链表
在链式描述中,数据对象的每一个元素都是用一个节点或者一个单元来描述。而链表的节点之间是通过节点中包含的指向下一个节点的指针来访问和操作下一个节点的,也就是说这些节点在内存空间中并不是连续的,所以为我们也无法使用像数组那样的公式来确定元素的位置。一个指针只能指向一块连续内存空间,同时链表中,一个节点只有一个指针域,所以,这种链表是单向链表。
链表的每一个节点必须明确包含另一个节点的位置信息,也就是另一个节点的指针。为了存储数据,所以链表的节点至少包含两个部分,一部分是存储下一个节点的内存地址,称为链域或者指针域;另一部分就是我们用来存储我们的数据,称数据域。为了更好的封装数据,则使用结构体来构建链表的每个节点。链表中最后一个节点后面不再有节点,所以最后一个节点的指针域也就不用再指向下一个节点。为了避免这个节点中的指针称为野指针等状况,常常将最后一个节点的指针域置为NULL。我们将这些节点称为ChainNode。
链表就像一根链条一样,我们在访问链表的时候只要知道指向第一个节点的指针,就能够像按照链节顺序对位于链表上的每个节点都能够进行访问和操作。我们单独设置一个指针变量用来指向第一个节点。设这个指针变量为FirstNode。最终形成的示意图如图所示。
特别的:
1.这个FirstNode我们通常称为头指针。头指针在链表中是必不可少的元素,它清楚的指向了链表中第一个节点的位置。
2.有时,为了更多的知道链表的信息和一些操作上的必要,我们将链表中的第一个节点并不存储数据,而是存储一些关于链表信息的数据,并且将这个节点称为头节点。
3.头指针对于链表来说是必须的,但是头节点却不是必须的。
由前面我们可知,ChainNode是用来存储数据的节点。每个节点都分为两部分,一个部分存储指向下一个节点的指针,一部分用来存储数据。数据域又可能会因为我们的使用的不同而有所差异。主要分为两种情况。一种是数据域存放指针,指向其他的内存空间;另一种是数据域存放一种或多种基本的数据类型或者结构体。如代码所示
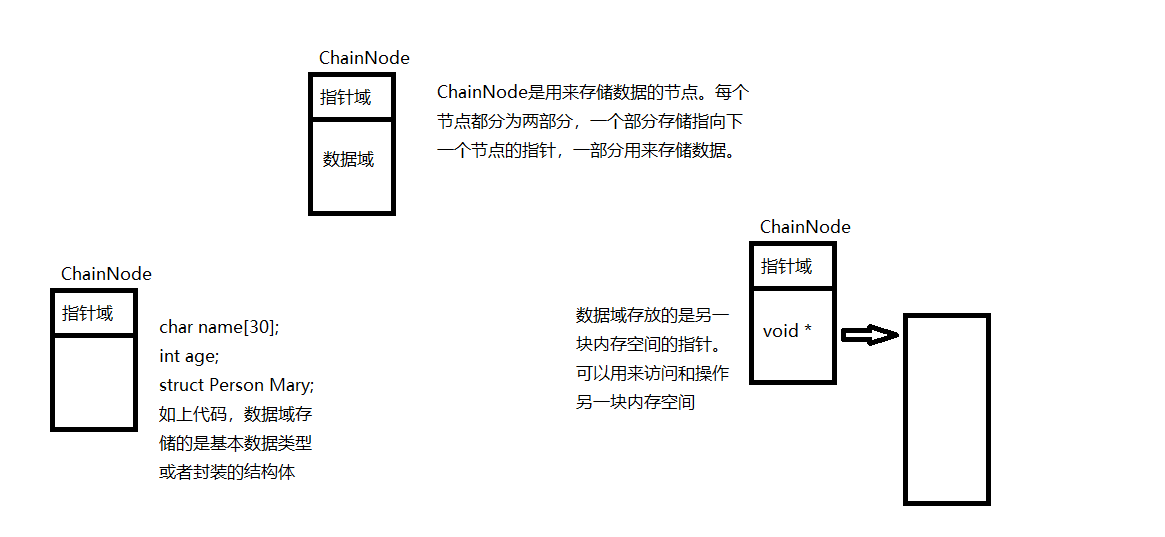
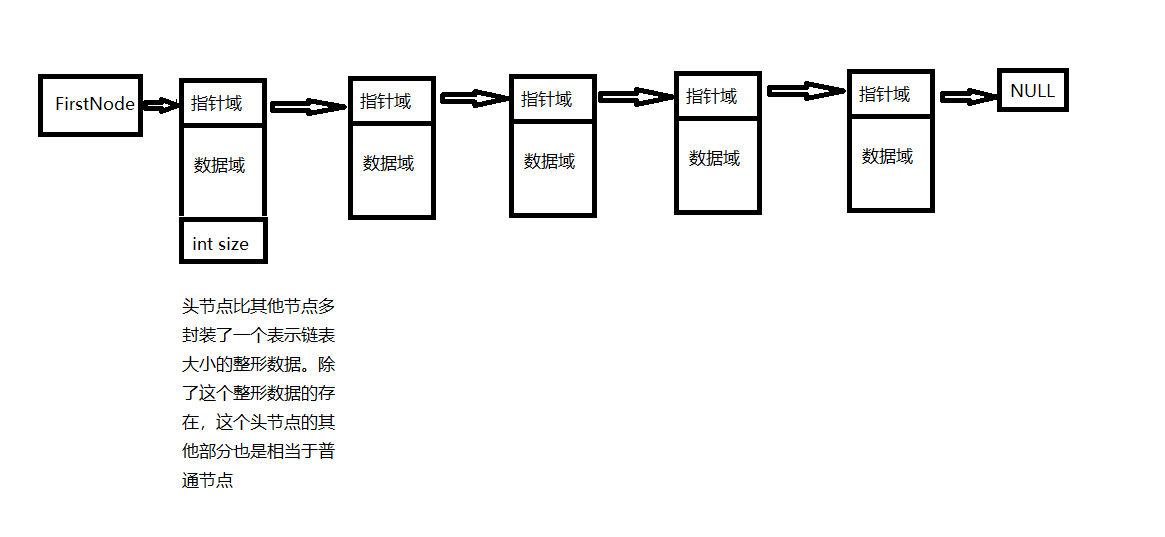
第一个节点的结构体所占的连续内存空间的首字节的地址很重要。除了指向第一个节点的指针之外,我们还需要时时知道链表中节点的个数,即链表的大小,这样可以避免操作越界。所以我们有必要在构造链表的时候在里面添加添加表征链表大小的变量。我们不妨还将其添加在头节点中。
在构建链表的时候,头节点和其他节点的结构体要分别构建。这是因为头节点的结构体中比普通节点的结构体中多封装了一个表征链表大小的整型变量。最后构建出代码链表结构如图所示。
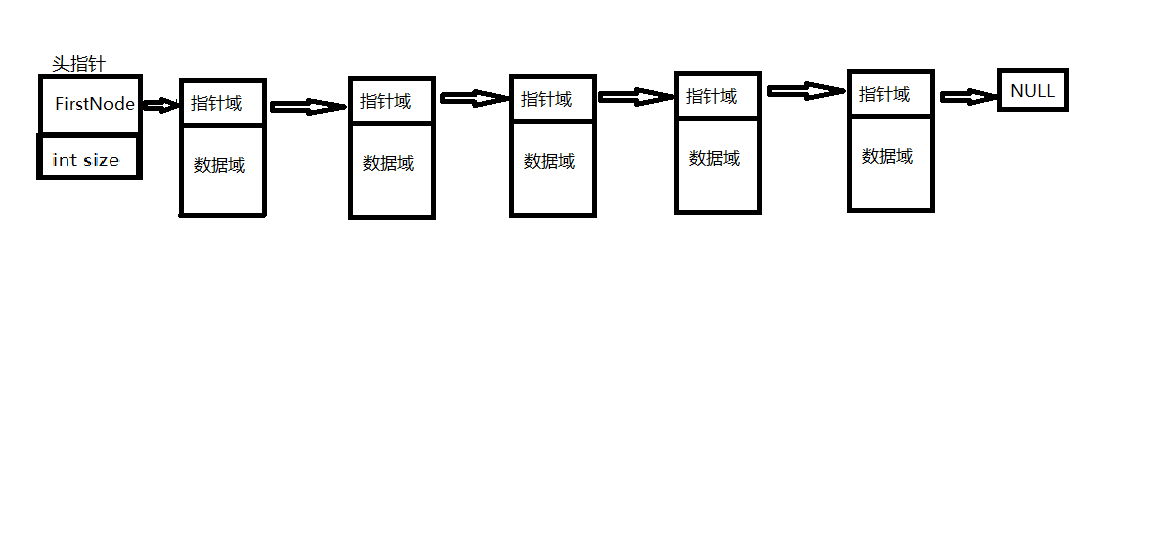
但同时还有另外一个版本,前面我们说到,头节点不是必须的,我们可以将记录栈中元素个数的size和头指针形成一个结构体。示意图如图所示。但此时我们在返回一个链表的时候不再是像前述版本提到的一样是一个头指针变量,而是一个结构体,结构体内封装了头指针和链表中存储数据元素的个数。当然,在这里,这个结构体和普通节点的结构体也要分别构建。
我们按照第一个原理给出代码。
1.构建结构体代码。
//节点的数据域中存储的是普通的数据类型 //先构建一个Person类 struct Person { char name[30]; int age; } //构建普通节点 struct ChainNode { int number; //普通数据类型 struct Person p1; //结构体数据类型 struct ChainNode* next; //指向下一节点的指针 } //构建头节点 struct LinkNode { struct ChainNode header; //和其他节点相同的数据部分 int size; //表征链表大小的整型变量 }
//节点中存储的是指向其他内存空间的指针 //构建普通节点 struct ChainNode { void* data; struct ChainNode* next; } //头节点 struct LinkNode { struct ChainNode header; int size; }
关于变量FirstNode的叙述
我们在创建链表的时候必定首先调用初始化函数对链表进行初始化,而调用初始化函数得到的返回值就是一个指针变量,这个指针变量中储存的是指向头节点所占的连续内存空间的指针,有了这个指针,我们可以访问和操作链表中的所有元素。而这个指针变量就是上述我们提到的FirstNode,因为这个指针变量指向链表的头节点LinkNode,所以这个初始化函数的返回值类型是struct LinkNode*,故函数原型可以为struct LinkNode* init_linklist();我们在创建链表的时候,必须创建一个struct LinkNode*类型的变量来接受这个FirstNode中储存的指针。如语句:struct LinkNode* list = init_linklist();
但同时,在如下代码中
typeof void* LinkList; //初始化链表 LinkList Init_LinkList() { struct LList *list = malloc(sizeof(struct LList)); if (NULL == list) { return NULL; } list->header.data = NULL; list->header.next = NULL; list->size = 0; return list; } LinkList list = Init_LinkList();
在上述代码中使用malloc函数分配内存空间得到的是void* 类型。而void*类型可以使用任何类型的指针来接受。虽然函数的返回值被定义为void*类型,但其实与struct LList*类型没什么区别。
创建第一个节点,即初始化链表
以下算法思想是我之前上课所记,但是与这个方法相差不多,可以作为参考
创建新节点并连接到链表中

插入新节点
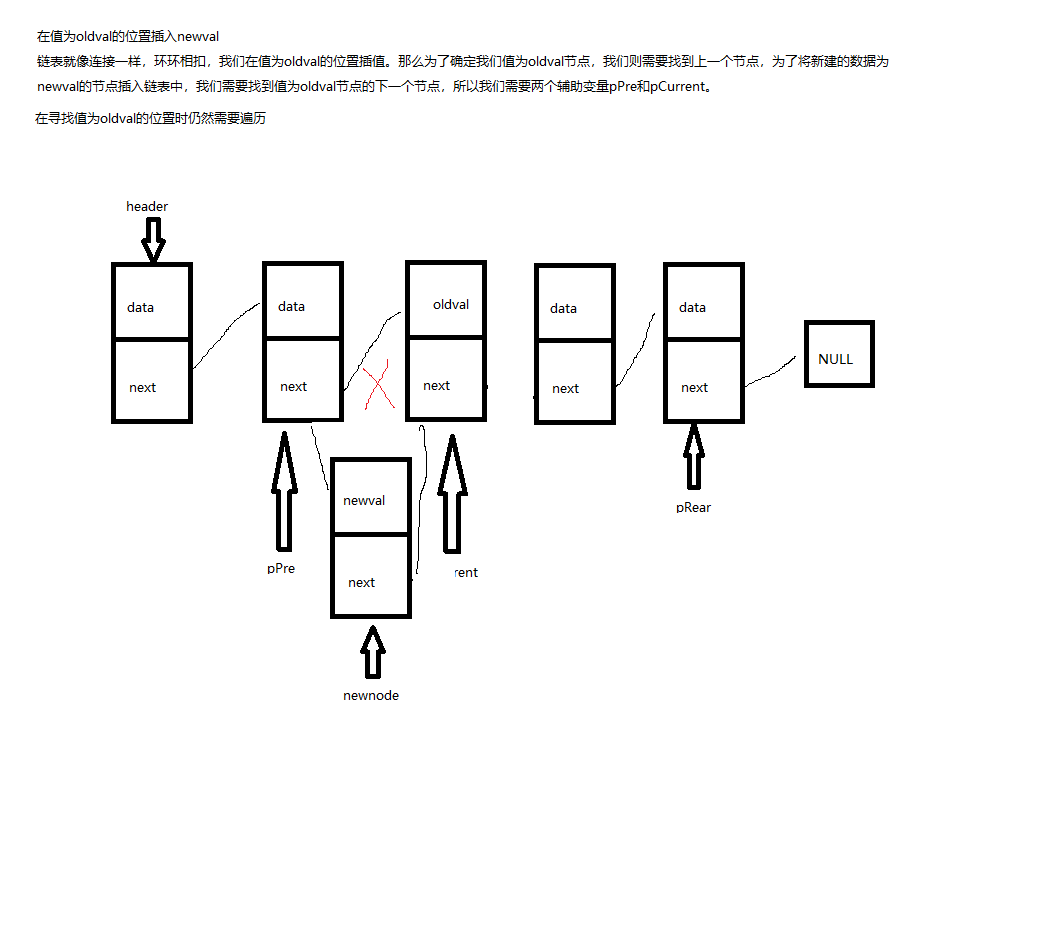
遍历
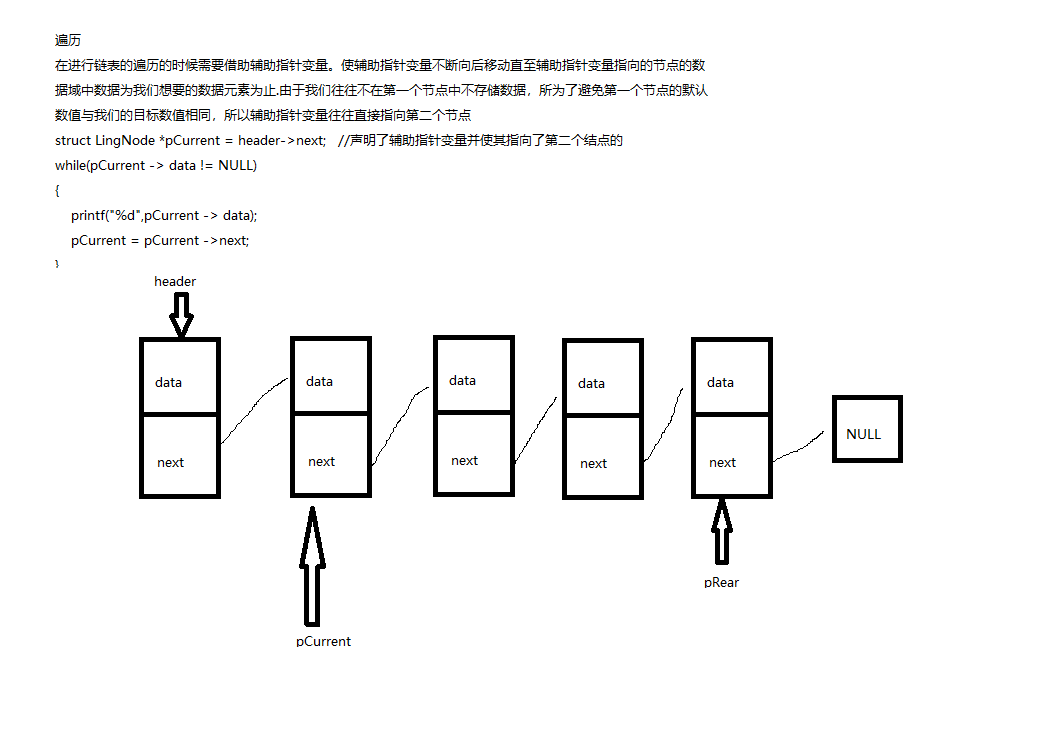
构建完整的代码
.h文件
#pragma once #include<stdlib.h> #include<string.h> #include<stdio.h> #ifdef __cplusplus extern "C"{ #endif typedef void * LinkList; typedef void(*FOREACH)(void *); typedef int(*COMPARE)(void *,void *); //初始化链表 LinkList Init_LinkList(); //插入节点 void Insert_LinkList(LinkList list,int pos,void *data); //遍历链表 void Foreach_LinkList(LinkList list, FOREACH myforeach); //按位置删除 void RemoveByPos_LinkList(LinkList list,int pos); //按值删除 void RemoveByVal_LinkList(LinkList list, void *data, COMPARE compare); //清空链表 void Clear_LinkList(LinkList list); //大小 int Size_LinkList(LinkList list); //销毁链表 void Destroy_LinkList(LinkList list); #ifdef __cplusplus } #endif
.c文件
#include"LinkList.h" //链表节点数据类型 struct LinkNode { void *data; struct LinkNode *next; }; //链表数据类型 struct LList { struct LinkNode header; int size; }; //初始化链表
//在初始化链表过程中我们得到的是指向链表头节点的一个指针,这个指针存储在指针变量list中
//在初始化链表的时候要能够我们要有一个同类型的指针变量来接收指针变量list中的地址
//在为头节点分配内存空间的时候我们使用的是malloc语句,返回的是一个void*类型的指针变量 LinkList Init_LinkList() { struct LList *list = malloc(sizeof(struct LList)); if (NULL == list) { return NULL; } list->header.data = NULL; list->header.next = NULL; list->size = 0; return list; }
//插入节点 void Insert_LinkList(LinkList list, int pos, void *data) { if (NULL == list) { return; } if (NULL == data) { return; } //在初始化变量的时候我们得到的是void*类型的指针,这个指针变量指向整这个链表,通过这个指针,我们可以访问和操作链表中所有的元素
//我们传入的是一个我们自己经过初始化后创建的函数,为了便于下面操作。又创建了一个指针变量mylist,指向我们创建的链表结构
//因为创建链表的时候得到的是void*类型的指针变量,所以需要强转 struct LList * mylist = (struct LList *)list; if (pos < 0 || pos > mylist->size) { pos = mylist->size; } //查找插入位置
//维护一个指向当前节点的指针变量,这个结构体变量要指向除了在初始化的时候被指向头节点,其他时间均指向普通节点
//为了指针变量指向的内存空间中存储的数据类型相同,所以取头节点中struct LinkNode header;部分的内存地址
struct LinkNode *pCurrent = &(mylist->header); for (int i = 0; i < pos; ++i) { pCurrent = pCurrent->next; } //创建新节点
//在创建新节点的时候,指针变量newnode指向为新节点分配的连续内存空间
struct LinkNode *newnode = malloc(sizeof(struct LinkNode)); newnode->data = data; newnode->next = NULL; //新节点插入到链表中 newnode->next = pCurrent->next; pCurrent->next = newnode; mylist->size++; } //遍历链表 void Foreach_LinkList(LinkList list, FOREACH myforeach) /*回调函数*/ { if (NULL == list) { return; } if (NULL == myforeach) { return; } struct LList * mylist = (struct LList *)list; struct LinkNode *pCurrent = mylist->header.next; while (pCurrent != NULL) { myforeach(pCurrent->data); pCurrent = pCurrent->next; } } //按位置删除 void RemoveByPos_LinkList(LinkList list, int pos) { if (NULL == list) { return; } struct LList *mylist = (struct LList *)list; if (pos < 0 || pos > mylist->size - 1) { return; } //找位置 struct LinkNode *pCurrent = &(mylist->header); for (int i = 0; i < pos; ++i) { pCurrent = pCurrent->next; } //先保存待删除结点 struct LinkNode *pDel = pCurrent->next; //重新建立待删除结点的前驱和后继结点关系 pCurrent->next = pDel->next; //释放删除节点内存 free(pDel); pDel = NULL; mylist->size--; } //按值删除 void RemoveByVal_LinkList(LinkList list, void *data, COMPARE compare) { if (NULL == list) { return; } if (NULL == data) { return; } if (NULL == compare) { return; } struct LList *mylist = (struct LList *)list; //辅助指针变量 struct LinkNode *pPrev = &(mylist->header); struct LinkNode *pCurrent = pPrev->next; while (pCurrent != NULL) { if (compare(pCurrent->data, data)) { pPrev->next = pCurrent->next; //释放删除节点内存 free(pCurrent); pCurrent = NULL; mylist->size--; break; } pPrev = pCurrent; pCurrent = pCurrent->next; } } //清空链表 void Clear_LinkList(LinkList list) { if (NULL == list) { return; } struct LList *mylist = (struct LList *)list; //辅助指针变量 struct LinkNode *pCurrent = mylist->header.next; while (pCurrent != NULL) { //先缓存下一个节点的地址 struct LinkNode *pNext = pCurrent->next; //释放当前结点内存 free(pCurrent); pCurrent = pNext; } mylist->header.next = NULL; mylist->size = 0; } //大小 int Size_LinkList(LinkList list) { if (NULL == list) { return -1; } struct LList *mylist = (struct LList *)list; return mylist->size; } //销毁链表 void Destroy_LinkList(LinkList list) { if (NULL == list) { return; } //清空链表 Clear_LinkList(list); free(list); list = NULL; }