欢迎关注WX公众号:【程序员管小亮】
python学习之路 - 从入门到精通到大师
文章目录
算法是一组完成任务的指令。任何代码片段都可视为算法,
一、二分查找
-
假设要在电话簿中找一个名字以K打头的人,可以从头开始翻页,直到进入以K打头的部分。但你很可能不这样做,而是从中间开始,因为你知道以K打头的名字在电话簿中间。
-
假设要在字典中找一个以O打头的单词,你可以从头A开始寻找到O字母,但是你应该不会这样做,因为你知道O在什么位置——中下,所以你将从中间附近开始。
-
假设你登录Facebook。当你这样做时,Facebook必须核实你是否有其网站的账户,因此必须在其数据库中查找你的用户名。如果你的用户名为karlmageddon,Facebook可从以A打头的部分开始查找,但更合乎逻辑的做法是从中间开始查找。
这三种情况都是在寻找自己的目标,可以统称为查找问题。在前述所有情况下,都可使用同一种算法来解决问题,这种算法就是 二分查找。
二分查找是一种算法,其输入是一个 有序的 元素列表(必须有序的原因稍后解释)。如果要查找的元素包含在列表中,二分查找返回其位置;否则返回null。
举一个例子,我们使用二分查找在电话簿中两个实业公司名,找到了第一个并返回了位置,没有找到第二个,所以反悔了NULL:

1)简单查找
下面举一个例子,来说明了二分查找的工作原理。这是一个酒桌上常玩的游戏,叫做猜数字,我先随便想一个1~100的数字,然后让另一个参与者,也就是你进行猜测,目标是以最少的次数猜到这个数字。每次你猜测错误后,我都会说小了、大了或对了这样的话来给出新的范围,输的人当然要喝酒,嘿嘿。
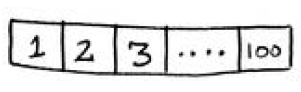
假设你从1开始依次往上猜,猜测过程会是这样:

这是 简单查找,更准确的说法是傻找,是一种糟糕的猜数法。每次猜测都只能排除一个数字。如果我想的数字是99,你得猜99次才能猜到!真的是醉了,这样子没人和你玩了哈。
2)更佳的查找方式
有没有更佳的猜数法呢?当然是有的,别着急,下面接着介绍。
从50开始猜数。

如果我说小了,这样你就知道了新的范围,也就是50 - 100,排除了一半的数字!至此,你就知道1 - 50都小了。接下来,你猜75。

如果我说大了,那余下的数字又排除了一半,也就是50 - 75!使用二分查找时,你猜测的是中间的数字,从而每次都将余下的数字排除一半。接下来,你猜63(50和75中间的数字)。
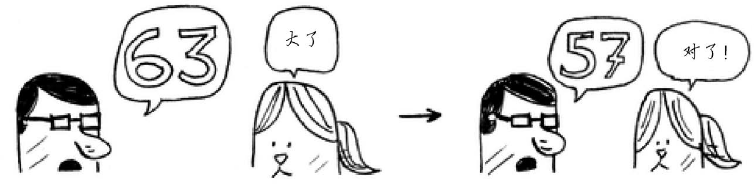
这就是二分查找,你学习的第一种算法!每次猜测排除的数字个数如下:
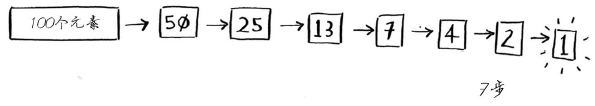
我们发现每一次使用二分查找时,都会排除一般的数字,简直不要太好用。换句话说,不管我心里想的是什么数字,你都能在7次之内猜到,因为每一次都能排除很多数字,当然我们说的是这个100以内猜数字是7次以内。
假设你要在字典中查找一个单词,而该字典包含240 000个单词,你认为每种查找最多需要多少步?如果要查找的单词位于字典末尾,使用简单查找将需要240 000步。使用二分查找时,每次排除一半单词,直到最后只剩下一个单词。
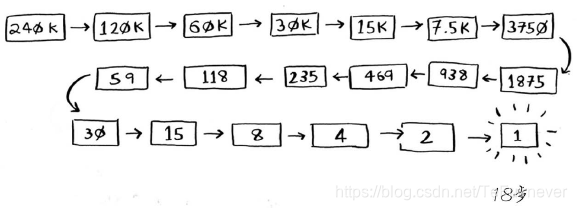
因此,使用二分查找只需18步——少多了!一般而言,对于包含n个元素的列表,用二分查找最多需要 步,而简单查找最多需要n步。
为什么是18,难道要一次一次的数嘛?答案当然是否,使用 进行计算,如果有的同学忘了对数,就一个例子,2的2次方是4,,那么,也就是说对数运算是幂运算的逆运算。
二、编程实战
如何编写执行二分查找的Python代码?这里的代码示例使用了数组。函数 binary_search 接受一个有序数组和一个元素。如果指定的元素包含在数组中,这个函数将返回其位置。我们准备跟踪的是要在其中查找目标的数组部分——最开始时为整个数组。
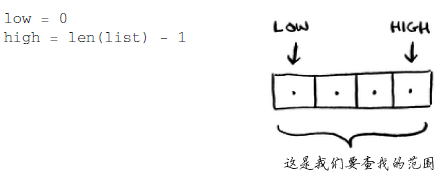
每一次都检查有序数组最中间的元素。

如果(low + high)不是偶数,我们就将mid向下取整。如果猜的数字小了,就相应地修改low。如果猜的数字大了,就修改high。完整的代码如下:
python版本代码如下:
def binary_search(list, item):
#low and high,就是对应你要跟踪搜索的列表的哪个部分
low = 0
high = len(list) - 1
#While 你还没有缩小到一个元素…
while low <= high:
# ... check the middle element
#……检查中间元素
mid = (low + high) // 2
guess = list[mid]
#找到了目标
if guess == item:
return mid
#猜测的太高了
if guess > item:
high = mid - 1
#猜测太低了
else:
low = mid + 1
#目标不存在
return None
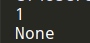
my_list = [1, 3, 5, 7, 9]
print(binary_search(my_list, 3)) # => 1
#'None' 在python中表示 0,我们用来表示找不到这个东西
print(binary_search(my_list, -1)) # => None
c++版本代码如下:
#include <iostream>
#include <vector>
using std::cout;
using std::endl;
template <typename T>
int binary_search(const std::vector<T>& list, const int& item) {
int low = 0;
int high = list.size() - 1;
while (low <= high) {
int mid = (low + high) / 2;
T guess = list[mid];
if (guess == item) {
return mid;
}
if (guess > item) {
high = mid - 1;
} else {
low = mid + 1;
}
}
return -1;
}
// this function returns pointer to the found element rather than array index
template <typename T>
const T* binary_search2(const std::vector<T>& list, const T& item) {
const T* low = &list.front();
const T* high = &list.back();
while (low <= high) {
// "guess" is the element in the middle between "high" and "low"
const T* guess = low + ((high - low) / 2);
if (*guess == item)
return guess;
if (*guess > item) {
high = guess - 1;
} else {
low = guess + 1;
}
}
return nullptr;
}
int main() {
std::vector<int> my_list = {1, 3, 5, 7, 9};
const int* binary_search2_result = binary_search2(my_list, 9);
const int* binary_search2_null = binary_search2(my_list, 4); // test finding element that is not in the list
cout << "Binary search for number 3: " << binary_search(my_list, 3) << endl;
cout << "Binary search 2 for number 9 (memory address): " << binary_search2_result << endl;
cout << "Binary search 2 for number 9 (value): " << *binary_search2_result << endl;
if (binary_search2_null == nullptr) {
cout << "4 was not found in the list" << endl;
}
return 0;
}
如果想要使用二分查找在一个包含128个名字的有序列表中查找一个名字,请问最多需要几步才能找到?
import math
int(math.log(128, 2)) # 或者int(math.log2(128))

三、运行时间
每次介绍算法时,都要将讨论其运行时间。一般而言,应选择效率最高的算法,以最大限度地减少运行时间或占用空间。
回到前面的二分查找。使用它可节省多少时间呢?简单查找逐个地检查数字,如果列表包含100个数字,最多需要猜100次。如果列表包含40亿个数字,最多需要猜40亿次。换言之,最多需要猜测的次数与列表长度相同,这被称为 线性时间(linear time)。
二分查找则不同。如果列表包含100个元素,最多要猜7次;如果列表包含40亿个数字,最多需猜32次。厉害吧?二分查找的运行时间为 对数时间(或log时间)。
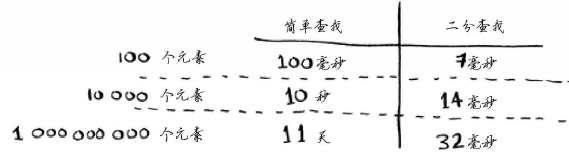
下表总结了我们发现的情况。
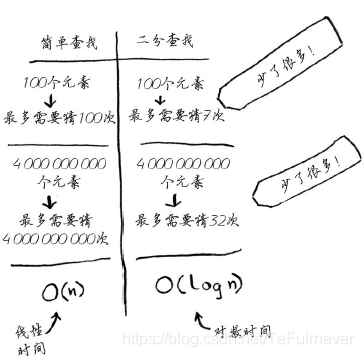
可以发现两个算法的时间成本上的差别。
四、大O 表示法
1)算法运行时间以不同的速度增加
下面来举一个高大上的例子,火箭登录月球计算着陆点,你回看到两种算法的运行时间呈现不同的增速。
Bob需要做出决定,是使用简单查找还是二分查找。使用的算法必须快速而准确。
- 一方面,二分查找的速度更快。Bob必须在10秒钟内找出着陆地点,否则火箭将偏离方向。
- 另一方面,简单查找算法编写起来更容易,因此出现bug的可能性更小。Bob可不希望引导火箭着陆的代码中有bug!
为确保万无一失,Bob决定计算两种算法在列表包含100个元素的情况下需要的时间。假设检查一个元素需要1毫秒。使用简单查找时,Bob必须检查100个元素,因此需要100毫秒才能查找完毕。而使用二分查找时,只需检查7个元素(log2100大约为7),因此需要7毫秒就能查找完毕。然而,真的是这个时间嘛?实际要查找的列表可能包含10亿个元素,在这种情况下,简单查找需要多长时间呢?二分查找又需要多长时间呢?
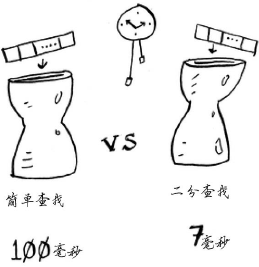
Bob使用包含10亿个元素的列表运行二分查找,运行时间为30毫秒(log21 000 000 000大约为30)。他心里想,二分查找的速度大约为简单查找的15倍,因为列表包含100个元素时,简单查找需要100毫秒,而二分查找需要7毫秒。因此,列表包含10亿个元素时,简单查找需要30 × 15 = 450毫秒,完全符合在10秒内查找完毕的要求。Bob决定使用简单查找。这是正确的选择吗?
不是,当然不是。实际上,Bob错了,而且错得离谱。列表包含10亿个元素时,简单查找需要10亿毫秒,相当于11天!为什么会这样呢?因为二分查找和简单查找的运行时间的增速不同,就是物理上常说的加速度。
看到了吗?运行时间的增速有着天壤之别。
简单来说,就是随着元素数量的增加,二分查找需要的额外时间并不多,而简单查找需要的额外时间却很多。因此,随着列表的增长,二分查找的速度比简单查找快得多。Bob以为二分查找速度为简单查找的15倍,这不对:列表包含10亿个元素时,为3300万倍。有鉴于此,仅知道算法需要多长时间才能运行完毕还不够,还需知道运行时间如何随列表增长而增加。这正是 大O表示法 的用武之地。
大O表示法指出了算法有多快。例如,假设列表包含n个元素。简单查找需要检查每个元素,因此需要执行n次操作。使用大O表示法,这个运行时间为O(n)。单位秒呢?没有——大O表示法指的并非以秒为单位的速度。大O表示法让你能够比较操作数,它指出了算法运行时间的增速。
再来看一个例子。为检查长度为n的列表,二分查找需要执行log n次操作。使用大O表示法,这个运行时间怎么表示呢?O(log n)。一般而言,大O表示法像下面这样:
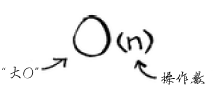
这指出了算法需要执行的操作数。之所以称为大O表示法,是因为操作数前有个大O。
2)理解不同的大 O 运行时间
下面来看一些例子,看看你能否确定这些算法的运行时间。首先拿出纸和笔,画一个网格,它包含16个格子。
如果想要绘制这样的网络,有什么好的算法嘛?
- 算法1
一种方法是以每次画一个的方式画16个格子。记住,大O表示法计算的是操作数。在这个示例中,画一个格子是一次操作,需要画16个格子。如果每次画一个格子,需要执行多少次操作呢?

这应该是不难的,画16个格子需要16步。这种算法的运行时间是多少?暂时不知道。
- 算法2
请尝试这种算法——将纸折起来。在这个算法中,将纸对折一次就是一次操作。第一次对折相当于画了两个格子!再折,再折,再折。
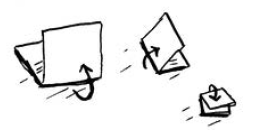
折4次后再打开,便得到了漂亮的网格!每折一次,格子数就翻倍,折4次就能得到16个格子!

感受到了嘛?有一种二分寻找的感觉。每折一次,绘制出的格子数都翻倍,因此4步就能“绘制”出16个格子。这种算法的运行时间是多少呢?
答案如下:算法1的运行时间为O(n),算法2的运行时间为O(log n)。
3)大O 表示法指出了最糟情况下的运行时间
假设使用 简单查找 在电话簿中找人。因为简单查找的运行时间为O(n),这意味着在最糟情况下,必须查看电话簿中的每个条目。如果要查找的是Adit——电话簿中的第一个人,一次就能找到,无需查看每个条目。考虑到一次就找到了Adit,请问这种算法的运行时间是O(n)还是O(1)呢?
当然还是O(n),简单查找的运行时间总是为O(n)。至于上面的情况,在查找Adit时,一次就找到了,这是最佳的情形,但大O表示法说的是 最糟的情形。因此可以说,在最糟情况下,必须查看电话簿中的每个条目,对应的运行时间为O(n)。这是一个保证——简单查找的运行时间不可能超过O(n)。
最简单地说,就是最大值,是个上限,实际上每一种可能都有,但是在比较讨论时,就是使用最糟糕的情况。
4)一些常见的大O 运行时间
下面按从快到慢的顺序列出了你经常会遇到的5种大O运行时间。
- O(log n),也叫 对数时间,这样的算法包括二分查找。
- O(n),也叫 线性时间,这样的算法包括简单查找。
- O(n * log n),这样的算法包括第4章将介绍的 快速排序——一种速度较快的排序算法。
- O(n2),这样的算法包括第2章将介绍的 选择排序——一种速度较慢的排序算法。
- O(n!),这样的算法包括接下来将介绍的 旅行商问题 的解决方案——一种非常慢的算法。
想象一下他们的函数图像

还有其他的运行时间,但这5种是最常见的。这里做了简化,实际上,并不能如此干净利索地将大O运行时间转换为操作数,但就目前而言,这种准确度足够了。可以获得的主要启示如下:
- 算法的速度指的并非 时间,而是 操作数的增速。
- 谈论算法的速度时,说的是随着输入的增加,其运行时间将以什么样的速度 增加。
- 算法的运行时间用 大O表示法 表示。
- O(log n)比O(n)快,当需要搜索的元素越多时,前者比后者快得越多。
5)旅行商问题
阅读前一节时,你可能认为根本就没有运行时间为O(n!)的算法。然而并不是,这节介绍的就是一个运行时间极长的算法。这个算法要解决的是计算机科学领域非常著名的旅行商问题,其计算时间增加得非常快。
问题如下:
有一位旅行商。他需要前往5个城市。
这位旅行商要前往这5个城市,同时要确保旅程最短。为此,可考虑前往这些城市的各种可能顺序。
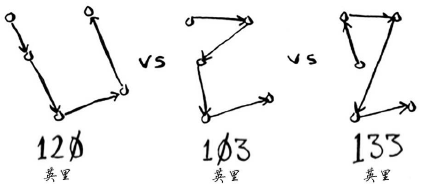
对于每种顺序,都计算总旅程,再挑选出旅程最短的路线。5个城市有120(5!)种不同的排列方式。因此,在涉及5个城市时,解决这个问题需要执行120次操作。涉及6个城市时,需要执行720(6!)次操作(有720种不同的排列方式)。涉及7个城市时,需要执行5040(7!)次操作!
推而广之,涉及n个城市时,需要执行n!(n的阶乘)次操作才能计算出结果。因此运行时间为O(n!),即阶乘时间。除非涉及的城市数很少,否则需要执行非常多的操作。如果涉及的城市数超过100,根本就不能在合理的时间内计算出结果——等你计算出结果,太阳都没了。
这种算法很糟糕!可是别无选择。。。这是计算机科学领域待解的问题之一。
五、总结
- 二分查找的速度比简单查找快得多。
- O(log n)比O(n)快。需要搜索的元素越多,前者比后者就快得越多。
- 算法运行时间并不以秒为单位。
- 算法运行时间是从其增速的角度度量的。
- 算法运行时间用大O表示法表示。
参考文章
- 《算法图解》