一.索引是什么?
在说索引的概念前,我们分享一个小故事:
张三是一个整天玩游戏看视频的颓废大学生,有一天,它意识到不能这样下去,迟早会成为一个废人的。因此它想要改变自己,从读书开始,之前基本不看书的张三如今沉迷于各种各样的文学书籍,看过的书一本又一本,书逐渐多了起来,摆满了一个又一个的书架。
有一天,张三在手机看到某站中西游记的场景,想起了自己读过的四大名著,想重新回味回味,于是他从书架中一本一本找,这个书架没有,那就下一个书架...ok,终于找到了,但半个小时过去了,张三觉得找的太慢了,以后要是书越来越多,那要找的时间岂不是得花费更久啊!
于是张三想了一个办法,把书架分成A书架,B书架,C书架并按顺序依次排放好......接着把书名第一个中文拼音首字母作为书存放到哪一个书架的规范,比如《阿凡达》:阿 --> a,那么《阿凡达》j就放到A书架中,《毕加索》:毕 --> b,那《毕加索》就放到B书架.....
下一次,张三想回味《卢食传说》,根据 卢首字母L --> L书架,没一会儿就找到了,开心得像一个200斤的英国大力士,沉迷于书籍中。
OK,我们来梳理一下,张三在采取措施的前后对比:
》措施前:书和书架没有任何关系,书随便放,书架没有没有顺序,查找慢
》措施后:书和书架产生关系(书首字母放到对应书架),书架也有一定的摆放顺序,查找快
下面介绍索引:
》索引是一种数据结构!数据结构!数据结构!并且索引是它保存的数据排好序的数据结构,目的是为了提高查询的效率;类比到书和书架,有序的书(放到对应书架)和书架(按编号顺序摆放)就叫做索引,是的,索引包含两部分:数据(书)+特殊的结构(书架)。
》索引是一个抽象的概念,就类似java中接口,有多种不同的实现,比如:B+Tree,平衡二叉树,红黑树等等
》索引在计算机中,以文件的形式存在,即“索引文件”。
补充:很多人会把索引用作动词,对xxx进行索引,其实就是说对xxx建立索引,即 为数据建立有序的结构。
二.索引的工作原理
现在存在表Test,表的字段分别为:Col 1和Col 2,为该表的Col 2 字段添加索引。为了方便理解,假设索引采用的数据结构是二叉搜索树,则如下图:

我们要知道,MySQL数据库中的表中的数据是存储在磁盘上的。即该Test表的数据是存储在磁盘上的。如果我们有SQL语句:
SELECT Col1, Col2 FROM Test WHERE Col2 = 89;
现在要查找 Col 2 = 89 这条记录。CPU必须先去磁盘查找这条记录,将数据分批加载到内存中,在内存进行快速查询,找到数据后再对数据进行处理。这个过程最耗时间的就是磁盘I/O(查找记录到加载到内存的整个过程)
如果我们不借助任何索引结构把数据进行规范的话,我们查找Col 2 = 89 这条记录,就要逐行去查找、去比较。从Col 2 = 34 开始,一行一行得比较....我们当前的Test表只有不到10行数据,但如果表很大的话,有上千万条数据,就意味着要做很多很多次磁盘I/O才能找到。速度是很慢的。
所以,这就是我们为什么要建索引,目的就是为了减少磁盘I/O的次数 ,加快查询速率
现在我们给字段Col 2 添加了索引,就相当于在硬盘上为Col 2维护了一个索引的数据结构(索引文件),即这个二叉搜索树。二叉搜索树的每个结点存储的是(K,V)结构,key 是Col 2字段值,value 是该 key 所在行记录的文件指针(地址)。比如:该二叉搜索树的根节点就是:(34,0x07)。
现在对 Col 2 添加了索引,这时再去查找 Col 2 = 89 这条记录的时候会先去查找该二叉搜索树(二叉树的遍历查找)。读 34 到内存,89>34;读 89 到内存,89 == 89;找到了
找到之后就根据当前节点的value快速定位到要查找的记录对于的地址。我们可以发现,只需要查找两次就可以定位到记录的地址,查询速度就提高了。
三.Mysql存储引擎-InnoDB
在Mysql5.5后的存储引擎换成了InnoDB了,它对索引的实现是B+Tree。大家是不是有这样的一个疑问,为什么要用B+Tree实现索引,普通二叉树、平衡二叉树等不可以吗?答案是可以的,不过B+Tree是这些不断优化而得到,下面详细介绍下索引结构的优化的过程吧:
什么是二叉查找树?如下:
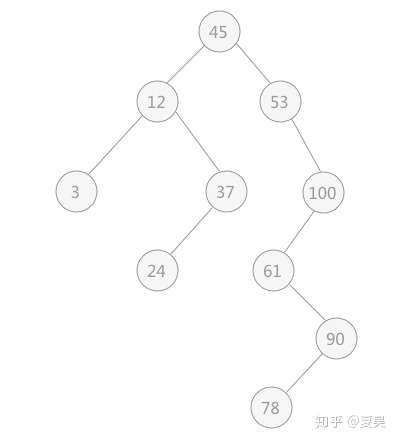
满足这样条件的就叫二叉查找树:
》每个节点左边节点的值都小于该节点,右边节点的值都大于该节点,没有值相等的节点,最顶端的节点也就是“45”被称为根节点。
二叉查找树的查找过程:若根结点的值等于查找的值,成功,否则,若小于根结点的值,递归查左子树(也就是根节点左边的所有节点形成的树)若大于根结点的值,递归查右子树(也就是根节点右边所有节点形成的树)。
假设用二叉查找树创建book表的索引:
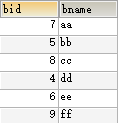
索引如下:
图一:
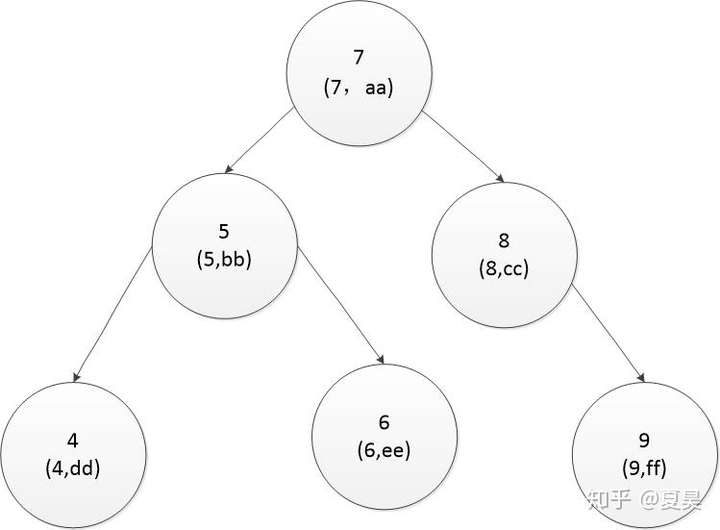
此处的bid为主键,每个节点存储了主键的值和该条记录的内容(地址)。
如果我要查找bid为6的图书的信息,则先用6和根节点的主键值7比较发现比7小,
然后6再和7左边的节点5比较发现比5大找到5右边的节点6,找到了,取出6对应的记录行的值ee.
总共经历了3次比较,如果扫描全表需要经过5次比较。
什么是平衡二叉树?
如果索引是这样:
图二:
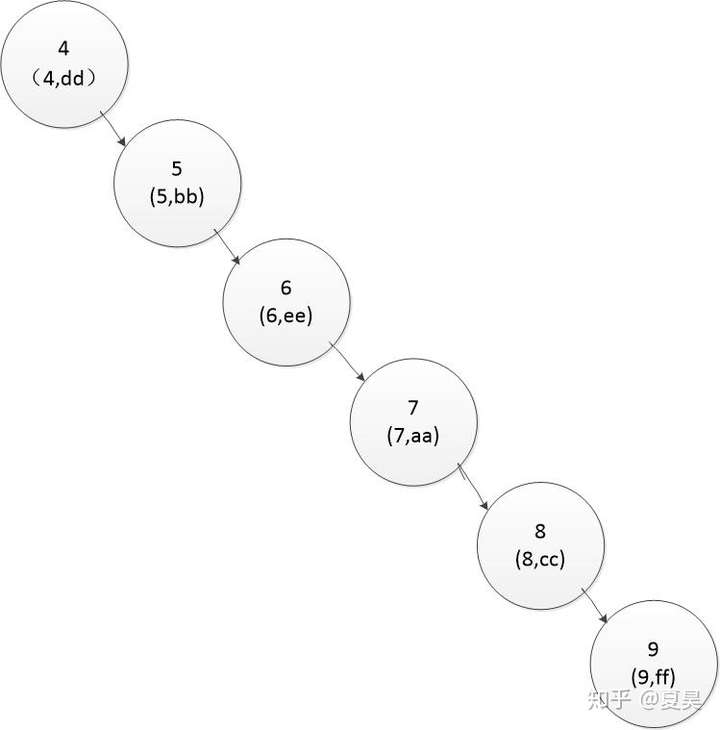
想要找到主键键值为9的记录就需要6次比较,此时查找二叉树的结构跟线性表基本没区别了,索引的优势完全体现不出来。
为什么会这样?原因就在于这棵树太高了,如果能想办法把它变得矮一点,胖一点就完美了。于是平衡二叉树闪亮登场:
平衡二叉树首先也是一个二叉树,需要满足二叉树的所有条件,然后有所改进,规定了左右子树的高度差不能超过1,如果插入数据导致高度差超过了1则自动进行调整(旋转),恢复到平衡状态。这也是平衡二叉树名字的由来。
图一就是一颗平衡二叉树,图二根节点的左子树高度为0,右子树高度为5,高度差是5超过了1所以不是一颗平衡二叉树。
平衡二叉树查找效率要高于二叉树。
什么是B树?
由前面的推导我们可以看出要想查找,比较的次数最少,必须想办法降低树形结构的高度,不管是二叉树还是平衡二叉树,每个节点最多只能有两个子节点,这就注定了它的高度会被子节点的个数所限制(允许拥有的子节点越多,在同样的数据量下,子节点越多的数高度越低),于是B树横空出世:
从上图可以看到B树的节点可以不止两个子节点,这样的好处就是树可以变得又矮又胖,矮胖的树是索引的最爱,用它做索引可以降低磁盘的IO(树高度越低,代表磁盘数据被读取到内存的次数越少,少一个高度就少读取一个磁盘块到内存).
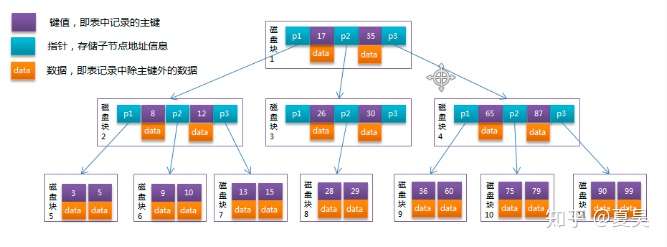
B树中的每个节点根据实际情况可以包含大量的键值,数据和指针,上图所示为一个3阶的B树:
每个节点占用一个磁盘块的空间,一个节点上有两个升序排序的键值和三个指向子树根节点的指针(只针对目前3阶的情况),指针存储的是子节点所在磁盘块的地址。两个键值划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,键值为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
模拟查找关键字29的过程:
根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
比较关键字29在区间(17,35),找到磁盘块1的指针P2。
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
比较关键字29在区间(26,30),找到磁盘块3的指针P2。
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
在磁盘块8中的关键字列表中找到关键字29。
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作。由于内存中的键值是一个有序表结构,如果数据很多,可以利用二分法查找极大提高效率。而3次磁盘I/O操作是影响整个B树查找效率的决定因素。
什么是B+树?
想想还有没有可能进一步优化,在B树中每个节点的内容由三部分组成:键值,指针,数据,而磁盘块的容量是有限的,并不是每次读取磁盘块都会取出里面的数据,只有在最后一次读取或者说找到所需要的数据后的时候才会取出里面的数据。那能不能将数据只存储在叶子节点里面,非叶子节点只存储键值和指针呢?这样的话非叶子节点就能存储更多的键值和指针了,最大化的利用磁盘块空间,没错,B+树就是这么干的:
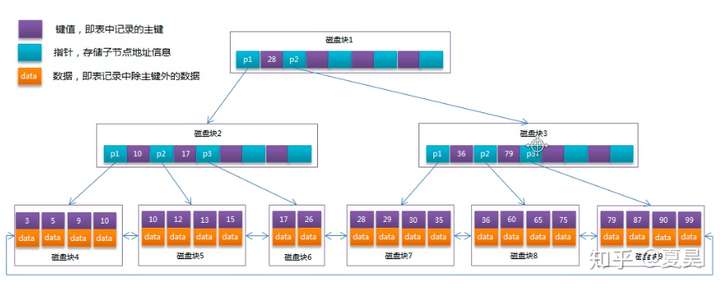
假设在非叶子节点不存数据以后每个节点可以存储4个键值和指针,就变成了上图的B+树
B+树相对于B树有几点不同:
- 非叶子节点只存储键值和指针。
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
在B+树中因为叶子节点的键值是按顺序排列的,所以进行键值的范围查找效率非常高。
在B+树中由于一个非叶子节点存储了更多的键值和指针,所以同样多的数据可以降低树的高度,减少磁盘io次数,从而提高效率。
四.聚集索引和非聚集索引
InnoDB要求表必须有主键(MyISAM可以没有),innodb会按照如下规则进行处理:
1,如果一个主键被定义了,那么这个主键就是作为聚集索引
2,如果没有主键被定义,那么该表的第一个唯一非空索引被作为聚集索引
3,如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,改列的值会随着数据的插入自增。
一般我们都会在表中加一个id的列作为主键,在上面树结构中应该有说过一个东西叫:键值。是的,主键的值就是作为键值。查找一个指定的id,在树结构中就是查找键值!
聚集索引:数据行的物理存储顺序和表中的逻辑顺序一致,一个表中只能存在一个聚集索引
事实上, 一个加了主键的表,并不能被称之为「表」。一个没加主键的表,它的数据会无序被放置在磁盘存储器上,一行一行的排列的很整齐, 跟我们认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。

上图就是带有主键的表(聚集索引)的结构图,其中树的所有结点(底部除外)的数据都是由主键字段中的数据构成,也就是通常我们指定主键的id字段。最下面部分是真正表中的数据。 假如我们执行一个SQL语句:
select * from table where id = 1256;
首先根据索引定位到1256这个值所在的叶结点,然后再通过叶结点取到id等于1256的数据行。 但是从上图能看出,树一共有三层, 从根节点至叶节点只需要经过三次查找就能得到结果。如下图:

假如一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,用大O标记法就是O(n)最坏时间复杂度,这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用, 因此, 这一亿次匹配在不经缓存优化的情况下就是一亿次IO开销,以现在磁盘的IO能力和CPU的运算能力, 有可能需要几个月才能得出结果 。如果把这张表转换成平衡树结构(一棵非常茂盛和节点非常多的树),假设这棵树有10层,那么只需要10次IO开销就能查找到所需要的数据, 速度以指数级别提升,用大O标记法就是O(log n),n是记录总树,底数是树的分叉数,结果就是树的层次数。换言之,查找次数是以树的分叉数为底,记录总数的对数,用公式来表示就是
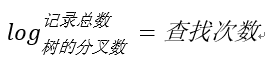
用程序来表示就是Math.Log(100000000,10),100000000是记录数,10是树的分叉数(真实环境下分叉数远不止10), 结果就是查找次数,这里的结果从亿降到了个位数。因此,利用索引会使数据库查询有惊人的性能提升。
然而, 事物都是有两面的, 索引能让数据库查询数据的速度上升, 而使写入数据的速度下降,原因很简单的, 因为平衡树这个结构必须一直维持在一个正确的状态, 增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, DBMS必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
非聚集索引:数据行的物理存储顺序和表中的逻辑顺序不同,一个表中可以建立多个非聚集索引
非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引的树结构就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。 如下图:

每次给字段建一个新索引(非聚集索引), 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据(行记录), 而通过非聚集索引可以查到记录对应的主键值 , 再使用刚才主键的值通过聚集索引查找到需要的数据,如下图:

不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。
部分资料来源:
https://www.zhihu.com/question/26113830
https://blog.csdn.net/better12038/article/details/100806721
https://zhuanlan.zhihu.com/p/23624390