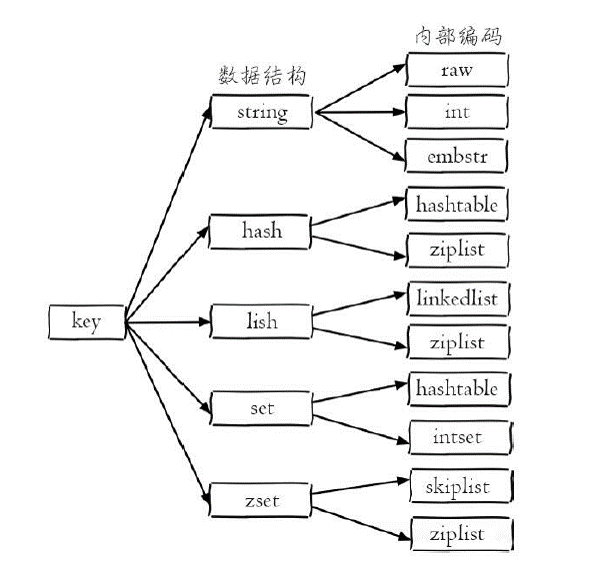
´RDB持久化是把当前进程数据生成快照保存到硬盘的过程,RDB文件保存在dir配置指定的目录下,触发RDB持久化过程分为手动触发和自动触发。
´手动触发:save,占用主进程,阻塞;bgsave,创建子进程,阻塞发生在fork子进程阶段,很短,推荐使用。
´自动触发:
1、使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。可配置多个。
2、如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点。
3、执行debug reload命令重新加载Redis时,也会自动触发save操作。
4、默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则自动执行bgsave。
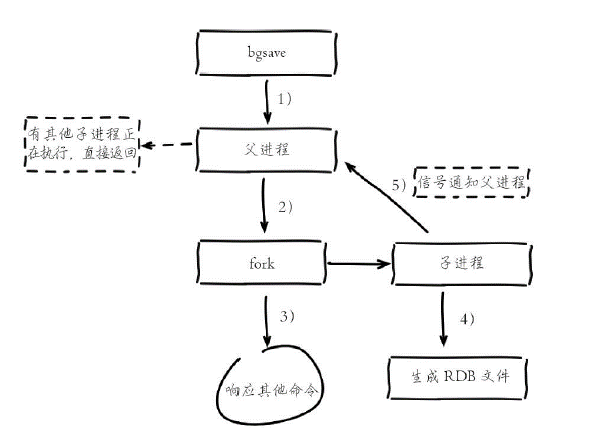
bgsave流程:
1)执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程,如果存在bgsave命令直接返回。
2)父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通过info stats命令查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒。
3)父进程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令。
4)子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行lastsave命令可以获取最后一次生成RDB的时间,对应info统计的rdb_last_save_time选项。
5)进程发送信号给父进程表示完成,父进程更新统计信息。
RDB优缺点
优点
´RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据快照。非常适用于备份,全量复制等场景。
´Redis加载RDB恢复数据远远快于AOF的方式。
缺点
´RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
´由于触发时机问题,不适合实时持久化。
AOF
´AOF(append only file)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
AOF文件同步策略
由config配置文件中appendfsync决定

´write操作会触发延迟写(delayed write)机制。Linux在内核提供页缓冲区用来提高硬盘IO性能。write操作在写入系统缓冲区后直接返回。同步硬盘操作依赖于系统调度机制,例如:缓冲区页空间写满或达到特定时间周期。同步文件之前,如果此时系统故障宕机,缓冲区内数据将丢失。
´fsync针对单个文件操作(比如AOF文件),做强制硬盘同步,fsync将阻塞直到写入硬盘完成后返回,保证了数据持久化。
´问题:AOF为什么把命令追加到aof_buf中?
Redis使用单线程响应命令,如果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负载。先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡。
AOF重写触发机制
´手动触发:直接调用bgrewriteaof命令。
´自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机,它底层也是调用bgrewriteaof。
´auto-aof-rewrite-min-size:表示运行AOF重写时文件最小体积,默认为64MB。
´auto-aof-rewrite-percentage:代表当前AOF文件空间(aof_current_size)和上一次重写后AOF文件空间(aof_base_size)的比值。
´自动触发时机=aof_current_size>auto-aof-rewrite-minsize&&(aof_current_size-aof_base_size)/aof_base_size>=auto-aof-rewritepercentage。
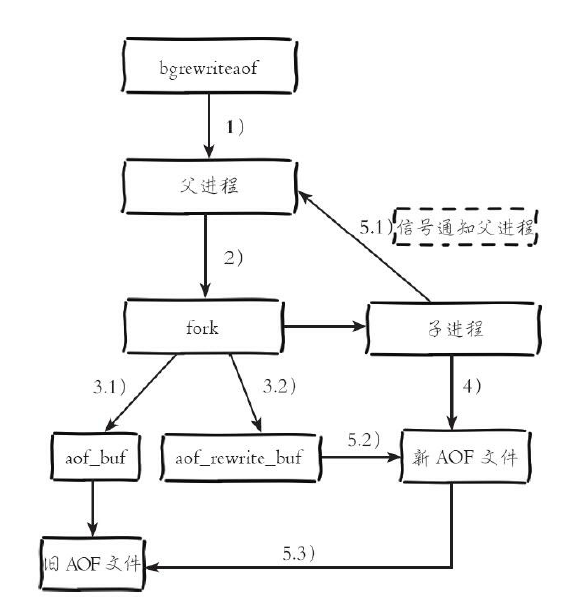
AOF bgrewriteof流程
1)执行AOF重写请求。
如果当前进程正在执行AOF重写,请求不执行并返回如下响应:
ERR Background append only file rewriting already in progress
334
如果当前进程正在执行bgsave操作,重写命令延迟到bgsave完成之后再
执行,返回如下响应:
Background append only file rewriting scheduled
2)父进程执行fork创建子进程,开销等同于bgsave过程。
3.1)主进程fork操作完成后,继续响应其他命令。所有修改命令依然写
入AOF缓冲区并根据appendfsync策略同步到硬盘,保证原有AOF机制正确
性。
3.2)由于fork操作运用写时复制技术,子进程只能共享fork操作时的内
存数据。由于父进程依然响应命令,Redis使用“AOF重写缓冲区”保存这部
分新数据,防止新AOF文件生成期间丢失这部分数据。
4)子进程根据内存快照,按照命令合并规则写入到新的AOF文件。每
次批量写入硬盘数据量由配置aof-rewrite-incremental-fsync控制,默认为
32MB,防止单次刷盘数据过多造成硬盘阻塞。
5.1)新AOF文件写入完成后,子进程发送信号给父进程,父进程更新
统计信息,具体见info persistence下的aof_*相关统计。
5.2)父进程把AOF重写缓冲区的数据写入到新的AOF文件。
5.3)使用新AOF文件替换老文件,完成AOF重写。
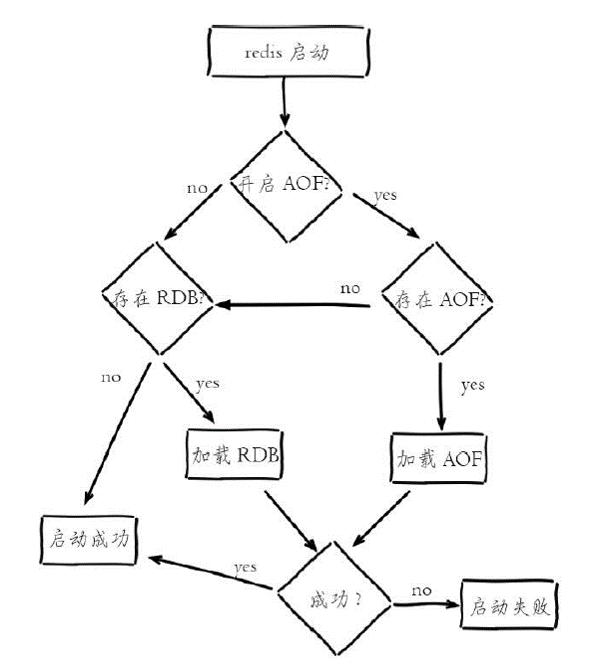
Redis重启加载过程
集群扩容
´步骤:准备新节点;加入集群;迁移槽和数据;加入新节点的从节点。
´redis-server redis-7006.conf,新启动一个节点
´redis-cli –a psw --cluster add-node 127.0.0.1:7006 127.0.0.1:7000,将新节点加入集群。
´redis-cli –a psw –p port cluster nodes,查看集群状态,发现新加入的node作为主节点还未分配槽。
´redis-cli --cluster reshard 127.0.0.1:7000,通过这条命令执行槽分配。
´redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 --cluster-slave --cluster-master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e,该条命令可用于将添加的新节点作为某个主节点的从节点。
´如果有空槽的节点已用第二步加进集群。可用以下指令来指定其主节点:
´redis-cli –a psw –p port; cluster replicate mastered
´问题:集群中主节点掉线后,会由其从节点选出一个作为新的主节点,旧主节点重新加入,会作为新主节点的从节点。
´问题:当一个主节点通过del-node命令移除后,它再次重启执行加入集群指令会报错,提示节点在集群中已知或存在数据。这个时候,需要先将该节点的以下数据移除:rdb文件,aof文件,cluster-config-file集群配置文件;移除文件后,重启该节点,再执行加入集群命令。
集群收缩
´首先确认是否是主节点,如果是从节点可以直接执行下线命令。
´redis-cli --cluster del-node 127.0.0.1:7000 `<node-id>`
´如果是主节点,如果主节点没有槽,则可以执行移除直接下线。
´如果主节点有分配的槽,则需要将其槽分配给其他主节点,没有槽后再下线,为了保证数据的完整性。
´下线的主节点如果有从节点,则会分配给集群中的一个主节点作为其从节点。
集群迁移
´1.Stop your clients. No automatic live-migration to Redis Cluster is currently possible. You may be able to do it orchestrating a live migration in the context of your application / environment.
´2.Generate an append only file for all of your N masters using the BGREWRITEAOF command, and waiting for the AOF file to be completely generated.
´3.Save your AOF files from aof-1 to aof-N somewhere. At this point you can stop your old instances if you wish (this is useful since in non-virtualized deployments you often need to reuse the same computers).
´4.Create a Redis Cluster composed of N masters and zero slaves. You'll add slaves later. Make sure all your nodes are using the append only file for persistence.
´5.Stop all the cluster nodes, substitute their append only file with your pre-existing append only files, aof-1 for the first node, aof-2 for the second node, up to aof-N.
´6.Restart your Redis Cluster nodes with the new AOF files. They'll complain that there are keys that should not be there according to their configuration.
´7.Use redis-cli --cluster fix command in order to fix the cluster so that keys will be migrated according to the hash slots each node is authoritative or not.
´8.Use redis-cli --cluster check at the end to make sure your cluster is ok.
´9.Restart your clients modified to use a Redis Cluster aware client library.