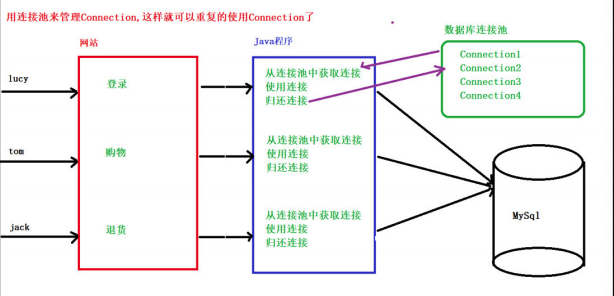
一、连接池
1、连接池介绍
连接池就是为了解决在开发中 『获取连接』或者『释放连接』这两个非常消耗系统资源的两个性能问题,通常
我们采用连接池技术来共享连接Coneection,这样我们就不需要每次都创建连接、释放连接,把这些操作都交给连接池
连接池的好处
因为使用池来管理Connection数据库连接对象,这样可以重复使用Connection,当使用完Connection后,调用
Connection 的close()方法也『不是正真的关闭』Connection,而是把Connection『归还』给池。
2、JDBC方式与连接池方式

3、如何使用数据库连接池
Java为数据库连接池提供了公共的接口:javax.sql.DataSource,各个厂商只需要让自己的连接池去
实现这个接口就好了,这样应用程序可以方便的切换不同厂商的连接池,常用的连接池有:
DBCP连接池,C3P0连接池,Druid连接池
二、连接池使用:
数据准备
create database db5 CHARACTER set utf8;
use db5;
create table employee(
eid int PRIMARY key auto_INCREMENT,
ename varchar(20),
age int,
sex VARCHAR(6),
salary double ,
empdate Date
);#插入数据
INSERT INTO employee (eid, ename, age, sex, salary, empdate) VALUES(NULL,'李清照',22,'女',4000,'2018-11-12');
INSERT INTO employee (eid, ename, age, sex, salary, empdate) VALUES(NULL,'林黛玉',20,'女',5000,'2019-03-14');
INSERT INTO employee (eid, ename, age, sex, salary, empdate) VALUES(NULL,'杜甫',40,'男',6000,'2020-01-01');
INSERT INTO employee (eid, ename, age, sex, salary, empdate) VALUES(null,'李白',25,'男',3000,'2017-10-01');
1、DBCP连接池
DBCP也是一个开源的连接池,是Apache成员之一,在企业开发中也比较常见,同时也是『tomcat内置的』连接池。
1) 首先需要将创建项目并导入对应的jar包并将jar包导入到项目的依赖中:
commons-dbcp-1.4.jar commons-pool-1.5.6.jar
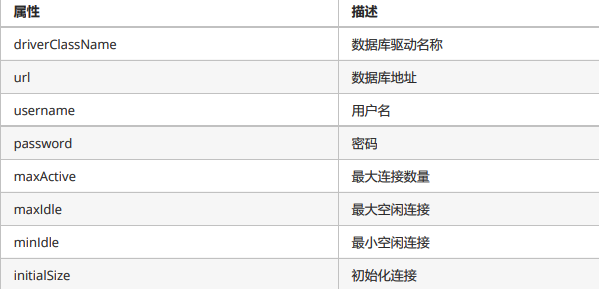
2)常见配置项:
3)编写工具类和案例:
连接数据表的工具类采用DBCP连接池的方式来完成:
- JAVA中提供了一个连接池的规则结构: DataSource ,它是java中提供的连接池
- 在DBCP包中提供了DataSource接口的实现类,我们要用的具体的连接池『 BasicDataSource 』 类
public class DBCPUtils {
//1.定义常量 保存数据库连接的相关信息
public static final String DRIVERNAME = "com.mysql.jdbc.Driver";
public static final String URL = "jdbc:mysql://localhost:3306/db5?characterEncoding=UTF-8";
public static final String USERNAME = "root";
public static final String PASSWORD = "root";
//2.创建连接池对象(由DBCP提供的实现类)
public static BasicDataSource dataSource = new BasicDataSource();
//3.使用静态代码块进行配置
static{
dataSource.setDriverClassName(DRIVERNAME);
dataSource.setUrl(URL);
dataSource.setUsername(USERNAME);
dataSource.setPassword(PASSWORD);
}
//4.获取连接的方法
public static Connection getConnection() throws Exception{
//从连接池中获取连接
Connection connection = dataSource.getConnection();
return connection;
}
//5.释放资源的方法
public static void close(Connection con, Statement statement){
if(statement != null){
try {
statement.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(con != null){
try {
//归还连接哦,不是关闭连接
con.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
public static void close(Connection con, Statement statement, ResultSet resultSet){
if(resultSet != null){
try {
resultSet.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
close(con,statement);
}
}
测试工具类:要求查询所有员工的姓名
public class TestDBCP {
/*
测试DBCP连接池
*/
public static void main(String[] args) throws Exception{
//1.从DBCP连接池中拿到连接
Connection connection = DBCPUtils.getConnection();
//2.获取Statement对象
Statement statement = connection.createStatement();
//3.查询所有员工的姓名
String sql = "select ename from employee";
ResultSet resultSet = statement.executeQuery(sql);
//4.处理结果集
while(resultSet.next()){
String ename = resultSet.getString("ename");
System.out.println("员工姓名:" + ename);
}
//5.释放资源
DBCPUtils.close(connection,statement,resultSet);
}
}
2、C3PO连接池
c3p0是一个开源的JDBC连接池,支持JDBC3规范喝JDBC2的标准扩展,目前使用它的开源项目有Hibernate、 Spring等
1)导入jar包及其配置文件
jar包:c3p0-0.9.5.2.jar mchange-commons-java-0.2.12.jar
配置文件:c3p0-config.xml 注意:该配置文件名不能更改、直接放到src下也可以放到资源文件夹中
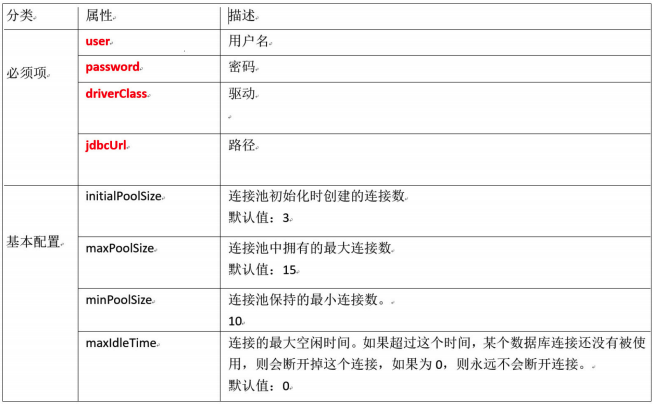
该配置文件常见的配置:
<c3p0-config>
<!--默认配置-->
<default-config>
<!-- initialPoolSize:初始化时获取三个连接,
取值应在minPoolSize与maxPoolSize之间。 -->
<property name="initialPoolSize">3</property>
<!-- maxIdleTime:最大空闲时间,60秒内未使用则连接被丢弃。若为0则永不丢弃。-->
<property name="maxIdleTime">60</property>
<!-- maxPoolSize:连接池中保留的最大连接数 -->
<property name="maxPoolSize">100</property>
<!-- minPoolSize: 连接池中保留的最小连接数 -->
<property name="minPoolSize">10</property>
</default-config>
<!--配置连接池mysql-->
<named-config name="mysql">
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/db5?characterEncoding=UTF-8</property>
<property name="user">root</property>
<property name="password">root</property>
<property name="initialPoolSize">10</property>
<property name="maxIdleTime">30</property>
<property name="maxPoolSize">100</property>
<property name="minPoolSize">10</property>
</named-config>
<!--配置连接池2,可以配置多个-->
</c3p0-config>
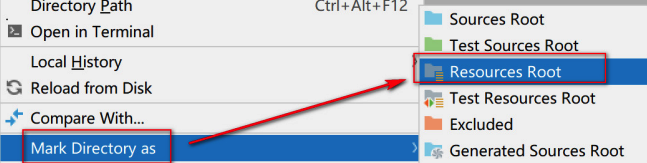
2)在项目下创建一个resource文件夹专门存放资源文件

3)选择文件夹,右键 将resource文件夹指定为资源文件夹,将文件放在resource目录下即可,
创建连接池对象的时候会去加载这个配置文件
4)编写C3P0工具类
- 『C3P0提供的核心工具类, ComboPooledDataSource , 如果想使用连接池,就必须创建该类的对象』
- new ComboPooledDataSource(); 使用 默认配置
new ComboPooledDataSource("mysql"); 使用命名配置
public class C3P0Utils {
//1.创建连接池对象 C3P0对DataSource接口的实现类
//使用的配置是 配置文件中的默认配置
//public static ComboPooledDataSource dataSource = new ComboPooledDataSource();}
//使用指定的配置
public static ComboPooledDataSource dataSource = new ComboPooledDataSource("mysql");
//获取连接的方法
public static Connection getConnection() throws Exception{
return dataSource.getConnection();
}
//释放资源
public static void close(Connection con, Statement statement){
if(statement != null){
try {
statement.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(con != null){
try {
con.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
public static void close(Connection con, Statement statement, ResultSet resultSet){
if(resultSet != null){
try {
resultSet.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
close(con,statement);
}
}
测试工具类
public class TestC3P0 {
//需求 查询姓名为李白的记录
public static void main(String[] args) throws Exception{
//1.获取连接
Connection connection = C3P0Utils.getConnection();
//2.获取预处理对象
String sql = "select * from employee where ename = ?";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//3.设置占位符的值
preparedStatement.setString(1,"李白");
ResultSet resultSet = preparedStatement.executeQuery();
//4.处理结果集
while(resultSet.next()) {
int eid = resultSet.getInt("eid");
String ename = resultSet.getString("ename");
int age = resultSet.getInt("age");
String sex = resultSet.getString("sex");
double salary = resultSet.getDouble("salary");
Date date = resultSet.getDate("empdate");
System.out.println(eid + " " + ename + " " + age + " " + sex + " " + salary + " " + date);
}
//5.释放资源
C3P0Utils.close(connection,preparedStatement,resultSet);
}
}
3、Druid连接池
Druid(德鲁伊)是阿里巴巴开发的号称为监控而生的数据库连接池,Druid是目前最好的数据库连接池。
在功能、性能、扩展性方面,都超过其他数据库连接池,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况。
1)导入jar包及其配置文件
jar包:druid-1.0.9.jar
导入配置文件: 是 properties形式的
可以叫做任意名称,可以放在任意目录下,我们统一放到resources资源目录
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://127.0.0.1:3306/db5?characterEncoding=UTF-8
username=root
password=root
initialSize=5
maxActive=10
maxWait=3000
2)编写Druid工具类
- 获取数据库连接池对象
通过工厂来来获取 DruidDataSourceFactory类的createDataSource方法
createDataSource(Properties p) 方法参数可以是一个属性集对象
public class DruidUtils {
//1. 定义Java为数据库连接池提供了公共的接口 dataSource
public static DataSource dataSource;
//2. 静态代码块
static{
try{
//3.创建属性集对象
Properties properties = new Properties();
//4.加载配置文件 Druid 连接池不能够主动加载配置文件,需要指定文件
InputStream inputStream = DruidUtils.class.getClassLoader().getResourceAsStream("druid.properties");
//5.使用Properties对象的load方法 从字节流中读取配置信息
properties.load(inputStream);
//6.通过工程类获取连接池对象
dataSource = DruidDataSourceFactory.createDataSource(properties);
}catch (Exception e){
e.printStackTrace();
}
}
//3.获取连接的方法
public static Connection getConnection(){
try {
return dataSource.getConnection();
} catch (SQLException throwables) {
throwables.printStackTrace();
return null;
}
}
//4.获取Druid连接池对象的方法
public static DataSource getDataSource(){
return dataSource;
}
//5.释放资源
//释放资源
public static void close(Connection con, Statement statement){
if(statement != null){
try {
statement.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(con != null){
try {
con.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
public static void close(Connection con, Statement statement, ResultSet resultSet){
if(resultSet != null){
try {
resultSet.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
close(con,statement);
}
}
测试案例
public class TestDruid {
//要求查询 薪资在3000-5000之间的员工姓名
public static void main(String[] args) throws SQLException {
//1.获取连接
Connection connection = DruidUtils.getConnection();
//2.获取Statement对象
Statement statement = connection.createStatement();
//3.执行查询
ResultSet resultSet = statement.executeQuery("select ename from employee where salary between 3000 and 5000");
//4.处理结果集
while(resultSet.next()){
String ename = resultSet.getString("ename");
System.out.println(ename);
}
//5.释放资源
DruidUtils.close(connection,statement,resultSet);
}
}
三、DBUtils工具类
1、DBUtils简介
使用JDBC我们发现冗余的代码太多了,为了简化开发 我们选择使用 DbUtils Commons
DbUtils是Apache组织提供的一个对JDBC进行简单封装的开源工具类库,使用它能够简化
JDBC应用程 序的开发,同时也不会影响程序的性能
使用方式:
DBUtils就是JDBC的简化开发工具包。需要项目导入commons-dbutils-1.6.jar。
2、dbutils核心功能的介绍
1.QueryRunner中提供对sql语句操作的api
2.ResultSetHandler接口,用于定义select操作后,怎样封装结果集
3.DbUtils类,他就是一个工具类,定义了关闭资源和事务处理相关的方法
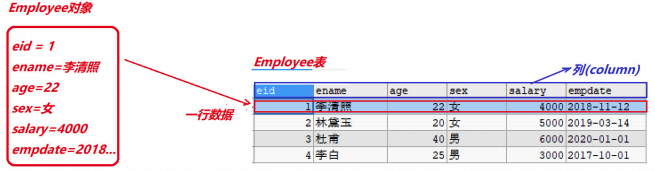
3、扩展:表与类之间的关系
- 整个表可以看做是一个类
- 表中的一行记录对应类的实例(对象)
- 表中的一列,对应类中的一个成员属性
3.1、JavaBean
1) JavaBean其实就是一个类,开发中常用于封装数据,有以下特点
- 需要实现 序列化接口,Serializable
- 提供私有字段:private 类型 变量
- 提供 getter 和 setter 方法
- 提供 空参构造
2) 创建一个entity包专门用来存放对应的javaBean类,我们创建的JavaBean类一般需要和数据库表名对应
public class Employee implements Serializable {
private int eid;
private String ename;
private int age;
private String sex;
private double salary;
private Date empdate;
public Employee(){}
public Employee(int eid,String ename,int age,String sex,double salary,Date empdate){
this.eid = eid;
this.ename = ename;
this.age = age;
this.sex = sex;
this.salary = salary;
this.empdate = empdate;
}
// get set 省略
}
3) 使用DBUtils 完成CRUD
QueryRunner 核心类:
构造方法:
QueryRunner()
QueryRunner(DataSource ds) ,提供数据源(连接池),DBUtils底层自动维护连接connection
常用方法:
update(Connection conn, String sql, Object... params) ,用来完成表数据的增加、删除、更新操 作
Connection conn: 数据库连接对象,自动模式创建QueryRun 可以不传,手动模式必须传递
因为我们在创建QueryRunner对象自动模式的时候已经已经将连接池传入
过去了,我们连接的维护已经交给连接池去维护了
String sql : 占位符形式的SQL,使用?号占位符
Object... param: Object类型的可变参数,用来设置占位符上的参数
query(Connection conn, String sql, ResultSetHandler rsh, Object... params) ,用来完成表 数据的查询操作
4)QueryRunner的创建
- 手动模式:QueryRunner qr = new QueryRunner();
- 自动模式:QueryRunner qr2 = new QueryRunner(DruidUtils.getDataSource());
- 自动模式需要传入连接池对象:我们需要有一个连接池工具类,然后将对应的连接池数据源返回
public static DataSource getDataSource(){
return dataSource;
}
5)QueryRunner实现增、删、改操作:
- update(Connection conn, String sql, Object... params) 方法
步骤:
1、创建QueryRunner(手动或者自动)
2、占位符方式编写SQL
3、设置占位符参数
4、执行
/**
* 使用QueryRunner的update()方法 实现增、删、改操作
*/
public class DBUtilsDemo2 {
// 添加操作
@Test
public void testInsert() throws Exception{
//1. 创建 QueryRunner 手动模式创建
QueryRunner qr = new QueryRunner();
//2. 编写占位符方式 SQL
String sql = "insert into employee values(?,?,?,?,?,?)";
//3.设置占位符的参数
Object[] param = {null,"张百万",20,"女",10000,"1990-12-26"};
//4.执行update方法
Connection connection = DruidUtils.getConnection();
/* 注意 connection数据库连接对象在自动创建可以省略,手动则必须写 */
int i = qr.update(connection,sql,param);
//5.释放资源DbUtils.closeQuietly(connection);
}
//修改操作
@Test
public void testUpdate() throws Exception{
//1.创建QueryRunner对象 自动模式,传入数据库连接池
QueryRunner qr = new QueryRunner(DruidUtils.getDataSource());
//2.编写SQL
String sql = "update employee set salary = ? where ename = ?";
//3.设置占位符参数
Object[] param = {0,"张百万"};
//4.执行update,不需要传入连接对象,连接的维护已经交给数据库连接池去维护了
qr.update(sql,param);
}
//删除操作
@Test
public void testDelete() throws SQLException{
QueryRunner qr = new QueryRunner(DruidUtils.getDataSource());
String sql = "delete from employee where eid = ?";
//只有一个参数,不需要创建数组
qr.update(sql,1);
}
}
6)QueryRunner实现查询操作:
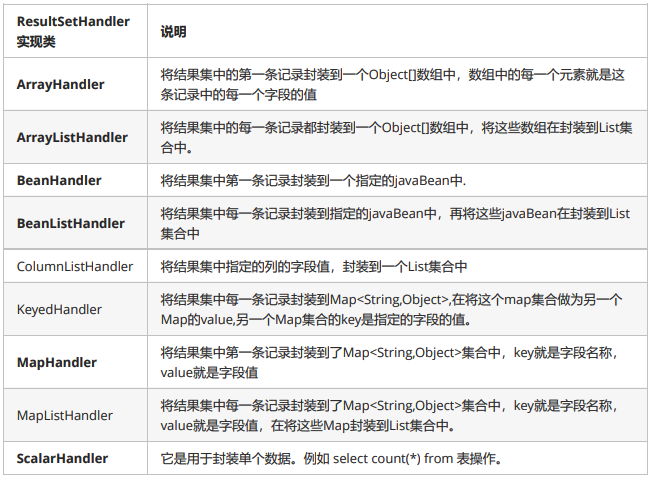
- ResultSetHandler可以对查询出来的ResultSet结果集进行处理,达到一些业务上的需求。
- 下面是使用ResultSetHandler接口几个常用实现类实现数据库的增删改查的案例
每一种实现类都代表了对查询结果集的一种处理方式
- ResultSetHandler常用实现类测试
QueryRunner的查询方法:
query方法的返回值都是泛型,具体的返回值类型会跟进结果集的处理方式发生变化

- 创建一个测试类, 对ResultSetHandler接口的几个常见实现类进行测试
查询id为5的记录,封装到数组中
查询所有数据,封装到List集合中
查询id为5的记录,封装到指定JavaBean中
查询薪资大于 3000 的所员工信息,封装到JavaBean中再封装到List集合中
查询姓名是 张百万的员工信息,将结果封装到Map集合中
查询所有员工的薪资总额
/**
* QueryRunner实现查询操作
*/
public class DBUtilsDemo03 {
/**
* 查询id为5的记录,封装到数组中
* ArrayHandler 将结果集的第一条数据封装到数组中
*/
@Test
public void testFindById() throws SQLException{
//1.创建QueryRunner
QueryRunner queryRunner = new QueryRunner(DruidUtils.getDataSource());
//2.编写SQL
String sql = "select * from employee where eid = ?";
//3.执行查询
Object[] query = queryRunner.query(sql, new ArrayHandler(), 5);
//4.获取数据
System.out.println(Arrays.toString(query));
}
/**
* 查询所有数据,封装到List集合中
* ArrayListHandler可以将每条数据先封装到数组中, 再将数组封装到集合中
*/
@Test
public void testFindAll() throws Exception {
//1.创建QueryRunner
QueryRunner qr = new QueryRunner(DruidUtils.getDataSource());
//2.编写SQL
String sql = "select * from employee";
//3.执行查询
List<Object[]> query = qr.query(sql, new ArrayListHandler());
//4.遍历集合获取数据
for (Object[] objects : query) {
System.out.println(Arrays.toString(objects));
}
}
/**
* 查询id为3的记录,封装到指定JavaBean中
* BeanHandler 将结果集的第一条数据封装到 javaBean中
* */
@Test
public void testFindByIdJavaBean() throws SQLException {
QueryRunner qr = new QueryRunner(DruidUtils.getDataSource());
String sql = "select * from employee where eid = ?";
Employee employee = qr.query(sql, new BeanHandler<Employee>(Employee.class), 3);
System.out.println(employee);
}
/**
* 查询薪资大于 3000 的所员工信息,封装到JavaBean中再封装到List集合中
* BeanListHandler 将结果集的每一条和数据封装到 JavaBean中 再将JavaBean 放到list集合中
*/
@Test
public void testFindBySalary() throws SQLException {
QueryRunner qr = new QueryRunner(DruidUtils.getDataSource());
String sql = "select * from employee where salary > ?";
List<Employee> list = qr.query(sql, new BeanListHandler<Employee>(Employee.class),
3000);
for (Employee employee : list) {
System.out.println(employee);
}
}
/*
* 查询姓名是 张百万的员工信息,将结果封装到Map集合中
* MapHandler 将结果集的第一条记录封装到 Map<String,Object>中
* key对应的是 列名 value对应的是 列的值
* */
@Test
public void testFindByName() throws SQLException {
QueryRunner qr = new QueryRunner(DruidUtils.getDataSource());
String sql = "select * from employee where ename = ?";
Map<String, Object> map = qr.query(sql, new MapHandler(), "张百万");
Set<Map.Entry<String, Object>> entries = map.entrySet();
for (Map.Entry<String, Object> entry : entries) {
//打印结果
System.out.println(entry.getKey() + " = " + entry.getValue());
}
}
/**
* 查询所有员工的薪资总额
* ScalarHandler 用于封装单个的数据
*/
@Test
public void testGetSum() throws SQLException {
QueryRunner qr = new QueryRunner(DruidUtils.getDataSource());
String sql = "select sum(salary) from employee";
Double sum = (Double)qr.query(sql, new ScalarHandler<>());
System.out.println("员工薪资总额: " + sum);
}
}
四、数据库批处理
1、什么是批处理
- 批处理(batch) 操作数据库
批处理指的是一次操作中执行多条SQL语句,批处理相当于一次一次执行效率提高很多
当向数据库中添加大量的数据时,需要用批处理
- 举例: 送货员的工作:
未使用批处理的时候,送货员每次只能运送 一件货物给商家;
使用批处理,则是送货员将所有要运送的货物, 都用车带到发放处派给客户。
2、实现批处理
Statement和PreparedStatement都支持批处理操作,以PreparedStatement举例:
1)要用到的方法:

2)MySQL批处理是默认关闭的,所以需要加一个参数才能打开mysql数据库批处理,在url中添加
rewriteBatchedStatements=true
例如: url=jdbc:mysql://127.0.0.1:3306/db5?characterEncoding=UTF-8&rewriteBatchedStatements=true
3) 案例:
1、创建一张表
create table testBatch(
id int primary key AUTO_INCREMENT,
uname varchar(50)
)2、测试向表中插入1万条数据
public class TestBath {
//使用批处理,向表中添加1万条数据
public static void main(String[] args) {
try{
//1.获取连接
Connection connection = DruidUtils.getConnection();
//2.获取预处理对
String sql ="insert into testBatch(uname) values(?)";
PreparedStatement ps = connection.prepareStatement(sql);
//3.创建for循环 来设置占位符参数
for(int i=0;i<10000;i++){
ps.setString(1,"小强"+i);
//将SQL添加到批处理 列表
ps.addBatch();
}
//添加时间戳 测试执行效率
long start = System.currentTimeMillis();
//统一 批量执行
ps.executeBatch();
long end = System.currentTimeMillis();
System.out.println("插入10000条数据使用: " +(end - start) +" 毫秒!");
}catch (SQLException e){
e.printStackTrace();
}
}
}
五、MySql元数据
1、什么是元数据
除了表之外的数据都是元数据,可以分为三类
- 查询结果信息: UPDATE 或 DELETE语句 受影响的记录数。
- 数据库和数据表的信息: 包含了数据库及数据表的结构信息。
- MySQL服务器信息: 包含了数据库服务器的当前状态,版本号等
2、常用命令
1、查看服务器当前状态:select version();
2、查看服务器的状态信息:show status;
3、显示表的字段信息等,和desc table_name一样 :show columns from table_name;
4、显示数据表的详细索引信息,包括PRIMARY KEY(主键):show index from table_name;
5、列出所有数据库:show databases;
6、显示当前数据库的所有表:show tables ;
7、获取当前的数据库名:select database();
3、使用JDBC 获取元数据
- JDBC中描述元数据的类

- 获取元数据对象的方法:getMetaData()
. connection 连接对象, 调用 getMetaData () 方法,获取的是DatabaseMetaData 数据库元数据对象
. PrepareStatement 预处理对象调用 getMetaData () , 获取的是ResultSetMetaData , 结果集元数据对象
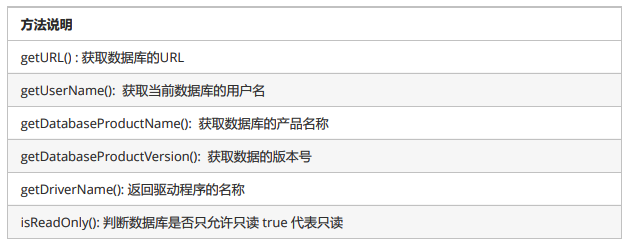
- DatabaseMetaData的常用方法
- ResultSetMetaData的常用方法

public class TestMetaDate {
//1.获取数据库相关的元数据信息 使用DatabaseMetaData
@Test
public void testDataBaseMetaData() throws Exception{
//1.获取数据库连接对象 connection
Connection connection = DruidUtils.getConnection();
//2.获取代表数据库的元数据对象 DatabaseMetaData
DatabaseMetaData metaData = connection.getMetaData();
//3.获取数据库相关的
String url = metaData.getURL();
System.out.println("数据库URL: " + url);
String userName = metaData.getUserName();
System.out.println("当前用户:" + userName);
String productName = metaData.getDatabaseProductName();
System.out.println("数据库产品名:" + productName);
String version = metaData.getDatabaseProductVersion();
System.out.println("数据库版本:" + version);
String driverName = metaData.getDriverName();
System.out.println("驱动名称:" + driverName);
//判断当前数据库是否只允许只读
boolean b = metaData.isReadOnly(); //如果是true就表示只读
if(b){
System.out.println("当前数据库只允许读操作");
}else {
System.out.println("不是只读数据库");
}
connection.close();
}
//获取结果集中的元数据信息
@Test
public void testResultSetMetaDate() throws SQLException{
//1.获取连接
Connection con = DruidUtils.getConnection();
//2.获取预处理对象
PreparedStatement ps = con.prepareStatement("select * from employee");
ResultSet resultSet = ps.executeQuery();
//3.获取结果集元数据对象
ResultSetMetaData metaData = ps.getMetaData();
//1.获取当前结果集 共有多少列
int count = metaData.getColumnCount();
System.out.println("当前结果集中共有: " + count + " 列");
//2.获取结果集中 列的名称和类型
for(int i = 1 ;i<=count;i++){
String catalogName = metaData.getCatalogName(i);
System.out.println("列名:" + catalogName);
String columnTypeName = metaData.getColumnTypeName(i);
System.out.println("类型: " + columnTypeName);
}
//释放资源
DruidUtils.close(con,ps,resultSet);
}
}
详细资料