今天开始将自己所学过的MySQL的知识都尝试融会贯通,并且用写博客的方式记录分享下来。
今天讲的主题是MySQL的组织架构,对于学习一个中间件或者开源项目而言,我觉得最重要的便是先知晓其组织架构,以一个全局的姿态去观察架构之后,再有选择性的深入到细节,才能够学的快且有收获。
MySQL的架构图
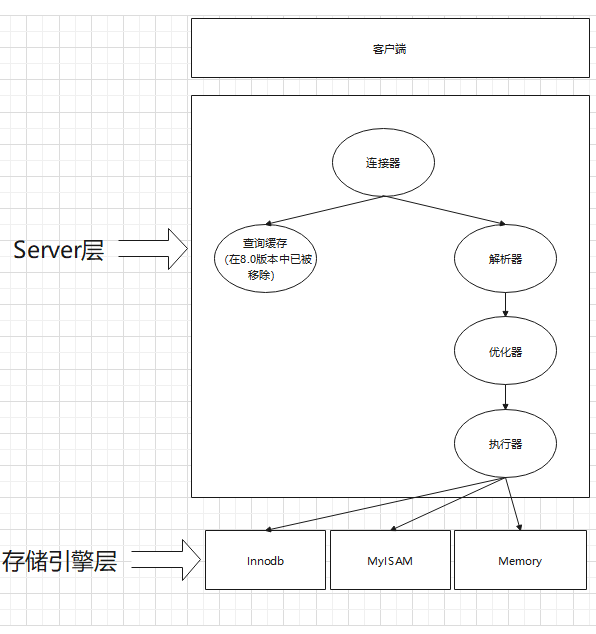
根据图可以观察到,MySQL主要是分为Server层与存储引擎层两大块;而客户端的含义非常广泛,理论上只要可以连接到MySQL,就能够算上是一个客户端;我们主要讨论MySQL架构中的Server层与存储引擎层。
Server层
Server层可以看做是将MySQL的共性操作,也就是所有跨存储引擎的操作都放到了这一层进行实现,比如查询、解析、优化、缓存以及所有的内置函数、存储过程、视图、触发器。
连接器的作用主要是判断用户是否可以利用某个账号登录MySQL,其中比较有意思的一点是一旦利用某个账号登录上去MySQL之后,它本次连接的权限便固定了,如果要让修改权限操作生效,那么便需要将本次连接重新连接,这样才会是新的权限。
查询缓存的作用是便是缓存一些热点查询的结果集,然后直接返回。它有很多很多的缺陷,它的实现是利用一个哈希表,将SQL语句的hash对应结果集。
查询缓存的缺陷很明显,主要为两个地方:
- 映射的Key是SQL语句的hash值,只要与key的查询有任何不一致的地方,都会查询缓存失败。
- 一旦进行更新,会直接清空缓存表。
这个功能太过于鸡肋,所以直接在8.0中去除,后续也不会再提及。
解析器的作用是解析SQL语句,利用词法分析、语法分析检查SQL语句是否存在语法错误的情况。
优化器的作用便是对SQL语句进行优化,比如索引的选取,连接的顺序等,具体的如何优化在后续的篇章里会介绍;
执行器的作用是生成执行计划,然后调用存储引擎的接口,进行数据的操作。
以上便是Server层的大致内容,总的来说,Server层便是由连接、解析、优化、执行四个部分组成,MySQL的架构将解析与获取数据拆开,也为后续的一些特性的实现提供了基础。
存储引擎层
存储引擎层的操作主要负责的是数据的存储与读取,不同的存储引擎有不同的特性,现在应用最多的存储引擎是Innodb,现在已经是MySQL的默认存储引擎;而在早起的版本中,MySQL的默认存储引擎为MyISAM,后期我们也会有关于这两个存储引擎的比较。
我们所熟知的事务、行锁、多版本并发控制、事务日志都是由存储引擎层实现的,而上述的这些内容,Innodb存储引擎是都支持的,所以MySQL官方后续将其设立为了默认引擎。
存储引擎它底层由数十个底层函数,而Server层是执行器利用组合这些函数来达到读取数据的能力,我比较喜欢把这个过程称为“乐高积木”。
总结
MySQL的基础架构为其后续的细节实现提供了基础,Server层的内容我们后续比较重要的内容是优化器如何进行优化;存储引擎层的内容,我们主要学习Innodb的特性以及在某些条件下,使用其他存储引擎的便利性。
MySQL的成功,与其基础架构具有很大的关联性,在Oracle霸占市场的年代,凭借复制所扩展出来的横向扩展功能让其在数据库市场下独占一角;后续又通过Innodb的出现,优化补充了很多老版本所出现的问题。所以希望各位读者能够根据自己之前的所学,结合这篇文章,对于MySQL的基础架构能够有新的认识。