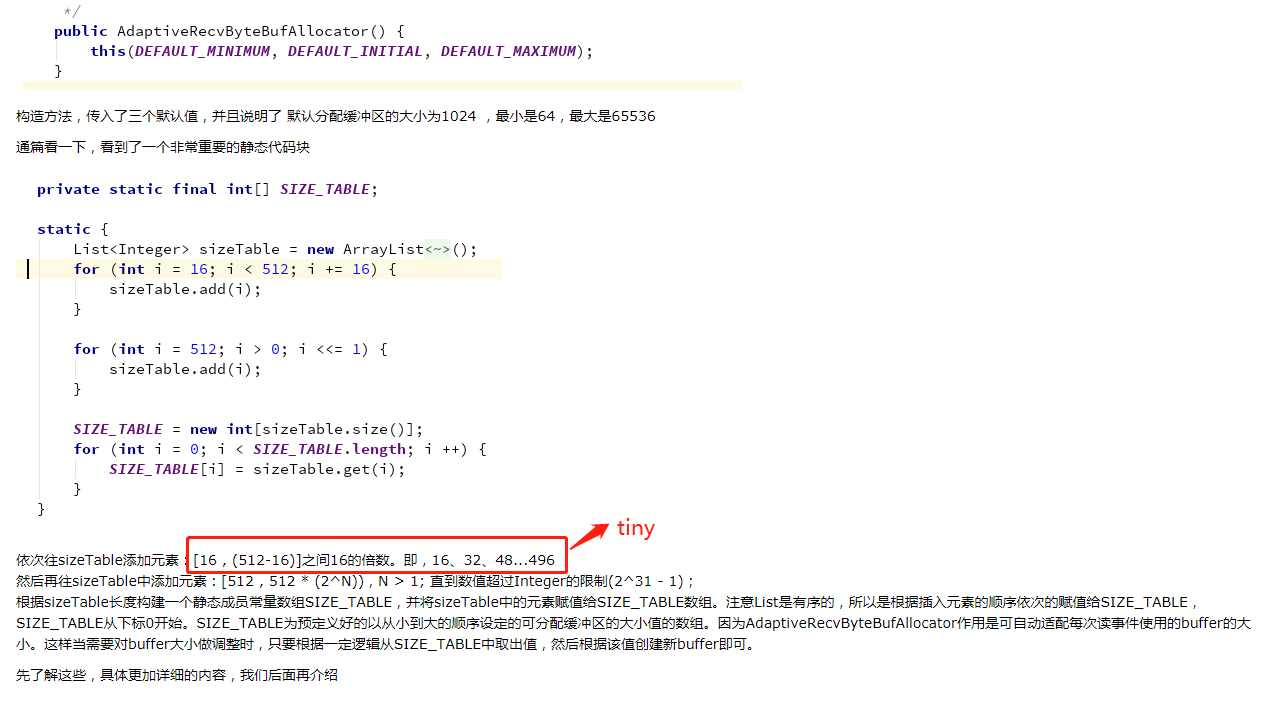
当然根据分配的请求大小,我们分为几个级别:
Tiny : < 512B的请求 分为 16 32 48 64 ....
Small : 512B <= 且 < 8K(PageSize)的请求
Normal : 8K <= 且 <= 16MB(ChunkSize)的请求
Huge : > 16MB(ChunkSize)的请求
好了,大概知道这么一个模型之后,我们继续看 PooledByteBufAllocator 的构造方法,
1 public PooledByteBufAllocator(boolean preferDirect, int nHeapArena, int nDirectArena, int pageSize, int maxOrder, 2 int tinyCacheSize, int smallCacheSize, int normalCacheSize, 3 boolean useCacheForAllThreads, int directMemoryCacheAlignment) { 4 super(preferDirect); 5 threadCache = new PoolThreadLocalCache(useCacheForAllThreads); // 创建一个Cache实例,但是这里并没有调用initialValue()方法 6 this.tinyCacheSize = tinyCacheSize; // 512 这个其实是tiny缓存队列的长度, 后面我们在说PoolThreadCache时会再介绍 7 this.smallCacheSize = smallCacheSize; // 256 small队列长度 8 this.normalCacheSize = normalCacheSize; // 64 normal队列长度 9 chunkSize = validateAndCalculateChunkSize(pageSize, maxOrder); // 计算chunk大小 , 其中maxOrder 就是上面模型的层数 11 , 那么chunkSize 其实就是 pageSize 左移 11位 , 10 // 也就是 8192 * 2^11 = 16M 11 12 if (nHeapArena < 0) { 13 throw new IllegalArgumentException("nHeapArena: " + nHeapArena + " (expected: >= 0)"); 14 } 15 if (nDirectArena < 0) { 16 throw new IllegalArgumentException("nDirectArea: " + nDirectArena + " (expected: >= 0)"); 17 } 18 19 if (directMemoryCacheAlignment < 0) { 20 throw new IllegalArgumentException("directMemoryCacheAlignment: " 21 + directMemoryCacheAlignment + " (expected: >= 0)"); 22 } 23 if (directMemoryCacheAlignment > 0 && !isDirectMemoryCacheAlignmentSupported()) { 24 throw new IllegalArgumentException("directMemoryCacheAlignment is not supported"); 25 } 26 27 if ((directMemoryCacheAlignment & -directMemoryCacheAlignment) != directMemoryCacheAlignment) { 28 throw new IllegalArgumentException("directMemoryCacheAlignment: " 29 + directMemoryCacheAlignment + " (expected: power of two)"); 30 } 31 32 int pageShifts = validateAndCalculatePageShifts(pageSize); // 2 ^ 13 = 8192 也就是pageSize 这里的pageShifts = 13, 这里怎么算的呢,看下面的方法 33 34 if (nHeapArena > 0) { // 堆内存区域竞技场数组个数 35 heapArenas = newArenaArray(nHeapArena); 36 List<PoolArenaMetric> metrics = new ArrayList<PoolArenaMetric>(heapArenas.length); 37 for (int i = 0; i < heapArenas.length; i ++) { 38 PoolArena.HeapArena arena = new PoolArena.HeapArena(this, 39 pageSize, maxOrder, pageShifts, chunkSize, 40 directMemoryCacheAlignment); 41 heapArenas[i] = arena; 42 metrics.add(arena); 43 } 44 heapArenaMetrics = Collections.unmodifiableList(metrics); 45 } else { 46 heapArenas = null; 47 heapArenaMetrics = Collections.emptyList(); 48 } 49 50 if (nDirectArena > 0) { // 直接内存竞技场数组个数 51 directArenas = newArenaArray(nDirectArena); // 创建 PoolArena 数组 大小 8 52 List<PoolArenaMetric> metrics = new ArrayList<PoolArenaMetric>(directArenas.length); 53 for (int i = 0; i < directArenas.length; i ++) { 54 PoolArena.DirectArena arena = new PoolArena.DirectArena( 55 this, pageSize, maxOrder, pageShifts, chunkSize, directMemoryCacheAlignment); // 实例化 PoolArena ,一会我们详细说这个 56 directArenas[i] = arena; 57 metrics.add(arena); 58 } 59 directArenaMetrics = Collections.unmodifiableList(metrics); // 一些信息的测度统计,忽略不看这个 60 } else { 61 directArenas = null; 62 directArenaMetrics = Collections.emptyList(); 63 } 64 metric = new PooledByteBufAllocatorMetric(this); 65 } 66 67 private static int validateAndCalculatePageShifts(int pageSize) { 68 if (pageSize < MIN_PAGE_SIZE) { 69 throw new IllegalArgumentException("pageSize: " + pageSize + " (expected: " + MIN_PAGE_SIZE + ")"); 70 } 71 72 if ((pageSize & pageSize - 1) != 0) { 73 throw new IllegalArgumentException("pageSize: " + pageSize + " (expected: power of 2)"); 74 } 75 76 // Logarithm base 2. At this point we know that pageSize is a power of two. 77 return Integer.SIZE - 1 - Integer.numberOfLeadingZeros(pageSize); // Integer.numberOfLeadingZeros 该方法的作用是返回无符号整型i的最高非零位前面的0的个数,包括符号位在内; 78 // 比如说,8192的二进制表示为 0000 0000 0000 0000 0010 0000 0000 0000 java的整型长度为32位。那么这个方法返回的就是 18 ,那么整个方法 结果就是 32 - 1 - 18 = 13 79 }
上面既然提到了堆内存和堆外直接内存,也就是大家说的Netty的零拷贝。
1、Netty的接收和发送采用直接内存,就是使用堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存进行Socket读写,JVM会将堆内存Buffer拷贝一份到直接内存中,然后才写入Socket中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
2. Netty提供了组合Buffer对象,可以聚合多个ByteBuffer对象,用户可以像操作一个Buffer那样方便的对组合Buffer进行操作,避免了传统通过内存拷贝的方式将几个小Buffer合并成一个大的Buffer。
3. Netty的文件传输采用了transferTo方法,它可以直接将文件缓冲区的数据发送到目标Channel,避免了传统通过循环write方式导致的内存拷贝问题。
跟我们理解的操作系统的这种普通零拷贝还不一样, 我觉得Netty的这种零拷贝完全是在用户空间的,当然这只是我自己的理解,不一定正确。
关于 AdaptiveRecvByteBufAllocator ,我在 Netty源码分析--创建Channel(三) 最后有明确说明,所以这里贴出来给大家回顾一下。
上面说到了,实例化PoolArena, 那我们就继续看这个的构造函数
protected PoolArena(PooledByteBufAllocator parent, int pageSize, int maxOrder, int pageShifts, int chunkSize, int cacheAlignment) { this.parent = parent; this.pageSize = pageSize; // 根据上面的分析,这个是8192 this.maxOrder = maxOrder; // chunk 满二叉树高度 11 this.pageShifts = pageShifts; // 用于辅助计算的 13 ===> 2 ^ 13 = 8192 this.chunkSize = chunkSize; // 16M chunk 大小 directMemoryCacheAlignment = cacheAlignment; // 对齐基准 directMemoryCacheAlignmentMask = cacheAlignment - 1; // 用于对齐内存 subpageOverflowMask = ~(pageSize - 1); // -8192 用于判断 是否是 tiny 和 small tinySubpagePools = newSubpagePoolArray(numTinySubpagePools); // subPage 双向链表 numTinySubpagePools = 32 为啥是32呢? 上面提到是16为单位递增,那么就是 512/16 = 512 >>> 4 = 32 for (int i = 0; i < tinySubpagePools.length; i ++) { tinySubpagePools[i] = newSubpagePoolHead(pageSize); // 初始化链表 } numSmallSubpagePools = pageShifts - 9; // 13 - 9 = 4 smallSubpagePools = newSubpagePoolArray(numSmallSubpagePools); // subPage 双向链表 numSmallSubpagePools = 4 也可以理解为 512 << 4 = 8192(Small最大值) 所以是 4 for (int i = 0; i < smallSubpagePools.length; i ++) { smallSubpagePools[i] = newSubpagePoolHead(pageSize); // 初始化链表 } q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, chunkSize); // chunk的链表 随着chunk使用率在这几个链表下转义,具体看底下我百度到的图 q075 = new PoolChunkList<T>(this, q100, 75, 100, chunkSize); q050 = new PoolChunkList<T>(this, q075, 50, 100, chunkSize); q025 = new PoolChunkList<T>(this, q050, 25, 75, chunkSize); q000 = new PoolChunkList<T>(this, q025, 1, 50, chunkSize); qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, chunkSize); q100.prevList(q075); q075.prevList(q050); q050.prevList(q025); q025.prevList(q000); q000.prevList(null); qInit.prevList(qInit); List<PoolChunkListMetric> metrics = new ArrayList<PoolChunkListMetric>(6); metrics.add(qInit); metrics.add(q000); metrics.add(q025); metrics.add(q050); metrics.add(q075); metrics.add(q100); chunkListMetrics = Collections.unmodifiableList(metrics); }
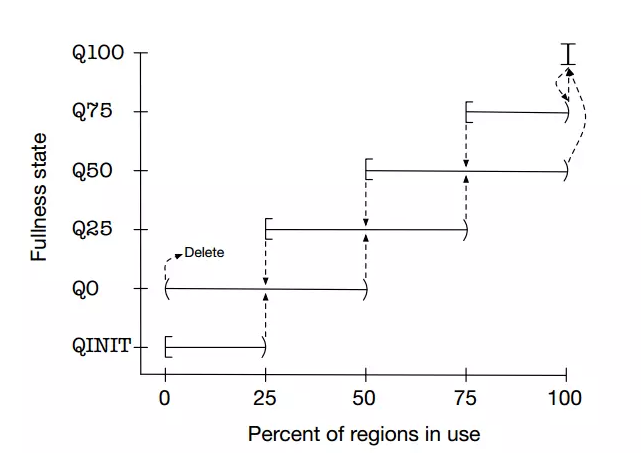
为了提高内存分配效率并减少内部碎片,jemalloc算法将Arena切分为小块Chunk,根据每块的内存使用率又将小块组合为以下几种状态:QINIT,Q0,Q25,Q50,Q75,Q100。Chunk块可以在这几种状态间随着内存 使用率的变化进行转移,内存使用率和状态转移可参见下图:

说完上面的,还记得上面说的这段吗?我们从这里进入,


猜测下一次会分配多大内存,这里默认是1024

刚刚说了 直接内存和 堆内存,这里Netty默认走的是直接内存分支
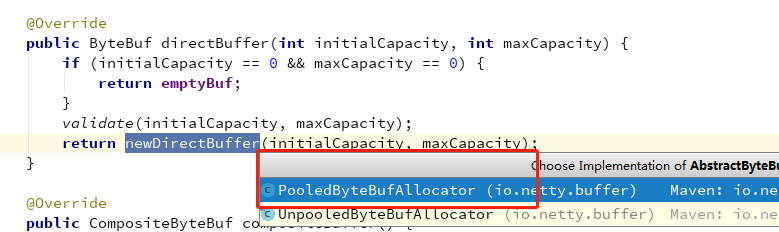
根据上面的分析,这里是进入一个池化的分配器
1 protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) { 2 PoolThreadCache cache = threadCache.get();// 获取缓存,这里的get方法会调用初始化方法 initialValue() ,会实例化 PoolThreadCache 3 PoolArena<ByteBuffer> directArena = cache.directArena; // 获取直接内存竞技场 4 5 final ByteBuf buf; 6 if (directArena != null) { // 肯定不为空 7 buf = directArena.allocate(cache, initialCapacity, maxCapacity); // 分配方法 8 } else { 9 buf = PlatformDependent.hasUnsafe() ? 10 UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) : 11 new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity); 12 } 13 14 return toLeakAwareBuffer(buf); 15 }
上面多次提到 PoolThreadCache ,那就分析一下, 先看构造方法
PoolThreadCache(PoolArena<byte[]> heapArena, PoolArena<ByteBuffer> directArena, int tinyCacheSize, int smallCacheSize, int normalCacheSize, int maxCachedBufferCapacity, int freeSweepAllocationThreshold) { if (maxCachedBufferCapacity < 0) { // 这个是最大缓存容量大小 这里默认是32K,后面我们解释一下为啥会有这个限制 throw new IllegalArgumentException("maxCachedBufferCapacity: " + maxCachedBufferCapacity + " (expected: >= 0)"); } this.freeSweepAllocationThreshold = freeSweepAllocationThreshold; // 分配次数的阈值 this.heapArena = heapArena; this.directArena = directArena; if (directArena != null) { tinySubPageDirectCaches = createSubPageCaches( tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny); // 创建subPage缓存数组 ,tinyCacheSize = 512 , PoolArena.numTinySubpagePools = 32 smallSubPageDirectCaches = createSubPageCaches( smallCacheSize, directArena.numSmallSubpagePools, SizeClass.Small); // 创建subPage缓存数组 ,smallCacheSize = 256, PoolArena.numSmallSubpagePools = 4 numShiftsNormalDirect = log2(directArena.pageSize); // 2 ^ 13 = 8192 这里是 13 normalDirectCaches = createNormalCaches( normalCacheSize, maxCachedBufferCapacity, directArena); // 创建Normal缓存数组 , normalCacheSize = 64 , maxCachedBufferCapacity = 32K directArena.numThreadCaches.getAndIncrement(); } else { // No directArea is configured so just null out all caches tinySubPageDirectCaches = null; smallSubPageDirectCaches = null; normalDirectCaches = null; numShiftsNormalDirect = -1; } if (heapArena != null) { // Create the caches for the heap allocations tinySubPageHeapCaches = createSubPageCaches( tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny); smallSubPageHeapCaches = createSubPageCaches( smallCacheSize, heapArena.numSmallSubpagePools, SizeClass.Small); numShiftsNormalHeap = log2(heapArena.pageSize); normalHeapCaches = createNormalCaches( normalCacheSize, maxCachedBufferCapacity, heapArena); heapArena.numThreadCaches.getAndIncrement(); } else { // No heapArea is configured so just null out all caches tinySubPageHeapCaches = null; smallSubPageHeapCaches = null; normalHeapCaches = null; numShiftsNormalHeap = -1; } // Only check if there are caches in use. if ((tinySubPageDirectCaches != null || smallSubPageDirectCaches != null || normalDirectCaches != null || tinySubPageHeapCaches != null || smallSubPageHeapCaches != null || normalHeapCaches != null) && freeSweepAllocationThreshold < 1) { throw new IllegalArgumentException("freeSweepAllocationThreshold: " + freeSweepAllocationThreshold + " (expected: > 0)"); } }
解释一下 tinyCacheSize = 512,smallCacheSize = 256,normalCacheSize = 64 是什么呢? 每一个Cache中都有一个ByteBuf内存空间队列,那么这三个数就是TinySmallNormal 对应的队列长度。一会就能看见
private static <T> MemoryRegionCache<T>[] createSubPageCaches( int cacheSize, int numCaches, SizeClass sizeClass) { if (cacheSize > 0 && numCaches > 0) { @SuppressWarnings("unchecked") MemoryRegionCache<T>[] cache = new MemoryRegionCache[numCaches]; // 创建 MemoryRegionCache 数组,TinySmall 数组大小是 324 for (int i = 0; i < cache.length; i++) { // TODO: maybe use cacheSize / cache.length cache[i] = new SubPageMemoryRegionCache<T>(cacheSize, sizeClass); // 初始化 } return cache; } else { return null; } }
private static <T> MemoryRegionCache<T>[] createNormalCaches(
int cacheSize, int maxCachedBufferCapacity, PoolArena<T> area) {
if (cacheSize > 0 && maxCachedBufferCapacity > 0) {
int max = Math.min(area.chunkSize, maxCachedBufferCapacity); // 32K 和 16m 取小的 那就是 32K
int arraySize = Math.max(1, log2(max / area.pageSize) + 1); // 32K 就是 8 k -> 16k -> 32 k 那么 arraySize = 3
@SuppressWarnings("unchecked")
MemoryRegionCache<T>[] cache = new MemoryRegionCache[arraySize];
for (int i = 0; i < cache.length; i++) {
cache[i] = new NormalMemoryRegionCache<T>(cacheSize);
}
return cache;
} else {
return null;
}
}
MemoryRegionCache(int size, SizeClass sizeClass) { this.size = MathUtil.safeFindNextPositivePowerOfTwo(size); // 对Size进行对齐, tiny = 512 Small = 256 queue = PlatformDependent.newFixedMpscQueue(this.size); // 创建队列,长度是Size this.sizeClass = sizeClass; // 记录类型 }
MPSC(Multiple Producer Single Consumer)队列即多个生产者单一消费者队列,之所以使用这种类型的队列是因为:ByteBuf的分配和释放可能在不同的线程中,这里的多生产者即多个不同的释放线程,这样才能保证多个释放线程同时释放ByteBuf时所占空间正确添加到队列中。
这个队列我简单画个图理解一下
Tiny 的队列 :
Queue : Tiny 16B ==> Buf1 - Buf2 - Buf3 - Buf4 ... - Buf512
Tiny 32B ==> Buf1 - Buf2 - Buf3 - Buf4 ... - Buf512
...
Tiny 496B ==> Buf1 - Buf2 - Buf3 - Buf4 ... - Buf512
Small 的队列
Queue : Small 512B ==> Buf1 - Buf2 - Buf3 - Buf4 ... - Buf256
Small 1024B ==> Buf1 - Buf2 - Buf3 - Buf4 ... - Buf256
Small 2048B ==> Buf1 - Buf2 - Buf3 - Buf4 ... - Buf256
Small 4096B ==> Buf1 - Buf2 - Buf3 - Buf4 ... - Buf256
Normal 的队列
Queue : Normal 8K ==> Buf1 - Buf2 - Buf3 - Buf4 ... - Buf64
Normal 16K ==> Buf1 - Buf2 - Buf3 - Buf4 ... - Buf64
Normal 32K ==> Buf1 - Buf2 - Buf3 - Buf4 ... - Buf64
不知道我画明白了没有。缓存的数组创建好了。大家想一下这个数据是什么时候放进去呢?肯定是ByteBuf用完后然后放在这个里面,再看下这个类里面,看到一个add方法。
在add方法上打个断点,然后我们启动一个客户端, 看下方法栈是怎么流转的。

断点进来了,我们继续往上找。

前一步是PoolArena的free方法。
再往前找,找到一些熟悉的类,方便我们分析

我是找到了这个

在handler 的channelRead方法中进行了release释放。从这个地方一直往里跟就会到刚刚看到的free方法。那我们也就清楚了,就是handler处理完成后,就释放内存。
至于为什么是 MessageToMessageDecoder 这个handler ,是因为 我的 ProtobufEncoder 继承了它。
分析了放入的时机,那我们就看下是怎么放入的吧。
boolean add(PoolArena<?> area, PoolChunk chunk, long handle, int normCapacity, SizeClass sizeClass) { MemoryRegionCache<?> cache = cache(area, normCapacity, sizeClass); // 获取缓存对应的数组 if (cache == null) { return false; } return cache.add(chunk, handle); // 添加到队列中 } private MemoryRegionCache<?> cache(PoolArena<?> area, int normCapacity, SizeClass sizeClass) { switch (sizeClass) { case Normal: return cacheForNormal(area, normCapacity); case Small: return cacheForSmall(area, normCapacity); case Tiny: return cacheForTiny(area, normCapacity); default: throw new Error(); } }
private MemoryRegionCache<?> cacheForSmall(PoolArena<?> area, int normCapacity) { int idx = PoolArena.smallIdx(normCapacity); // 获取数组下标 比如 1024 就是 下边为 1 , 512 是 0 , 2048 是 2 if (area.isDirect()) { return cache(smallSubPageDirectCaches, idx); } return cache(smallSubPageHeapCaches, idx); } private MemoryRegionCache<?> cacheForNormal(PoolArena<?> area, int normCapacity) { if (area.isDirect()) { int idx = log2(normCapacity >> numShiftsNormalDirect); return cache(normalDirectCaches, idx); } int idx = log2(normCapacity >> numShiftsNormalHeap); return cache(normalHeapCaches, idx); } private static <T> MemoryRegionCache<T> cache(MemoryRegionCache<T>[] cache, int idx) { if (cache == null || idx > cache.length - 1) { return null; } return cache[idx]; // 根据数组下标,获取对应Cache }
public final boolean add(PoolChunk<T> chunk, long handle) { Entry<T> entry = newEntry(chunk, handle); // 新建ENTRY boolean queued = queue.offer(entry); // 添加队列 if (!queued) { // 如果队列满了,直接回收,不缓存 // If it was not possible to cache the chunk, immediately recycle the entry entry.recycle(); } return queued; }
好了,添加的这个说完了,还有一个问题,大家想一下这么多缓存是什么时候释放的呢??

PoolThreadLocalCache 是 继承于 FastThreadLocal ,上一节我们看了FastThreadLocal的源码。最后的时候讲了是怎么清除数据,防止内存泄漏的,就是通过remove方法。 也就是线程生命周期结束的时候,会通过remove方法进行释放。
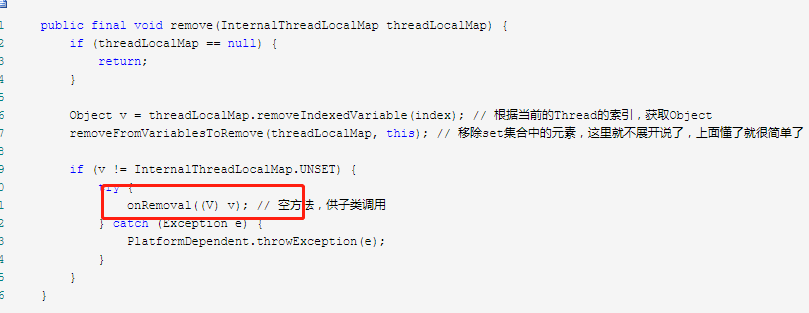
提供了onRemoval方法供子类重写,那就看下是怎么重写的。
protected void onRemoval(PoolThreadCache threadCache) { threadCache.free(); }
void free() { // As free() may be called either by the finalizer or by FastThreadLocal.onRemoval(...) we need to ensure // we only call this one time. if (freed.compareAndSet(false, true)) { int numFreed = free(tinySubPageDirectCaches) + free(smallSubPageDirectCaches) + free(normalDirectCaches) + free(tinySubPageHeapCaches) + free(smallSubPageHeapCaches) + free(normalHeapCaches); if (numFreed > 0 && logger.isDebugEnabled()) { logger.debug("Freed {} thread-local buffer(s) from thread: {}", numFreed, Thread.currentThread().getName()); } if (directArena != null) { directArena.numThreadCaches.getAndDecrement(); } if (heapArena != null) { heapArena.numThreadCaches.getAndDecrement(); } } }
对所有的数组进行释放,具体的free过程就不一起看了,比较简单。ok, 下一节我们看下重点的分配方法。
buf = directArena.allocate(cache, initialCapacity, maxCapacity);