论文译文
大佬分析的原文
简洁分析
架构:
实际的VGG16(只算卷积和全连接层的个数为16)
(前两组conv-relu-conv-relu-pool,中间三组conv-relu-conv-relu-conv-relu-pool,最后三个fc,前两个fc是fc-relu-dropout,最后一个fc仅有fc 不对?????
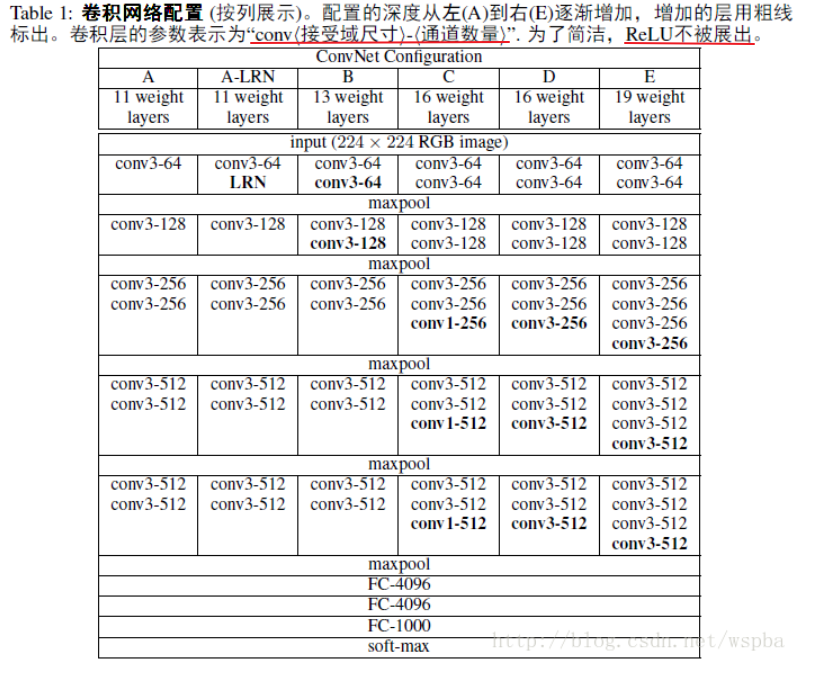
- LRN(Local Response Normalization)层(AlexNet中出现的),该层会对相邻的N个通道在同一 (x,y) 位置处的像素值进行normalize。VGGNet作者发现(实验A和A-LRN),LRN层对分类准确率不仅没有提升,还带来更多的显存占用和计算时间,因此在之后的四组(B、C、D、E)实验中均没有出现LRN层。
贡献:
1.小卷积核和stride全部替换为3×3(极少用了1×1)(受Zeiler & Fergus, 2013; Sermanet et al., 2014启发)
2.层数更深更宽(11层、13层、16层、19层)。反正参数量(because of小卷积核)我的gpu可以cover住,就试试depth说不定可以水文章(#.#)。
但应该再加入一下对宽度(channel)数分析对比的实验,6组实验中channel数都是逐层加宽的
3.池化核变小且为偶数。VGGNet中都是2×2的(小kernel带来的是更细节的信息捕获),(AlexNet全是3×3的),它们两个的stride都是2 。2×2带来的信息损失相比3×3的比较小,相比3×3更容易捕获细小的特征变化起伏(实验效果证明了鸭)
******4.
网络测试阶段将训练阶段的三个全连接替换为三个卷积。对于训练和测试一样的输入维度下,网络参数量没有变化,计算量也没有变化,思想来自OverFeat,1×1的卷积思想则来自NIN。优点在于全卷积网络可以接收任意尺度的输入(这个任意也是有前提的,长和宽都要满足:a×2n,n是卷积与池化做stride=2的下采样的次数);
******5.
刷比赛的小技巧。其实没什么意思,比方输入图片的尺寸对于训练和测试阶段的处理方式不同,single和multi-scale的问题(具体见后文)。
优秀泛化性证据:
在ImageNet预训练得到的模型,在其他小数据(VOC-2007、VOC-2012、Caltech-101、Caltech-256等图像分类任务)上发现优秀的泛化性能
(这部分来自本篇文章附录 Localization 的 Generation of Very Deep Features)
操作:
输入图像:尺寸为224×224的图像,输入前需要减去RGB均值(提前跑了一遍train set,resize到224并计算每个位置的强度均值)。下面是作者作的六组实验,观察深度、LRN、conv1x1的小卷积这三个因素对结果的影响。