本文转载自:
http://www.sohu.com/a/258190629_494938
背景
SSD(Solid-State Drive)是目前正处于鼎盛时期的存储设备。相较于传统的硬盘存储器(HDD),因为取消了机械部件,也没有了时延很高的寻道过程,在随机访问方面有很大提升,功耗也显著降低。近些年的蓬勃发展,成本方面相较于HDD也已经不存在明显劣势。相较于3D XPoint以及其他一些最新的NVRAM存储技术,SSD更加成熟,大量存储和数据库应用的成功运用,经历了市场的考验。是目前生产级大规模存储系统的中流砥柱。
这篇文章搜集整理了大量资料,在总结SSD的架构和特性的基础上,帮助软件程序员们找到如何基于SSD更好的构建高质量、高效率存储系统的方法。
解构SSD
一块SSD主要由IO接口、控制器芯片、DRAM缓存和NAND Flash存储芯片构成。其架构可以用下图表示。
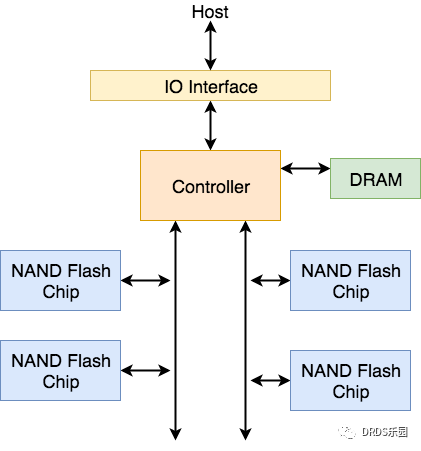
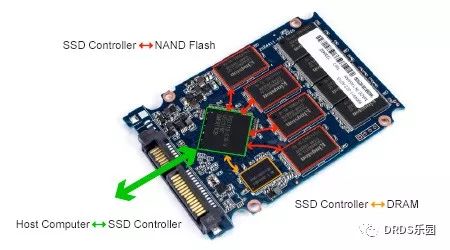
下图所示的是一块SSD的实物图:
IO接口与协议
目前SSD使用的主流IO接口是PCIe、SATA和SAS。其中PCIe和SAS的性能较高,价格也相对昂贵。SATA则价格低廉,并且同时支持SSD和HDD驱动器,但是性能就相对较低。
除了IO接口,SSD还需要使用一定的协议与Host进行通信,目前SSD使用的主要协议有传统的AHCI和专为NVM存储介质设计的NVMe两种。其中NVMe性能强大,但是只支持PCIe接口。AHCI协议的支持更广泛,但是性能相对较低。接口与协议的相关信息可以用下表总结:
| IO接口 | 最高带宽 | 支持协议 |
|---|---|---|
| PCIe | 1GB/s每通道,通常配置4~16通道 | AHCI、NVMe |
| SAS | 600MB/s每通道,最多支持4通道 | AHCI |
| SATA | 550 MB/s | AHCI |
NAND Flash存储介质
SSD使用NAND Flash作为基础存储介质,NAND Flash通过在Cell中存储电荷来存储信息。按照不同的制造工艺,每个Cell可以存储1~4个比特位。一定数量的Cell组成一个Page,一个Page的大小通常是2KB、4KB、8KB或者16KB。一定数量的Page组成一个Block,一个Block通常由128或者是256个Page组成。
NAND Flash支持三种基本操作:读、写和擦除。其中读写操作的最小单位是Page,如果读取的地址不与Page对齐,也需要读取或写入整个Page。NAND Flash比较特殊的一点是提供的写入操作在底层NAND Flash介质上是执行了一次的“编程”操作,被编程之后的NAND Flash就不能被再次编程了,也就是不能再次写入了,必须首先进行一次擦除操作,才能再次执行写入操作。擦除操作的最小单位是Block。NAND Flash的每个Cell的最大编程-擦除(P/E过程)次数是非常有限的,超过最大P/E次数Cell将不可用,这也是NAND Flash的存储介质的一个重要特征之一。
NAND Flash的Cell类型、读写时延、最大P/E次数的相关数据总结在下表中:
| Cell类型 | 每Cell存储bit数 | 读取一个Page耗时 (微秒) | 写入一个Page耗时(微秒) | 擦除一个Block耗时(毫秒) | 最大P/E次数 |
|---|---|---|---|---|---|
| SLC | 1 | 25 | 200 ~ 300 | 1.5 ~ 2 | 多 |
| MLC | 2 | 50 | 600 ~ 900 | 3 | 中 |
| TLC | 3 | 75 | 900 ~ 1350 | 4.5 ~ 10 | 中 |
| QLC | 4 | 220 | 2000 | 10 | 较少 |
SSD控制器
控制器(Controller)是整个SSD产品的核心,由专用的控制器芯片实现。负责接收来自Host的命令,并将其转换为对应的NAND Flash上的基本操作,最终向Host返回需要的数据。控制器在运行期间还会使用到易失高速缓存存储器(DRAM)和持久化存储(用户地址空间外的NAND Flash)。
Flash Translation Layer (FTL)
控制器需要完成的首要工作就是实现FTL。Host访问存储设备时,都使用48位的线性地址LBA(Logical Block Address),如果是HDD会把LBA转换成相应的(柱面,磁头,扇区),如果是SSD则需要把LBA转换成相应的(Block, Page)。FTL就需要负责完成LBA到(Block, Page)的映射与管理。
SSD与HDD的区别在于从LBA到(柱面,磁头,扇区)的映射是一个静态映射,例如典型的映射可以用下面这个关系表示,根据LBA完成相应的转换即可。
LBA = (( 柱面号 x 总磁头数 ) + 磁头号 ) x 每磁道的平均扇区数 + 扇区号 - 1
而SSD因为NAND Flash的存储介质特性与HDD不同,FTL需要完成的映射是动态的,下面以一个实例说明:
- 初始时block上有3个page包含数据,分别是x、y和z,有1个page是空闲的

- 修改page-0,page-0在擦除之前无法再次写入,于是写入一个新的版本,存在page-3,并在FTL中修改映射相同的LBA到新的page
- 再次修改page-1,则把所有page都拷贝到一个新的block,把老的block擦除,并更新FTL
通过上面的实例不难看出,FTL需要一个映射表才能完成从LBA到(Block,Page)的映射。该映射表会被存储在DRAM中,以保证控制器的高速访问。同时保证在断电前能够持久化到NAND Flash。
实现FTL最Naive的算法不难想到,有两种极端,一种是做Page级别的映射转换,另一种是做Block级别的映射转换。按照Page级别进行映射转换的问题在于映射表占用的空间会非常大,而按照Block级别则会造成在P/E过程中的写放大比例会增大。所以产品级的SSD都会使用某种优化的Block-Page混合映射算法。
垃圾回收
由于NAND Flash在一次编程之后必须先进行一次擦除才能再进行下一次编程,而且擦除的粒度和耗时都比较大,所以SSD产品都会在NAND Flash上封装垃圾回收功能:
- 在更新一个Page的时候不直接执行擦除操作,而是写入一个新的Page,并且在FTL中标记老的Page无效
- 垃圾回收逻辑在恰当的时机(通常是空闲时),选择恰当的Block(无效Page较多),把当中仍然有效的Page拷贝到其他Block,并执行Block的擦除操作
- 在FTL中标记Block的所有Page可写
如果垃圾回收的速度能够跟的上Page失效的速度,则SSD将尽量把垃圾回收放到后台,否则将会不得不在写入的时候进行垃圾回收,验证影响写入性能。
磨损均衡
前面提到每个Cell的最大P/E次数是有限的,所以控制器还需要设计巧妙的算法让P/E的次数尽量在每个Block上均衡的分布。通常,为了提升整体的寿命,SSD产品还会提供部分用户不可见的NAND Flash存储空间,在局部磨损实在不均衡的情况下进行提升,称作Over-Provisioning。
SSD的多级并行机制
SSD相对于HDD的优势主要来自去除机械部件后,单次读取时延的显著提升。如果单看一片NAND Flash所提供的带宽其实并不高,只有不到100MB/s。为了提高吞吐量,SSD内部实现了多级并行的优化技术,使得整体SSD的吞吐量得到极大提升,最高可到10几GB/s量级。
如下图所示,SSD使用层级的方式管理NAND Flash。Controller会使用多Channel的方式与NAND Flash Chip连接。每个Channel的吞吐量在100MB/s以下,以总线的方式可以连接一个或多个NAND Flash Chip。每个NAND Flash Chip内部封装(Packaging)了多个Die,每个Die上排列了多个Plane,每个Plane中包含多个Block,每个Block中有多个Page。
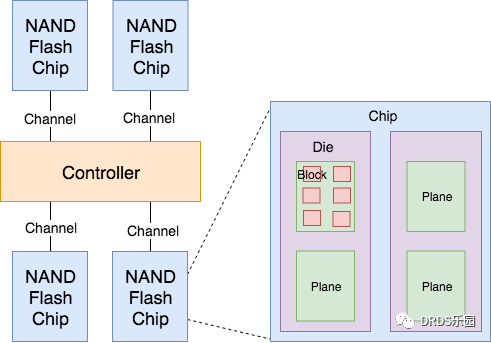
基于多层级的NAND Flash管理,SSD实现了多级并行机制:
- Channel级别:Controller可以同时使用多个Channel在不同的NAND Flash Chip上执行不同的操作
- Chip级别:连接在相同Channel上的不同的不同Chip,也可以使用流水线(Interleaving)的方式同时执行不同的命令
- Die级别:一个Chip封装多个Die,Chip可以把不同的命令发送到多个Die上并行执行
- Plane级别:一个Die包含多个Plane,相同的命令(读、写、擦除)可以在一个Die的多个Plane上同时执行
下面是Chip级别并行使用到的流水线(Interleaving)技术的一个简要图示:
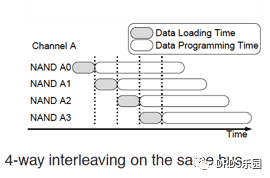
一个写入操作分两步完成:
- 把数据载入到Chip内部的寄存器
- 根据寄存器中的数据在NAND Flash芯片上执行编程操作
NAND Flash芯片的编程操作耗时比数据载入到寄存器的操作耗时长很多,可以用流水线的方式提升吞吐量。
Clustered Blocks:利用SSD多级并行机制,可以被并行访问的最大数量的Block集合称为一组Clustered Blocks。
程序员们打开SSD的正确方式
基于SSD在存储介质、操作模式和多级并行机制等各方面的特点,这一节为程序员们总结如何使用SSD构建高效存储系统的一些基础原则。
为了后面描述方便,先界定一下什么是IO操作上的顺序读写和随机读写:如果一个读、写操作所访问的LBA是上次读、写操作的所访问的最后一个LBA+1,则称这个读、写操作为顺序读、写,否则该读写操作就称作随机读、写。
另外,界定一下什么事大块读写,什么是小块读写:如果一次读写操作所读取、写入的数据大于等于SSD Cluster Block的大小,则称这样的读写操作是大块读、写,反之,小于Cluster Block大小的读写操作称作小块读、写。
写操作的优化
大块写是对SSD最友好的写操作模式,借助FTL和多级并行技术,SSD可以把一次大块写打散到多个Clustered Block上并行执行,有效降低时延,提高吞吐量。
顺序写和随机写的差别
如果写操作每次写入的数据量较小时,则顺序写的吞吐量显著高于随机写。虽然SSD的多级并行机制,对于无论是小块随机写还是小块顺序写,都可以把写操作在Clustered Block上并行执行,两者的区别主要体现在以下两个方面:
- 小块随机写将导致更多的FTL映射表更新,而顺序写可以合并FTL映射表的更新,显著降低映射表更新的开销
- 小块随机写更容易造成某个Block中少量的Page被设置为无效,需要进行擦除,加剧垃圾回收过程的写放大
如果随机写每次写入的数据比较大块,上述的两个效应将会显著降低,当每次写入的数据块达到Clustered Block大小时,顺序写与随机写的性能将保持相同。
单线程写和并发写的差别
单线程大块写是最快的。如果是大块写则没有必要再进行多线程并发写入,多线程并发写入会因为竞争提高写操作的时延。如果是小块写,则多线程并发写入有助于提高SSD多级并发机制的效益,提高吞吐量。上述特别总结在下面的表格中:
| 大块写 | 小块写 | |
|---|---|---|
| 单线程 | 最快 | 最慢 |
| 多线程并发 | 无助于吞吐量,提高时延 | 有助于提高多级并发机制的利用,提高吞吐量 |
读操作的优化
Write-Order-Based原则
由于取消了HDD的机械部件和寻道时间,SSD的读操作不再像HDD表现出顺序读操作相对于随机读操作的绝对优势。决定SSD读操作性能的是对多级并行机制的利用。能够打散到多个Cluster Block上并行执行的读操作,才能发挥出SSD的最大性能。
对SSD读操作的优化,被总结为“Write-Order-Based”原则。也就是说读操作需要尽量符合写操作的模式:哪些Page在写入的时候是被一起写入的,那么在读取的时候也尽量被一起读取。因为写入的时候SSD会尽量的把所写的Page打散到多个Clustered Block上进行并行,那么读操作如果同时读取这些Page将会获得最多的并行。相反如果读操作总是读取不同写操作写入的Page,那么这些Page很可能处于相同的Plane上,必须串行读取。以下图为例,SSD有4个Plane可以并行操作,4次写入操作都在这4个Plane上并行执行。Read-1操作因为遵循了“Write-Order-Based”原则,读取4个Page可以并行。而Read-2因为没有遵循“Write-Order-Based”原则,读取的4个Page落在了同一个Plane上,不得不串行执行。
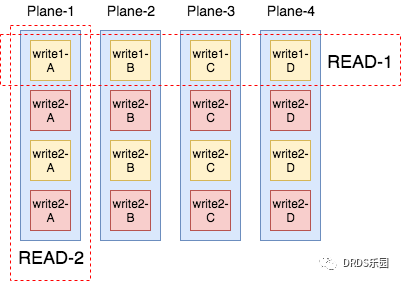
所以,不难推出一个SSD比较有意思的特性,把写操作优化为大块写不但能提升写操作本身的性能,还能提高读操作的性能。因为如果写操作非常随机,每次写的数据也非常小块,读操作就很难follow写操作的模式。而大块写操作对于读操作来说就比较好follow:一个比较简单的原则就是大块写-大块读,这样一次读操作就会很大概率命中一大批一次写操作写入的Page。
单线程读与并发读的差别
多线程并发读会使得SSD内部的一些read ahead机制失效,所以不建议多线程并发读,单线程的符合写模式的读是最高效的。
当然,对于大量小块读而言,多线程并发还是有提高利用多级并发机制的概率。
读写混合负载的优化
和并发读一样,并发读写混合操作对于SSD内部的一些read ahead机制也是会产生负作用的。所以处理读写混合负载的推荐的方式是一个跟着一个的执行大块的读、写操作。
冷热数据分离
热数据是指那些频繁更新的数据,冷数据则是很少更新的数据。如果把冷热数据不同的Page放在同一个Block中,则更新热数据也会连带冷数据被转移和擦除,带来更多的写放大。所以把冷数据和热数据分别放在不同的Block中可以减少包含冷数据的Block被擦除的次数。
TRIM
基于SSD构建文件系统的时候容易出现这么一个问题:文件系统中删除一个文件并不会真正的把文件所占的磁盘空间释放,而只是标记这些空间可用,等待后续新建文件的写入。这就会导致SSD后台的垃圾回收执行的不及时,只有新的文件真正需要写入这块空间时才进行垃圾回收,从而影响写入的性能。为此SSD支持显示的TRIM操作,可由上层用户发送到SSD,指明哪些LBA的空间可以释放。
另外,TRIM操作还可以用于实现结合上层应用知识的批量数据删除。上层应用可以结合自身的管理策略,把数据删除操作累积到一起,通过TRIM操作批量执行,提高效率。
小结
总结了SSD的基本结构与特性,以及程序员如何基于SSD构建高效存储系统的几条基础原则。DRDS HTAP存储打造同时为事务型和分析型数据库提供支持的高可靠、高效率的存储层,还有很多工作需要做,继续努力!