爬虫目的
使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据
爬虫工具
使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文档对象,并提取职位信息。
爬取过程
1.请求地址
https://www.lagou.com/zhaopin/Python/
2.需要爬取的内容
(1)岗位名称
(2)薪资
(3)公司所在地
3.查看html
使用FireFox浏览器,登陆拉勾网,按F12可以进入开发者工具页面:
这时候会看到该页面的html网页源码。
接下来需要寻找岗位信息对应的源码,比如岗位名称:

在开发者工具页面左上角有个箭头标志,点击它,然后再点击岗位名称,就能看到对应的源码。
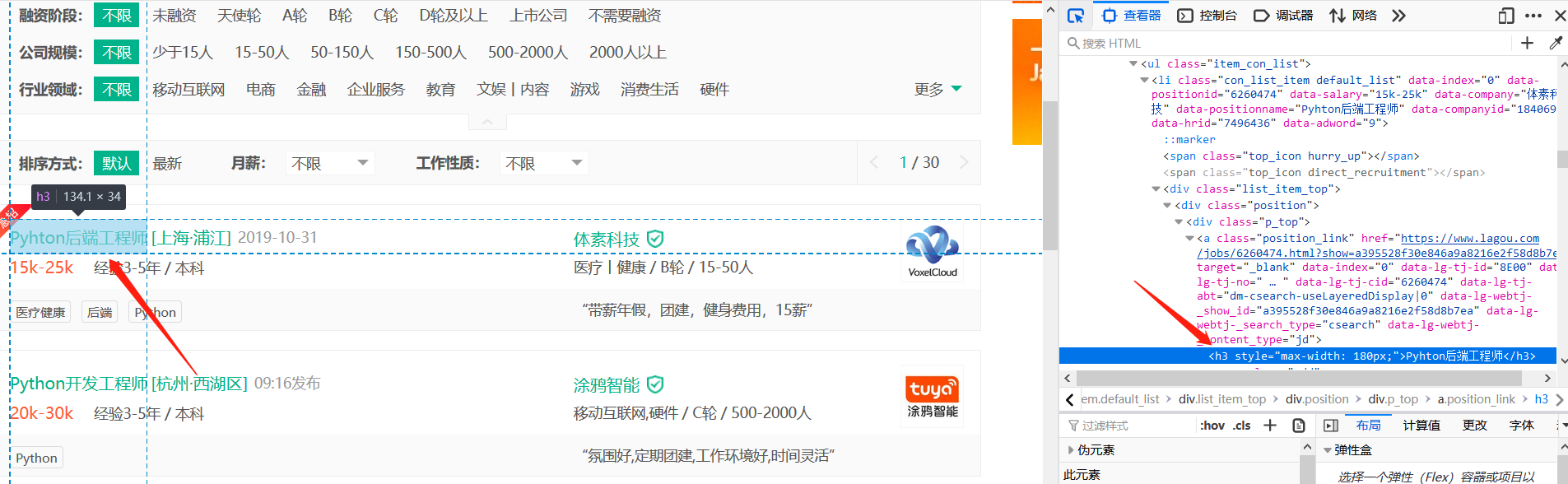
知道对应的源码后,还需要知道请求头:
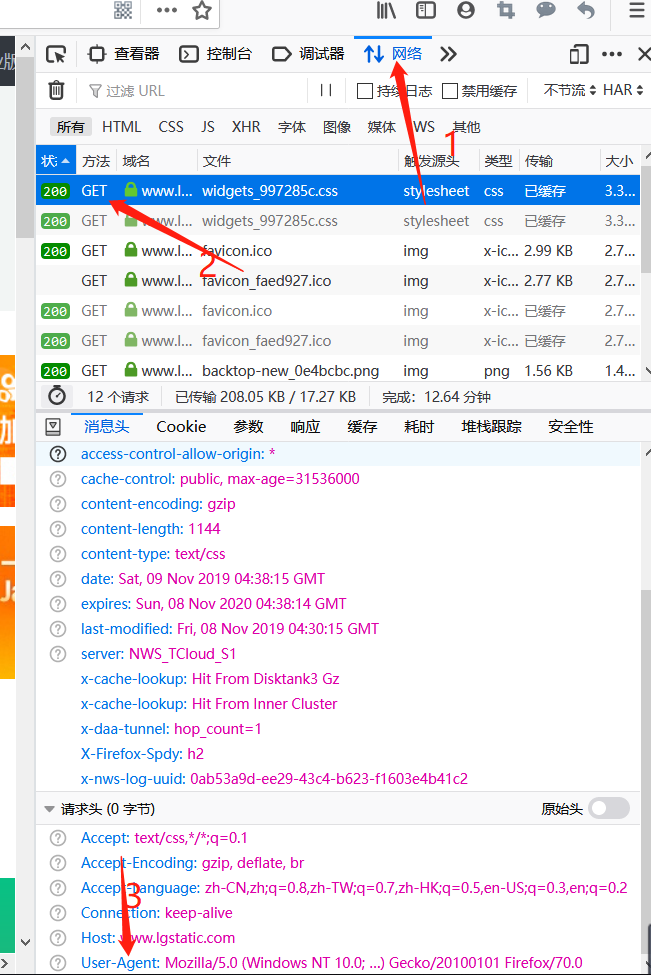
点击“网络”,之后点击“get”,在最下方User-Agent中的内容就是请求头
(如果是使用Chrome浏览器或者其它浏览器方法会有所不同)
完成上述操作后就可以利用BeautifulSoup4提取里面的文本。
利用requests发出数据请求
import requests import io import sys from bs4 import BeautifulSoup sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36',} r = requests.get('https://www.lagou.com/zhaopin/Python/',headers=headers) #设置请求头 r.encoding=r.apparent_encoding result=r.text bs=BeautifulSoup(result,'html.parser') #创建一个BeautifulSoup对象
利用BeautifulSoup提取网页数据
b=[] #创建空列表用来存储爬取的数据 a=[] d=[] name = bs.find_all('h3') #获取所有包含'h3'标签的内容
’ for h3 in name: b.append(h3.string) money = bs.find_all('span',attrs={'class':'money'}) for span in money: a.append(span.string) #获取字符串形式的数据 ltd=bs.find_all('em') for em in ltd: d.append(em.string) i=0 print("职业:"," 薪资:"," 地点:") try: while True: print(b[i],a[i],d[i]) i+=1 except IndexError: print()