kafakproducer概要(看源码前,最好能理解)
摘要
kafak 被设计用来作为一个统一的平台来处理庞大的数据的实时工具,在设计上有诸多变态的要求
它必须具有高吞吐量才能支持大量事件流,例如实时日志聚合。
它需要优雅地处理大量数据积压,以支持从脱机系统定期加载数据。
系统将必须处理低延迟传递,以处理更多传统的消息传递用例。
支持进行分区,分布式,实时处理,强大的容错能力。
下文主要对kafka client 客户端源码进行分析
kafka客户端

上图为kafka客户端发送消息的简单架构图,在kafka客户端(以下简称客户端)中存在2个线程
①:kafkaProducer 主线程负责数据收集并存入RecordBatch
②:Sender 负责从RecordBatch中获取数据,并组装报文,发送请求以及解析响应报文
通讯协议和消息格式
客户端说白了就是负责组装报文用来通讯的,那么理解kafka的通讯协议(报文)和消息格式对看源码是非常有必要的,可以解决你心目中的各种why,why,why
通讯协议
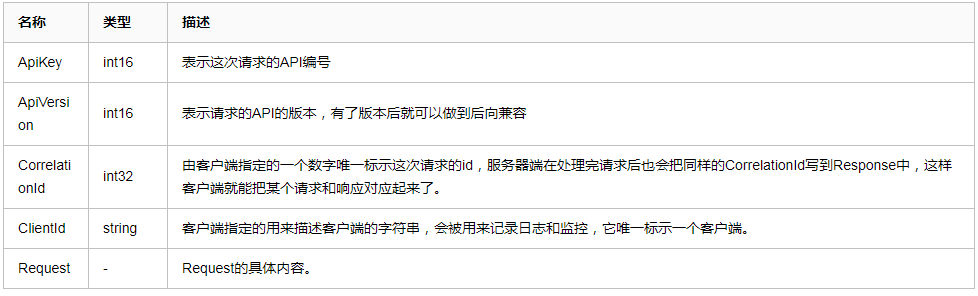
消息格式

至于这些到底干啥用的,我就不解释那么多,给大家推荐2篇文章,解释的相当到位
①:通讯协议(https://www.cnblogs.com/wxd0108/p/6519620.html)
②:消息格式(https://blog.csdn.net/u013256816/article/details/80300225)
给大家浓缩一下
通讯过程(重要)
①:通讯协议定义了双方交换数据的基本结构。通讯的过程可以简单地表示为:客户端打开与服务器端的Socket,然后往Socket写入一个4个字节的数字表示这次发送的Request有多少字节
②:然后继续往Socket中写入对应字节数的数据。服务器端先读出一个4个字节的整数,从而获取这次Request的大小,然后读取对应字节数的数据从而得到Request的具体内容。服务器端处理了请求后,也用同样的方式来发送响应。
区分不同请求(重要)
①:客户端不同的请求类型(这个很好理解,简单发送数据和从服务器拿数据,这2个请求肯定不同的,返回的内容也是不同的),kafka主要通过通过通讯协议的apikeys来区别
