简介
- Scrapyd是一个服务,用来运行scrapy爬虫
- 它允许你部署你的scrapy项目以及通过HTTP JSON的方式控制你的爬虫
- 官方文档: http://scrapyd.readthedocs.org/
安装
pip install scrapyd
- 安装完成后,输入scrapyd:
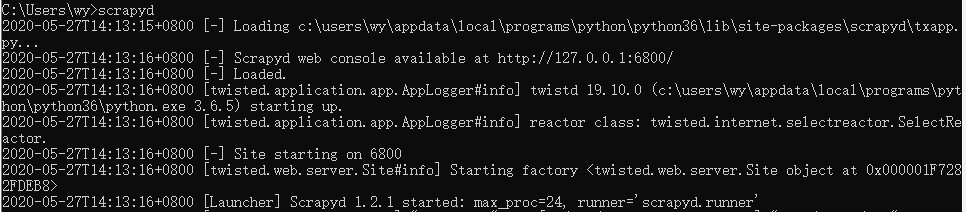
- 这样scrapyd就运行起来了,访问127.0.0.1:6800即可看到可视化界面。

部署scrapy
一、scrapyd其实就是一个服务器端,真正在部署爬虫的时候,我们需要两个东西:
- 1、scrapyd (安装在服务器端)
- 2、scrapyd-client (客户端)
scrapyd-client,它允许我们将本地的scrapy项目打包发送到scrapyd 这个服务端
安装 scrapyd-client:pip install scrapyd-client
二、部署scrapy项目
修改scrapy项目中scrapy.cfg配置文件
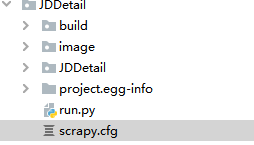
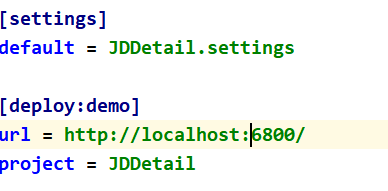
把url的注释取消掉,这个就是我们要部署到目标服务器的地址
然后,把[deploy]这里改为[deploy:demo],这里是命名为demo,命名可以任意怎么都可以,只要能标识出来项目就可以。
下边的project 就是我们的工程名,到此配置文件更改完成。
接着,执行scrapyd-deploy,这个命令在windows下是运行不了的,(在mac和linux下都是可以的)在我们的python环境中(C:UserswyAppDataLocalProgramsPythonPython36Scripts)可以查看到这个文件是没有目录的
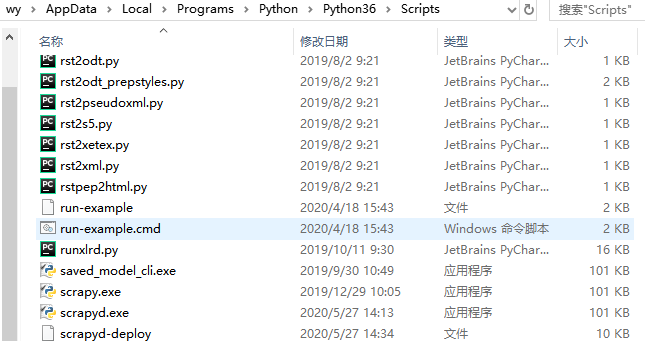
我们需要在这个目录下新建一个scrapy-deploy.bat文件
@echo off
"D:PYTHNONscrapyvenvScriptspython.exe" "C:UserswyAppDataLocalProgramsPythonPython36Scriptsscrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
上面的服务是我的环境中python.exe路径,大家可以根据自己环境来改变路径做配置。
这样就可以执行scrapyd-deploy这个命令了。
然后,进入到我们爬虫的根目录,运行scrapyd-deploy:

显示这个就证明我们成功执行了scrapyd-deploy,执行这个需要到scrapy.cfg的那一层的目录
执行命令
scrapyd-deploy demo -p JDDetail
因为上边我们已经配置过scrapy.cfg文件了,这里直接使用配置完的参数即可
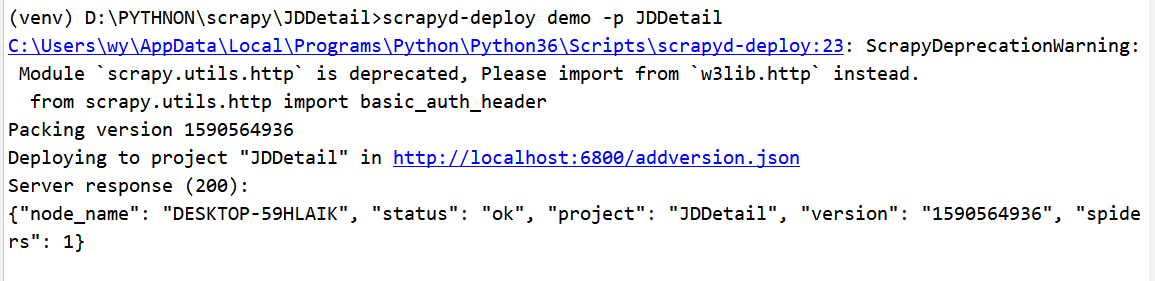
这里显示我们部署成功,可以查看执行启动scrapyd服务端的当先目录下有两个文件夹

到这一步,只是把爬虫项目上传到服务端,并没有启动,
先运行命令查看服务端状态:curl http://localhost:6800/daemonstatus.json

再执行启动命令:
curl http://localhost:6800/schedule.json -d project=JDDetail -d spider=jdSpider
project是项目名
spider是爬虫名字
然后查看网页127.0.0.1:6800
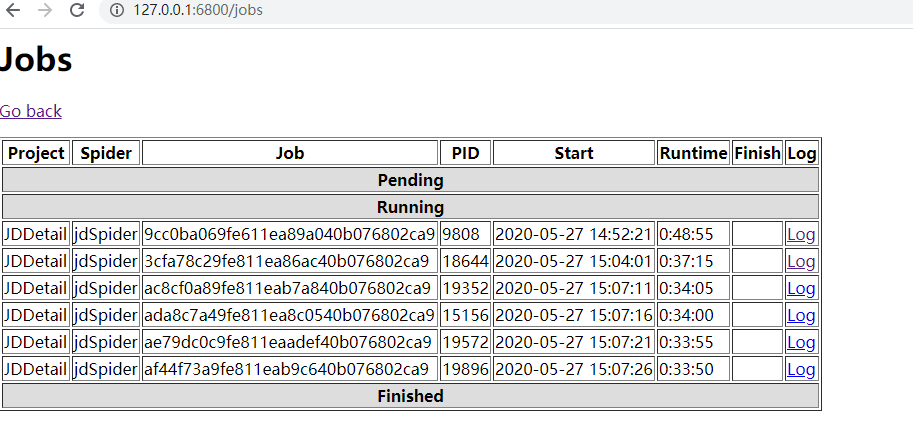
我们在生产环境中,一般scrapyd是部署在服务器,而我们一般会从本地直接发送到服务器端,这时需要调整
vim /usr/lib/python3/site-packages/scrapyd/default_scrapyd.conf
scrapyd的默认配置文件:
默认scrapyd启动bind绑定的ip地址是127.0.0.1端口是:6800,
将ip地址设置为0.0.0.0
打开配置文件不需要翻页就能够找到bind_address
注意:如果下载文件的话,会存储到部署scrapyd启动的目录处