1、分析
a)《HTTP权威指南》里第16章国际化里提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是'ISO-8859-1'编码。一般现在页面编码都直接在html页面中
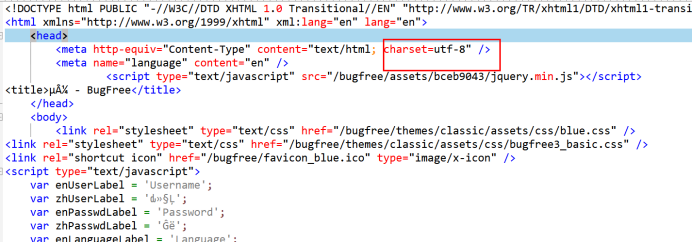
这处理英文页面当然没有问题,但是中文页面,就会有乱码了!
b)分析requests的源代码发现,content是urllib3读取回来的原始字节码,而text不过是尝试对content通过编码方式解码为unicode,即text返回的是处理过的Unicode型的数据,而使用content返回的是bytes型的原始数据,程序只通过http响应首部获取编码,假如响应中,没有指定charset, 那么直接返回'ISO-8859-1'。
c)本文中返回的html编码为utf-8,所以解码时出现了问题
2、解决办法
a)requests模块中自带该属性,但默认并没有用上,所以我们可以直接执行encoding为正确编码,让response.text正确解码即可
import requests url = 'http://192.168.127.129/bugfree/index.php/site/login' data = { 'username': 'admin', 'password': '123456', 'language': 'zh_cn', 'rememberMe': '0' } header = { 'User-Agent': 'Mozilla/5.0' } cookie = { '1_product': 'a6c11f988efefbf5398458aaf673011a504bf08ds%3A1%3A%221%22%3B', 'pageSize': '6f3ba80f2ac7df7b59e81c6cacbe4c041c5a706ds%3A2%3A%2220%22%3B', 'PHPSESSID': 'ku858m8vbmli7hp4inic0pifh7', 'language': 'bece46be16477e1ab82f9d40a53074cb0a54e105s%3A5%3A%22zh_cn%22%3B' } res = requests.post(url,data,headers=header,cookies=cookie) res.encoding = res.apparent_encoding print(res.text)
b)由于content是HTTP相应的原始字节串,所以我们需要直接可以通过使用它。把content按照页面编码方式解码为unicode!
import requests url = 'http://192.168.127.129/bugfree/index.php/site/login' data = { 'username': 'admin', 'password': '123456', 'language': 'zh_cn', 'rememberMe': '0' } header = { 'User-Agent': 'Mozilla/5.0' } cookie = { '1_product': 'a6c11f988efefbf5398458aaf673011a504bf08ds%3A1%3A%221%22%3B', 'pageSize': '6f3ba80f2ac7df7b59e81c6cacbe4c041c5a706ds%3A2%3A%2220%22%3B', 'PHPSESSID': 'ku858m8vbmli7hp4inic0pifh7', 'language': 'bece46be16477e1ab82f9d40a53074cb0a54e105s%3A5%3A%22zh_cn%22%3B' } res = requests.post(url,data,headers=header,cookies=cookie) print(res.content.decode('utf-8'))
解决前:
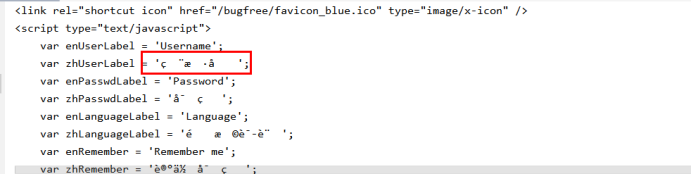
解决后:

参考博文:https://www.cnblogs.com/bitpeng/p/4748872.html;
https://blog.csdn.net/feixuedongji/article/details/82984583