环境 CentOS5.5,内存256MB,MySQL5.5.16
一、创建测试表
CREATE TABLE part_tab( c1 INT DEFAULT NULL, c2 VARCHAR(30) DEFAULT NULL, c3 DATE DEFAULT NULL ) ENGINE=myisam CHARSET=utf8 partition by RANGE(YEAR(c3))( partition p0 values less than(1995), partition p1 values less than(1996), partition p2 values less than(1997), partition p3 values less than(1998), partition p4 values less than(1999), partition p5 values less than(2000), partition p6 values less than(2001), partition p7 values less than(2002), partition p8 values less than(2003), partition p9 values less than(2004), partition p10 values less than(2010), partition p11 values less than MAXVALUE)
CREATE TABLE `no_part_tab` ( `c1` int(11) DEFAULT NULL, `c2` varchar(30) DEFAULT NULL, `c3` date DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=utf8;
二、创建测试数据
CREATE PROCEDURE `p1`() begin declare v int default 0; while v<8000000 do insert into part_tab values (v,'testing partition',adddate('1995-01-01',(rand(v)*36520) mod 3652)); set v=v+1; end while; end
call p1;
insert into no_part_tab select * from part_tab
三、测试
select count(*) from part_tab where c3>date '1995-01-01' and c3< date '1995-12-31'; #1.875s
select count(*) from no_part_tab where c3>date '1995-01-01' and c3< date '1995-12-31'; #9.269s
四、分析
desc select count(*) from part_tab where c3>date '1995-01-01' and c3< date '1995-12-31' G;
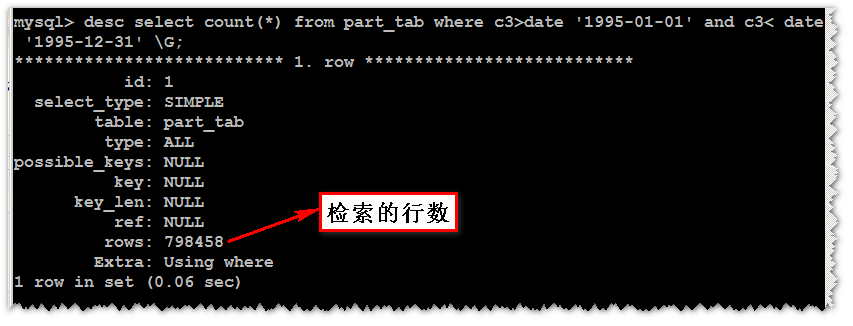
desc select count(*) from no_part_tab where c3>date '1995-01-01' and c3< date '1995-12-31' G;
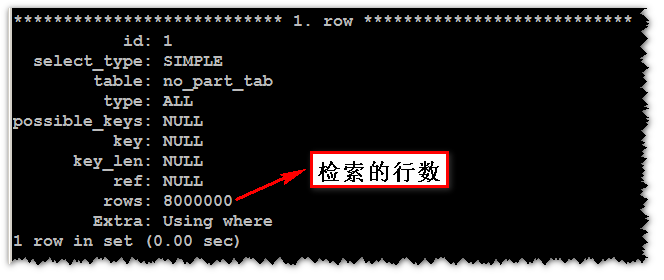
可以看出慢的原因了
五、创建索引再测试
create index idx_of_c3 on part_tab(c3);
create index idx_of_c3 on no_part_tab(c3);
select count(*) from no_part_tab where c3>date '1995-01-01' and c3< date '1995-12-31'; #1.49s
select count(*) from part_tab where c3>date '1995-01-01' and c3< date '1995-12-31'; #1.48s
查询时间差不多,分析图就想想就知道样子了
六、使用未索引字段查询
select count(*) from no_part_tab where c3>date '1995-01-01' and c3< date '1996-12-31' and c2='hello'; #12.274s
select count(*) from part_tab where c3>date '1995-01-01' and c3< date '1996-12-31' and c2='hello'; #2.74s
七、分析
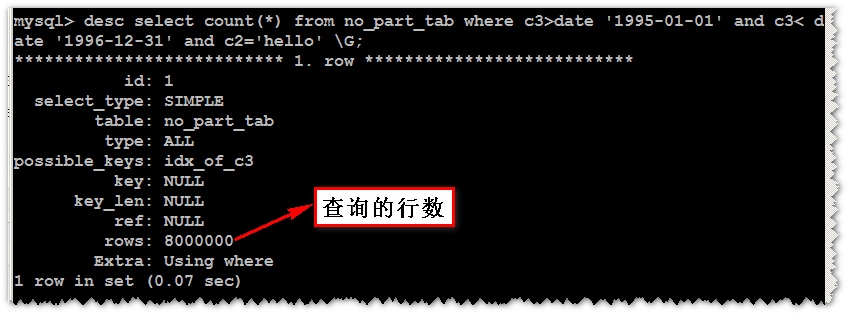
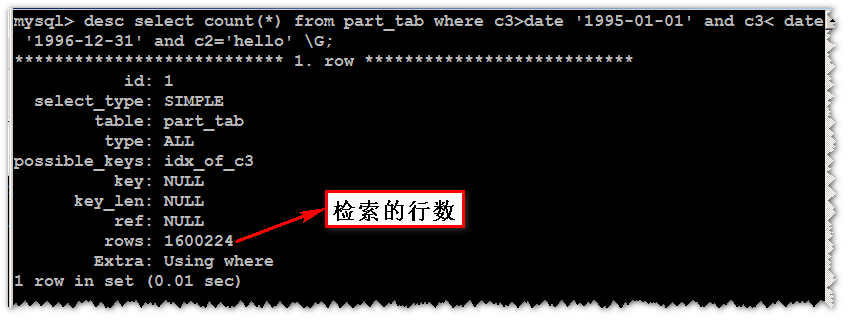
八、总结
在数据量较大的情况 使用被作为查询条件较频繁的字段 作为分区的依据。