SS是Spider Studio (采集工作站) 的简称, 这是由GDT团队开发的一款互联网数据采集开发工具. 它以浏览器为基础, 运用JQuery技术, 结合脚本化C#的强大功能, 能够轻松解决各类数据采集问题.
首先下载SS: http://www.gdtsearch.com/products.spiderstudio.htm
安装完成后运行起来界面如下:
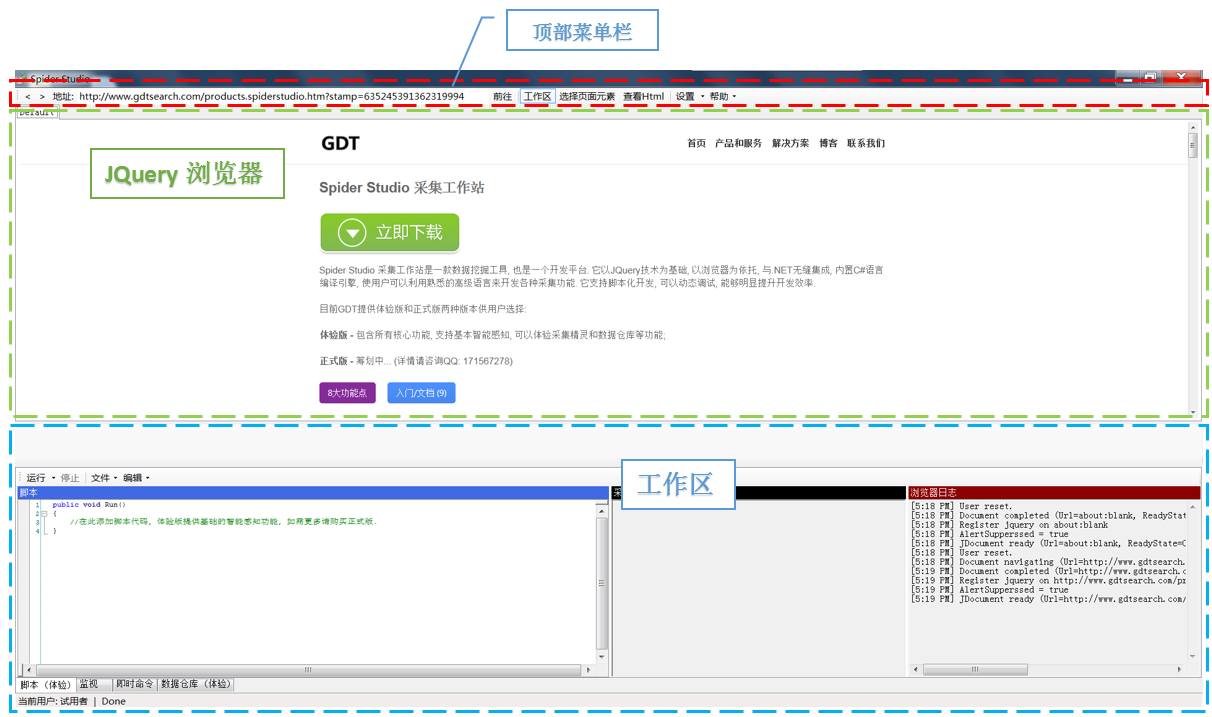
1. 顶部菜单栏
包含浏览器地址栏, 工作区展开/折叠开关, 页面元素选择器开关, Html查看按钮, 设置和帮助
菜单栏中大部分功能都很容易理解, 我重点说说 "设置" 菜单的子菜单:

- 浏览器选项 - 打开IE的设置页, 能够对IE进行各项设置, 比如不显示图片, 不显示flash等.
- 保存日志文件 - 如果勾上则会将"采集输出"和"浏览器日志"中显示的内容自动保存到log文件中, 用于进行分析诊断.
log文件都存放在安装目录下的"Log"子目录中, 文件名带有日期信息:
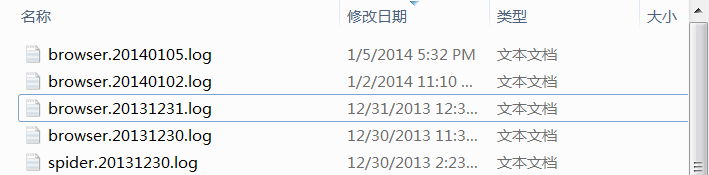
注: 其中browser.yyyymmdd.log是"浏览器日志", spider.yyyymmdd.log是"采集输出日志"
- 关闭所有标签页 - 在SS中能够用脚本管理多个标签页, 从而能够实现同时打开多个URL进行抓取, 最后将结果合并到一起的应用. 此部分具体用法将在后面专门撰文介绍.
- 数据仓库 - 自动刷新 - 开关, 告诉SS是否实时显示数据仓库中数据的变化, 如果打开, 则当数据更新非常频繁时会对性能造成一定影响.
- 添加/删除程序集 - 用来管理第三方程序集和代码中的using区域.
2. JQuery浏览器
这是一个为SS特别定制的浏览器. 它以IE为内核, 集成了JQuery技术, 提供了一系列DOM检索功能. 具体用法请阅读: API - 使用Default对象 - 基础篇
3. 工作区
工作区是SS最核心的一个功能区域. 其中包括 节点选择器, 脚本编辑器, 日志窗口, 监视窗口, 即时命令窗口和数据仓库管理界面.
3.1. 节点选择器
当我们在顶部菜单栏中点击 "选择页面元素" 之后, 用鼠标在页面移动时就会有一个蓝色方框自动跟随. 当我们在蓝色方框点击鼠标时 (左右键均可), 方框将停留在选中的元素上, 与此同时节点选择器会显示选中元素的JQuery表达式:
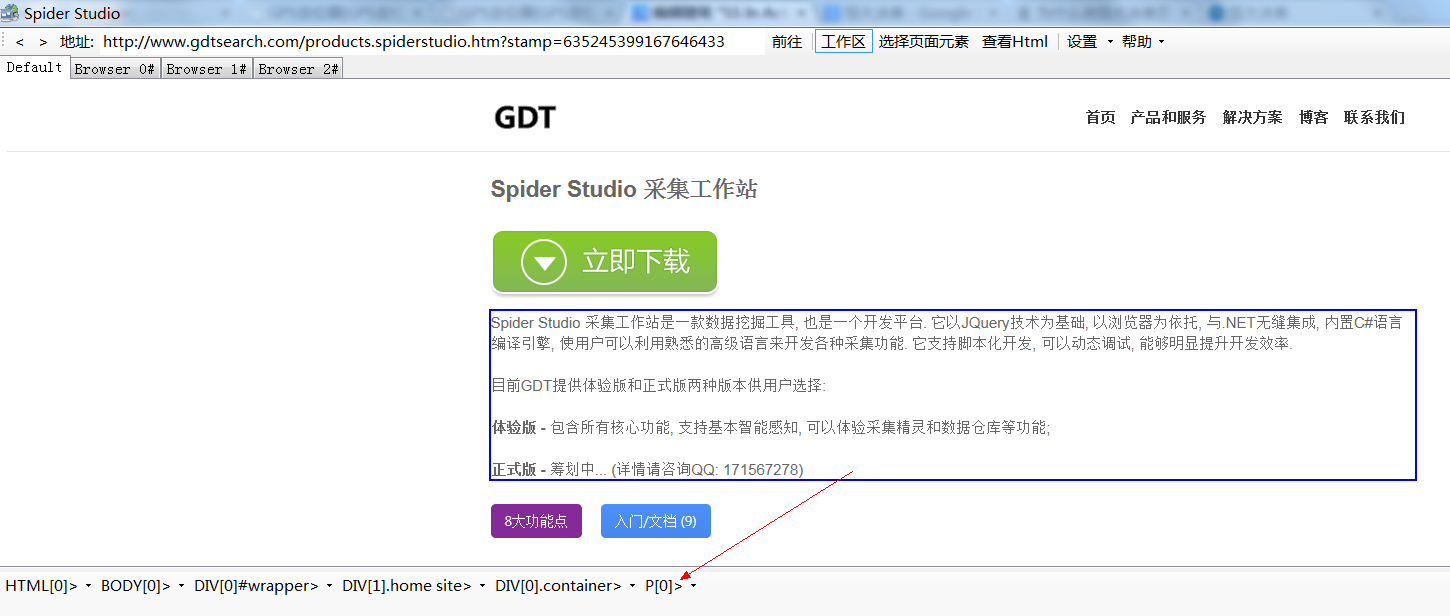
JQuery表达式的每个节点都是一个按钮, 点击后会出现节点的基本信息和相关功能菜单项.
3.2. 脚本编辑器, 日志窗口
这部分很简单, 我只介绍一些值得一提的应用技巧:
3.2.1. 最大化脚本编辑器 - 当编写的脚本很多很长时, 我们就希望能够最大化脚本编辑器, 从而显示更多内容. 通过双击标题栏可以做到这一点:
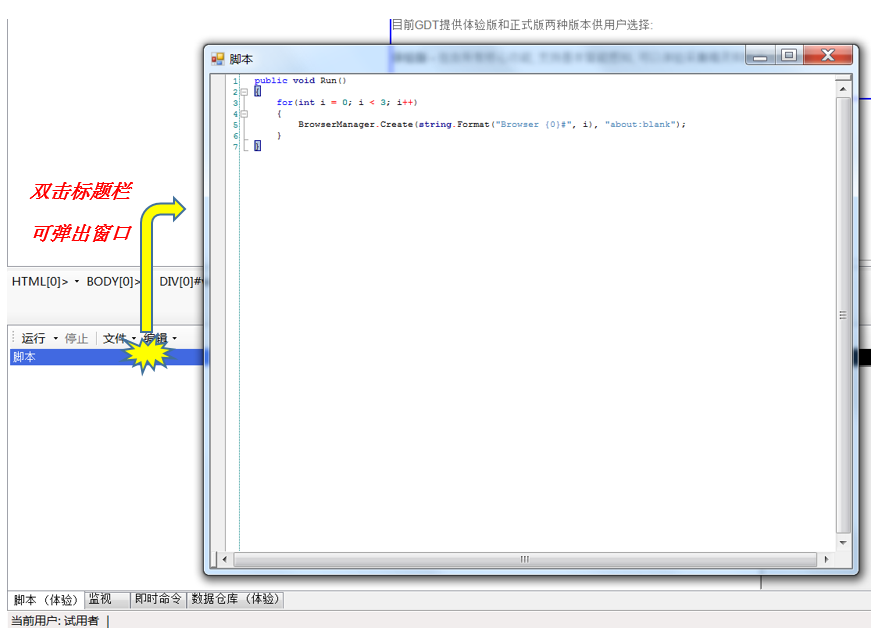
注: "采集输出" 窗口也提供了同样功能.
3.2.2. 脚本编辑器提供了代码智能感知的功能 (体验版只有最基本的)
3.2.3. CTRL + F 可以在脚本编辑器中查找; CTRL + H 是替换
3.3. 监视窗口
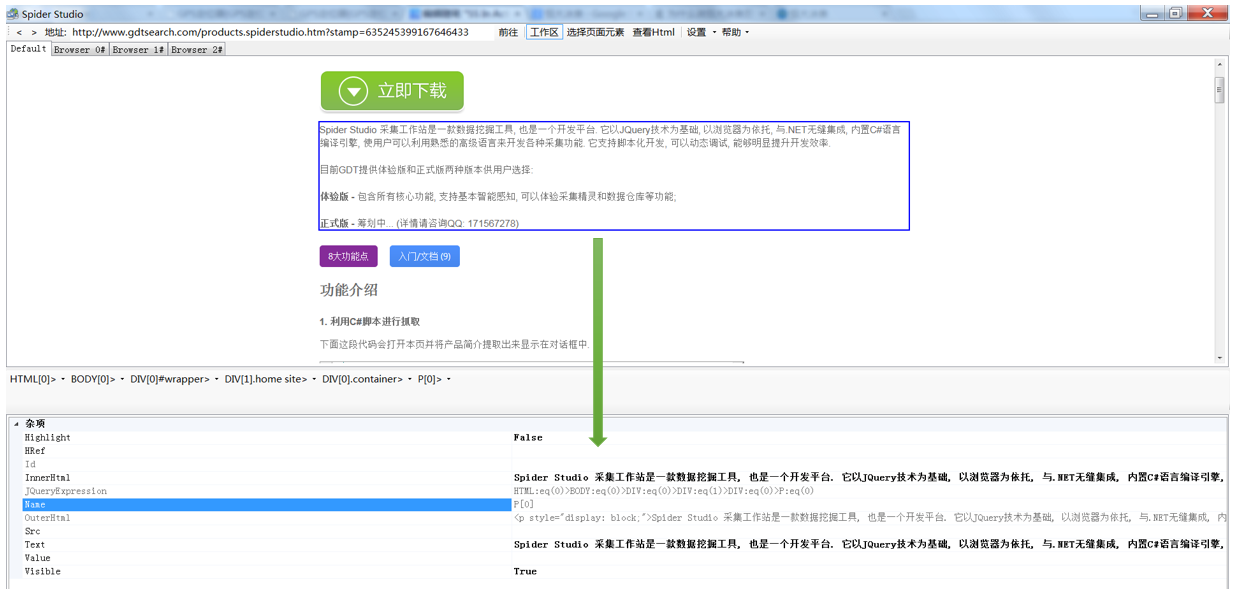
在节点选择器点击节点, 弹出菜单中的第一项就是 "监视", 点击之后就可以在监视窗口中看到详细信息, 如下:
3.4. 即时命令窗口
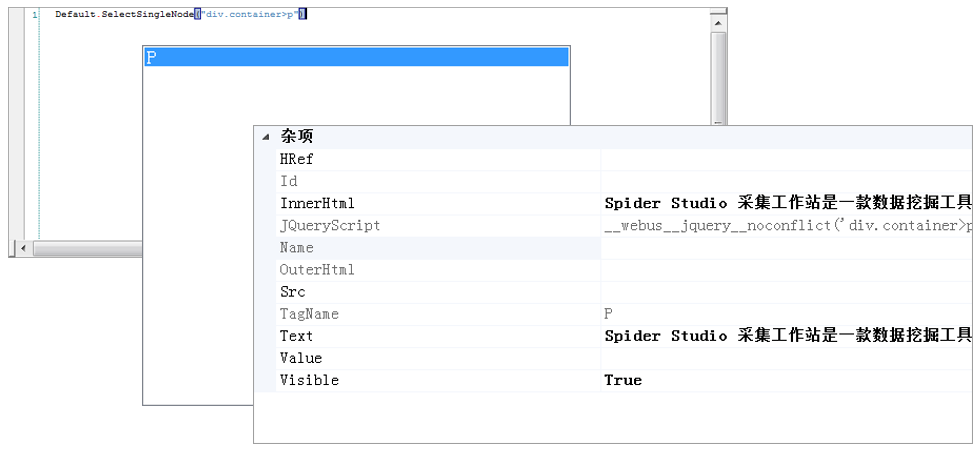
在即时命令窗口中我们可以编写简单代码片段并运行查看效果. 这个功能在编写脚本的时候非常有用, 可以让我们方便的测试自己使用的JQuery表达式是否有效:
3.5. 数据仓库管理界面
数据仓库也是SS中的一个重要模块, 它提供了一个非常方便的临时数据保存场所. 有时候我们需要编写多个脚本来完成采集任务, 十分典型的场景就是网站中有一种列表页面, 每页m个链接, 共n多页. 我们的目标是采集每一个链接的详细页面, 共m * n个. 为了快速完成采集, 我们会先行采集列表页面, 将所有链接保存在数据仓库中, 然后用采集精灵并行采集详细页面, 以最快的速度完成任务. 此时数据仓库除了能够保存所有链接外, 还能够通过游标来协调各个采集精灵同步工作.

利用管理界面, 我们能够新建数据集, 重置游标, 清空或删除数据集, 还能够导出为CSV或者XML文件.
SS还提供了一套API让我们可以从脚本访问数据仓库, 具体用法请阅读: API - 使用数据仓库 - 基础篇