工作中经常要用到的一些东西,一直没整理,用的多的记住了,用的不多的每次都是去查,所以记录一下。
DDL(数据定义语言),那就包括建表,修改表结构等等了
建表:create hive table
1 hive> CREATE TABLE pokes (foo INT, bar STRING);
创建一个名为pokes的表,包括两个字段,第一个字段foo是整型,第二个字段bar是字符串。
1 hive> CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING);
创建一个名为invites的表,包括两个字段(列):foo、bar,和一个分区字段(列)ds。分区字段是虚拟的字段(列)。他不属于数据本身,而是一个特定的数据集。
默认情况下表被按照文本格式存储,以ctrl+a分隔列。
下面是工作中常用的建表方式(日期表和分区表):
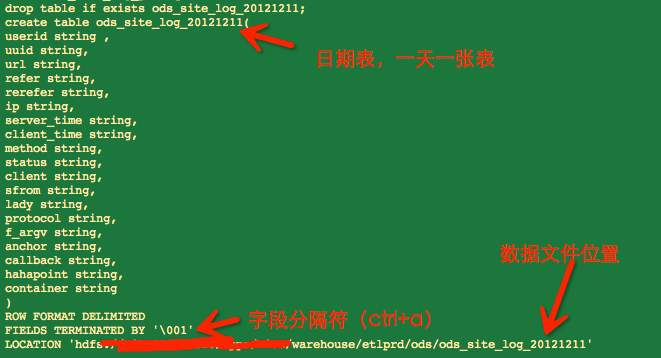
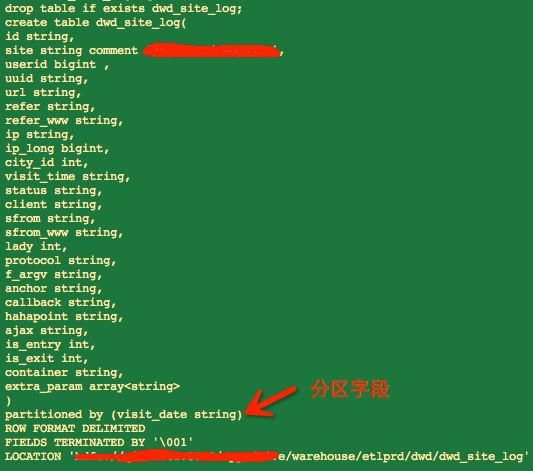
需要解释的地方:
1 ROW FORMAT DELIMITED 2 FIELDS TERMINATED BY '�01' 3 COLLECTION ITEMS TERMINATED BY '�02' 4 MAP KEYS TERMINATED BY '�03' 5 STORED AS TEXTFILE;
[ROW FORMAT DELIMITED]关键字,是用来设置创建的表在加载数据的时候,支持的列分隔符。不同列之间用一个'�01'分割,集合(例如array,map)的元素之间以'�02'隔开,map中key和value用'�03'分割。
stored as textfile表示按文本存储数据文件
浏览表:browsing through table
1 hive> SHOW TABLES;
列出所有的表
1 hive> SHOW TABLES '.*s';
列出所有以‘s’结尾的表(正则模式使用Java的规则)
1 hive> DESCRIBE invites;
列出表中的字段信息
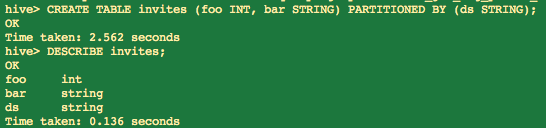
变更和删除表:altering and dropping tables
可以变更表名,或者增加和删除列等:
1 hive> ALTER TABLE events RENAME TO 3koobecaf; 2 hive> ALTER TABLE pokes ADD COLUMNS (new_col INT); 3 hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment'); 4 hive> ALTER TABLE invites REPLACE COLUMNS (foo INT, bar STRING, baz INT COMMENT 'baz replaces new_col2');
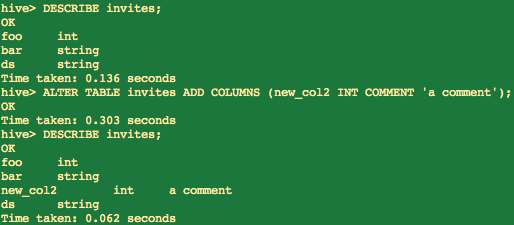
注意:REPLACE COLUMNS替换所有的列,但是数据不会变更。这个功能可以用于删除表中的某些列,如:
1 ALTER TABLE invites REPLACE COLUMNS (foo INT COMMENT 'only keep the first column');
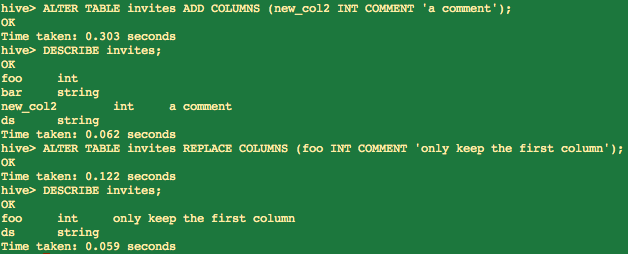
替换后仅留下了第一列和分区列
1 hive> DROP TABLE pokes;
删除表
DML(数据处理语言)包括数据载入导出等
从本地文件加载到表
1 hive> LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
OVERWRITE表示覆盖表中数据,如果没有使用OVERWRITE将把数据追加到表中原有数据后面
载入文件中的内容必须按照正确地分隔符分割列,load data并不会进行数据验证
1 hive> LOAD DATA LOCAL INPATH './examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15'); 2 hive> LOAD DATA LOCAL INPATH './examples/files/kv3.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-08');
上面给两条语句将数据载入到不同的分区
1 hive> LOAD DATA INPATH '/user/myname/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');
上面的命令从HDFS中加载文件。从HDFS中加载文件将移动文件
SQL(结构化查询语言)用于查询数据
查询
1 hive> SELECT a.foo FROM invites a WHERE a.ds='2008-08-15';
从invites表的2008-08-15分区中查询出foo字段
1 hive> INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='2008-08-15';
查询invites表的2008-08-15分区的所有字段内容并将查询结果导入到hdfs的/tmp/hdfs_out文件中
1 hive> INSERT OVERWRITE LOCAL DIRECTORY '/tmp/local_out' SELECT a.* FROM pokes a;
将查询结果保存到本地文件
1 hive> INSERT OVERWRITE TABLE events SELECT a.* FROM profiles a; 2 hive> INSERT OVERWRITE TABLE events SELECT a.* FROM profiles a WHERE a.key < 100; 3 hive> INSERT OVERWRITE LOCAL DIRECTORY '/tmp/reg_3' SELECT a.* FROM events a; 4 hive> INSERT OVERWRITE DIRECTORY '/tmp/reg_4' select a.invites, a.pokes FROM profiles a; 5 hive> INSERT OVERWRITE DIRECTORY '/tmp/reg_5' SELECT COUNT(*) FROM invites a WHERE a.ds='2008-08-15'; 6 hive> INSERT OVERWRITE DIRECTORY '/tmp/reg_5' SELECT a.foo, a.bar FROM invites a; 7 hive> INSERT OVERWRITE LOCAL DIRECTORY '/tmp/sum' SELECT SUM(a.pc) FROM pc1 a;
一些查询示例
GROUP BY使用
1 hive> FROM invites a INSERT OVERWRITE TABLE events SELECT a.bar, count(*) WHERE a.foo > 0 GROUP BY a.bar; 2 hive> INSERT OVERWRITE TABLE events SELECT a.bar, count(*) FROM invites a WHERE a.foo > 0 GROUP BY a.bar;
(上面的两条语句是等价的)
JOIN
1 hive> FROM pokes t1 JOIN invites t2 ON (t1.bar = t2.bar) INSERT OVERWRITE TABLE events SELECT t1.bar, t1.foo, t2.foo;
join使用时要注意方式的选择({LEFT|RIGHT|FULL} [OUTER] JOIN)及优化,下面是一些参考
http://yugouai.iteye.com/blog/1849395
http://www.open-open.com/lib/view/open1341214750402.html
多表插入(MULTITABLE INSERT)
1 FROM src 2 INSERT OVERWRITE TABLE dest1 SELECT src.* WHERE src.key < 100 3 INSERT OVERWRITE TABLE dest2 SELECT src.key, src.value WHERE src.key >= 100 and src.key < 200 4 INSERT OVERWRITE TABLE dest3 PARTITION(ds='2008-04-08', hr='12') SELECT src.key WHERE src.key >= 200 and src.key < 300 5 INSERT OVERWRITE LOCAL DIRECTORY '/tmp/dest4.out' SELECT src.value WHERE src.key >= 300;
上面的语句含义是从src表中查询出各表需要的数据插入到不同的表中