我们学习神经网络基本都是从分类器开始的。
二分类任务和多分类任务
我们在进行分类任务,也就是图像识别的任务时,一张图片中一般有且只有一个对象,并且这个对象占据了这个图片的绝大部分空间。
对于二分类任务,我们只是输出一个数:0或1,0表示该图片中包含该对象,1表示该图片中不包含该对象。
对于多分类任务时,我们首先通过一个one-hot编码,将每个分类唯一地用一个多维向量来表示。在进行预测时,则是在神经网络地最后通过一个softmax层来输出一个向量,这个向量中包含了图片属于每个分类的概率值(此时这个向量中有多个非零值),并通过一定手段将向量中概率值最大的元素的位置设置为1表示该图片中包含的是该分类,将其它位置设置为0表示不包含该分类。这样就实现了一张图片的多分类问题。
分类定位任务
但是在实际的问题中,如无人驾驶车辆的相机中拍到的图片往往包含多个对象,同时图像中的对象在图像中只是占据很小的区域。这个时候我们不仅需要对该图像的对象进行分类,还要确定出图像中对象的位置,也就是所谓的定位。
首先从一张图片中的单个对象的定位讲起。

这是一张车的图片,在神经网络中,我们自然能够通过学习来实现这辆车的分类任务。那么如何来实现图像中的定位任务呢,我们假设我们通过某种算法得到了一个恰好包含车的方框,也就是上图中的红线所表示的方框,那么我们就可以说这个方框就是代表了这辆车在图中的位置。如果我们能够使用参数来精确表示这个方框在图中的位置,那我们就可以说表达出了车在图片中的位置,也就是实现了定位。
那么使用哪些参数来表示这个方框呢?这个方框通过四个参数来表示,(x, y, w, h)。其中(x, y)表示方框,也就是车的中心位置;w, h分别表示方框的宽和高。注意,(x, y, w, h)都是针对图像坐标而言的,并且是经过归一化之后的参数。n+
对于多分类任务(二分类任务相似),我们在输出softmax层输出的表示分类预测结果的向量后面再添加四个维度值(x, y, w, h),就实现了分类任务和该对象在图片中的定位任务。
考虑到输入的图片中可能任何分类对象都没有,只包含背景信息。所以需要在输出的向量前面再添加一个标志位pc,若图像中检测到对象,则将pc置为1,否则将pc置为0。
综上所述,假设一个多分类任务的类别数木为n,那么分类定位任务的输出向量共有(n+5)维。第一维是是否检测到对象的标志位pc,2~5维是表示检测到对象时,表示对象的位置的参数,6~(n+5)维是一个one-hot编码来表示分类对象。
滑动窗口的分类定位任务
首先有两个问题:
1.我们前面说过,我们用于分类任务的输入图像一般都是检测对象基本占据整个图像的图片。
2.前面说的是,我们假设我们通过某种算法得到了恰好包含车的红色方框。
如果我们将上述图片中的红色方框部分截取出来,我们就得到了下面的图片

在这里我们主要研究的是算法,所以在这里我们不考虑图片的失真问题。
1.那么我们就得到了车辆占据整个图片的图片,可以用作图片的分类任务。
2.我们假设我们通过某种算法得到了恰好包含车的红色方框,我们将上述图片的边界视为方框的话,我们就是得到了红色方框。只不过我们这里使用的是截取的方式。
但是在计算机中,图片是通过矩阵来表示的,而通过矩阵操作我们是可以实现对整个矩阵中任何部分的提取,也就是说我们能得到图片的任何部分。那么我们就可以理解为我们可以使用任何方框在图片中框出一部分(方框就是我们得到的图片的边框)。如果我们将我们框选出的图片送给分类算法执行分类任务,我们就实现了该部分的分类,并同时记录该方框相对于整个图片的位置(x, y, w, h)我们就得到了这个分类对象的位置,这样就实现了分类定位的任务。
那么基于窗口滑动的目标检测算法就呼之欲出了

假设这是一张测试图片,首先选定一个特定大小的窗口,将这个红色小方块(就是该方块内表示该区域的矩阵值)输入卷积神经网络(也就是分类任务的算法),卷积网络开始进行预测,即判断红色方框内有没有汽车。

接下来会继续处理第二个图像,即红色方框稍向右滑动之后的区域,并输入给卷积网络,因此输入给卷积网络的只有红色方框内的区域,再次运行卷积网络,然后处理第三个图像,依次重复操作,直到这个窗口滑过图像的每一个角落。
重复上述操作,不过这次我们选择一个更大的窗口,截取更大的区域,并输入给卷积神经网络处理。
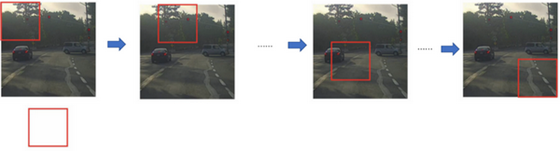
如果你这样做,不论汽车在图片的什么位置,总有一个窗口可以检测到它。
这种算法叫作滑动窗口目标检测,因为我们以某个步幅滑动这些方框窗口遍历整张图片,对这些方形区域进行分类,判断里面有没有汽车。
卷积实现的滑动窗口的目标检测
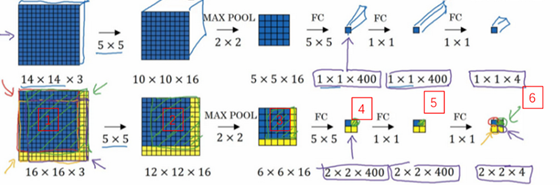
显然,上述做法就相当于我们把每个红色框内的矩阵输入给卷积神经网洛(分类任务的算法),那么此时很多计算都是重复的。如果我们将整个图片直接作为卷积神经网络的输入,那么我们就得到了滑动窗口的卷积实现。得到的是一个矩阵,矩阵的行等于使用红色方框原来的设置滑动过原始图片的行数,同时矩阵的列数等于使用红色方框原来的设置滑动过原始图片的列数。矩阵的第三维与原来执行分类任务得到的维数相同。