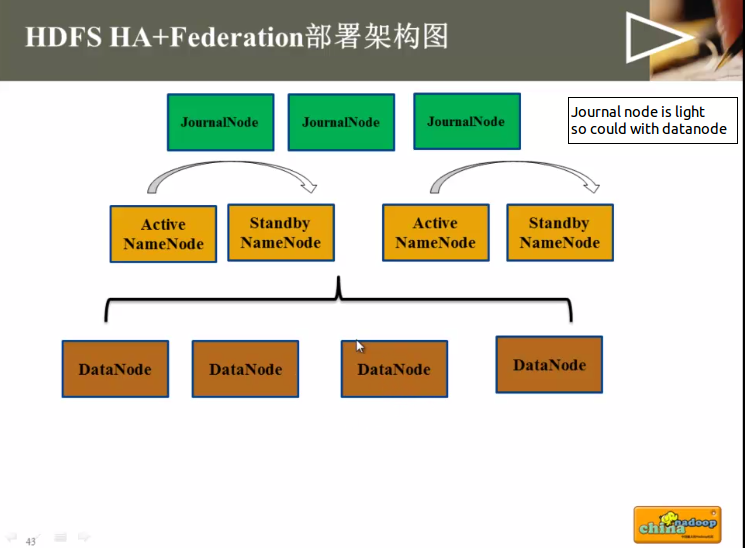
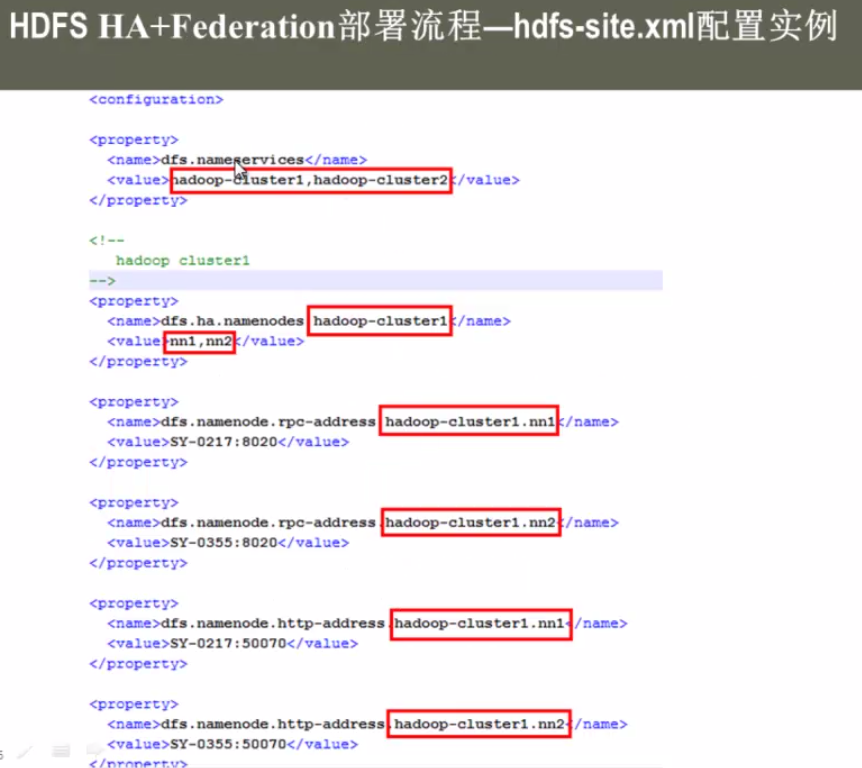

其他的配置跟HDFS-HA部署方式完全一样。但JournalNOde的配置不一样
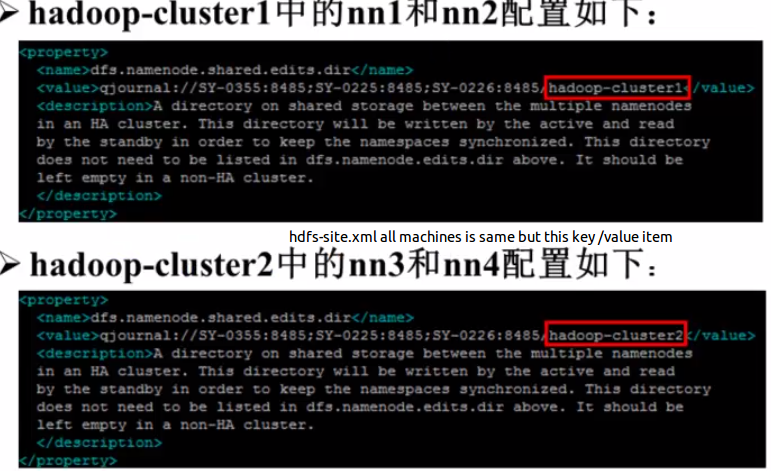
》hadoop-cluster1中的nn1和nn2和hadoop-cluster2中的nn3和nn4可以公用同样的journalnode但dfs.namenode.shared.edits.dir配置不能相同。
hadoop-cluster1中的nn1和nn2配置如下:
hdfs ha federation启动/关闭流程
在nn1,nn2两个节点上如下操作
step1:在各个journalnode上,启动journalnode服务:
sbin/hadoop-daemon.sh start journalnode
step2:在[nn1]上,对其进行格式化,并启动
bin/hdfs namenode -format -clusterId hadoop-cluster
sbin/hadoop-daemon.sh start namenode
step3:在[nn2]上,同步[nn1]的元数据信息
bin/hdfs namenode -bootstrapStandby
step4:在[nn2],启动Namenode:
sbin/hadoop-daemon.sh start namenode
(经过以上四步,nn1和nn2均处于standby状态)
step5:在[nn1]上,将NameNode切换为active
bin/hdfs haadmin -ns hadoop-cluster1 -transitionToActive nn1 [-ns 指定命名服务 在dfs.nameservices中指定了]

最后:在nn1上,启动所有datanode
sbin/hadoop-daemon[s].sh start datanode
依次看4个50070节点就行。有两个active ,两个standby
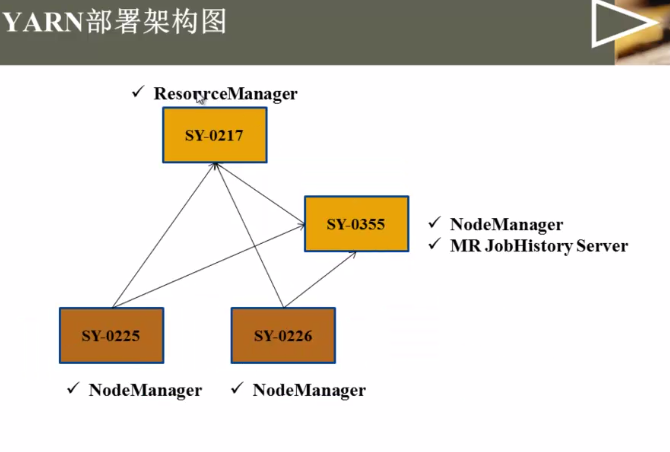
选一个作为rsourcemanager就行,其他作为nodemanager


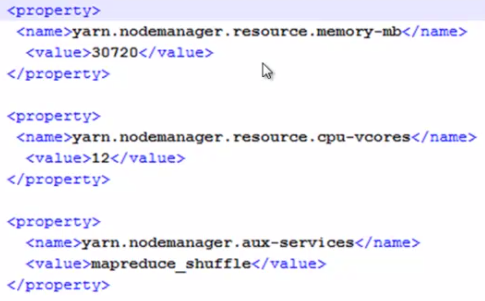
memory-mb与cpu-vcores:告诉resourcemanager我有多少资源可供使用,比方namenode上有20G内存供yarn使用,12个核,可以配置15G的内存,6个核供yarn使用。剩余的给hdfs或其他服务使用
fairscheduler.xml的配置实例:
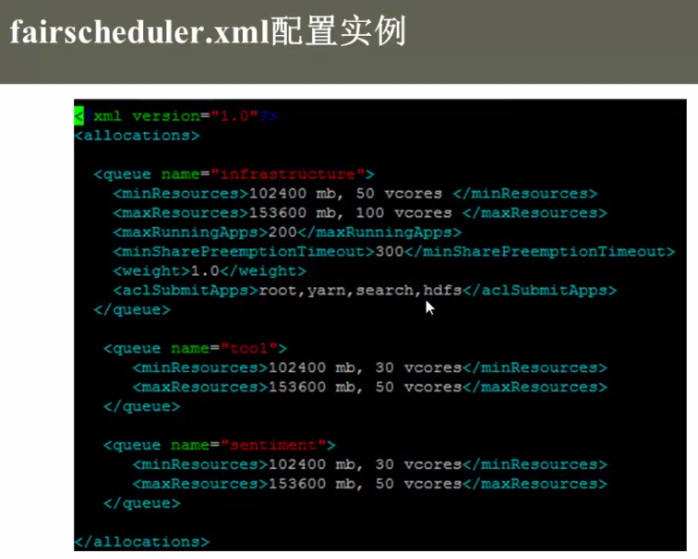
aclSubmitApps 指定了只有哪些用户可以使用这个队列。
mapred-site.xml
在sy-0217上启动yarnsbin/start-yarn.sh
停止:
sbin/stop-yarn.sh
在sy-0355上启动MR JOb history server:
sbin/mr-jobhistory-daemon.sh start historyserver (可以在命令行下查看所有mr历史任务,默认一个程序过去后他的一些历史数据就看不到了 )