linux里面,有一个结构体task_struct,也叫“进程描述符”的数据结构,它包含了与进程相关的所有信息,它非常复杂,每一个字段都可能与一个功能相关,所以大部分细节不在我的研究范围之内,在这篇文章里面只讲述这些数据结构的组织方式,相当于一个知识点的大的梗概或骨架,如果骨架搞明白了,那么内部的细节就可以抽丝剥茧,搞明白也非难事。
一,链表
很简单,上面所说的进程描述符以双向链接的形式组织起来,说起来很简单,但还是有一些特色在里面的
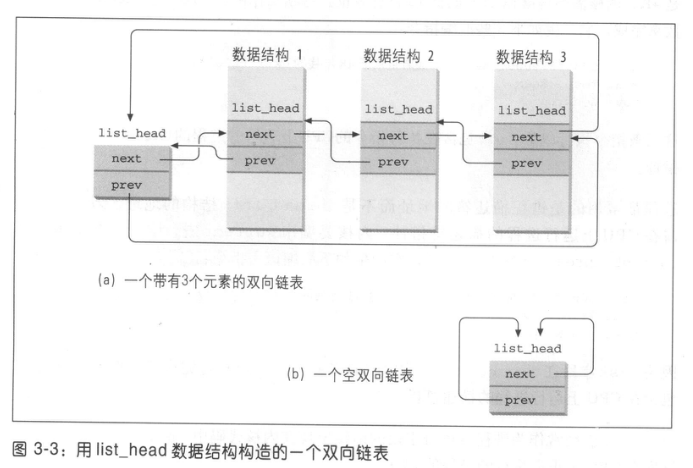
1,在Linux内核链表中,不是在链表结构中包含数据,而是在数据结构中包含链表节点。
在内核中定义了list_head的一个数据结构,struct list_head { struct list_head *next, *prev;}; 它只含有两个字段。它就组织成了一个没有数据域的双向链表,通过在task_struct中包含一个list_head数据结构,实现了task_struct的双向链接。
但是,list_head的指针只是指向list_head自己的地址,怎样通过list_head指针,来获取task_struct的地址呢?方法如下:
#define list_entry(ptr, type, member) container_of(ptr, type, member)
#define container_of(ptr, type, member) ({ const typeof( ((type *)0)->member ) *__mptr = (ptr);
(type *)( (char *)__mptr - offsetof(type,member) );})
#define offsetof(type, member) ((size_t) &((type *)0)-> member)
解释如下:
通过定义一个task_struct指针p,其地址指向0,然后获取p->list_head的地址,就可以获取list_head在task_struct中的偏移量,这应该是个常量。然后就用list_head的地址减去这个常量 ,就得到了task_struct的地址。
参考文献:http://www.cnblogs.com/Daniel-G/archive/2013/09/06/3305834.html
2,140个优先权队列
进程的优先权有140个,为了调度的需要,内核就组织了140个链表,每个链表代表一个优先权。这通过在task_struct中包含一个list_head字段来实现。
所有的这些链接通过一个prio_array_t的数据结构实现。如下,在里面我们看到了bitmap位图数据结构的使用。

3,等待队列
进程经常等待某些事件的发生,例如等待一个磁盘操作的终止。
当进程等待一些资源时,内核就将这个进程放到此资源对应的等待队列中。
二,哈希表
以链表的形式组织task_struct数组,特点就是灵活。但如果想通过PID获取到对应的task_struct的地址,仅仅使用链表还是不够的,O(1)神器hash_table可以解决这个问题。
内核初始化时,动态的创建4个哈希表,如下:

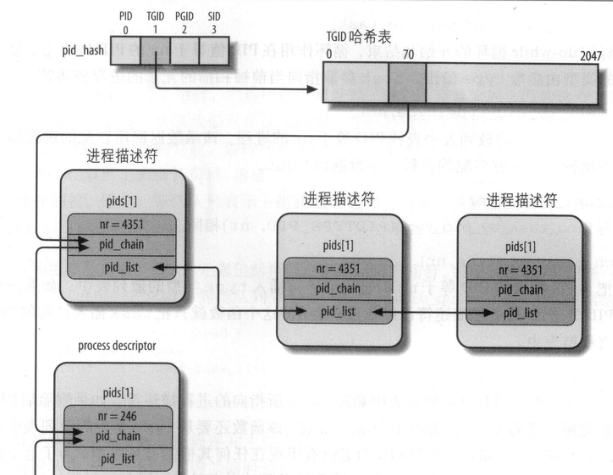
哈希表就不多说了,下面简单的说一下TGID哈希表的结构,如下图。
举例说明,例如现在内核要回收TGID=4351的所有进程,那么我们立即就可以得到TGID=4351的进程所在的位置,一般情况下,我们通过哈希表只得到一个节点,但内核的哈希表扩展了一下,就是将TGID=4351的所有进程都链接到一个链表中,那么遍历链表就可以获取TGID=4351的所有进程了。
三,位图
1,每个进程对有一个唯一标记PID,默认情况下最大的PID号是32767,但这个值可以更改,那么怎么做到循环使用PID呢,内核通过一个pidmap_array位图来表示当前已经分配的PID号的闲置的PID号。也就是用32767个bit就可以解决这个问题。
2,上面所讲到的优先权队列中也有bitmap的使用,用5个unsigned long型,也就是160个bit完全可以满足140个优先权的使用。
读完《深入理解linux内核》第三章后,所学到的就是上面的内容。读得也不够深入,人为的忽略了很多细节的阅读,因为我的目标也不在于细节。
有两点感受:
1,感觉内核所用的数据结构也就是我们平常使用的到的数据结构。
2,内核把性能放在了第一位,有时候可以拿一些空间来换取时间,例如上面所讲到的hash表,TGID=4351和TGID=246的所有进程完全可以放在一个链表中,然后通过遍历来拿到TGID=4351的进程,但内核还是将它们分开,代价就是需要在每一个task_struct中再增加一对指针。