重现基线模型
基线模型原理
我们选用的的模型为DeepCS,接下来我将解释一下它的原理。
我们要进行代码搜索,其实就是希望寻找一个代码片段(code snoppets)和它的自然语言描述(description)的一个对应关系,然而,由于编程语言和自然语言间存在的差异,如果仅仅依靠文本内容的相似性,很容易出现误匹配。我们就需要在另一个空间去寻找一种表征,或者说寻找一种或多种映射,让对应的代码片段和自然语言描述通过各自的映射,在新的空间足够的相似,这样也就能很方便的去根据相似性去搜索代码。
所以论文中提出了CODEnn模型(Code-Description Embedding Neural Network),所谓的embedding通俗来讲,就是用向量来表示一种实体(单词、图像等等),使得相似的物体在embedding的向量空间也足够相似(如余弦相似性)。如下图,由于代码和自然语言描述是两种不同的东西,我们也采用了两个不同的网络来分别进行embedding,使得语义对应的代码和描述在向量空间足够接近,而语义不同的代码和描述在向量空间则没有那么近。
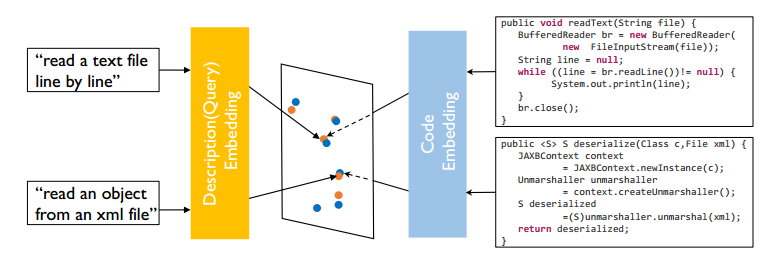
由于代码语言和自然语言都存在序列性,一句话前后的单词构成了一个序列,适合采用循环神经网络(RNN)来进行embedding,具体RNN方面的知识这里也就不详细介绍了,我们对各个时刻的隐藏层状态做一个最大值池化,来作为最终embedding的结果,它下面是CODEnn的一个整体结构图。

对于代码,我们不是直接采用源代码,而是从中提取三部分,分别是方法的名字(采用驼峰法分解)、API的调用序列(代码中调用的各种函数接口)、源代码中的token(通俗的理解指不可分的最小符号,如一个一个单词,采用驼峰法分解)。对于描述,训练时我们通常采用文档描述的第一句话。下面是分解提取的一个例子。

代码的三部分分别进行embedding(token部分无序列性,直接采用MLP,其余采用RNN),再通过一个全连接层将它们融合起来,作为最后的向量表示,而描述部分也进行embedding,然后采用余弦相似性来比较二者的相似程度。在训练的过程中,每个代码C都有一个正描述D+和负描述D-(D-从所有代码描述中随机选择),通过构造损失函数$cal{L}( heta) $,使得C和D+尽可能相似,而C和D-尽可能不同。
训练好网络进行搜索时,整个模型的工作流如下图。
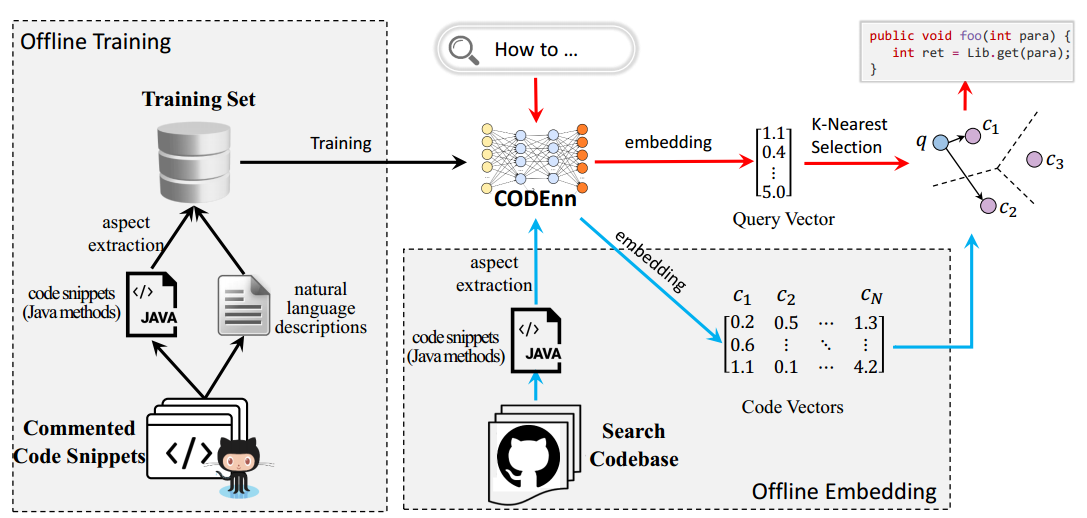
搜索的代码库(search codebase)可以是用户自己定义的,代码库中的代码通过CoNN生成向量库,搜索时输入的查询语句通过DeNN也生成一个向量,再和所有的代码向量计算余弦相似性,选择相似性排前K的代码作为结果返回,完成搜索过程。
模型的优缺点
优点:
- 可以理解查询语句的语义信息,而不是只是通过其中的关键词去比较。比如可以区分 "queue an event to be run on the thread" 和"run an event on a thread queue",这两句话中的关键词几乎一样,但是意思却完全不一样。
- 搜索结果更鲁棒,不容易受不相关或者不重要的关键词影响。比如"get the content of an input stream as a string using a specified character encoding",不太重要的关键词就有specified和character等,而DeepCS可以识别出那些是最重要的关键词。
- 它搜索的范围更大,不仅仅会返回关键词比较匹配的结果,也会返回关键词不是那么匹配但是语义相关的结果,也为查询的用户提供了更多可以参考的代码。
缺点:
- 它的一个缺点是有时一些相关性不是那么高的代码反而会排在准确的代码的前面,这可能是因为模型返回结果完全是按照向量的相似性来排序的,然后向量的表示能力也与训练时选择的方式有很大关系,这些也是可以改进的地方。
模型重现结果
首先放上参考的结果( lr=1e-3, epoch=800)。
| dataset | acc@top 5 | acc@10 |
|---|---|---|
| validation set(pool=200) | 0.806875 | 0.884375 |
| validation set(pool=800) | 0.621563 | 0.726250 |
| test set(pool=200) | 0.780667 | 0.860333 |
| test set(pool=800) | 0.596250 | 0.711250 |
由于时间等多方面的原因,我们未能完整的训练完800个epoch,但我们在训练的过程中发现,210个epoch后,测试的acc就开始成下降趋势(如下图),可能出现了过拟合,表现最好的测试结果如表格(210个epoch)。
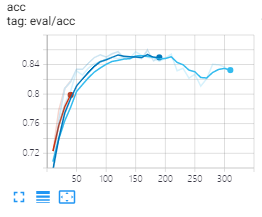
训练过程acc
| dataset | acc@top 5 | acc@10 |
|---|---|---|
| validation set(pool=200) | 0.763946 | 0.854014 |
| validation set(pool=800) | 0.560868 | 0.674792 |
| test set(pool=200) | 0.762517 | 0.853707 |
| test set(pool=800) | 0.557396 | 0.672014 |
由于训练的epoch不一样,也不便于直接比较,但可以看出,模型还是比较有效的。复现的一个难度主要还是时间问题,训练需要的时间太长了。
提出改进
改进动机
-
考虑模型的主要缺点,即有时一些相关性不是那么高的代码反而会排在准确的代码的前面,说明模型embedding的结果不是那么鲁棒,有时原本不是那么相关的代码和描述,经过embedidng后在向量空间却相似了。一个可能的原因是训练的时候,缺少了相关的样本,所以模型没有学习到这一点。模型训练时,采用的时三元组,即(代码C,正描述D+,负描述D-),而代码中D-时随机采样得到的,因此可以考虑在构造三元组时,选择D-可以更有针对性一点,如果这一点比较难做到,也可以一个选更多不同的D-来构成一个多元组(当然Loss的表达式形式也要适当的调整)。
-
同样考虑上一点,原模型中采用的是余弦相似度来衡量相似性,可能可以尝试其他的衡量方式,如欧氏距离、曼哈顿距离等。
-
模型结构方面,首先是每个网络可以优化,如RNN、MLP的具体结构等,如代码中对于token集,其实并没有经过MLP,只是embedding后直接进行了dropout和pooling操作,这部分也可以改进。
-
另一方面我们的训练样本代码部分是提取了三部分(方法的名字、API的调用序列、源代码中的token),可能对源代码的表示能力不够,也可以在数据处理上思考更合理的方式,如token现在不考虑顺序以及相互之间的关系,可以把这个也考虑进去。
新模型框架
以上改进并没有对原来的模型框架进行大幅度的调整,只是在具体的一些细节上提出了一些可能有效的改进,因此也就没有重新画一个结构图了。
评价合作伙伴
其实这次结对作业主要的贡献还是在他,我十一回家了,跑代码也不太方便,所以实验完全是由他在跑,我只是后来提出了一些改进建议,不过由于时间等问题,我们也没法具体实现了。总之,我的合作伙伴是非常靠谱的,之前也曾经多次合作过。至于可以改进的地方,其实应该是我们都可以改进的地方,就是不要太拖延吧,如果我们可以早一些开始工作,这次作业应该可以完成度更高一些。