简介
最近在看 speechbrain 语音识别项目,其中第一步就是对文本标签进行 tokenization 了,各种参数看得云里雾里的,现在系统
总结 googel的 sentencepiece 的使用。
参考:https://github.com/google/sentencepiece
一、安装
pip install sentencepiece
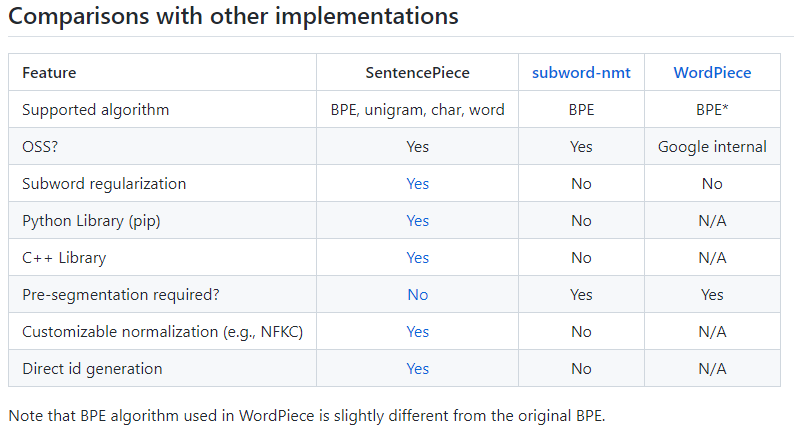
二、支持的切词方法
三、python 接口的使用
import sentencepiece as spm # Model Training ''' --input: one-sentence-per-line raw corpus file. No need to run tokenizer, normalizer or preprocessor. By default, SentencePiece normalizes the input with Unicode NFKC. You can pass a comma-separated list of files. --model_prefix: output model name prefix. <model_name>.model and <model_name>.vocab are generated. --vocab_size: vocabulary size, e.g., 8000, 16000, or 32000 --character_coverage: amount of characters covered by the model, good defaults are: 0.9995 for languages with rich character set like Japanese or Chinese and 1.0 for other languages with small character set. --model_type: model type. Choose from unigram (default), bpe, char, or word. The input sentence must be pretokenized when using word type. ''' # 一些特殊字符的处理 ''' 1. By default, SentencePiece uses Unknown (<unk>), BOS (<s>) and EOS (</s>) tokens which have the ids of 0, 1, and 2 respectively 2. We can redefine this mapping in the training phase as follows. -bos_id=0 --eos_id=1 --unk_id=5 3. When setting -1 id e.g., bos_id=-1, this special token is disabled. Note that the unknow id cannot be disabled. We can define an id for padding (<pad>) as --pad_id=3. ''' spm.SentencePieceTrainer.Train(input='botchan.txt', model_prefix='m', model_type="unigram", vocab_size=1000) # 在当前目录下生成 m.model 和 m.vocab 文件 # 加载训练好的模型,切分文本 sp = spm.SentencePieceProcessor(model_file='m.model') # 编码 text -> id result = sp.encode(['This is a test', 'Hello world'], out_type=int) print(result) result = sp.encode(['This is a test', 'Hello world'], out_type=str) print(result) # 解码 id -> text result = sp.decode([285, 46, 10, 170, 382]) print(result) result = sp.decode(['▁This', '▁is', '▁a', '▁t', 'est']) print(result) # 采样 for _ in range(10): result = sp.encode('This is a test', out_type=str, enable_sampling=True, alpha=0.1, nbest_size=-1) print(result) # 其它常用方法 sp.get_piece_size() sp.id_to_piece(2) sp.id_to_piece([2, 3, 4]) sp.piece_to_id('<s>') sp.piece_to_id(['</s>', ' ', '▁'])