循环神经网络可以更好的利用传统神经网络结构所不能建模的信息,但同时也会出现——长期依赖问题(long-term dependencies)
例如,当前时刻的预测值要依赖之间时刻的信息,当两个时间间隔较短时,RNN可以比较容易地利用先前时刻信息。但当这两个时间间隔不断变长时,简单的循环神经网络有可能会丧失学习到距离很远的时刻的信息的能力。在一些复杂语言场景中,有用信息的间隔有大有小、长短不一,简单的RNN网络的性能会收到限制。而LSTM网络的设计就是为了解决该问题。LSTM网络的结构如下图所示:
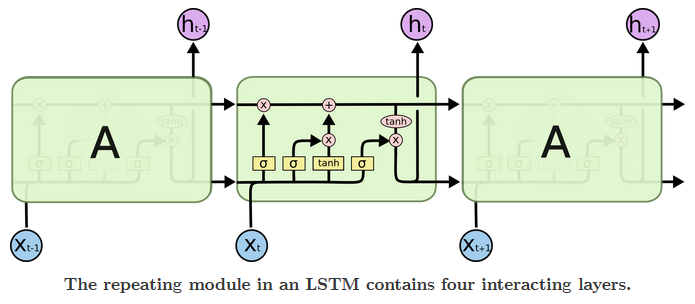

详细介绍参考:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
以下代码展示了在tensorflow中实现使用LSTM结构的循环神经网络的前向传播过程。
# 定义一个LSTM结构,LSTM中使用的变量也会在该函数中自动被声明 lstm=rnn_cell.BasicLSTMCell(lstm_hidden_size) # 将LSTM中的状态初始化为全0数组,BasicLSTMCell提供了zero_state函数来生成全零的初始状态 state=lstm.zero_state(batch_size,tf.float32) # 定义损失函数 loss=0.0 # 理论上循环神经网络可以处理任意长度的序列,但是在训练时为了避免梯度消散的问题,会规定一个最大的序列长度 # 下面代码使用参数num_steps来表示这个长度 for i in range(num_steps): # 在第一个时刻声明LSTM结构中使用的变量,在之后的时刻都需要复用之前定义好的变量 if i>0: tf.get_variable_scope().reuse_variables() # 每一步处理时间序列中的一个时刻。将当前输入(current_input)和前一时刻状态(state)传入定义的LSTM结构可以得到 # 当前LSTM结构的输出lstm_output和更新后的状态state lstm_output,state=lstm(current_input,state) # 将当前时刻LSTM结构的输出传入一个全连接层得到最后的输出 final_output=fully_connected(lstm_output) # 计算当前时刻输出的损失 loss+=calc_loss(final_output,expected_output)
LSTM网络的变体:双向循环神经网络和深层循环神经网络
双向循环神经网络的主体结构是由两个单向循环神经网络组成的。在每一个时刻t,输入会同时提供给这两个方向相反的循环神经网络,而输出则是由这两个单向循环神经网络共同决定。其结构如下图所示:
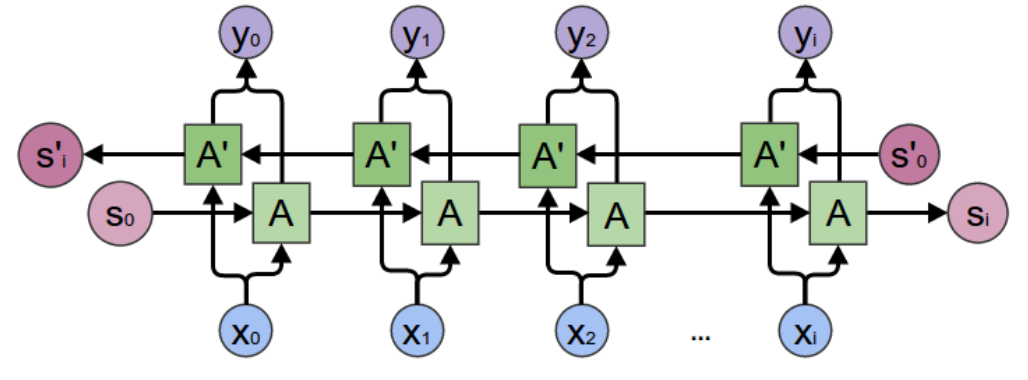
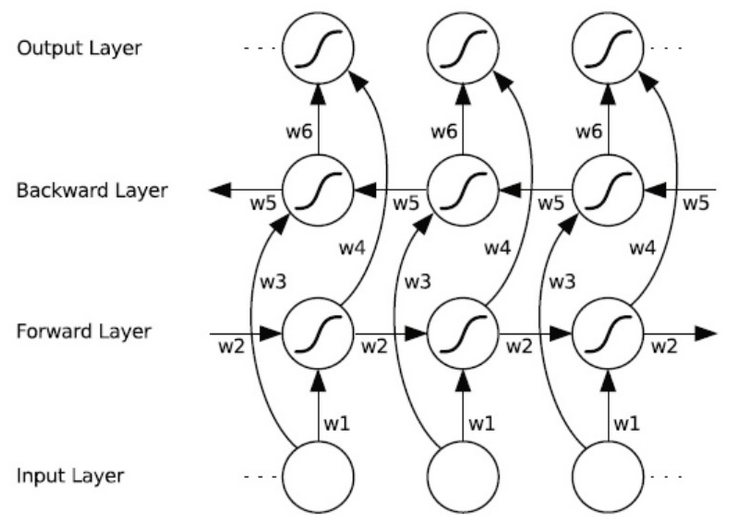
六个权值分别对应:输入到向前和向后隐含层(w1, w3),隐含层到隐含层自己(w2, w5),向前和向后隐含层到输出层(w4, w6)。值得注意的是:向前和向后隐含层之间没有信息流,这保证了展开图是非循环的。
深层循环神经网络:为了增强模型的表达能力,该网络在每一个时刻上将循环体结构复制多次,每一层的循环体中参数是一致的,而不同层中的参数可以不同。其结构如下图所示:
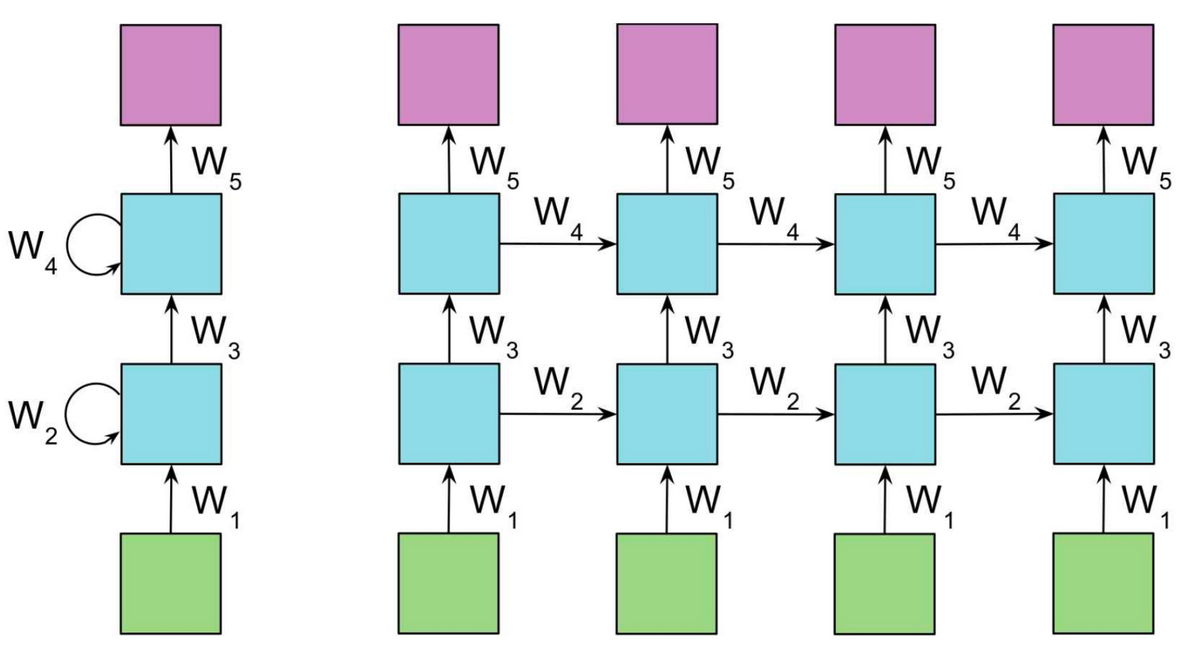
tensorflow中提供了MultiRNNCell类来实现深层循环神经网络的前向传播过程。代码如下:
# 定义一个基本的LSTM结构作为循环体的基础结构。深层循环神经网络也支持使用其他的循环体结构 lstm=rnn_cell.BasicLSTMCell(lstm_size) # 通过MultiRNNCell类实现深层循环神经网络中每一个时刻的前向传播过程。其中number_of_layers表示有多少层。 stacked_lstm=rnn_cell.MultiRNNCell([lstm]*number_of_layers) # 通过zero_state函数来获取初始状态 state=stacked_lstm.zero_state(batch_size,tf.float32) # 定义损失函数 loss=0.0 for i in range(num_steps): if i>0: tf.get_variable_scope().reuse_variables() stacked_lstm_output,state=stacked_lstm(current_input,state) # 将当前时刻LSTM结构的输出传入一个全连接层得到最后的输出 final_output=fully_connected(stacked_lstm_output) # 计算当前时刻输出的损失 loss+=calc_loss(final_output,expected_output)
1、在PTB数据集上使用循环神经网络实现语言模型
读取数据集
import tensorflow as tf import reader # 存放原始数据的路径。 DATA_PATH='data' train_data,valid_data,test_data,_=reader.ptb_raw_data(DATA_PATH) # 读取原始数据 print(len(train_data)) print(train_data[:100])
输出:929589
[9970, 9971, 9972, 9974, 9975, 9976, 9980, 9981, 9982, 9983, 9984, 9986, 9987, 9988, 9989, 9991, 9992, 9993, 9994, 9995, 9996, 9997, 9998, 9999, 2, 9256, 1, 3, 72, 393, 33, 2133, 0, 146, 19, 6, 9207, 276, 407, 3, 2, 23, 1, 13, 141, 4, 1, 5465, 0, 3081, 1596, 96, 2, 7682, 1, 3, 72, 393, 8, 337, 141, 4, 2477, 657, 2170, 955, 24, 521, 6, 9207, 276, 4, 39, 303, 438, 3684, 2, 6, 942, 4, 3150, 496, 263, 5, 138, 6092, 4241, 6036, 30, 988, 6, 241, 760, 4, 1015, 2786, 211, 6, 96, 4]
该训练数据集中总共包含了929589单词,其中句子结束的标识符ID为2。
虽然循环神经网络可以接受接受任意长度的序列,但在训练时需要将序列按照某个固定的长度来截断。如下代码将实现句子截断并组织成batch。
# 将训练数据组织成batch大小为4、截断长度为5的数组。 # 读取每个batch中的数据,其中包括每个时刻的输入和对应的正确输出。 x, y = reader.ptb_producer(train_data, 4, 5) with tf.Session() as sess: coord = tf.train.Coordinator() tf.train.start_queue_runners(sess, coord=coord) try: x,y=sess.run([x,y]) print(x) print(y) finally: coord.request_stop() coord.join()
完整的模型代码实现:
import tensorflow as tf import reader import numpy as np DATA_PATH='data' # 存放原始数据的路径。 HIDDEN_SIZE=200 # 隐藏层大小 NUM_LAYERS=2 # 深层循环神经网络中LSTM结构的层数 VOCAB_SIZE=10000 # 词典规模,加上语句结束标识符和稀有单词标识符总共一万个单词 LEARNING_RATE=1.0 # 学习速率 TRAIN_BATCH_SIZE=20 # 训练数据batch的大小 TRAIN_NUM_STEP=35 # 训练数据截断长度 # 在测试时不需要使用截断,所以可以将测试数据看成一个超长的序列 EVAL_BATCH_SIZE=1 # 测试数据batch的大小 EVAL_NUM_STEP=1 # 测试数据截断长度 NUM_EPOCH=2 # 使用训练数据的轮数 KEEP_PROB=0.5 # 节点不被dropout的概率 MAX_GRAD_NORM=5 # 用于控制梯度膨胀的参数 # 通过一个PTBModel类来描述模型。 class PTBModel(object): def __init__(self,is_training,batch_size,num_steps): # 记录使用的batch大小和截断长度 self.batch_size=batch_size self.num_steps=num_steps # 定义输入层,维度为: batch_size * num_steps self.input_data=tf.placeholder(tf.int32,[batch_size,num_steps]) # 定义预期输出。 self.targets=tf.placeholder(tf.int32,[batch_size,num_steps]) # 定义使用LSTM结构为循环体结构且使用dropout的深层循环神经网络。 lstm_cell=tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) if is_training: lstm_cell=tf.nn.rnn_cell.DropoutWrapper(lstm_cell,output_keep_prob=KEEP_PROB) cell=tf.nn.rnn_cell.MultiRNNCell([lstm_cell]*NUM_LAYERS) # 初始化最初的状态,也就是全零的向量。 self.initial_state=cell.zero_state(batch_size,tf.float32) # 将单词ID转换成单词向量。因为总共有VOCAL_SIZE个单词,每个单词向量的维度为HIDDEN_SIZE,所以 # embedding参数的维度为VOCAB_SIZE * HIDDEN_SIZE embedding=tf.get_variable('embedding',[VOCAB_SIZE,HIDDEN_SIZE]) # 将原本batch_size * num_steps个单词ID转化为单词向量, # 转化后的输入层维度为:batch_size * num_steps * HIDDEN_SIZE inputs=tf.nn.embedding_lookup(embedding,self.input_data) # 只在训练时使用dropout if is_training: inputs=tf.nn.dropout(inputs,KEEP_PROB) # 定义输出列表。在这里先将不同时刻LSTM结构的输出收集起来,再通过一个全连接 # 层得到最终的输出 outputs=[] # state 存储不同batch中LSTM的状态,将其初始化为0。 state=self.initial_state with tf.variable_scope('RNN'): for time_step in range(num_steps): if time_step>0: tf.get_variable_scope().reuse_variables() # 从输入数据中获取当前时刻的输入并传入LSTM结构 cell_output,state=cell(inputs[:,time_step,:],state) # 将当前输出加入输出队列 outputs.append(cell_output) # 将输出队列展开成[batch,hidden_size*num_steps]的形状,然后再reshape # 成[batch*num_steps,hidden_size]的形状 output = tf.reshape(tf.concat(outputs, 1), [-1, HIDDEN_SIZE]) # 将从LSTM中得到的输出在经过一个全连接层得到最后的预测结果,最终的预测结果在 # 每一个时刻上都是一个长度为VOCAB_SIZE的数组,经过softmax层之后表示下一个位置 # 各单词出现的概率 weight=tf.get_variable('weight',[HIDDEN_SIZE,VOCAB_SIZE]) bias=tf.get_variable('bias',[VOCAB_SIZE]) logits=tf.matmul(output,weight)+bias # 定义交叉熵损失函数。tesorlfow提供了 loss=tf.contrib.legacy_seq2seq.sequence_loss_by_example( [logits], # 预测的结果 [tf.reshape(self.targets,[-1])], # 正确的答案,这里将[batch_size,num_steps]二维数组转换为一维数组 # 损失的权重。在这里所有的权重都为1,也就是说不同batch和不同时刻的重要程度是一样的。 [tf.ones([batch_size*num_steps],dtype=tf.float32)] ) # 计算得到每个batch的平均损失 self.cost=tf.reduce_sum(loss)/batch_size self.final_state=state # 只在训练模型时定义反向传播操作 if not is_training: return trainable_variables=tf.trainable_variables() # 通过clip_by_global_norm函数控制梯度的大小,避免梯度膨胀问题。 grads,_=tf.clip_by_global_norm( tf.gradients(self.cost,trainable_variables),MAX_GRAD_NORM) # 定义优化方法 optimizer=tf.train.GradientDescentOptimizer(LEARNING_RATE) # 定义训练步骤 self.train_op=optimizer.apply_gradients(zip(grads,trainable_variables)) # 使用给定的模型model在数据data上运行train_op并返回在全部数据上的perplexity值 def run_epoch(session,model,data,train_op,output_log,epoch_size): # 计算perplexity的辅助变量 total_costs=0.0 iters=0 state=session.run(model.initial_state) # 使用当前数据训练或者训练模型 for step in range(epoch_size): x, y = session.run(data) # 在当前batch上运行train_op并计算损失值。交叉熵损失函数计算的就是下一个单词为给定 # 单词的概率 cost,state,_=session.run([model.cost,model.final_state,train_op], {model.input_data:x,model.targets:y,model.initial_state:state}) # 将不同时刻、不同batch的概率加起来就可以得到第二个perplexity公式等号右边的部分, # 再将这个和做指数运算就可以得到perplexity值。 total_costs+=cost iters+=model.num_steps # 只有在训练时输出日志。 if output_log and step % 100 ==0: print('After {} steps,perplexity is {}'.format(step,np.exp(total_costs/iters))) # 返回指定模型在给定数据上的perplexity值 return np.exp(total_costs/iters) def main(_): # 获取原始数据 train_data,valid_data,test_data,_=reader.ptb_raw_data(DATA_PATH) # 计算一个epoch需要训练的次数 train_data_len = len(train_data) train_batch_len = train_data_len // TRAIN_BATCH_SIZE train_epoch_size = (train_batch_len - 1) // TRAIN_NUM_STEP valid_data_len = len(valid_data) valid_batch_len = valid_data_len // EVAL_BATCH_SIZE valid_epoch_size = (valid_batch_len - 1) // EVAL_NUM_STEP test_data_len = len(test_data) test_batch_len = test_data_len // EVAL_BATCH_SIZE test_epoch_size = (test_batch_len - 1) // EVAL_NUM_STEP # 定义初始化函数 initializer=tf.random_uniform_initializer(-0.05,0.05) # 定义训练用的循环神经网络模型。 with tf.variable_scope('language_model',reuse=None,initializer=initializer): train_model=PTBModel(True,TRAIN_BATCH_SIZE,TRAIN_NUM_STEP) # 定义评测用的循环神经网络模型。 with tf.variable_scope('language_model',reuse=True,initializer=initializer): eval_model=PTBModel(False,EVAL_BATCH_SIZE,EVAL_NUM_STEP) with tf.Session() as sess: tf.global_variables_initializer().run() train_queue = reader.ptb_producer(train_data, train_model.batch_size, train_model.num_steps) eval_queue = reader.ptb_producer(valid_data, eval_model.batch_size, eval_model.num_steps) test_queue = reader.ptb_producer(test_data, eval_model.batch_size, eval_model.num_steps) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 使用训练数据训练模型 for i in range(NUM_EPOCH): print('In iteration: {}'.format(i+1)) # 在所有训练数据上训练循环神经网络模型 run_epoch(sess,train_model,train_queue,train_model.train_op,True,train_epoch_size) # 使用验证数据评测模型效果 valid_perplexity=run_epoch(sess,eval_model,eval_queue,tf.no_op(),False,valid_epoch_size) print('Epoch: {} Validation Perplexity: {}'.format(i+1,valid_perplexity)) # 最后使用测试数据测试模型效果 test_perplexity=run_epoch(sess,eval_model,test_queue,tf.no_op(),False,test_epoch_size) print('Test Perplexity: {}'.format(test_perplexity)) coord.request_stop() coord.join(threads) if __name__ == '__main__': tf.app.run()
语言模型评价标准:perplexity
语言模型效果好坏的常用评价指标是复杂度(perplexity)。perplexity值刻画的是通过某一个语言模型估计一句话出现的概率。比如$(w_{1},w_{2},...,w_{m})$表示语料库中的一句话,则语言模型预测这句话的概率越高越好,即perplexity值越小越好。公式表示如下:
$Perplexity(S)=p(w_{1},w_{2},...,w_{m})^frac{1}{m}=sqrt[m]{frac{1}{p(w_{1},w_{2},...,w_{m})}}=sqrt[m]{prod_{i=1}^{m}frac{1}{p(w_{i}|w_{1},w_{2},...w_{i-1})}}$
$p(w_{i}|w_{i-n+1},...w_{i-1})=frac{C(w_{i-n+1},...,w_{i-1},w_{i})}{C(w_{i-n+1},...,w_{i-1})}$
其中C(X)表示单词序列X在训练语料库中出现的次数。复杂度perplexity表示的概念其实是平均分支系数(average branch factor),即模型预测下一个词时的平均可选择数量。以0~9这10个数字为例组成一个长度为m的序列,由于10个数字是随机出现的,所以每个数字出现的概率为1/10。因此,在任意时刻,模型都有10个等概率的候选答案可以选择,于是perplexity就是10,即$Perplexity(S)=sqrt[m]{prod_{i=1}^{m} frac{1}{frac{1}{10}}}$
perplexity的另一种常用表示形式:$log(Perplexity(S))=frac{-sum p(w_{i}|w_{1},w_{2},...,w_{i-1})}{m}$,将乘积开根号的运算转换为加法运算,提高运算速度,同时可以避免概率为0时导致整个计算结果为0的问题。