- 高性能,指的是查询快
redis是c语言实现,与其他语言相比,在实现语言层面性能高;redis是内存数据库,而传统的关系型数据库是磁盘文件读写,所以redis读写快;单线程,无上下文切换损耗,也不需要线程间同步,在单核cpu上,性能高,如果服务器是多核cpu,可以开启多个进程的单线程redis实例;基于以上原因,才达到了官网所说的,即使pc都支持QPS>10w/s的查询。
- 高可用(High Availability),高可用指的是在节点故障时,服务仍然能正常运行或者进行降级后提供部分服务
单点redis:redis是内存数据库,在遇到断电或者重启时,数据能恢复吗?当然能。redis提供了两种持久化方式AOF/RDB,AOF是Append Of File,redis的修改命令(hset、set)会写入文件中,在恢复数据时,从头执行一遍命令就恢复了数据了,这种数据最全,但是恢复时间长。RDB是Redis DataBase,redis会定时备份数据,这是默认的持久化方式,但是因为是定时备份所有数据会有部分缺失。
master-slave(主从.复制):如果单点redis遇到故障怎么办?redis提供master-slave/sentinel/cluster高可用方案,master-slave是常见的复制(Replication) 方案,一个master,多个slave,就是俗称的主从复制,master用来接收请求,slave备份master数据,冗余了数据,但master-slave有个缺点,master 故障后,slave不会自动切换为master,必须人为干预,sentinel就是用来解决这个问题的
sentinel(哨兵):这种方案在master-slave的基础上,多了sentinel[ˈsentɪnl],sentinel汉语意思是哨兵,哨兵监测master及所有的slave状态(心跳),如果master故障,sentinel会组织slave选举新的master,并通知客户端,从而实现可用性,但是单master毕竟能力有限(查询最大10w/s),如果超过这个极限,怎么办?我们会想,如果有多个master就好了,这就是集群
- 高并发(redis cluster.集群)
redis集群有2个TCP 端口,一个用来伺服客户端,比如常见的6379,另外一个对6379+10000=16379,作为“high”端口,high端口用来节点间通信、失败监测、故障转移授权、配置更新,high端口与数据端口差值必须是固定的10000。redis集群对数据做了分片,redis数据分片没有采用一致性哈希(consistent hash),而是使用了hash slot,redis集群一共有16384(2的14次方)个槽,key对16384取模分配,比如A、B、C三个节点,
节点A 哈希槽( 0 ~ 5500)
节点 B 哈希槽(5501 ~ 11000)
节点 C哈希槽( 11001 ~ 16383)
增加节点D,那么就要将A、B、C的部分数据迁移到D上;如果删除A,那就要将A的数据迁移到B、C上,然后才能完全删除A。为了增加可用性,每个节点使用主从复制,比如A1、B1、C1,当B节点故障时,集群会将B1设置为新master,当B1也故障时,集群就真down了
replication(主从.复制)
如果业务要承载的QPS在几十万,单机是不可能做到的,此时就可以用到复制。做一个主从架构,一主多从,master节点负责写,slave节点负责读,假如说一个节点可以承载的5w读QPS,那么两个节点就可以承载10w的读QPS,水平扩容非常方便。

master节点挂太多slave节点会有性能问题,此时就可以在slave节点上挂slave节点
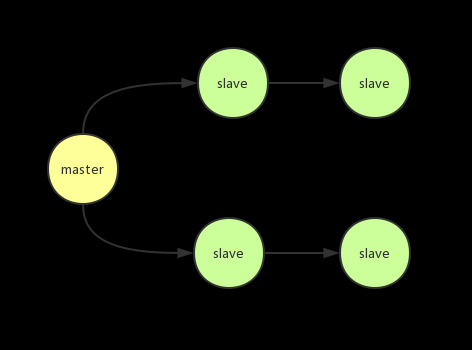
redis replication(主从复制)的核心机制有如下几点:
- redis采用异步方式复制数据到slave node,不会block master node的正常工作
- 一个master node可以配置多个slave node,slave node也可以连接其他的slave node
- slave node主要用来进行横向扩容,做读写分离,扩容的slave node可以提高读的吞吐量
主从复制原理:
- slave连接master,发送SYNC命令;
- master接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- master BGSAVE执行完后,向slave发送快照文件,并在发送期间继续记录被执行的写命令;
- slave收到快照文件后丢弃所有旧数据,载入收到的快照;
- master快照发送完毕后开始向salve发送缓冲区中的写命令;
- slave完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令(从服务器初始化完成)
- master每执行一个写命令就会向slave发送相同的写命令,slave接收并执行收到的写命令(从服务器初始化完成后的操作)
主从复制优缺点:
优点:
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离
- 为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成
- Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。
- Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
- Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据
缺点:
- Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
- Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
sentinel(哨兵)
主从架构有一个缺点就是如果master节点挂了,那么写服务是不可用的,因为slave节点默认是只读的,这时就重启master节点或者重新配置主从,有没有更好的方案呢?类似zookeeper的组件,能自动完成主从切换。在Redis中还真有,就是sentinel节点,当master节点发生故障能自动完成主从切换。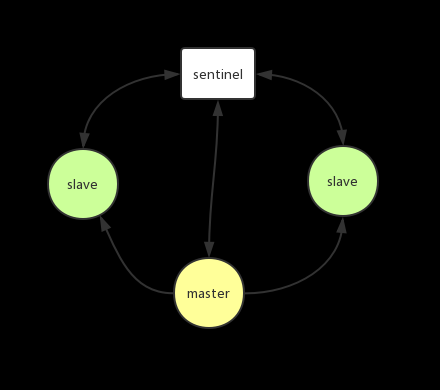
当master节点挂掉时,sentinel将一个slave节点变成maste节点,当原先的master节点可用时,以slave的角色加入集群。
一个高可用的系统是很忌讳有单点问题的。看到没,sentinel就是一个单点,如果sentinel挂了,主从切换也就没人做了。所以应该将sentinel也做成一个集群,其部署架构主要包括两部分:Redis Sentinel 集群和 Redis 数据集群。
其中 Redis Sentinel 集群是由若干 Sentinel 节点组成的分布式集群,可以实现故障发现、故障自动转移、配置中心和客户端通知。Redis Sentinel 的节点数量要满足 2n+1(n>=1)的奇数个。

哨兵的作用有如下几点
- 集群监控,负责监控redis master和slave进程是否正常工作
- 消息通知,如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
- 故障转移,如果master node挂掉了,会自动转移到slave node上
- 配置中心,客户端初始化时,通过哨兵获得master地址,如果故障转移发生了,通知客户端新的master地址
哨兵的工作方式:
- 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)
- 如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态
- 当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)
- 在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
- 当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
哨兵模式的优缺点
优点:
- 哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
- 主从可以自动切换,系统更健壮,可用性更高。
缺点:
- Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂
redis cluster(集群)
redis的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台redis服务器都存储相同的数据,很浪费内存,因为一个master节点并不能放海量数据,而且单个Redis的实例过大时,会导致rdb文件过大,当执行主从同步时时间过长,所以在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同的内容。
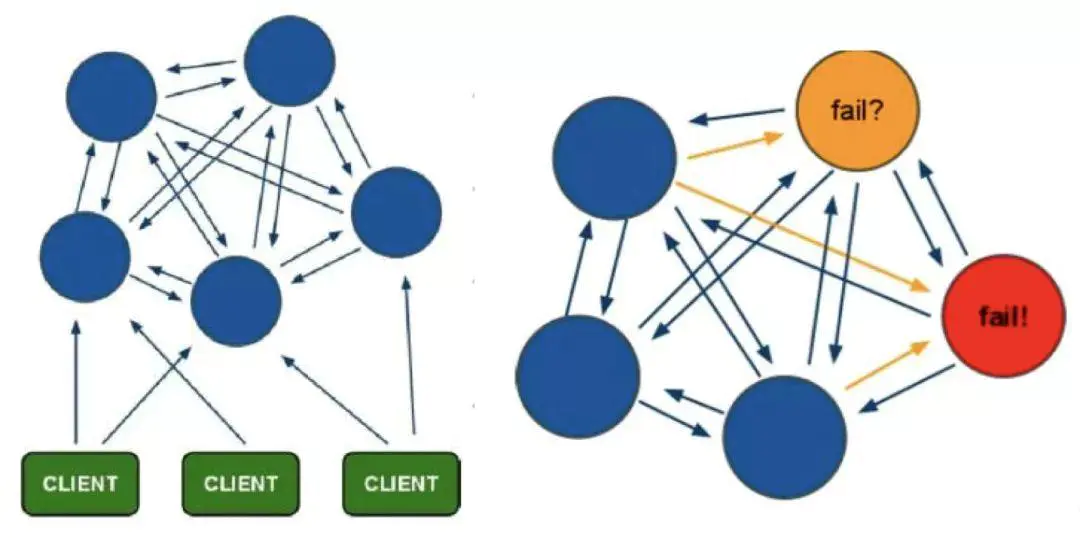
Redis-Cluster采用无中心结构,它的特点如下:
-
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
-
节点的fail是通过集群中超过半数的节点检测失效时才生效。
-
客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
工作方式:
在redis的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是cluster,可以理解为是一个集群管理的插件。当我们的存取的key到达的时候,redis会根据crc16的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
为了保证高可用,redis-cluster集群引入了主从模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点。当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点A1都宕机了,那么该集群就无法再提供服务了。
优点:
- 无中心架构;
- 数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布;
- 可扩展性:可线性扩展到 1000 多个节点,节点可动态添加或删除;
- 高可用性:部分节点不可用时,集群仍可用。通过增加 Slave 做 standby 数据副本,能够实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave 到 Master 的角色提升;
- 降低运维成本,提高系统的扩展性和可用性。
缺点:
- Client 实现复杂,驱动要求实现 Smart Client,缓存 slots mapping 信息并及时更新,提高了开发难度,客户端的不成熟影响业务的稳定性。目前仅 JedisCluster 相对成熟,异常处理部分还不完善,比如常见的“max redirect exception”。
- 节点会因为某些原因发生阻塞(阻塞时间大于 clutser-node-timeout),被判断下线,这种 failover 是没有必要的。
- 数据通过异步复制,不保证数据的强一致性。
- 多个业务使用同一套集群时,无法根据统计区分冷热数据,资源隔离性较差,容易出现相互影响的情况。
- Slave 在集群中充当“冷备”,不能缓解读压力,当然可以通过 SDK 的合理设计来提高 Slave 资源的利用率。
- Key 批量操作限制,如使用 mset、mget 目前只支持具有相同 slot 值的 Key 执行批量操作。对于映射为不同 slot 值的 Key 由于 Keys 不支持跨 slot 查询,所以执行 mset、mget、sunion 等操作支持不友好。
- Key 事务操作支持有限,只支持多 key 在同一节点上的事务操作,当多个 Key 分布于不同的节点上时无法使用事务功能。
- Key 作为数据分区的最小粒度,不能将一个很大的键值对象如 hash、list 等映射到不同的节点。
- 不支持多数据库空间,单机下的 redis 可以支持到 16 个数据库,集群模式下只能使用 1 个数据库空间,即 db 0。
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
- 避免产生 hot-key,导致主库节点成为系统的短板。
- 避免产生 big-key,导致网卡撑爆、慢查询等。
- 重试时间应该大于 cluster-node-time 时间。
- Redis Cluster 不建议使用 pipeline 和 multi-keys 操作,减少 max redirect 产生的场景。
1、客户端分片:这种方案将分片工作放在业务程序端,程序代码根据预先设置的路由规则,直接对多个Redis实例进行分布式访问。这样的好处是,不依赖于第三方分布式中间件,实现方法和代码都自己掌控,可随时调整,不用担心踩到坑。这实际上是一种静态分片技术。Redis实例的增减,都得手工调整分片程序。基于此分片机制的开源产品,现在仍不多见。这种分片机制的性能比代理式更好(少了一个中间分发环节)。但缺点是升级麻烦,对研发人员的个人依赖性强——需要有较强的程序开发能力做后盾。如果主力程序员离职,可能新的负责人,会选择重写一遍。所以,这种方式下,可运维性较差。出现故障,定位和解决都得研发和运维配合着解决,故障时间变长。因此这种方案,难以进行标准化运维,不太适合中小公司(除非有足够的DevOPS)。
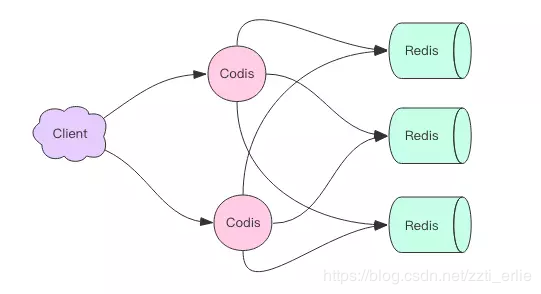
Twemproxy是一种代理分片机制,由Twitter开源。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis服务器,再原路返回。这个方案顺理成章地解决了单个Redis实例承载能力的问题。当然,Twemproxy本身也是单点,需要用Keepalived做高可用方案。这么些年来,Twemproxy是应用范围最广、稳定性最高、最久经考验的分布式中间件。只是,他还有诸多不方便之处。Twemproxy最大的痛点在于,无法平滑地扩容/缩容。这样增加了运维难度:业务量突增,需增加Redis服务器;业务量萎缩,需要减少Redis服务器。但对Twemproxy而言,基本上都很难操作。或者说,Twemproxy更加像服务器端静态sharding。有时为了规避业务量突增导致的扩容需求,甚至被迫新开一个基于Twemproxy的Redis集群。Twemproxy另一个痛点是,运维不友好,甚至没有控制面板。
Codis由豌豆荚于2014年11月开源,基于Go和C开发,是近期涌现的、国人开发的优秀开源软件之一。现已广泛用于豌豆荚的各种Redis业务场景,从各种压力测试来看,稳定性符合高效运维的要求。性能更是改善很多,最初比Twemproxy慢20%;现在比Twemproxy快近100%(条件:多实例,一般Value长度)。Codis具有可视化运维管理界面。Codis无疑是为解决Twemproxy缺点而出的新解决方案。因此综合方面会由于Twemproxy很多。目前也越来越多公司选择Codis。Codis引入了Group的概念,每个Group包括1个Redis Master及至少1个Redis Slave,这是和Twemproxy的区别之一。这样做的好处是,如果当前Master有问题,则运维人员可通过Dashboard“自助式”切换到Slave,而不需要小心翼翼地修改程序配置文件。为支持数据热迁移(Auto Rebalance),出品方修改了Redis Server源码,并称之为Codis Server。Codis采用预先分片(Pre-Sharding)机制,事先规定好了,分成1024个slots(也就是说,最多能支持后端1024个Codis Server),这些路由信息保存在ZooKeeper中。
Redis-cluster:
reids-cluster在redis3.0中推出,支持Redis分布式集群部署模式。采用无中心分布式架构。所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.节点的fail是通过集群中超过半数的节点检测失效时才生效.客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可,减少了代理层,大大提高了性能。redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->key之间的关系。目前Jedis已经支持Redis-cluster。从计算架构或者性能方面无疑Redis-cluster是最佳的选择方案。