一、问题背景
倒排索引其实就是出现次数越多,那么权重越大,不过我国有凤巢....zf为啥不管,总局回应推广是不是广告有争议...
eclipse里ctrl+t找接口或者抽象类的实现类,看看都有啥方法,有时候hadoop的抽象类返回的接口没有需要的方法,那么我们返回他的实现类。
吧需要的文件放入hdfs下的目录下,只要不是以下划线开头的均算。
二、理论准备
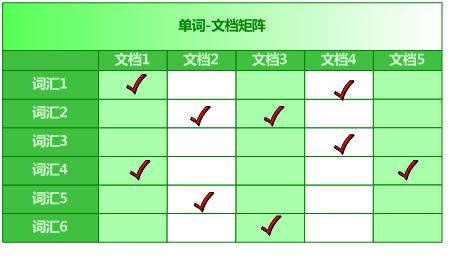
搜索引擎查询的时候就是查询这个单词文档矩阵,旺旺采用倒排索引存储,后缀树也可以。
不管理论直接看例子,这是原始的文档
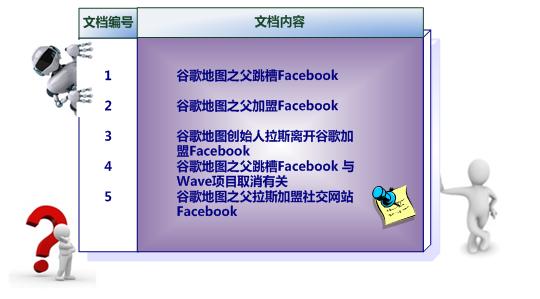
下面是简单的索引,只是表征是否在文档中出现过。
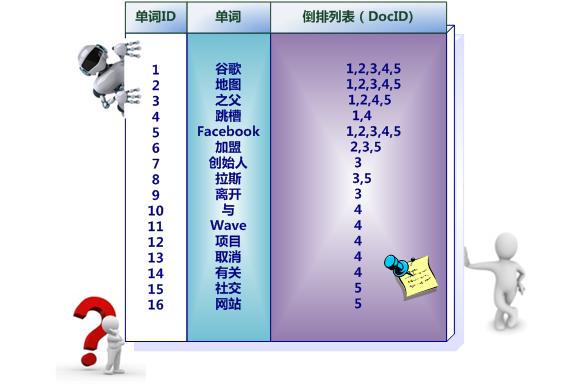
下面就是文档及出现次数。
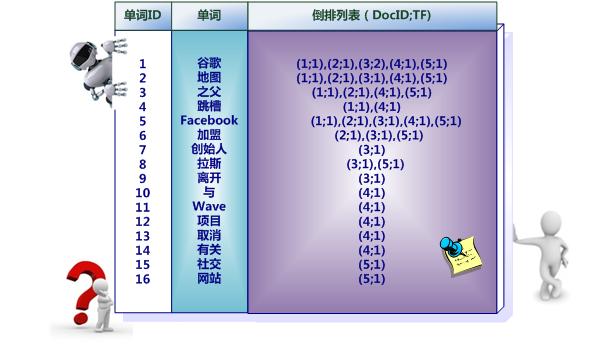
擦,咋有点想协同过滤。
三、思路分析
其实是一个全文检索的数据结构。理论上关键字出现次数越多,那么文章就越靠前。
就是wc的加强版本。wc是统计单词在文章里出现的次数,倒排是统计关键字在各个文章出现的次数。
有时候不能一下子写出来,可能需要多次mr,那么我们首先确定最终的结果形式,然后向上反推。
如果多个mr,考虑使用combiner,不过要考虑combiner是不是可插拔的,也就是combiner和业务逻辑是否和reducer一样。
怎么知道单词出现在那个文章里?从context对象里获取。既然能忘context写东西,那么也能从其中获取信息。
最终结果是
hello "a.txt->5 b.txt->3" tom "a.txt->2 b.txt->1" kitty "a.txt->1"
那么reduce的输出
context.write("hello","a.txt->5 b.txt->3");
那么combiner阶段是
<"hello",{"a.txt->5","b.txt->3"}>
那么map的输出
context.write("hello","a.txt->5");
context.write("hello","b.txt->3");
不过考虑到wc,map的输出应该是,路径放在value不好处理,还要廉价呢。
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->b.txt",1);
context.write("hello->b.txt",1);
context.write("hello->b.txt",1);
那么combiner阶段根据就输出
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->b.txt",1>
<"hello->b.txt",1>
<"hello->b.txt",1>
context.write("hello","a.txt->5");
context.write("hello","b.txt->3");
次是不同文件的相同key并没有合并,reducer合并输出皆可。
四、代码实现
4.1 Mapper
public class IIMapper1 extends Mapper<LongWritable, Text, Text, Text> {
private Text k = new Text();
//下面其实是int,不过也可以在接收端Integer.parseInt转了就好
private Text v = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
//从context对象里找到单词属于那个文章
//context.getInputSplit();找到切片 按ctrl找 发现返回时InputSplit
//不过是个抽象类 ctrl + t找他的实现类
//能把数据写入context,繁殖也能从context拿到很多信息
//从下面inputSplit调用get的时候发现没有合适的方法,那么我们找他的实现类,调用实现类的方法
//InputSplit inputSplit = context.getInputSplit();
//inputSplit.get
//他的子类很多 我们处理文件就用File开头的 然后有个getPath
FileSplit inputSplit = (FileSplit)context.getInputSplit();
//文件名是hdfs://hostname:port/a/1.txt
//我们戒掉hdfs://hostname:port 不能戒掉a 应为这是文件夹否则不知道1.txt来自哪 其他文件家下可能也有同名文件
//也可以不接去
String path = inputSplit.getPath().toString();
for(String w:words) {
k.set(w+"->"+path);
v.set("1");
context.write(k, v);
}
}
}
4.2 Combiner
String[] wordAndPath = key.toString().split("->");
String word = wordAndPath[0];
String path = wordAndPath[1];
// process values
int sum = 0;
for (Text val : value) {
sum += Integer.parseInt(val.toString());
}
k.set(word);
v.set(path+"->"+sum);
context.write(k, v);
4.3 Reducer
//不涉及多线程 用StringBuilde即可
StringBuilder sb = new StringBuilder();
// process values
for (Text val : value) {
sb.append(val.toString()).append(" ");
}
context.write(key, new Text(sb.toString()));
四、实验分析
