2018-12-09 19:07:29
深层的深度学习网络存在梯度消失和梯度爆炸等问题导致难以进行训练。
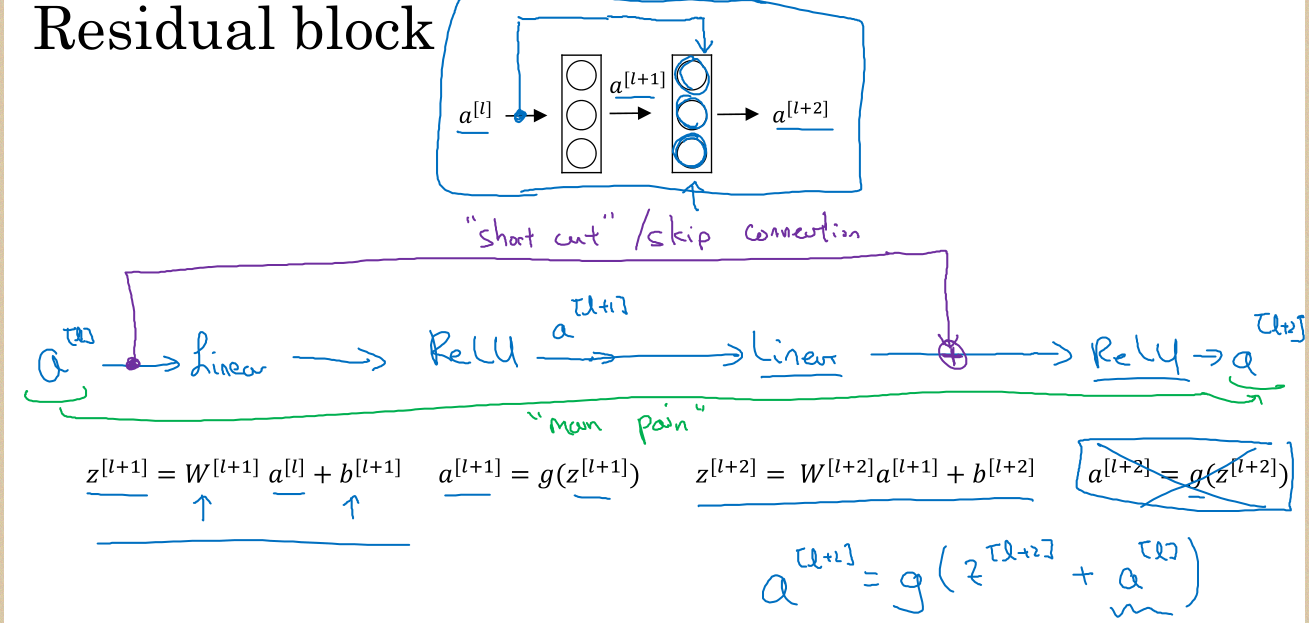
ResNet提出了Skip-Connection来将某一层的输入直接传递到更深的层,通过这种方式可以训练得到更深的神经网络。
为什么这个是有效的呢?
理论上,更深的模型的训练误差不应当大于浅层模型,但是出现的退化问题,这表明很难去利用多层网络拟合同等函数。但是,残差的表示形式使得多层网络近似起来要容易的多,如果同等函数可被优化近似,那么多层网络的权重就会简单地逼近0来实现同等映射,即F(x) = 0。
简言之,通过Skip-Connection可以使网络更容易的学习到恒等变换,这样整个网络的性能至少不会因为深度的加深而下降,并且更多的时候能够提高整个模型的性能。
Residual block:

如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那现在要解决的就是学习恒等映射函数了。 但是直接让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x) = F(x) + x,如下图。我们可以转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。