32位汇编第一讲x86和8086的区别,以及OllyDbg调试器的使用
一丶32位(x86也称为80386)与8086(16位)汇编的区别
1.寄存器的改变
AX 变为 EAX 可以这样想,16位通用寄存器前边都加个E开头
例如:
EAX EBX ECX EDX ESI EDI ESP EBP ;八个寄存器 EIP EFLAGES ;特殊寄存器
CS ES SS DS GS FS ;其中GS FS是新增加的寄存器,这些段寄存器,并不是4个字节(32位的)还是以前16位的
注意在32位下没有分段的概念的,因为寻址能力是 0- FFFFFFFF ,在当时的inter认为当初的4G已经很厉害了,那是后最好的内存才1G,放到现在看
我们感觉4G不够用了,但也是近几年才开始用的8G
有分区的概念,比如我们16位汇编中,给代码分段的时候,顺便分了一下区,分区是为了更好的管理代码的编写
2.地址有20根总线变为32根总线(也就是4G)
3.寄存器的数量没有做改变
2.32位寄存器和16位寄存器的兼容
EAX 的低16位变为AX了,所以兼容的16位,其余的寄存器同理
32位中的段寄存器不是我们能操作的了,给操作系统使用,所以有了权限一说
在16位中,我们可以直接操作段寄存器分段,或者寻址,而这样很不安全,万一你分段的时候,正好在操作系统的代码区,那么你可以修改代码,那么操作系统就崩溃了
所以为了系统的稳定,操作系统不让使用段寄存器了,而这些段寄存器操作系统都记录了一些表的信息
二丶编写32位中的汇编代码
1.介绍
在编写32位汇编的时候,介绍一下编译器和连接器,以前我们使用的汇编编译器是可以编译32位汇编的,但是连接器是不能连接32位汇编程序
所以link连接器需要改为32位的,如果有安装过vc++6.0 那么是可以找到它的连接器的,我们使用它的连接器即可.
2.分区概念
上面说了,操作系统不让我们使用段寄存器,那么我们可以去分区,分为 常量区 全局数据区 代码区 (没有栈区,栈区由编译器维护,编译器分配)
首先介绍一下伪指令的用法(伪指令在16位汇编最后一讲都讲了,那么这节课就要调用伪指令去编写汇编代码了,还会增加伪指令去讲解)
1.伪指令
①.model伪指令的使用

memorymodel: 表示你要设置的内存模式 这里我们设置平坦模式(表示内存是连续的,因为不能分段了)平坦模式 FLAT
[,langtype]调用约定: 如果这里写了调用约定,那么以后我们使用 函数的伪指令(PROC)的时候,就不用指明调用约定
了而且win32可以调用操作系统API,而调用API的时候,这些API的调用约定,也是你这里给指定的
用法例子:
.386 ;这里表示我们要写386的程序(也就是32位)汇编程序,指明一下,这个不是伪指令 .model FLAT,stdcall ;内存设置为平坦模式,默认调用约定stdcall
②伪指令PROTO(函数声明)

函数声明的伪指令,这个主要是针对我们自己写的函数,如果调用的时候,函数正好在下面(他会从上面找,找不到报错)所以声明一下告诉它存在即可
例子:
;使用伪指令声明 My_ADD PROTO n1:dword,n2:dword ;调用 invoke My_Add ,1,2 ;函数实现在下面,如果不写声明告诉存在,就会调用出错 My_ADD PROC n1:dword,n2:dword ;定义了一个函数,参数是n1,n2,指明的大小是DWORD(4个字节的),这里没有写调用约定,上面写了默认的调用约定了
My_ADD endp ;函数定义的结束标志
③伪指令 option(选项的伪指令)
这个伪指令主要是增加额外选项,比如上面我们调用函数,汇编不区分大小写,你这样写是可以调用的,但是为了
不必要的麻烦,我们加上一个选项,也就是大小写敏感,也就是区分大小写,这样我们调用系统API的时候就不用怕出错了

使用例子:
option casemap:none ;使用大小写敏感的选项
④定义常量去的伪指令(.const)
上面说了,内存有了保护模式,分为了 可读可写可执行,如果是常量去,那么只能读,不能写,不能执行
语法:
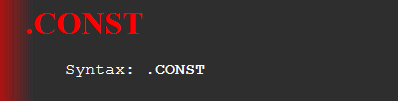
这个比较简单了
使用例子:
.const ;定义常量区 g_szTitle db "Hello" ;在常量区中定义常量字符串
⑤数据区的定义(.data)
数据区,专门定义数据使用的,是可读可写的
语法:

它分为两种,一种是初始化的数据区,一种是未初始化的数据区
初始化数据区的写法:
.data ;定义数据区 ....;你自己的数据
未初始化的数据区写法
.data ?;加?号表示未初始化 g_szData dw ? ;数据的申请必须是? 也就是未初始化的
两者的区别
初始化的数据,不过你定义数据的时候,是否给? 都会写的EXE(PE文件中)
未初始化的数据, 定义数据的时候只能给? 不在PE文件中保存
⑥代码区的伪指令(.code)
定义执行的代码区
语法:

例子:
.code START: ;代码开始执行的标号 end START; end表示文件结束START表示要从START开始执行代码
⑦多文件编译ASM(#include 后缀名.inc)
我们有时候会想,代码不可能一个文件写完,比如多个文件联合编译,所以就有了.inc文件
一般我们定义数据区,或者定义的宏都放在.inc的文件中
然后ASM文件使用include xxxx.inc 包含你自己的.inc文件即可
3.一段完整的win32汇编代码框架
上面的伪指令已经讲完了,这里写一段完整的汇编代码
.386 ;定义为386的汇编程序 .model FLAT,stdcall ;内存为平坦模式,默认调用约定stdcall option casemap:none ;增加选项,区分大小写 .const ;定义常量区(这些应该放到.inc文件中这里不妨了,放的话就是拷贝过去,然后这个文件引用即可) g_szTitle db "Title",0 ;win32字符串结尾都是0结尾了 g_szMsg db "Hello 51asm.com",0 .data ;定义数据区 .code ;定义代码区 START: ..... ;你的核心代码 end START
三丶编译连接Win32汇编程序
在32位中,编译汇编程序和连接汇编程序就有点不同了
1.编译:
在CMD中输入
ml /c /coff 文件名.asm
上面说过,我们在32位下,有了PE文件格式(exe文件),而PE文件格式是 COFF格式,也称作为PE
编译帮助:
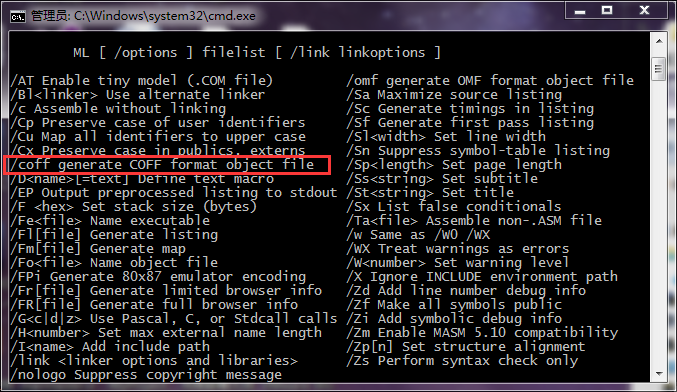
表示我们要编译为一个PE的obj格式
 编译我们的代码
编译我们的代码

然后出现这个,表示编译成功,看下obj文件

如果我们不加,就会编译成了16位的了,而连接的时候就会找16位的连接器,就会出错,显示找不到入口点的
错误
2.连接
连接的时候,不能在使用16位的连接器了,这里可以使用VC自带的link,没有没有关系,我会在每天的资料中上传所用的工具
连接选项(对我们有用的)
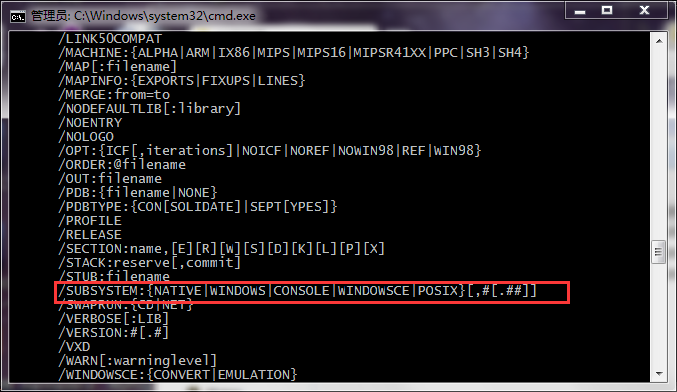
这个对我们有用,因为在32系统下,有了窗口的概念的,表示你要连接成什么程序,控制台的还是窗口的
假设我们要连接为一个控制台的程序
link /subsystem:console 文件名.obj ;连接成一个控制台的程序


代码没有出错,则正常显示
四丶写一个窗口版本探弹消息的程序,并用OllyDbg去分析
1.编写窗口程序
我们基于上面的32位程序的框架,写一个简单版本的信息框,弹出一个消息,把我们常量区的数据弹出来
并用OlleyDbg去分析
首先查一下MessageBox的用法

我们知道了,第一个参数是窗口句柄,没有我们可以给NULL 而NULL 在汇编中没有,我们就用宏定义 (EQU)
第二个参数是一个0结尾字符串的首地址,那么在汇编中可以通过 offset伪指令,把常量区的地址给它
第三个参数一样
第四个参数是显示弹框的按钮风格,我们一般使用MB_OK,而MB_OK 是0,汇编中也没有,所以我们定义一下
汇编代码例子:
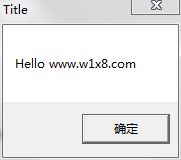
.386 .model FLAT,stdcall ;设置内存为平坦模式,默认调用约定STDCALL option casemap:none ;区分大小写 NULL EQU 0 ;定义NULL MB_OK EQU 0 ;定义为0 MessageBoxA PROTO hWnd:DWORD, :DWORD,:DWORD,:DWORD ;函数声明,声明为有4个参数,默认调用约定是Stdcall .const g_szTitle db "Title",0 g_szMsg db "Hello www.w1x8.com ",0 .data .code START: invoke MessageBoxA,NULL, offset g_szMsg,offset g_szTitle,MB_OK;调用API end START
这里使用的是MessageBoxA,因为操作系统分为宽字节和Ascii码版本
这里编译的时候命令还是上面的那个命令,(ml /c /coff 文件名.obj)
连接的时候不一样了
连接的时候我们需要链接为Windows窗口程序,而且最重要的一点就是MessageBoxA的实现代码在User32.lib中,所以也要一并的加入进来
link /subsystem:windows 文件名.obj user32.lib ;注意,user32.lib放到汇编程序所在的目录下
看下编译出来的程序
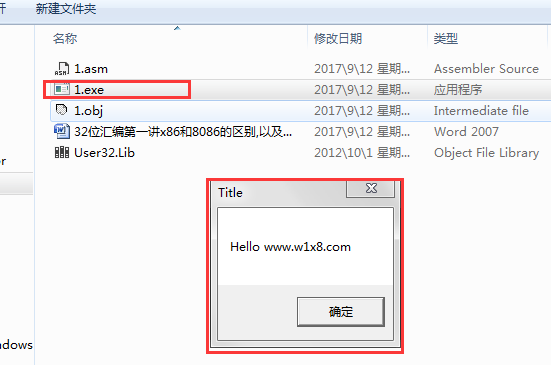
2.使用OllyDbg分析
把我们的exe放到OllyDbg中分析
这里先说下常用的快捷键
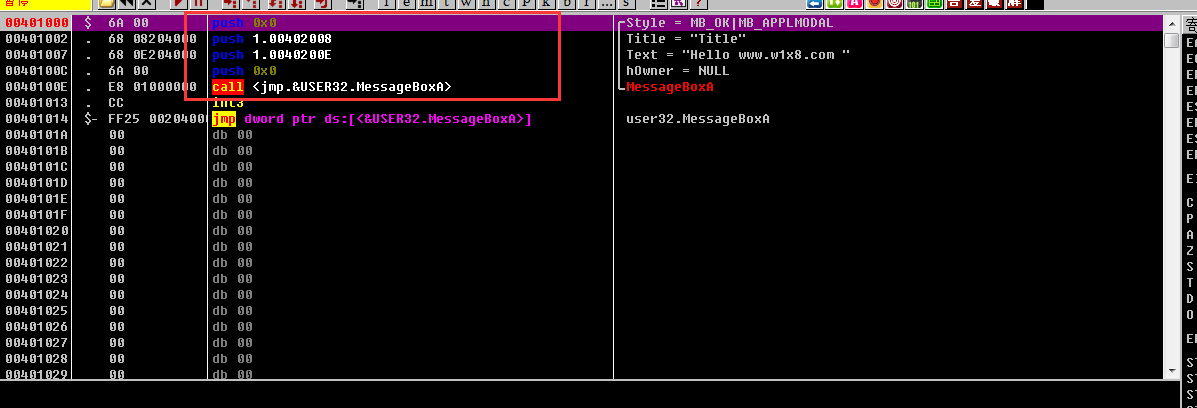
可以看到我们的汇编代码都在这里,我们F8单步执行,找到第一个Call,也就是MessageBoxA,F8走到Call的地方
F7进入
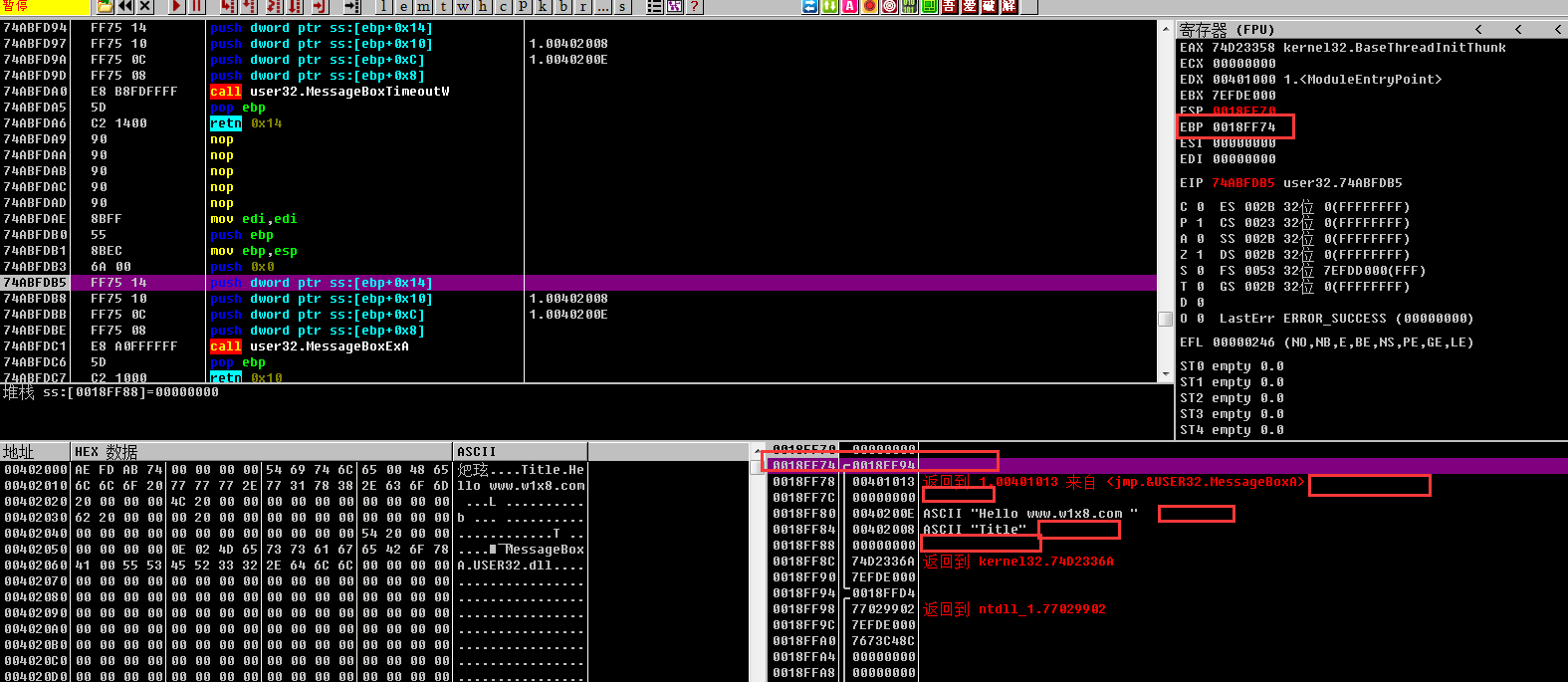
然后看下,他也是一样压栈ebp,出栈ebp,然后看下栈区,
看下EBP的位置(这里的EBP是执指向栈顶的,因为我们 mov ebp,esp了)
然后栈的格式和我们前边讲的是一样的
栈的当前结构:
保存栈底的值(ebp)
返回地址
参数一
参数二
参数三
参数四
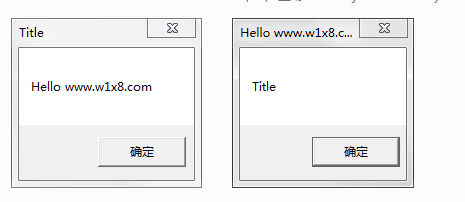
3.使用OD把我们的标题修改了成输出的消息,把以前的标题,修改为输出的消息(有点绕,就是两个互换输出)
思路:
我们把压栈的顺序修改一下

双击,把当前的压栈的顺序修改一下
push 1.00402008 修改为: push 1.0040200E push 1.0040200E 修改为: push 1.00402008
然后选择这两行,右键 -> 复制到可执行文件 然后选择 选择所有复制(相当于修改后的EXE)
最后弹出了个新的,我们点击保存文件即可
修改后的EXE
五丶关于PE文件的那点事
上面说了我们的信息会保存在exe文件中(也就是PE)我们用WinHex(16进制编辑器)查看一下
1.32位执行的开始
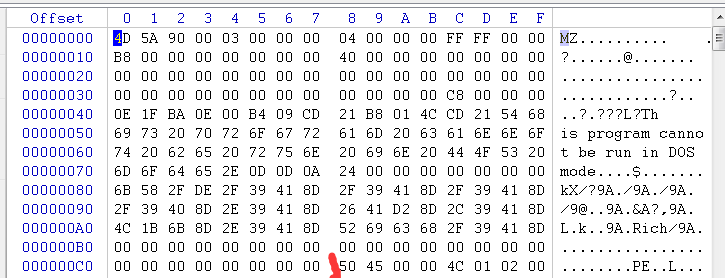
我们的EXE在这里上面的位置,都是为了兼容16位的,而真正的32位程序是从PE这里开始执行的,
上面的某些字段保存了PE所在的偏移,比如PE所在的位置是C8,那么上面的字段就会有C8保存,因为软件已启动
会根据这个偏移寻找PE文件的位置,这里C8位置在3C的位置

那么就代表我们不改变这个值,其余的随便修改,那么不影响32位程序的使用,我们修改一下
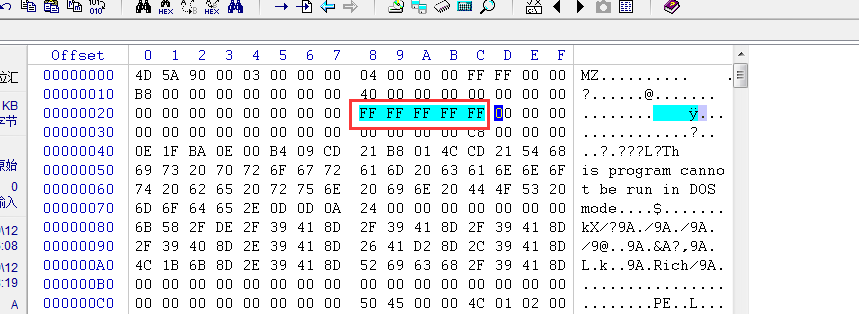
修改后还是能运行的
这个汇编程序会崩溃,原因是我们没有写退出,比如16位汇编中的退出是
mov ah,4c00h int 21h
这里就不写了
2.32汇编中简单的Dll劫持和API HOOK(思想)
注入方法很多,这里有个简单的,比如我们上面调用了一个MessageBoxA
他是在Lib中寻找dll的路径,以及MessageBoxA在那个Dll中
我们使用的这个Dll是动态的Dll,里面记录了Dll所在的路径,以及导出函数
而我们汇编中刚在这样用则是把user32.lib中当前调用的MessageBoxA所在的Dll路径,以及Dll导出函数的信息
连接到EXE文件中
所以说EXE文件中也会保存Dll的信息
我们使用WinHex查找一下EXE中是否有MessageBoxA
CTRL + F 查找,输入字符串

找到了所在的位置,我们把USER32.DLL改下名


可以看到,他找不到AAER32.dll,如果厉害的自己可以写一个AAER32.DLL,(当然细节很多,这里只是简单的思想)
我们就可以把DLL劫持了
比如我们把前边的函数名字修改了,那么如果你厉害,可以写个相同函数,就形成了APIHOOK
课堂资料下载地址:
当前第一课课程资料: 链接:http://pan.baidu.com/s/1geLWBzP 密码:2ko2
当前32位汇编所有课程资料: 链接:http://pan.baidu.com/s/1geC3iNL 密码:0hpc