Python基础学习04
文件操作
字符编码字符转码
简单三级菜单
简单购物车
一、文件操作
1、文件打开操作


1 f = open("text.txt",encoding = "utf-8") #文件句柄 2 data = f.read() #读文件内容 3 data_2 = f.read() 4 print( data ) #正常输出 5 print("aaaaaaaaaaa") #输出:aaaaaaaaaaa 6 print(data_2) #无输出(文件读完之后光标移动到最后,在次读不会有新的内容) 7 f.close() #关闭文件 8 #此为非规范书写,没有书写读写模式,默认为读模式 9 f = open("text.txt","r",encoding = "utf-8") #标准书写(只能读文件) 10 f.close() 11 12 f = open("text_1.txt","w",encoding = "utf-8") #创建一个新文件,并以写模式打开,若之前存在同名的文件则会覆盖 13 f.write("你不面对现实 ") #只能对文件进行写操作,不能读取 14 f.write("现实就会面对你") 15 f.close() 16 '''文档内容: 17 你不面对现实 18 现实就会面对你 19 ''' 20 21 f = open("text_1.txt","a",encoding = "utf-8") #以写模式打开一个文件,并在文件末尾追加新内容 22 f.write(" 勿以恶小而为之 ") #只能对文件进行写操作,不能读取 23 f.write("勿以善小而不为") 24 f.close() 25 '''文档内容: 26 你不面对现实 27 现实就会面对你 28 勿以恶小而为之 29 勿以善小而不为 30 ''' 31 # r:只读模式(默认)。 32 # w:只写模式。(不可读;不存在则创建;存在则删除内容;) 33 # a:追加模式。(不可读;不存在则创建;存在则只追加内容;) 34 35 #预先读取文件内容到内存中(少用) 36 f = open("text.txt","r",encoding = "utf-8") 37 for i in range(3): 38 print(f.readline()) #逐行读取,读取前3行 39 for line in f.readlines(): #预先读取文件内容并把文件中所有内容以列表的形式存到内存中(不适用于大文件) 40 print(line.strip()) #逐行打印全部文件内容(strip()去掉换行空格) 41 42 for index,line in enumerate(f.readlines()): 43 if index == 5 : #当文件读取到第5行时 44 print('----------') #用"----------"来替换第6行的内容 45 continue #继续读取 46 print(line.strip()) #打印读取内容 47 48 #逐行读取文件内容到内存中(常用) 49 count = 0 50 for line in f: 51 if count == 5: 52 print('----------') 53 count += 1 54 continue 55 print(line.strip()) 56 count += 1 57 f.close() 58 59 60 61 # "+" 表示可以同时读写某个文件 62 # r+,可读写文件。(可读;可写(追加写模式)) 63 # w+,写读(先新建文件,然后写入新内容,之后读自己写的内容) 64 # a+,追加读写 65 66 f = open("text.txt","r+",encoding = "utf-8") #常用 67 f.close() 68 69 f = open("text_2.txt","w+",encoding = "utf-8") #不常用 70 f.write("________________ ") 71 f.write("++++++++++++++++ ") 72 f.write("================ ") 73 f.seek(0) 74 print(f.readline()) #输出:________________ 75 print(f.readline()) #输出:++++++++++++++++ 76 print(f.readline()) #输出:================ 77 f.close() 78 79 #"b"表示处理二进制文件(bytes类型) 80 # rb 81 # wb 82 # ab 83 #网络传输会用到,网络传输只能用二进制模式 84 f = open("text.txt","rb") #二进制读 85 print(f.readline()) #输出:# b'When you are old ' 86 f.close() 87 88 f = open("text_2.txt","wb") #二进制写 89 f.write("当你老了".encode()) 90 f.close()
2、其他操作
1 f = open("text_1.txt","r",encoding = "utf-8") 2 print(f.tell()) #文件句柄指针指向的位置 输出:0 3 print(f.readline()) #读1行内容 4 print(f.tell()) #输出:20 5 6 print(f.readline()) #在读一行内容 输出:现实就会面对你 7 f.seek(20) #将文件句柄指针指向的位置移动到指定位置 8 print(f.readline()) #输出:现实就会面对你 9 10 f.flush() #刷新(写完数据后数据是存在内存缓存中的,flush是把缓存中的数据存到硬盘中) 11 f.close() 12 #实现进度条 13 import sys,time 14 for i in range(50): 15 sys.stdout.write("#") 16 sys.stdout.flush() 17 time.sleep(0.1) 18 19 f = open("text_1.txt","a",encoding = "utf-8") 20 f.truncate(10) #从文件开头开始截断指定个数字符,不写内容会清空文件
3、文件修改
1 #文件修改:打开一个文件,修改后存到一个新的文件 2 f = open("text.txt","r",encoding = "utf-8") #以读模式打开源文件 3 f_new = open("text_new.txt","w",encoding = "utf-8") #以写模式打开新文件 4 for line in f: #逐行读取 5 if "慢慢读着" in line: #找到想要修改的位置 6 line = line.replace("慢慢读着","manmanduzhe") #修改字符串 7 f_new.write(line) #将内容写入新文件 8 f.close() 9 f_new.close() 10 11 12 #实现简单的shell sed 替换功能 13 import sys 14 f = open("text.txt","r",encoding = "utf-8") #以读模式打开源文件 15 f_new = open("text_new.txt","w",encoding = "utf-8") #以写模式打开新文件 16 find_str = sys.argv[1] 17 replace_str = sys.argv[2] 18 for line in f: #逐行读取 19 if find_str in line: #找到想要修改的位置 20 line = line.replace(find_str,replace_str) #修改字符串 21 f_new.write(line) #将内容写入新文件 22 f.close() 23 f_new.close()
4、with操作
1 #f = open("text.txt","r",encoding = "utf-8") #以读模式打开源文件 2 with open("text.txt","r",encoding = "utf-8") as f: #与上面功能相同 3 print(f.readline()) 4 #为了避免打开文件后忘记关闭 5 6 #在Python 2.7 后,with又支持同时对多个文件的管理,即: 7 with open('log1') as obj1, open('log2') as obj2: 8 pass 9 #python开发规范:一行代码尽量不要超过80个字符(所以上面格式可以写成下面这样) 10 with open("text.txt","r",encoding = "utf-8") as f, 11 open("text_2.txt","r",encoding = "utf-8") as f2: 12 pass
二、字符编码字符转码
一、字符编码
1、ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)
是基于字母的一套电脑编码系统,主要用于显示现代英语,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1种不同状态,每种状态就唯一对应一个字符,比如A--->00010001,而英文只有26个字符,算上一些特殊字符和数字,128个状态也够,这样计算机就可以用127个不同字节来存储英语的文字了。这就是ASCII编码。
扩展ANSI编码
最开始,一个字节有八位,但是最高位没用上,默认为0;后来为了计算机也可以表示拉丁文,就将最后一位也用上了,从128到255的字符集对应拉丁文。所以,ASCII码主要用于显示现代英语和其他西欧语言,最多只能表示 255 个符号。
2、GB2312(1980年)
计算机来到中国后,计算机不认识中文,当然也没法显示中文;而且一个字节所有状态都被占满了,于是中国人重写一张表,直接将扩展的第八位对应拉丁文全部删掉,规定一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合大约7000多个简体汉字了(一共收录了7445个字符);这种汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展。
3、GBK 和 GB18030编码
汉字太多了,GB2312不够用,于是规定:只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。
2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。
现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
4、UNICODE编码
很多其它国家都搞出自己的编码标准,彼此间却相互不支持。这就带来了很多问题。于是,国际标谁化组织为了统一编码,提出了标准编码准则:UNICODE 。
Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定由 16 位来表示一个字符(2个字节),即:2 **16 = 65536,这足以覆盖世界上所有符号(包括甲骨文)
5、UTF-8
unicode可以解决所有编码,为什么还要有一个utf-8的编码呢?
对于英文世界的人们来讲,一个字节完全够了,比如要存储A,本来00010001就可以了,现在unicode得用两个字节:00000000 00010001才行,浪费太严重,基于此,科学家们提出了:utf-8。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...这样好处是,虽然在我们内存中的数据都是unicode,但当数据要保存到磁盘或者用于网络传输时,直接使用unicode就远不如utf-8省空间,这也是为什么utf-8是推荐编码方式。
Unicode与utf8的关系:
Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
二、py2字符编码字符转码
在py2中,有两种字符串类型:str类型和unicode类型;str类型存字节数据,unicode存的是unicode数据
在python2默认编码是ASCII
1 #coding:utf-8 #在python2中默认编码是ASCII,必须声明编码,否则不能解析中文,会报如下错误信息 2 # SyntaxError: Non-ASCII character 'xe4' in file zz.py on line 4, but no encoding declared; 3 4 s1='你好' #在py2中定义字符串(默认类型) 5 print type(s1) # <type 'str'> #类型为str类型 6 print repr(s1) #'xe4xbdxa0xe5xa5xbd' #存储的数据为字节数据 7 s2=u'你好' #用unicode类型定义字符串 8 print type(s2) # <type 'unicode'> #类型为unicode类型 9 print repr(s2) # u'u4f60u597d' #存储的数据unicode数据 10 11 b=s2.encode('utf-8') #将unicode数据以utf-8进行编码 12 print b #浣犲ソ #输出乱码 13 print type(b) #<type 'str'> #类型为str类型 14 print repr(b) #'xe4xbdxa0xe5xa5xbd' 15 16 u=s1.decode('utf-8') #将utf-8编码的字节用utf-8的规则解码 17 print u # 你好 18 print type(u) # <type 'unicode'> #解码后数据类型为unicode类型 19 print repr(u) # u'u4f60u597d' #存储的数据unicode数据 20 21 u2=s1.decode('gbk') #将utf-8编码的字节用gbk的规则解码 22 print u2 #浣犲ソ #输出乱码 23 print type(u2) # <type 'unicode'> #解码后数据类型依旧为unicode类型
无论是utf8还是gbk都只是一种编码规则,一种把unicode数据编码成字节数据的规则,所以utf8编码的字节一定要用utf8的规则解码,否则就会出现乱码或者报错的情况
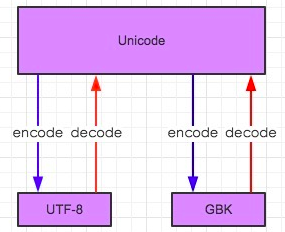
在Python2中运行带有中文的程序会先声明编码,一般为UTF-8或GBK,定义字符串后,字符串的数据格式为bytes,如果需要打印输出,需将bytes类型decode为事先声明的编码
转换编码时,需先decode(“当前编码”),解码成Unicode,后将Unicode编码encode(“目标编码”)。此时转换完成
1 #coding:utf-8 2 3 import sys 4 print(sys.getdefaultencoding()) #ascii 5 6 msg = "你好" 7 msg_gb2312 = msg.decode("utf-8").encode("gb2312") #将utf-8编码转换成gb2312编码 8 gb2312_to_gbk = msg_gb2312.decode("gbk").encode("gbk") #将gb2312编码转换成gbk编码 9 10 print(msg) #浣犲ソ (py2中str类型存字节数据) 11 print(msg.decode("utf-8")) #你好 将msg的字节数据以utf-8解码 12 print(msg_gb2312) #你好 13 print(gb2312_to_gbk) #你好
三、py3字符编码字符转码
py3也有两种数据类型:str和bytes; str类型存unicode数据,bytse类型存bytes数据,与py2比只是换了一下名字而已。
在python3默认编码是unicode
1 #py3中默认编码是unicode类型,不用声明编码,也能解析中文 2 import json 3 s1='你好' #在py3中定义字符串(默认类型) 4 print(type(s1)) #<class 'str'> #类型为str类型 5 print(json.dumps(s1)) # "u4f60u597d" #存储的数据为unicode类型数据 6 7 #s2 = b"你好" #py3中不能把中文直接定义成字节类型,会报错:SyntaxError: bytes can only contain ASCII literal characters. 8 #字节只能包含ASCII文字字符 9 10 b=s1.encode('utf-8') #将字符串以utf-8格式编码 11 print(type(b)) # <class 'bytes'> #编码后数据类型为bytes类型 12 print(b) # b'xe4xbdxa0xe5xa5xbd' #以bytes格式输出字符串 13 14 u=b.decode('utf-8') #将bytes类型数据以utf-8格式解码 15 print(type(u)) #<class 'str'> #解码后数据类型为str类型 16 print(u) #你好 #打印输出 17 print(json.dumps(u)) #"u4f60u597d" #存储的数据为unicode类型数据
在Python3中默认就是unicode,不用再decode
1 import sys 2 print(sys.getdefaultencoding()) #utf-8 3 4 msg = "你好" 5 6 msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode 7 gb2312_to_unicode = msg_gb2312.decode("gb2312") #将gb2312编码的bytes类型数据 8 gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8") 9 #将gb2312编码的字符串,先解码后编码成utf-8类型到bytes数据 10 print(msg) # 你好 #默认就是unicode,不用再decode直接显示 11 print(msg_gb2312) #b'xc4xe3xbaxc3' #encode后变成gb2312编码的bytes类型 12 print(gb2312_to_unicode) #你好 #将将gb2312编码的bytes类型数据解码 13 print(gb2312_to_utf8) #b'xe4xbdxa0xe5xa5xbd' #utf-8编码后的bytes类型
三、简单三级菜单
1 data = { 2 '山东':{ 3 '青岛' :['四方','黄岛','崂山','李沧','城阳'], 4 '济南' : ['历城','槐荫','高新','长青','章丘'], 5 '烟台' : ['龙口','莱山','牟平','蓬莱','招远'] 6 }, 7 '江苏':{ 8 '苏州' : ['沧浪','相城','平江','吴中','昆山'], 9 '南京' : ['白下','秦淮','浦口','栖霞','江宁'], 10 '无锡' : ['崇安','南长','北塘','锡山','江阴'] 11 }, 12 '河北': { 13 '石家庄': ['鹿泉', '藁城', '元氏'], 14 '邯郸': ['永年', '涉县', '磁县'], 15 } 16 } 17 run_data = True 18 while run_data: 19 for i in data: 20 print(i) 21 choice = input('选择进入的菜单,按q退出:') 22 if choice in data: 23 while run_data: 24 for i1 in data[choice]: 25 print(i1) 26 print('按q退出,按b返回上一级菜单!') 27 choice1=input('选择进入的菜单:') 28 if choice1 in data[choice]: 29 while run_data: 30 for i2 in data[choice][choice1]: 31 print(i2) 32 choice3 = input('按q退出,按b返回上一级菜单!:') 33 if choice3 == 'b': 34 break 35 elif choice3 == 'q': 36 run_data= False 37 else: 38 print('这是最后一级菜单!') 39 elif choice1 == 'b': 40 break 41 elif choice1 == 'q': 42 run_data=False 43 else: 44 print('请输入正确的编号!') 45 elif choice == 'q': 46 run_data=False 47 else: 48 print('请输入正确的编号!')
四、简单购物车
1 product_list = [ 2 ('iphone',5000), 3 ('computer',6000), 4 ('watch',1500), 5 ('bike',100), 6 ('book',50), 7 ('fruit',20) 8 ] 9 shopping_list = [] 10 sallary = input("Please Input Your Sallary:") 11 if sallary.isdigit(): 12 sallary = int(sallary) 13 while True: 14 #for item in product_list: 15 # print(product_list.index(item),item) 16 for index,item in enumerate(product_list): 17 print(index,item) 18 print('input q to finish your shopping') 19 user_choice = input("please input your goods number:") 20 if user_choice.isdigit(): 21 user_choice = int(user_choice) 22 if user_choice<len(product_list) and user_choice>=0: 23 p_item = product_list[user_choice] 24 if p_item[1] < sallary: 25 shopping_list.append(p_item) 26 sallary -=p_item[1] 27 print("Add %s into shopping cart , your current balence is %s"%(p_item,sallary)) 28 else: 29 print("you dont have so much money! ") 30 else: 31 print("there is no goods with your number!!") 32 elif user_choice == 'q': 33 print('-----your shopping list-----') 34 for p in shopping_list: 35 print(p) 36 print("your current balance is :",sallary) 37 exit() 38 else: 39 print("please input right number!!") 40 #break 41 else: 42 print("Please input right sallary!!")