内存分段
一丶分段(汇编指令分段)
1.为什么分段?
因为分段是为了更好的管理数据和代码,就好比C语言为什么会有内存4区一样,否则汇编代码都写在一起了,执行的话虽然能执行,但是代码多了,数据多了,搞不清什么是代码
什么是数据了.
汇编分段代码
1 e 1000:0 "Hello$" 首先给1000:0的物理地址写入Hello字符串 2 d 1000:0 显示一下是否显示成功 3 4 mov ax,1000 给ax赋值数据,下面要分段了,所以需要给ax赋值 5 mov ds,ax 开始分段(分配数据段),把ax的值给段寄存器ds,可能有人会说,ds也是段寄存器,为什么不直接写 mov ds,1000, 这里因为是cs ds ss es等段寄存器是后面出来的,数据线没有连接他们,所以通过地址加法器先给ax赋值,再给ds...赋值 6 mov es,ax (分配附加段)ax的值也给es赋值(ds和es一般都是相同段地址) 7 mov ax,2000 给ax赋值2000 8 mov ss,ax 给ss段寄存器赋值2000 (分配栈段) 9 mov dx,0 给dx赋值字符串的偏移 (因为在指令字典中,dx是字符串的首地址的偏移,但是他是和ds数据段连用的,所以ds已经改为了1000,而1000*16 + 0偏移就是字符串的首地址,所以直接给即可) 10 mov ah,9 调用显示hello,给参数9 11 int 21 系统调用(调用API) 12 mov ax,4c00 退出指令,给ax 13 int 21 系统调用(调用API) 14 ret 返回
指令图片,变为100偏移处了

注意一点,我们给mov dx,100的时候,其实是把100的偏移给dx,这样 ds内容的段地址是1000,dx是100, 他会联合起来去寻址,利用昨天的寻址公式找到物理地址, 1000 * 16 + 100 = 10100(实际物理地址)而实际物理地址就是字符串的首地址
所以下面调用可以正常显示hello了
但是我们如果写成 mov dx,[100] 那么就相当于对当前的物理地址取内容给dx, 变成了从100的偏移中取得内容给dx,dx的值就变味6548了,因为小端模式,所以65先读,又因为dx是16位寄存器,所以只能读取2个word,
那么这样寻址就会错误了,等价于他去寻找字符串的首地址变成了 1000 * 16 + 6548 = ???反正结果是不对了,就会出现各种各样的BUG
退出指令
mov ax,4c00 这个是操作系统提供的,用于退出汇编程序
如果不退出,ip的偏移就会出现错误,那么就可能随机的吧ip和cs联合寻找的物理地址当做代码段去执行,就会出现错误.所以直接退出.
int 21就是系统调用(也就是调用API)
二丶多个汇编程序变为一个汇编程序执行
想想以前,如果不能多人开发,那么就不会出现各种游戏和高级软件了.
怎么解决汇编程序多人开发
上面说了,我们为了有效的区分代码,数据.我们分段了,但是多人开发,每个代码段怎么办,难道要规定好?
所以以前如果合并汇编程序,那么要修改代码段,然后修改偏移,最后让两个汇编程序执行到一起.
但是这样是有规律的,所以后来就出现了连接器 link(连接成Obj)link的作用就是专门修复段,还有修复段偏移的,达到两个程序就可以在一起都执行了
当然OBJ网上有开源的文件格式可以研究一下.
这样方法,叫做重定向,obj首次发明了出来,那么这个时候就有了连接的概念了,
obj最简单的文件格式
代码段 代码段长度
数据段 数据段长度
附加段 附加段长度
等等,当然可能更加详细.但是这样通过把另一个程序的段还有数据长度,都修改一下,就完成了两个汇编语言合并到一起就可以都执行了.
三丶编译器的出现
上面说的debug只是一个调试器,或者叫做翻译器
现在出现了一个编译器,编译器就规定了语法了,然后那个时候我们可以把我们的程序,按照编译器的语法,编译成汇编代码
比如分段
1.代码段
MyCode segment
....你的汇编代码
MyCode ends
那么这样就把代码段分好了(专门执行代码)(但是这样虽然分好了,但是永远不会执行)
因为CS和IP是确定代码执行的位置,显然我们这只是把段分好了,但是CS和Ip还没有修改,也不能修改,因为一开始就是默认的,怎么办,
所以现在在编译器中我们可以写成这样
MyCode segment
START: 在这里首次提出了标号的概念,就相当于C语言的Goto语句,可以定义标号
...你的汇编代码
MyCode segment
end START 这里有个end,代表了汇编程序结束, START代表跳转到START来执行我们的代码
2.分数据段
MyData segment db "helloworld$" ;分号在编译器里面已经认为了是汇编代码的注视了,这里的db相当于是 #define byte,就是按字节定义,也可以写为 db 100 就是分配数据区为100 ;dd 代表 #define Dword (4个字节) ;dw 代码 #define Word 定义两个字节的意思 MyData ends
3.分栈段
MyStack segment stack 这里后面要加个关键字,因为上面的地址是数据段,当我们压栈的时候,栈的方向是向上增长的(也就是压栈,然后数据不断的累积,压一个,那么数据就会向上增长,向低地址增长,那么就会把数据段给覆盖了,所以给个关键字,转换过来) ;db 100 dup(?) 这里我写的注释,意思就是 分配 100个字节, dup的意思就是是否初始化,给? 就是这个栈不初始化,(一般来说不会初始化的) ;db 100 dup(0) 这里就是分配了100个字节,都初始化为0 org 64 这个意思就是当前的断寄存器分配64k,如果分配64k,那么在1MB的空间中,最多只能分配16个这样的段 org是贵求64k段 MyStack ends; ends是结束
四丶编译器
编译器用微软独立开发的是 6.15版本,最后的版本,可以区第一课的连接中下载编译器
文件夹

其中 ml.exe是编译器
link.exe 是连接器,连接obj文件
edit 是微软以前的编辑器 (ALT+ F操作菜单,那时候没有键盘,TAB切换各个选项)
1.编译器的使用
1.改名
我们要使用编译器,第一步就是给编译器改个名字,为了不可vc++6.0自带的冲突,所以随便改一个
这里我改成ml16.exe
2.配置环境变量, 计算机 - > 属性- > 高级 - > 环境变量

打开属性
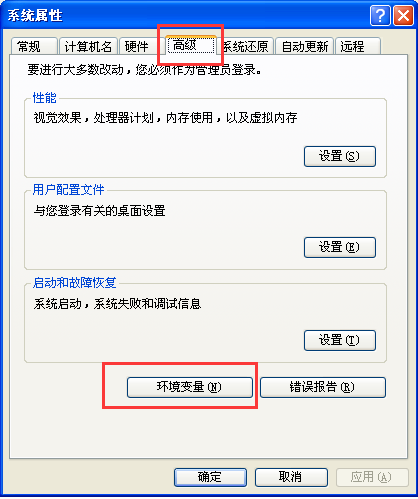
选择高级,然后选择环境变量

这里分为三步,第一步,复制ml编译器所在的文件夹路径,第二部点击环境变量的path,然后在最后面输入 ; 文件夹路径, 分号是结束上一个环境变量的语句,然后自己添加新的
第三不就是 ;文件夹路径即可. 确定 确定 确定.....
输入自己编译器的名字测试是否完成
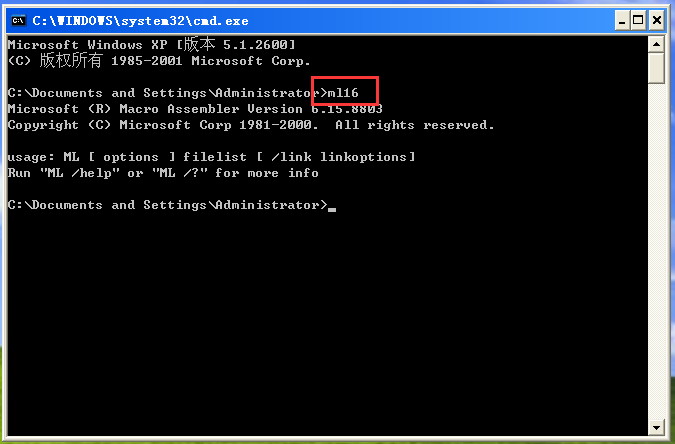
显示版本号完成
编译我们的汇编程序,编译我们的汇编程序,就要按照编译器的规范去写了.汇编文件的后缀名字是.asm
五丶第一个.asm程序 利用编译器分段,执行一个Hello
1 MyData segment 2 g_szHello db "HelloWorld$" //这些是分数据段 还有个g_szHello标号,下面偏移的时候细说 3 MyData ends 4 5 MyStack segment stack 6 org 64 //这些是分栈段 7 MyStack ends 8 9 MyCode segment 10 START: //设置标号 11 mov ax,1234h 12 mov bx,1234h 13 ;因为分好段了,所以现在开始设置段寄存器 14 mov ax,MyData 15 mov ds,ax //汇编代码分段,例如给ds分数据段,则可以直接给 MyData了,给栈分段,则直接可以给MyStack(当然这些段的名字都是自己定义的,自己随便定义主要是后面的关键字不要变即可) 16 mov es,ax 17 mov ax,MyStack 18 mov ss,ax 19 mov dx,offset g_szHello //我们利用汇编分段的时候说过,以前是 mov dx,0 (代表了从 ds * 16 + 0的物理地址得出字符串的地址)现在有个标号的概念,我们可以利用关键字直接给标号了,这样就不用自己手写给地址了,大大的提升了开发的效率 20 mov ah,9h 21 int 21h 22 mov ax,4c00h //退出汇编程序需要给的值 23 int 21h //调用int 21h会看ax的值是否是4c00是就退出 24 ret 25 MyCode ends 26 end START
编译出来是一个汇编写的可执行文件,也就是EXE这个可执行文件里面记录了各种段的信息,以及IP指令执行的位置(这也就是为什么通过exe文件格式,设计出来的入口函数,如果用Debug,你是没办法修改的)
EXE文件格式后面细讲,主要现在有个概念,就是EXE记录了段信息,各种寄存器的信息即可.
还需要注意,这里我们是按照编译器的规范写的第一个ASM程序,我们的数据都加上了h这种结束符号,因为从编译器开始就认为你给16进制就要给h了
比如mov ah,9 在debug里面就认为参数是9h, 而编译器认为虽然也是9,但是是10进制的9, 而且在编译器中,还可以写成二进制,八进制,10进制
比如 mov ah,9(debug的) ,在编译器可以写成 mov ah,1001b 在调用int 21一样调用
编译程序步骤
ml16 /c 文件名.asm
link 文件名.obj
(这里回车回车回车即可)
执行

三步走,第一步就是编译
第二步就是连接,连接的时候,我画了一个框框,因为光标会在这4个地方等待,直接回车 回车...即可.
第三步就是执行了
六丶段超越
但是分段只是逻辑上的分段,比如你在代码段里面放数据,是一样可以执行的
比如上面的asm代码可以改成下面这样
1 MyData segment 2 g_szHello db "HelloWorld$" 3 MyData ends //和上面一样分段 4 5 MyStack segment stack 6 org 64 //给栈分配 7 MyStack ends 8 9 MyCode segment //代码段 10 g_szNumber db "HelloWorldsssss$" //我们要在START上面放数据,不然汇编程序会把数据当做代码执行,现在我们给了 一段数据 11 START: 12 mov ax,1234h 13 mov bx,1234h 14 ;因为分好段了,所以现在开始设置段寄存器 15 mov ax,MyCode // 这个ax给的是代码段的段地址 16 mov ds,ax //那么把ds数据段设置为代码段的位置,那么下面调用数据段的内容会从这里开始当做段基地址 * 16 + 偏移,找到数据内容 也就是 Helloworld sssss 17 mov es,ax 18 mov ax,MyStack 19 mov ss,ax 20 mov ax,cs:[0h] 21 mov dx, offset g_szNumber //这里的dx 会把ds当做基地址,然后寻址找到Hellossss....... 所以说分段只是逻辑上的分段,现在数据段和逻辑段都重叠了 22 mov ah,9h 23 int 21h 24 mov ax,4c00h 25 int 21h 26 ret 27 MyCode ends 28 end START
为什么要再举一个这样的例子,其实说以前主要是为了藏代码执行,就比如说你写个C语言程序,如果就是main函数对吧,(其实真正的入口点不是这个,不做简介,自己百度)
然后利用上面的手段,你会发现,我在main函数里面就写个return 0,但是程序一打开就是有很牛逼的界面,你说厉害不,其实最主要的就是,这种方法病毒程序都使用这种方法.
所以其实段只是逻辑的概念,比如C语言的内存4区,就是基于汇编的分段,C语言也可以在全局变量区执行代码,执行函数,有的是方法.只不过分段了只是为了更好的开发而已
真正底层这些都不会是问题的.
执行结果:
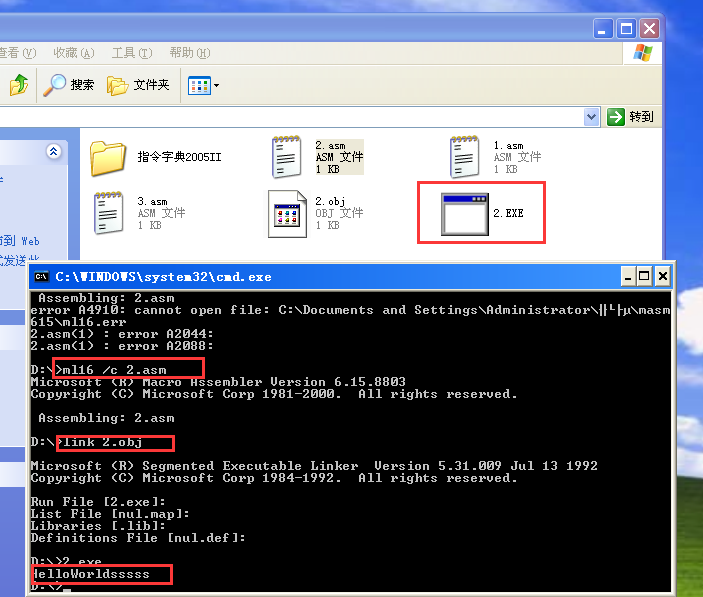
段超越:
什么是段超越,上面我们分段了,但是其实分段只是逻辑中的分段
比如我们 mov dx,0 那么基地址就是 ds数据段,dx存的就是0偏移,然后通过寻址方法,找到物理地址所在的内存
那么现在我们改成这样 dx的值不从ds数据段获取了
改为 mov dx,CS:[0H] 代表了我们要从 CS代码段里面的0偏移处,取出的内容赋值给DX
比如
CS的段基地址为 1000 :0 存放的数据为 1 2 3 4 5 6 7
那么 mov dx,CS:[0H] 相当于 从CS数据段中的0偏移取出内容 给 dx,因为dx寄存器是16位,所以取出的内容是3412 dx的偏移就是3412
我们也可以指定读取, mov dx,word ptr[0h]这个不是段超越,段超越是指定段读取,这个是默认从DS数据段中取出在0H位置处的两个字节的长度,给DX
注意只要是从DS(数据段)取出的内容,都不是段超越
除了DS都是,默认的 mov dx,[0h] 则是在ds中取出数据,等价于 mov dx,DS:[0H]
七丶,8086的机器码寻址方式 这个比较着重要了,就是通过机器代码反汇编出来汇编代码 主要常用的有三种寻址方式 1.立即数寻址方式 2.寄存器寻址方式 3.存储器寻址方式 先介绍第一种,(第二种第三种,第四讲细讲) 第一种 比如我们写了一段汇编代码,反汇编的时候可以看出机器码 有的时候要通过机器码反汇编出来汇编代码 比如下面我写好了一个程序
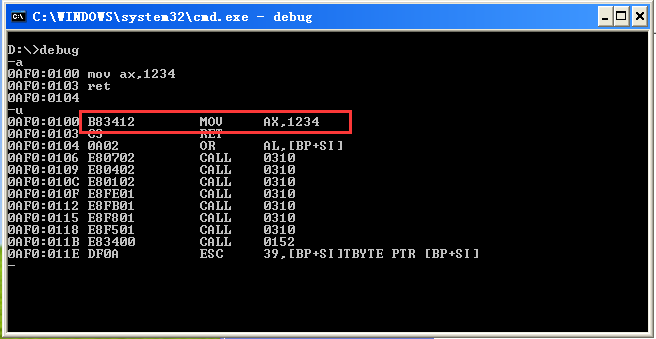
前边我们说过,每一条汇编指令对应一条机器码
上面从B83412去看
其中立即数寻址方式就是 ax后面的1234会按照小尾方式当做机器码存储
那么现在看的 B83412 其中3412就是操作数
B8是什么
B代表的是MOV指令
8转换成二进制是 1000B 我们推测可能是代表那个寄存器,最起码后边三位要代表寄存器
我们换一条指令,mov bx,1234看看有什么改变

我们发现变成了BB3412 前边知道了第一个B是mov指令的意思,3412是立即数
那么现在又多了一个B,我们变成二进制查看一下
B 1011B 发现侯三给变成11了
那么我们利用e 指令,给指定位置写入二进制,看看能出来一个汇编指令吗 (e 地址 回车,然后输入第一个,空格则可以输入第二个地址,依次类推)
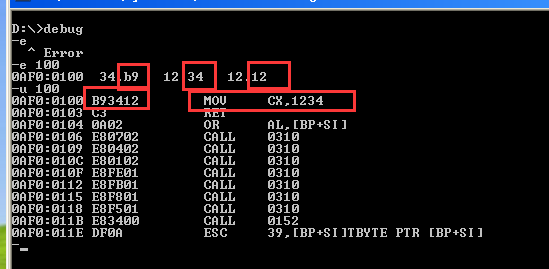
我们发现,我们写了一段二进制代码变成汇编代码成了 MOV CX,1234
9的二进制代码是 1001 代表的是CX
那么由此可以看出
8代表的是AX寄存器
9代表的是CX寄存器
B 代表的 BX寄存器
作业:
求出 八位通用寄存器分别所代表的值, 包括低八位和高八位各个寄存器的值
(AX BX CX DX SI DI SP BP ah,al , bh,bl......)
笔记代码连接:
链接:http://pan.baidu.com/s/1c2xVEBQ 密码:66cw