日志对互联网应用的运维尤为重要,它可以帮助我们了解服务的运行状态、了解数据流量来源甚至可以帮助我们分析用户的行为等。当进行故障排查时,我们希望能够快速的进行日志查询和过滤,以便精准的定位并解决问题。
传统的日志获取方法比较单一。一般是,到日志所在机器节点上,找到日志目录,并查看和过滤日志信息。如果服务有多实例,并部署在多台机器上,就需要遍历查看多台机器的日志文件。随着服务数量和服务实例数量的增加,日志获取变得越来越艰难,另外日志一般设置滚动策略,当日志文件超过限定值,会进行日志压缩,这使得查看历史日志信息更是难上加难。
随着计算机产品复杂性的增加,主机可能部署在不同的区域,甚至是跨国界部署,即使是部署在同一个地方的主机系统,也会根据操作系统,应用服务,业务逻辑等的不同而有所差别。面对如此海量的数据,通过传统的方法,登陆到不同的机器节点上去查看,显然有些耗费人力,并略显笨拙。传统的日志文件获取方法已经不能再满足正常的日志分析需求了,于是搭建集中式的日志系统,将日志集中整合并可视化分析展示,逐渐进入大家的视野。这就引入,我们今天的主角ELK。ELK可以帮助我们稳定可靠的获取,分析并展示收集到的数据,并能够屏蔽输入数据格式。
当前ELK已经成为最流行的集中式日志解决方案。ELK创建了一个端到端的流程,可以从几乎任何类型的结构化或非结构化的数据源实时获取数据,并可视化的对数据进行分析展示。ELK是Elasticsearch、Logstash、Kibana三个开源软件的首字母缩写,这三者先后被Elastic.co公司纳入名下。 Elasticsearch 是一个分布式RESTful搜索和分析引擎,基于Apache Lucene构建,作为ELK Stack的核心,它集中存储用户的数据,以便用户可以快速发现想要搜索的数据。它具有高可伸缩性、高可靠和易管理等特点。Logstash 作为数据收集的引擎,它支持动态的从各种数据源来收集数据,并对数据进行过滤、分析,并统一格式输出,然后存储到用户指定的位置。 Kibana是一个数据分析和可视化平台,通常跟Elasticsearch配合使用,对存储在Elasticsearch中的数据进行搜索,分析并以各种统计图表的形式进行展示。
最简单的ELK架构只需要一个Elasticsearch实例用于数据存储, 一个Logstash实例用于日志搜集和一个kibana实例用于数据分析和展示。Logstash通过输入插件从多种数据源获取数据,再经过过滤插件加工数据,最后通过输出插件,将数据输出到Elasticsearch中进行存储,最终通过Kubana展示。因为Logstash仅有一个实例,那么只能获取到Logstash实例所在节点的日志信息。如果想要获取到更多的日志信息,需要在不同的节点上都安装Logstash实例。然而Logstash会占用节点的内存和CPU。为了解决Logstash占用较高节点CPU和内存的问题,引入Beats作为日志搜集器,Beats将搜集到的数据发送到Logstash,经Logstash解析、过滤后,将其发送到Elasticsearch存储。与Logstash相比,Beats所占用的系统CPU和内存几乎可以忽略不计。另外Beats和Logstash之间支持SSL/TLS加密传输,客户端和服务器端双向认证,保证了通信安全。
网络上常见各种安装ELK的详细介绍,一般,在虚拟机上安装ELK服务,大致需要先后安装和配置Elasticsearch、LogStash、Kibana三个服务。Elastic.co公司提供了多种安装包供用户下载和安装,基本可以实现安装部署的一键化操作。但是组件配置过程中,操作频繁。功能调试更是需要用户对三个组件以及组件之间的配合有较深入的了解。这无疑增加了使用ELK进行日志分析的难度。使用过程中如果需要搭建多套ELK监控系统,也会导致大量的重复性操作。这使得ELK的部署占用了用户不必要的精力,不能使用户专心聚焦于自身业务的开发部署上。
鉴于ELK服务在日志采集和搭建日志解决方案的重要性,以及ELK部署过程的繁杂。华为云AOS服务对ELK的搭建进行了封装,并提供了ELK技术栈的示例模板,供用户使用,使用户可以方便的通过AOS服务一键式部署搭建ELK服务,并通过简单的配置更改,适配自身服务。这大大缓解了用户搭建 ELK服务的困难性,并使服务的扩容和迁移变得异常简单。通过AOS部署可以屏蔽ELK技术问题,使用户不用去深入了解ELK的原理,便可以方便使用ELK服务。通过AOS服务,ELK的搭建仅需要20分钟左右,可以有效减少服务部署的时长。
下面来简要介绍下,如何通过应用编排服务搭建一套ELK系统。 搭建的ELK堆栈将会采集Logstash所在节点的kubernetes日志,并将日志存储在Elasticsearch中,最终展示在Kibana的可视化界面上。
找到行业场景模板中的ELK技术栈,并点击创建堆栈。
输入堆栈名称huawei-aos-elk-stack。
分别点击availabilityZone,nodeFlavor 后的下拉列表,选取计算节点可用区和计算节点的规格。
点击下一步, 创建堆栈,然后继续等待堆栈创建成功。
等待大概20min左右,堆栈部署成功。
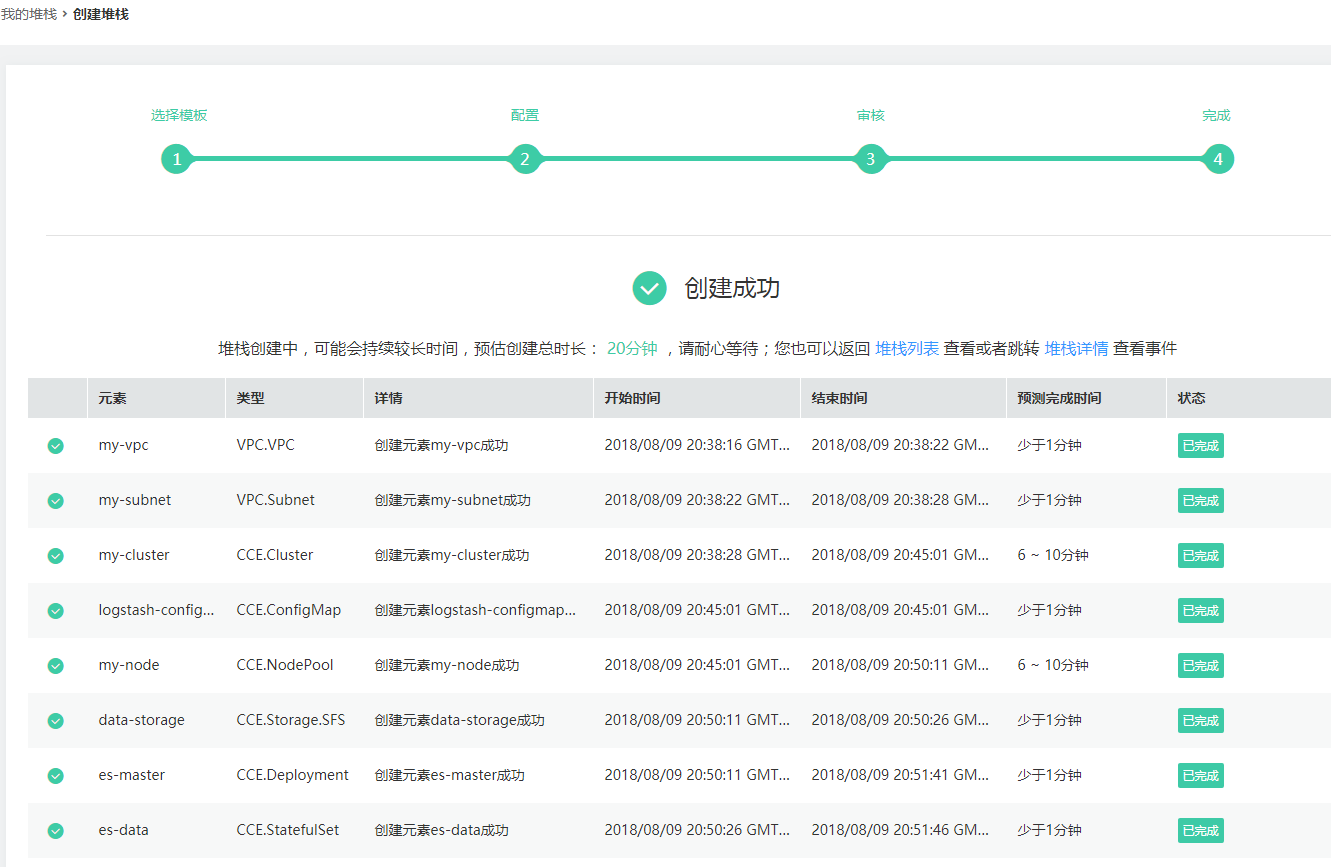
堆栈创建成功后,可以查看堆栈的输出页面,获取Kibana的访问地址。
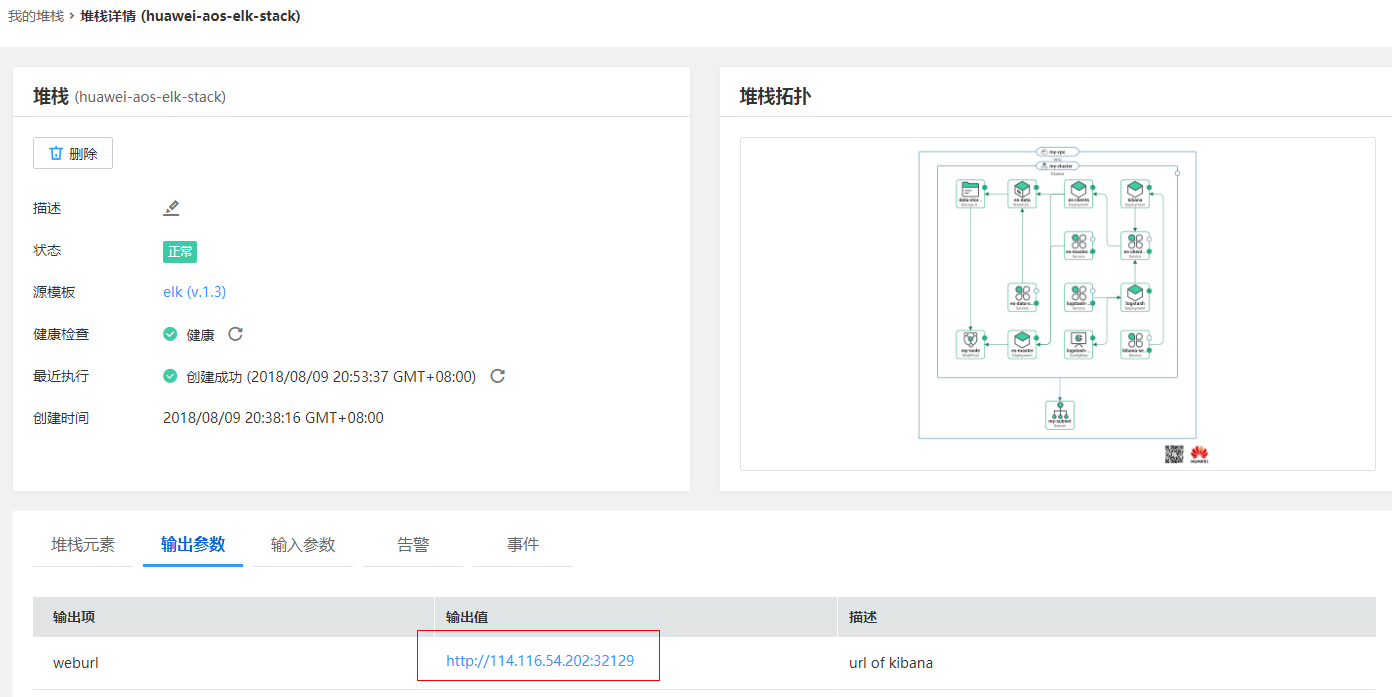
点击kibana的访问地址,进入kibana的界面。
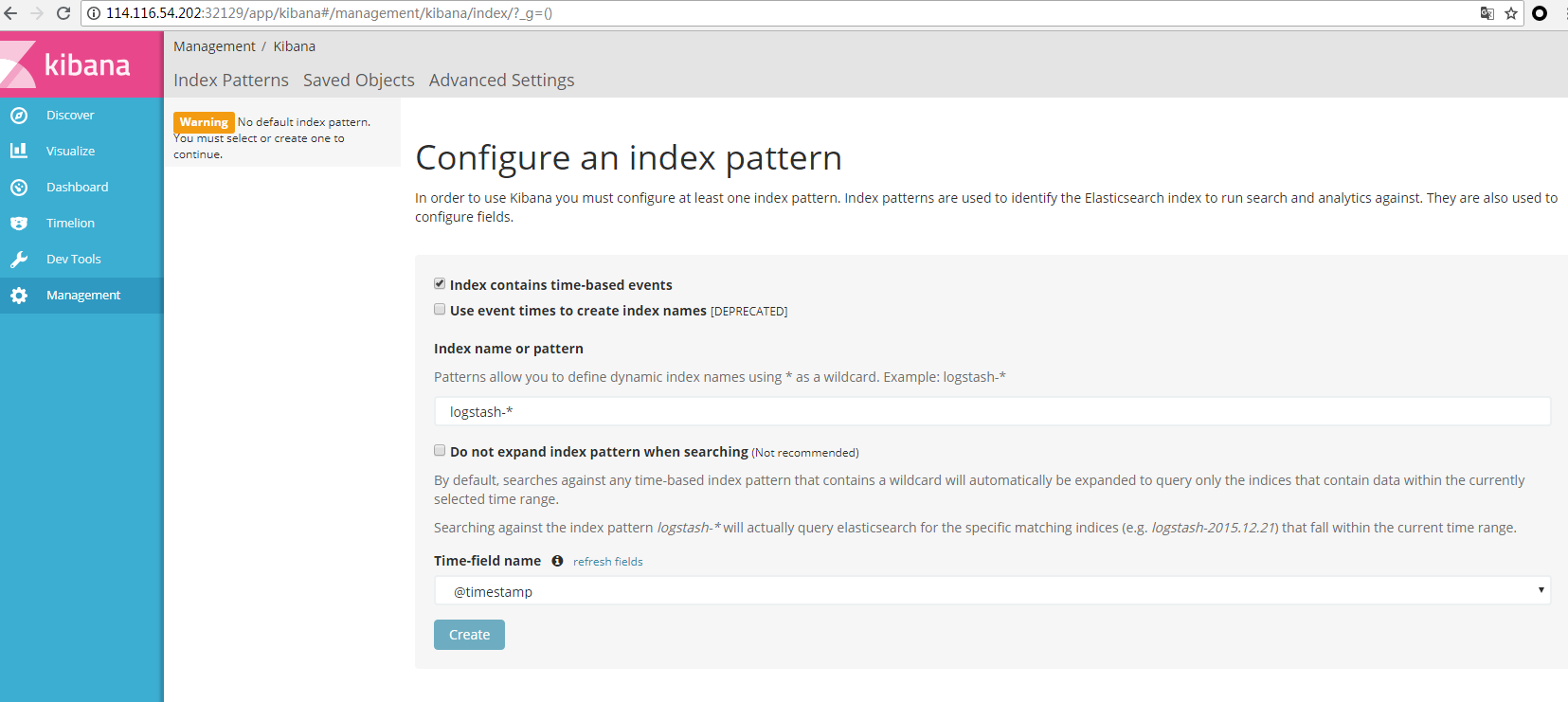
在使用Kibana的时候,kibana会自动搜索用来展示的索引。使用默认配置,点击create按钮,Kibana的索引配置就完成了,现在可以查看和使用Kibana界面展示的日志信息了。
Discover界面可以查看和过滤日志信息,搜索是在指定索引的情况下搜索,Kibana支持使用查询语法进行查询。
单纯的数据查询会当做一个字符串处理,表明在当前索引的所有字段中,搜索包含当前字符串的记录。
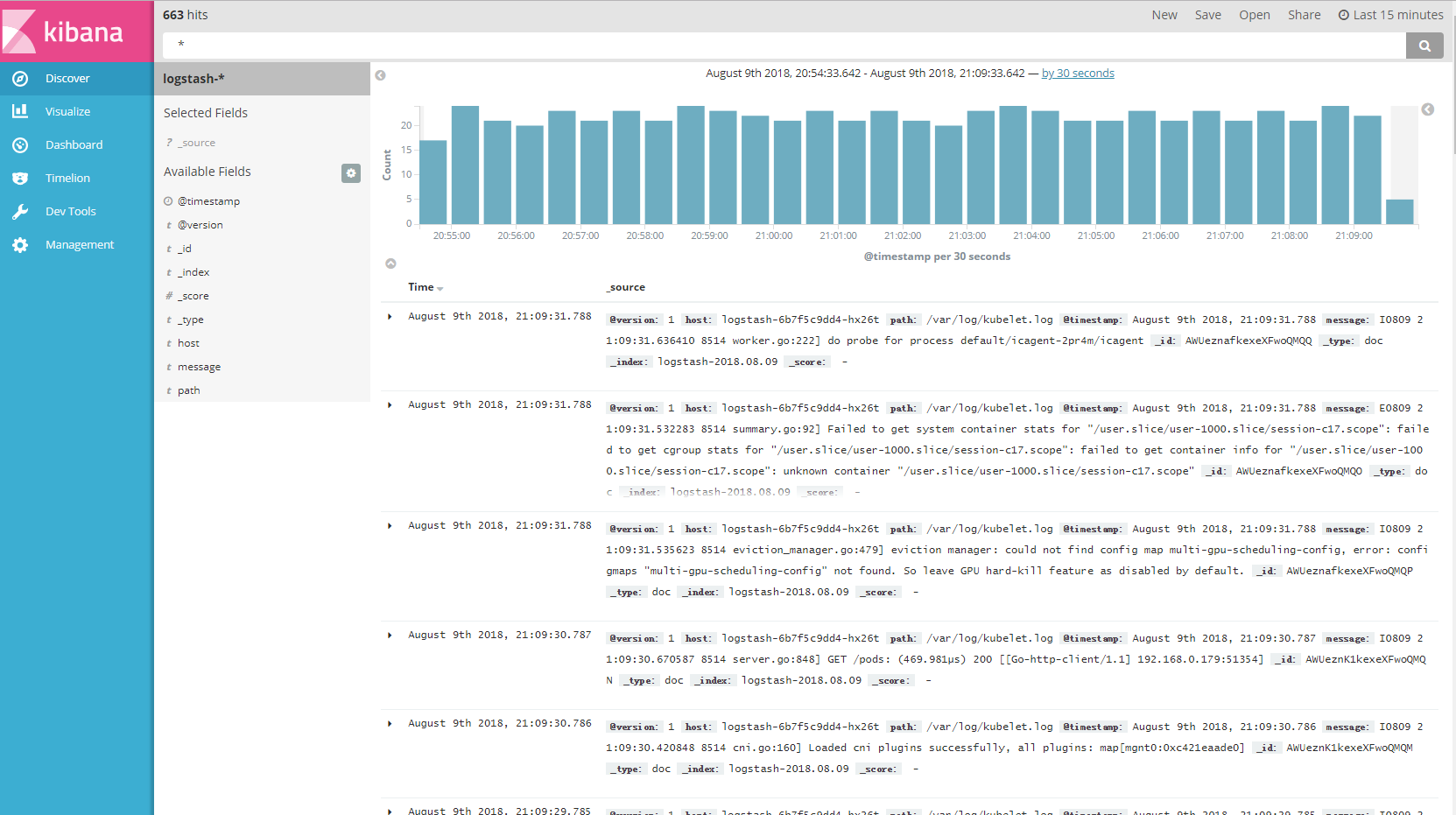
搜索栏输入关键词”192.168.0.179” 进行搜索,可以得到搜索的日志信息。
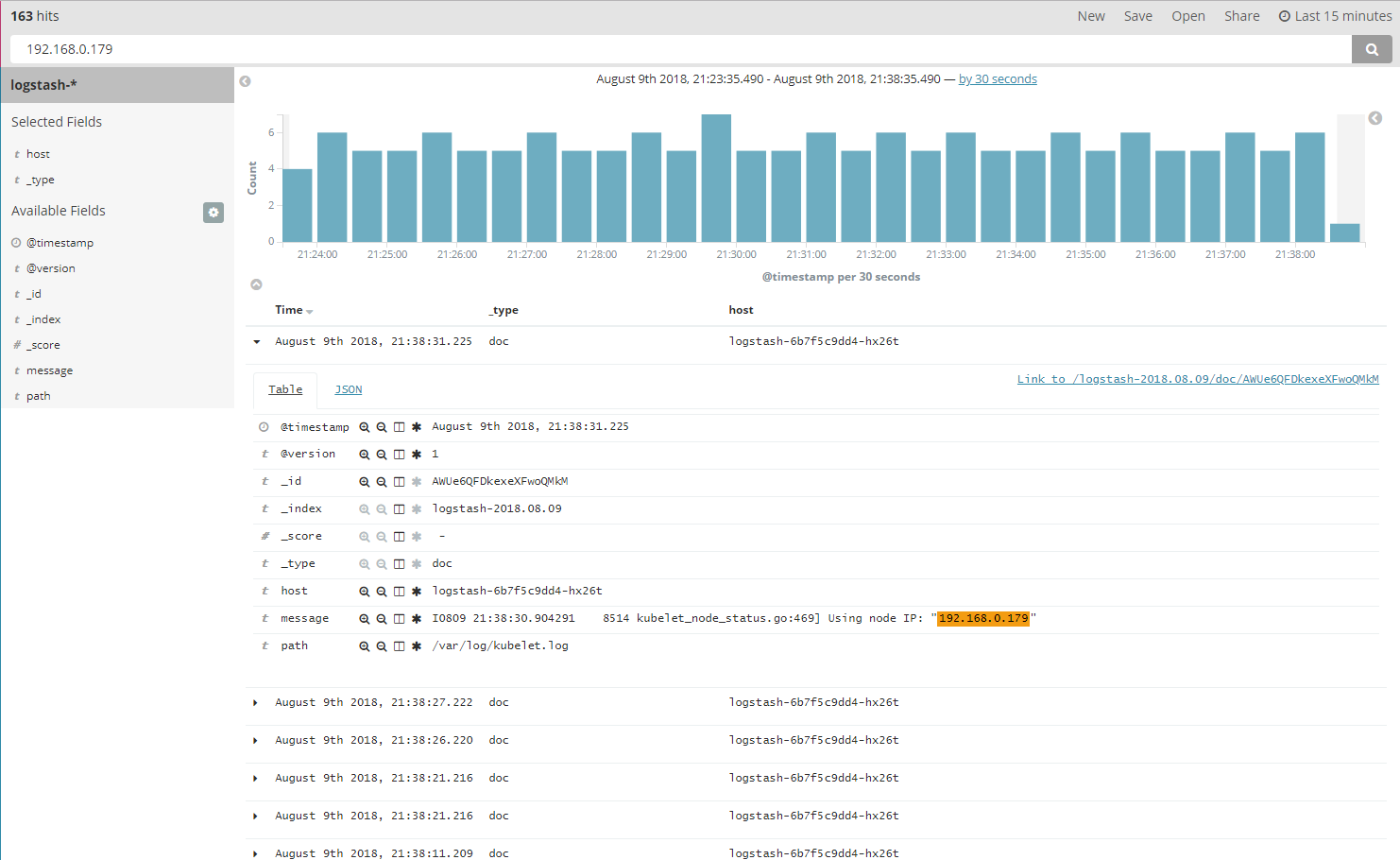
如果要指定在某个字段中搜索,则使用fieldname:data的格式,下面使用_id field进行过滤,这样查询可以获取到一条数据。
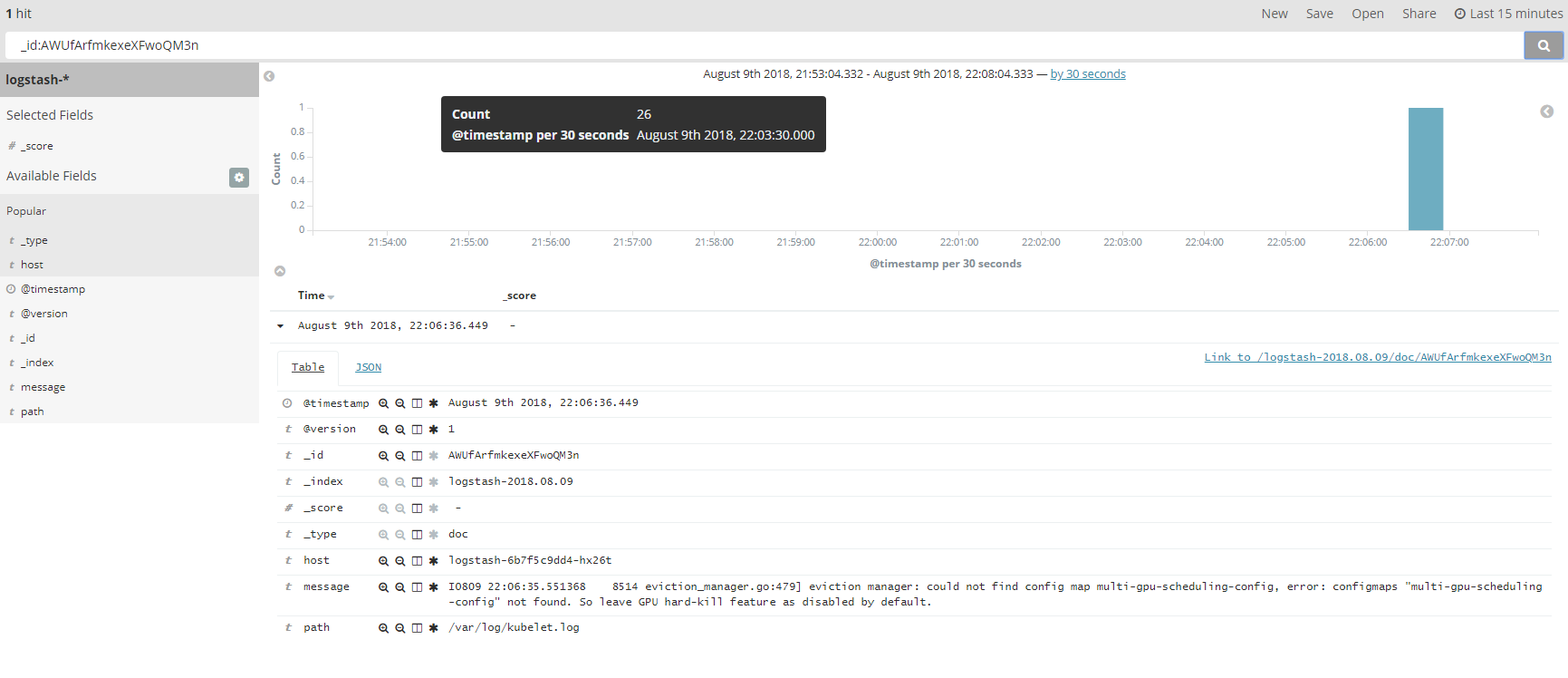
data也可以使用区间进行查询,格式为fieldname:[start To end]。
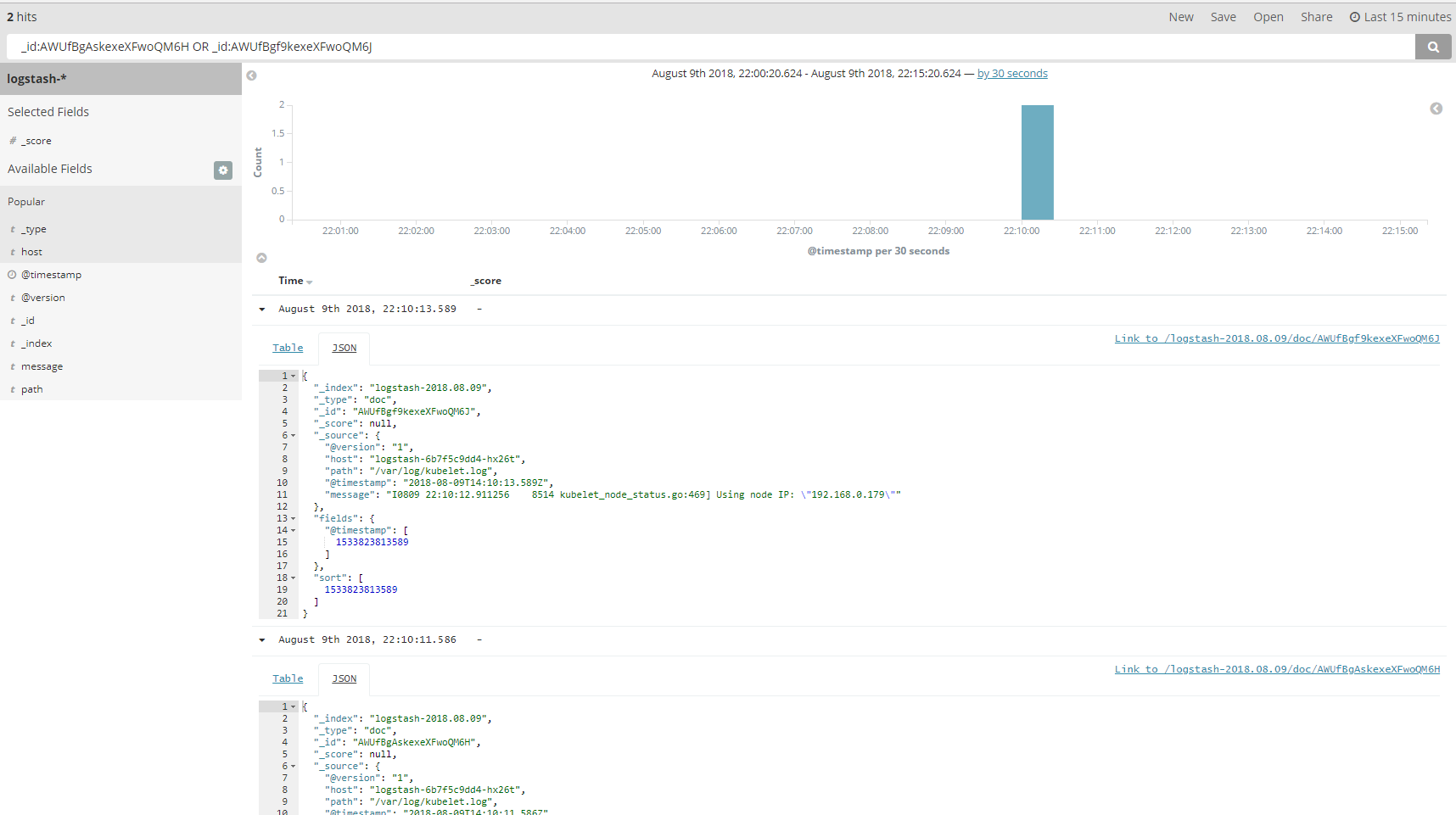
也可以使用逻辑表达式来进行搜索和查询,表达式支持AND OR NOT,通过OR逻辑运算符进行搜索两个不同_id的日志信息。
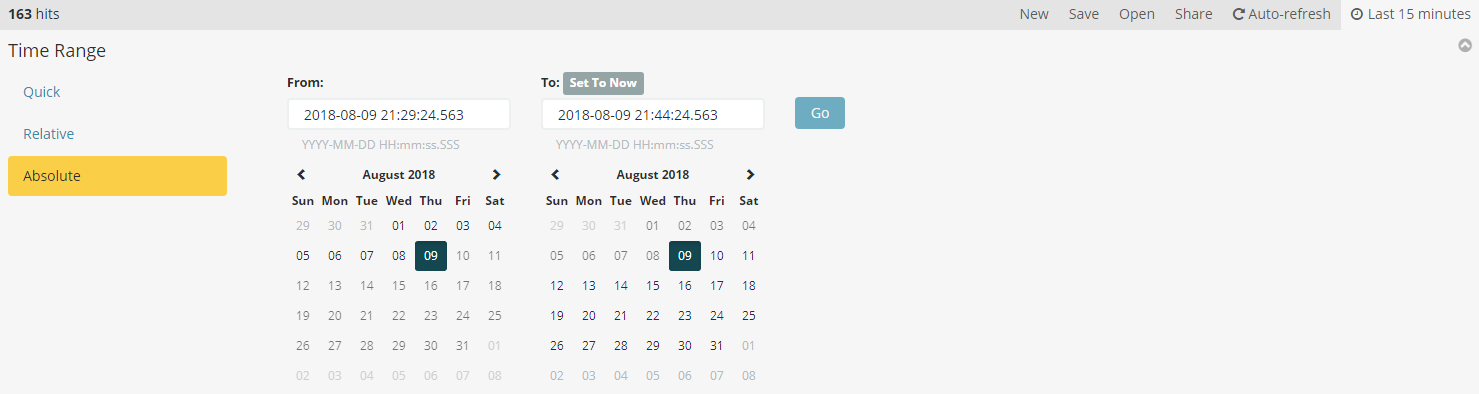
如果配置索引的时候选择了带时间戳,那么查询的时候会默认加上一个时间条件,如果在配置索引的时候选择带了时间戳,右上角会出现时间条件。并可以选择自动刷新时间。


默认情况下,查询结果会显示所有的字段,即_source的内容。
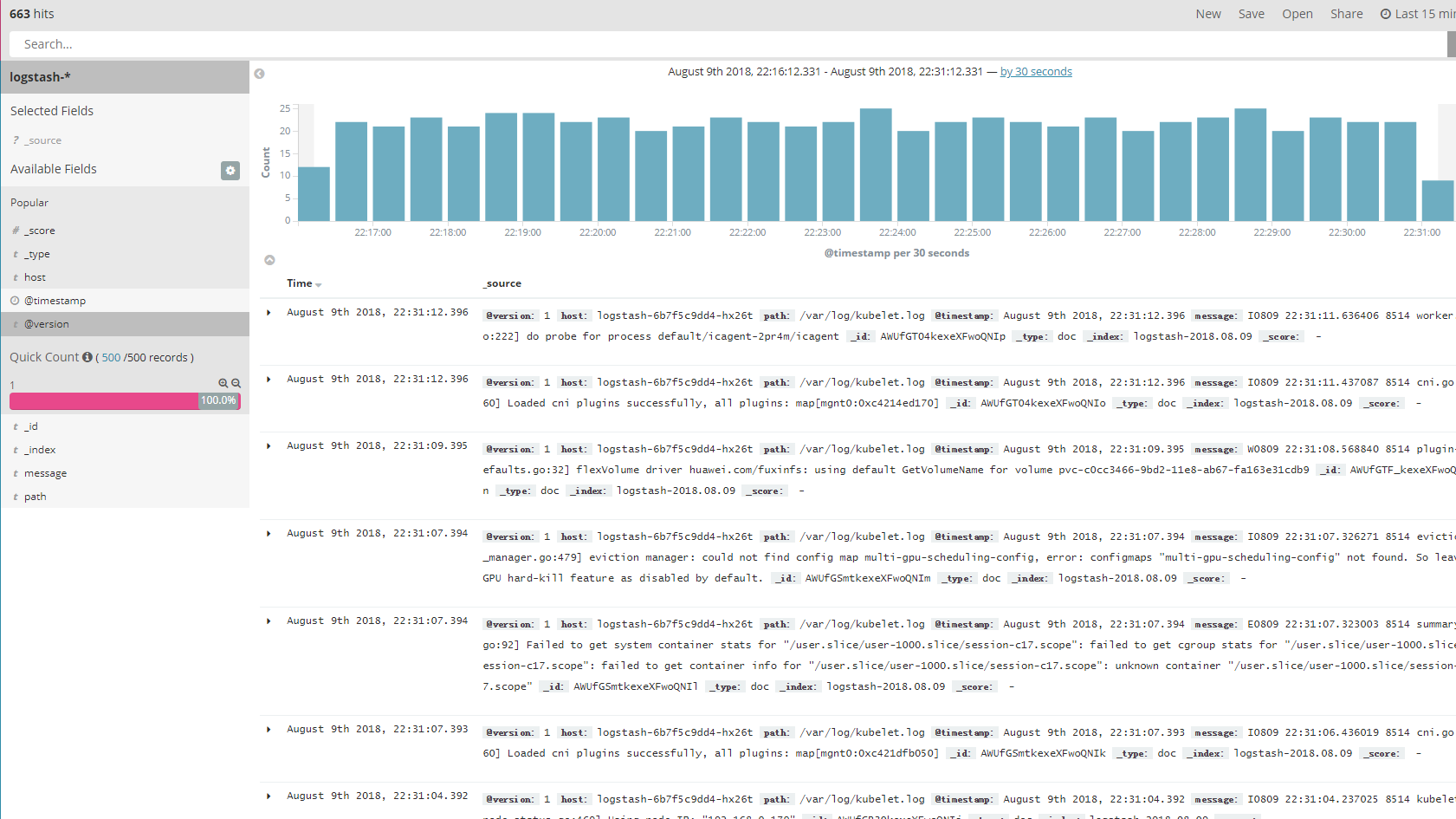
当用户只想关心一些指定的字段时,那么可以分别添加左边栏显示的字段名称。同时也可以删除已添加的字段名称。
当点击其中某一个字段时,会把当前字段数量最多的前5个值及占比现实出来。
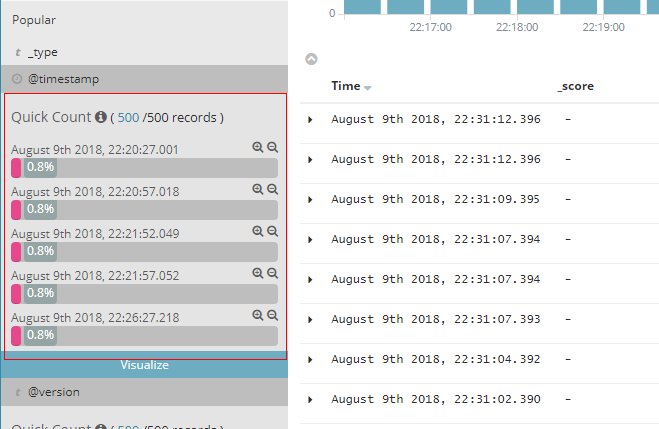
Visualize界面可以图形化的显示日志信息,可以看到kibana给我们提供了各种各样的用来展示的模板,可以根据你的需求来选择合适的。
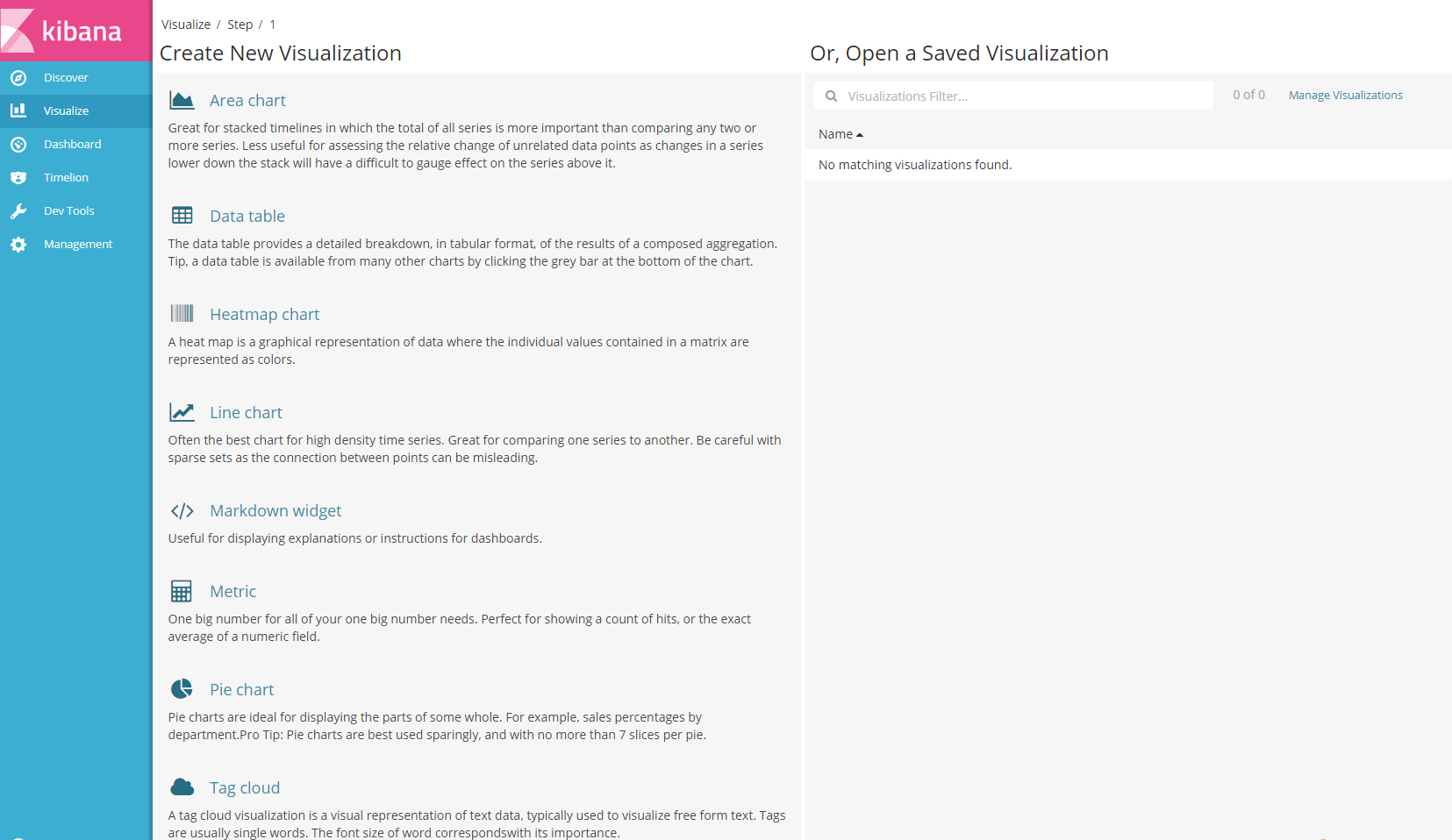
新建一个data Table 然后设置如下,可以看到右侧出现结果。
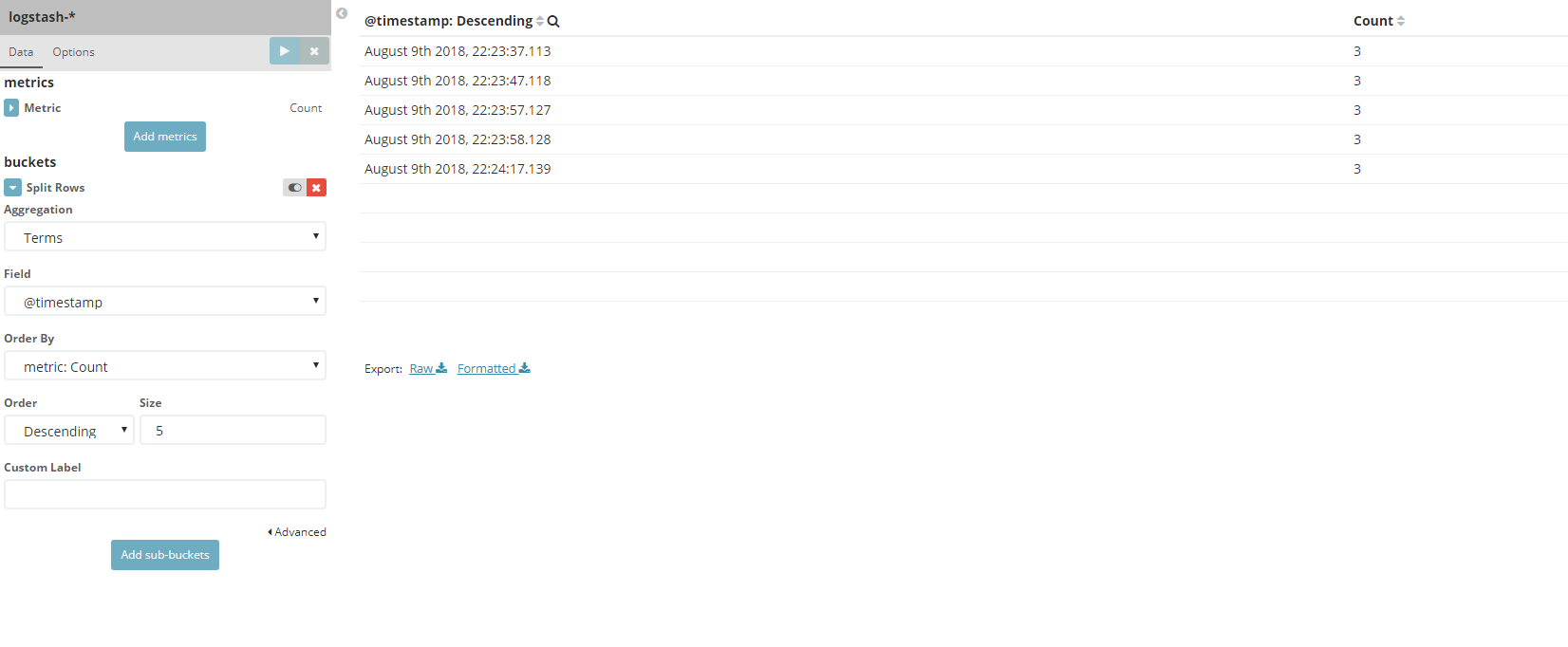
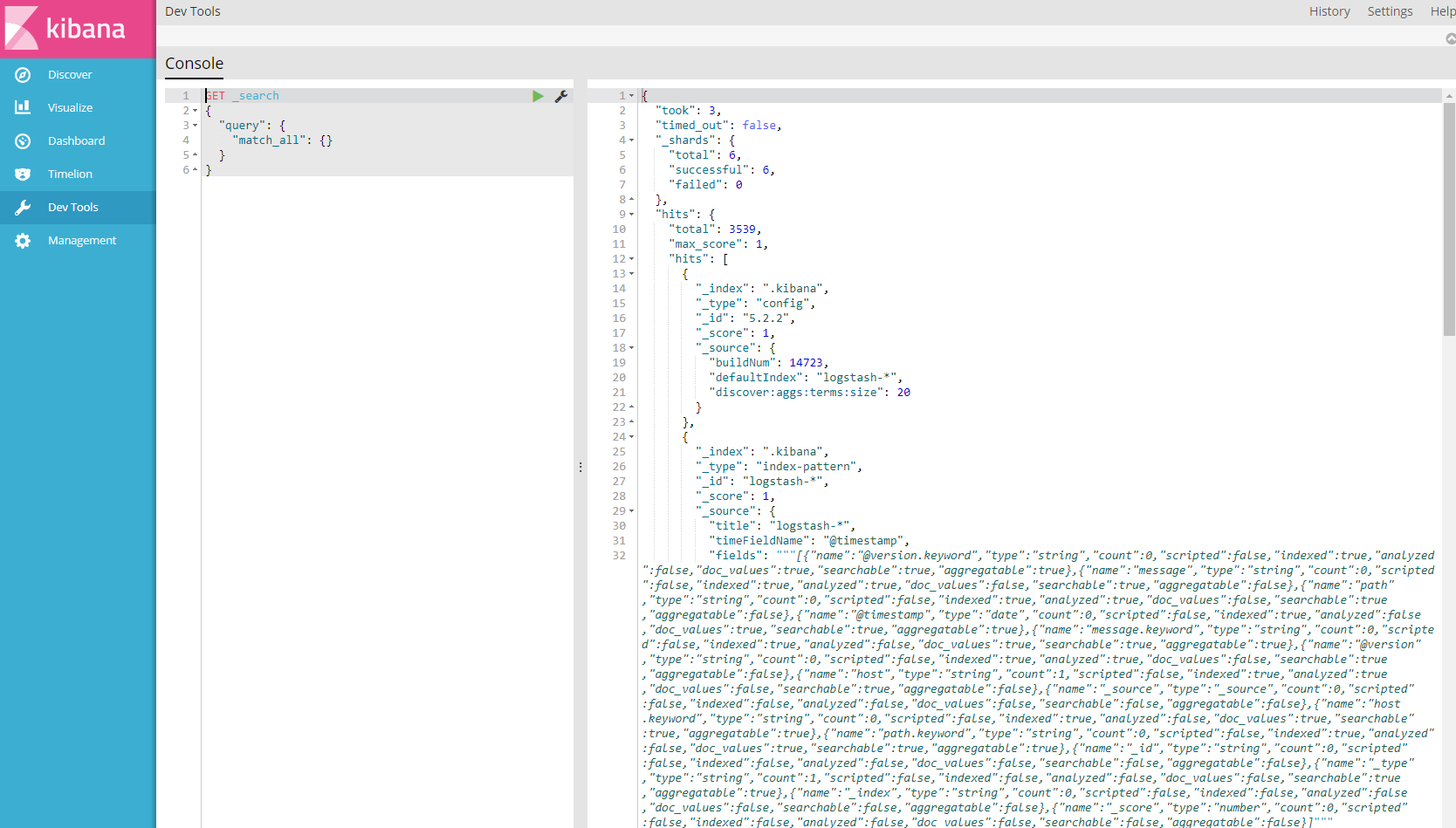
如果你觉得上面的搜索条件,还是不够个性化,那么可以使用Kibana的开发者模式,即Dev Tools界面。可以使用命令行的形式获取Elasticsearch存储的日志信息,可以说是很方便了。
通过ELK搭建部署和使用ELK就介绍那么多了,下面来简单介绍下搭建ELK堆栈所使用的模板文件,及用户进行个性化修改的修改点。
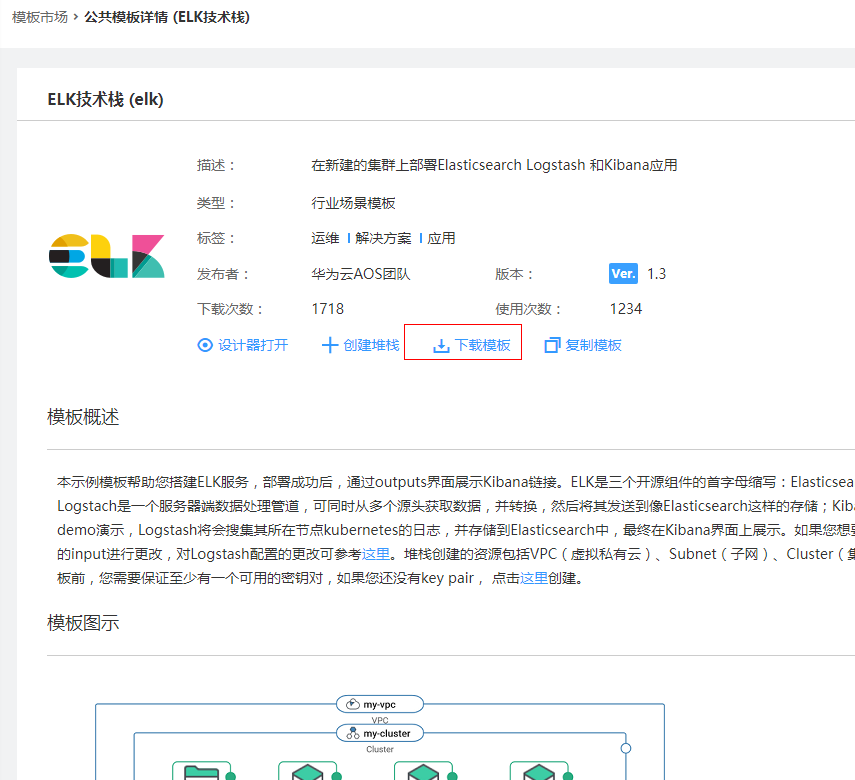
想要获取并更改模板的内容,你可以点击进入ELK技术栈模板的详情页面,点击下载模板按钮,即可获取ELK技术栈的模板文件。或者通过点击通过设计器打开,在AOS设计器界面打开该堆栈,在线编辑使用模板。
如果需要更改ELK系统搜集日志的来源,需要更改Logstash的配置文件,用户可以通过更改该配置文件中的inputs部分来配置新的日志采集来源。
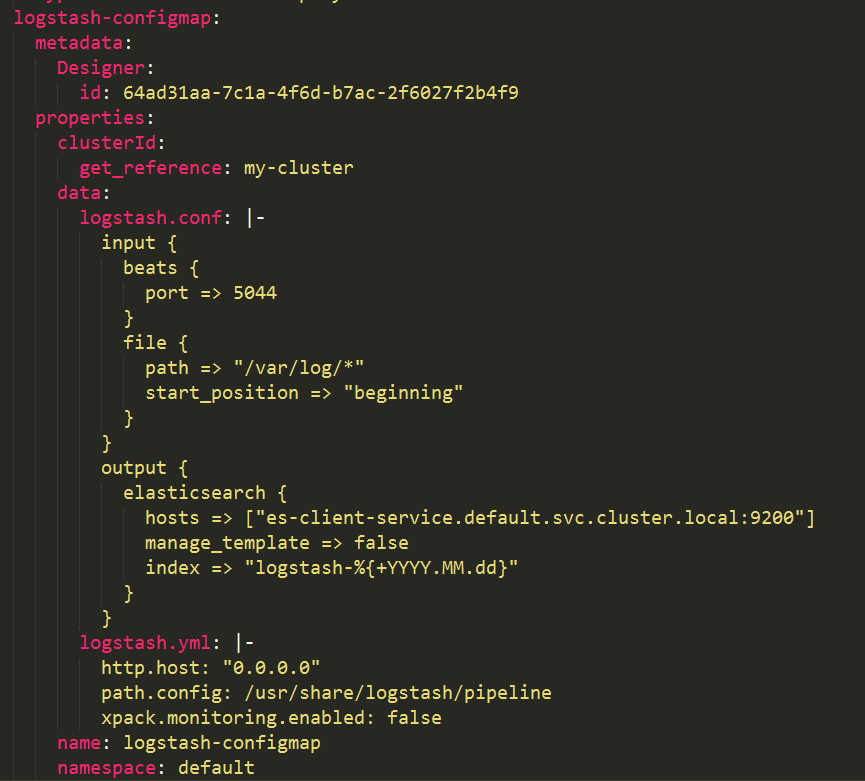
Logstash的日志来源可以有多个,这里file文件栏定义了将会把节点上面/var/log目录下的所有文件作为数据源进行采集。
output部分指定了Logstash采集的日志文件的存储路径,指定了Elasticsearch作为数据存储的媒介,其中hosts指定了Elasticsearch的访问地址。
再来介绍下ELK堆栈部署中模板的inputs参数。
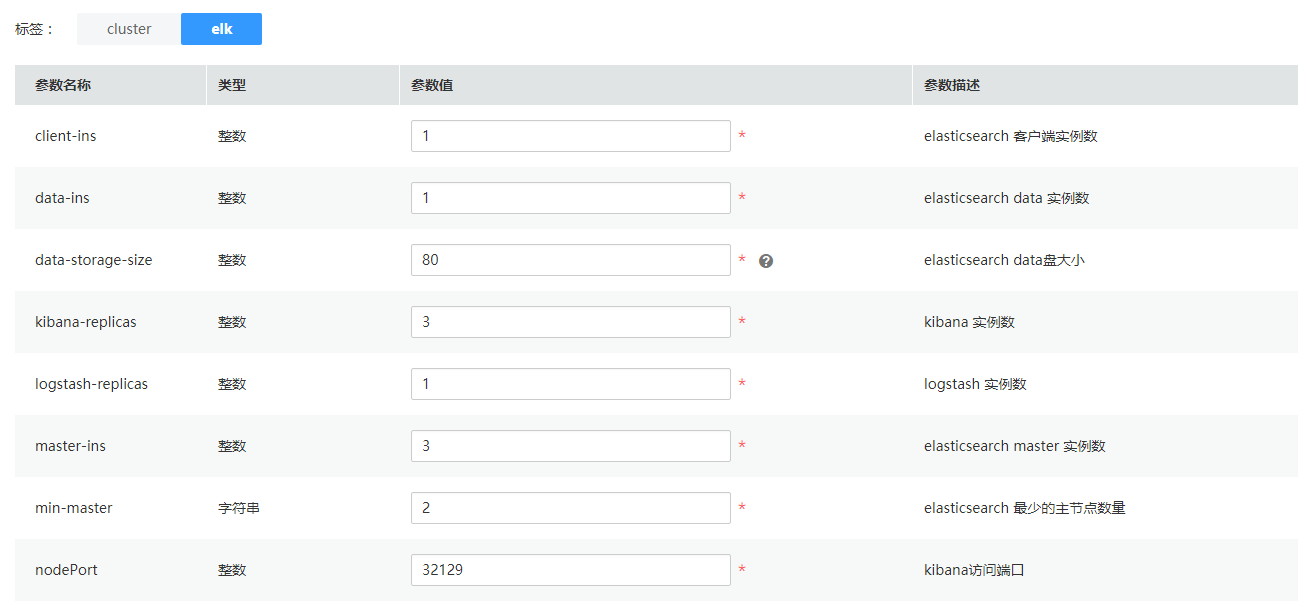
client-ins 指定Elasticsearch中客户端的实例数,Elasticsearch客户端主要负责为外部服务访问Elasticsearch服务提供服务分发等操作。
data-ins指定Elasticsearch中数据节点的实例数, Elasticsearch 的数据节点负责数据的存储。
master-ins指定Elasticsearch中作为master的实例数,master节点主要负责索引的创建。
min-master指定Elasticsearch中可以作为master节点的实例数。
data-storage-size指定Elasticsearch中作为数据存储节点所挂载的数据盘的大小。
nodePort指定Kibana的访问端口
kibana-replicas和logstash-replicas分别是指定Kibana和Logstash服务的实例数。
有兴趣的朋友可以可以体验一下:https://www.huaweicloud.com/product/aos.html