内容概要:
1、为什么要限流
2、分布式限流解决方案
3、Guava实现令牌限流和漏桶限流
4、SpringBoot结合Redis实现分布式限流
5、SpringCloud GateWay网关限流---微服务SprignCloud 6、Nginx限流
为什么要限流
目标
学习在项目开发中为什么要使用限流技术,以及限流的作用。
概述
在分布式领域,我们难免会遇到并发量突增,对后端服务造成高压力,严重甚至会导致系统宕机。为避 免这种问题,我们通常会为接口添加限流、降级、熔断等能力,从而使接口更为健壮。Java领域常见的 开源组件有Netflix的hystrix,阿里系开源的sentinel等,都是蛮不错的限流熔断框架。
图解


在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。缓存的目的是提升系统访问速度和 增大系统能处理的容量,可谓是抗高并发流量的银弹;而降级是当服务出问题或者影响到核心流程的性 能则需要暂时屏蔽掉,待高峰或者问题解决后再打开;而有些场景并不能用缓存和降级来解决,比如稀 缺资源(秒杀、抢购)、写服务(如评论、下单)、频繁的复杂查询(评论的最后几页),因此需有一 种手段来限制这些场景的并发/请求量,即限流。
解决一个问题:保护、保证系统一定可用。
解决方案
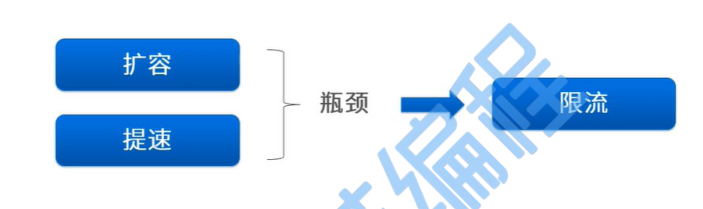
扩容
增加物理服务的硬件和设备。
缓存
缓存比较好理解,在大型高并发系统中,如果没有缓存数据库将分分钟被爆,系统也会瞬间瘫痪。使用 缓存不单单能够提升系统访问速度、提高并发访问量,也是保护数据库、保护系统的有效方式。大型网 站一般主要是“读”,缓存的使用很容易被想到。在大型“写”系统中,缓存也常常扮演者非常重要的角
色。比如累积一些数据批量写入,内存里面的缓存队列(生产消费),以及HBase写数据的机制等等也 都是通过缓存提升系统的吞吐量或者实现系统的保护措施。甚至消息中间件,你也可以认为是一种分布 式的数据缓存。
降级
服务降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以 此释放服务器资源以保证核心任务的正常运行。降级往往会指定不同的级别,面临不同的异常等级执行 不同的处理。根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。根据服务范围: 可以砍掉某个功能,也可以砍掉某些模块。总之服务降级需要根据不同的业务需求采用不同的降级策 略。主要的目的就是服务虽然有损但是总比没有好。
限流
限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量已达到保护系统的目的。一般来说 系统的吞吐量是可以被测算的,为了保证系统的稳定运行,一旦达到的需要限制的阈值,就需要限制流 量并采取一些措施以完成限制流量的目的。比如:延迟处理,拒绝处理,或者部分拒绝处理等等。
限流的目的
限流的目的是通过对并发访问/请求进行限速或者一个时间窗口内的的请求进行限速来保护系统,一旦 达到限制速率则可以拒绝服务(定向到错误页或告知资源没有了)、排队或等待(比如秒杀、评论、下 单)、降级(返回兜底数据或默认数据,如商品详情页库存默认有货)。
一般开发高并发系统常见的限流有:限制总并发数(比如数据库连接池、线程池)、限制瞬时并发数
(如nginx的limit_conn模块,用来限制瞬时并发连接数)、限制时间窗口内的平均速率(如Guava的RateLimiter、nginx的limit_req模块,限制每秒的平均速率);其他还有如限制远程接口调用速率、限 制MQ的消费速率。另外还可以根据网络连接数、网络流量、CPU或内存负载等来限流。
先有缓存这个银弹,后有限流来应对618、双十一高并发流量,在处理高并发问题上可以说是如虎添 翼,不用担心瞬间流量导致系统挂掉或雪崩,最终做到有损服务而不是不服务;限流需要评估好,不可 乱用,否则会正常流量出现一些奇怪的问题而导致用户抱怨。
保护、保证系统和网站的正常运行。
使用场景
秒杀、抢购,年底查询密集,评论查询。
SpringBoot结合Redis实现分布式限流演进
目标
为什么使用分布式限流解决方案,整个过程是如何来的。

步骤
1:搭建springboot框架
2:导入web依赖,和guava依赖,以及redis依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency>
3:最简单的限流讲解---计数器限流
package com.itheima.limiting.web; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class OrderController { // 抢购,抢购数量,也就限流的阈值 static long limit = 10; // 计算器,代表请求的用户数量 private long count = 0; @GetMapping("/makeorder") public String makeOrder(){ long c = ++count; if(c > limit){ return "抢购结束,下次在来! count = " + c; } return "恭喜,抢购成功,count = " + c; } }
存在问题:
1:当前count没有标记成为static。需要标记成static吗?答案是不需要,因为 @RestController 标记当前类是单例的, 所以在内存中count只有一份,不会出现所谓的多份问题。而是共用的一个计数器。
2:往往在分布式集群的项目中,项目是部署多多台,是多个 jvm。每个jvm都又自己的计数器,这个时候就会引发高并发带来的线程安全问题。
3:那可以使用volatile 吗?答案是不可以。因为volatile只保证成员变量在线程见的可见性,它不保证线程安全。
4:如果线程不安全可以使用synchronized ,这种是没问题的,可以解决线程安全的问题。但是同时带
@GetMapping("/makeorder")
public synchronized String makeOrder(){
long c = ++count;
if(c > limit){
return "抢购结束,下次在来! count = " + c; 6 }
return "恭喜,抢购成功,count = " + c; 8 }
来的隐患就是:性能低下,这个是必然的,如果使用了synchronized关键字,就是上了锁,代码的执行 就编程了串行,一大推的阻塞,如果这个时候又1w的并发,这个时候处理都会造成大量的阻塞。而且 性能极低。在一般的开发中我们都会认为和代码是不适合的。也满足不了我们高并发的需要。那么进行 优化,如何解决呢?原子类。
5:如果在分布式环境下呢?
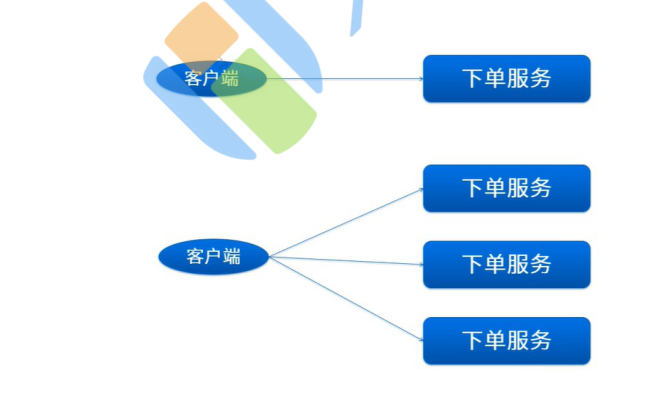
可以使用分布式缓存来解决这个问题:
为什么不用Lock和synchronized,在单机环境下,是没有问题,但是往往在开发中,大部分情况下是集 群环境,这个适合每个电脑都是独立JVM环境,你是没有办法去控制别人jvm内存中的东西,所以我们 要计数器进行共享。
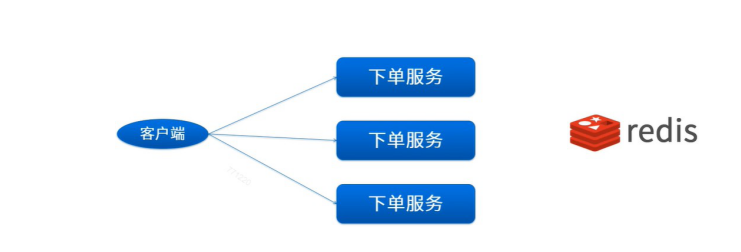
为什么选择Redis呢?而不是memcache操作呢?
答案很简单:Redis单线程。(基于linux的io模型来架构的,EPOLL 异步IO BIO NIO EPOLL ) jedis redission

代码如下:
引入依赖:
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.1.0</version> </dependency>
@GetMapping("makeorder2")
public String makeOrder2(String name){
// 从jedis上获取自增值
try(Jedis jedis = new Jedis("localhost",6379)){
long c = jedis.incr(name);
if(c > limit){
return "抢购结束,下次在来! count = " + c; 8 }
return "恭喜,抢购成功,count = " + c; 10 }
11 }
测试:启动8080和8081两个端口:访问
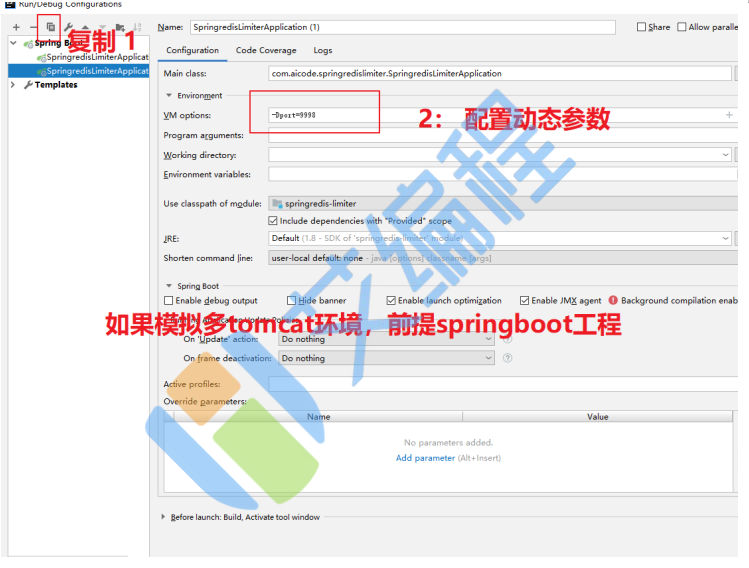
http://localhost:8081/makeorder2?name=lisi 和 http://localhost:8080/makeorder2?name=lisi 模 拟同一个用户在集群环境下的并发问是否共享计数器。答案很明显是可以的。

限流接口的时间窗请求数--时间窗限流
概述
即一个时间窗口内的请求数,如需限制某个接口/服务每秒/每分钟/每天的请求数/调用量。
如果实现呢?
Guava---单机系统
使用LoadingCache限流
package com.itheima.limiting.web; import com.google.common.cache.CacheBuilder; import com.google.common.cache.CacheLoader; import com.google.common.cache.LoadingCache; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; import redis.clients.jedis.Jedis; import java.util.Calendar; import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicLong; @RestController public class OrderGuavaController { // 抢购,抢购数量,也就限流的阈值 static long limit = 5; // 限时间窗请求数,限制5r/s LoadingCache<Long,AtomicLong> loadingCache = CacheBuilder.newBuilder().expireAfterAccess(2, TimeUnit.SECONDS) .build(new CacheLoader<Long, AtomicLong>() { @Override public AtomicLong load(Long aLong) throws Exception { return new AtomicLong(0); } }); @GetMapping("/makeorder3") public String makeOrder() throws Exception{ // 当前秒 long currentTime = System.currentTimeMillis()/1000L; //long c = atomicLong.incrementAndGet(); long c = loadingCache.get(currentTime).incrementAndGet(); if(c > limit){ return "抢购结束,下次在来! count = " + c; } return "恭喜,抢购成功,count = " + c; } }
package com.itheima.limiting.limiter; import java.util.HashMap; import java.util.Map; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ConcurrentMap; import java.util.concurrent.atomic.AtomicLong; public class MyLimiter { private ConcurrentMap<Long, AtomicLong> map = new ConcurrentHashMap<> (); private long before; public MyLimiter(long before){ super(); this.before = before; } public AtomicLong get(long key){ if(!this.map.containsKey(key)){ synchronized (map){ if(!this.map.containsKey(key)){ map.put(key,new AtomicLong(0L)); // 移除指定秒数的计数器 this.removeBeforeKey(key); } } } return this.map.get(key); } private void removeBeforeKey(long ckey){ for(Long key : this.map.keySet()){ // 把哪些超过时间的key,从map中移除出去。 if(key + before < ckey){ this.map.remove(key); } } } }
package com.itheima.limiting.web; import com.google.common.cache.CacheBuilder; import com.google.common.cache.CacheLoader; import com.google.common.cache.LoadingCache; import com.itheima.limiting.limiter.MyLimiter; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; import redis.clients.jedis.Jedis; import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicLong; @RestController public class OrderRedisController { // 抢购,抢购数量,也就限流的阈值 static long limit = 5; public String makeorder6(String name) throws Exception{ try (Jedis jedis = new Jedis("localhost",6379)){ long c = jedis.incr(name); if(c > limit){ return (System.currentTimeMillis()/1000)+"抢购结束,下次在来! count = " + c; }else{ if(c==1){ // 设置过期时间 jedis.expire(name,1); } } return (System.currentTimeMillis()/1000) + "恭喜,抢购成功,count = " + c; } } }
local key = KEYS[1] --限流Key(一秒一个) local limit = tonumber(ARGV[1]) --限流大小 local expire = ARGV[2] --过期时间 -- 获取当前计数器的值 local current = tonumber(redis.call('get',key) or "0") -- 如果超过限制大小 if current + 1 > limit then return 0 Redis处理类 测试用例 else current = tonumber(redis.call('INCRBY',key,"1")) --请求数+1 if current == 1 then --如果是第一次访问需要设置过期时间 redis.call("expire",key,expire) --设置过期时间 end end return 1 --返回1代表不限流
package com.itheima.limiting.limiter; import com.google.common.io.Files; import org.springframework.core.io.ClassPathResource; import redis.clients.jedis.Jedis; import java.nio.charset.Charset; public class JedisLuaLimiter { private String luascript; private String key; private String limit; private String expire; public JedisLuaLimiter(String key,String limit,String expire,String scriptFile){ super(); this.key = key; this.limit = limit; this.expire = expire; try{ this.luascript = Files.asCharSource(new ClassPathResource(scriptFile).getFile(), Charset.defaultCharset()).read(); }catch(Exception ex){ ex.printStackTrace(); } } // 尝试获取 public boolean tryAcqure(){ Jedis jedis = new Jedis("localhost",6379); return (Long)jedis.eval(this.luascript,1,key,limit,expire) == 1L; } }
测试用例
package com.itheima.limiting; import com.itheima.limiting.web.OrderRedisController; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import java.util.concurrent.CountDownLatch; import java.util.concurrent.CyclicBarrier; import java.util.concurrent.TimeUnit; @SpringBootTest class LimitingApplicationTests { @Autowired private OrderRedisController orderRedisController; @Test void contextLoads() throws Exception { // 倒计数锁存器 CountDownLatch countDownLatch = new CountDownLatch(50); // 循环屏障 CyclicBarrier cyclicBarrier = new CyclicBarrier(50); for (int i = 0; i < 50; i++) { new Thread(()->{ try{ cyclicBarrier.await(); }catch(Exception ex){ ex.printStackTrace(); } try { System.out.println(Thread.currentThread().getName() + "===" + orderRedisController.makeorder6("aicode111")); }catch (Exception ex){ ex.printStackTrace(); } countDownLatch.countDown(); }).start(); } try{ countDownLatch.await(); }catch(Exception ex){ ex.printStackTrace(); } TimeUnit.SECONDS.sleep(1); System.out.println(Thread.currentThread().getName() + "===" + orderRedisController.makeorder6("aicode111")); } }
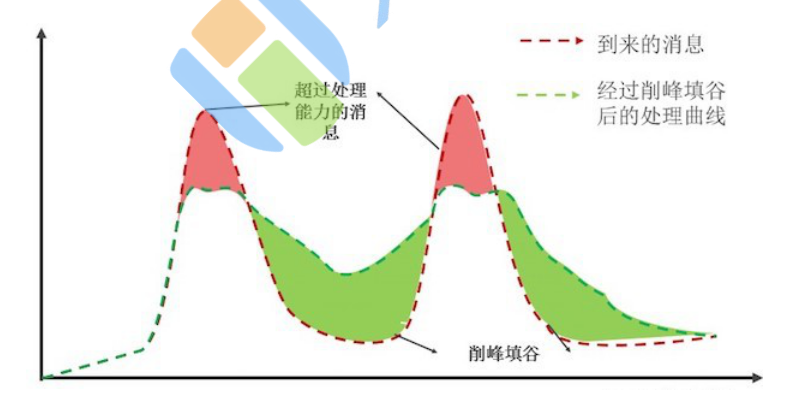
上图中,红色的部分代表超出消息处理能力的部分。把红色部分的消息平均到之后的空闲时间去处理, 这样既可以保证系统负载处在一个稳定的水位,又可以尽可能地处理更多消息。通过配置流控规则,可 以达到消息匀速处理的效果。
AHAS 流控降级的排队等待功能,可以把骤增的大量请求匀速分配,以固定的间隔时间让请求通过,起到“削峰填谷”的效果,从而避免流量骤增造成系统负载过高的情况。堆积的请求将会被排队处理,当请 求的预计排队时间超过最大超时时长时,AHAS 将拒绝这部分超时的请求。
例如:配置匀速模式下请求 QPS 为 5,则每 200 ms 处理一条请求,多余的处理任务将排队;同时设置了超时时间为 5s,则预计排队时长超过 5s 的处理任务将被直接拒绝。具体操作步骤,参见新建流控规则。
示意图如下:

问题
突发请求,流量整形,整形为匀速请求处理,(比如 5r/s 时间间隔200毫秒处理一个请求,平滑速率).
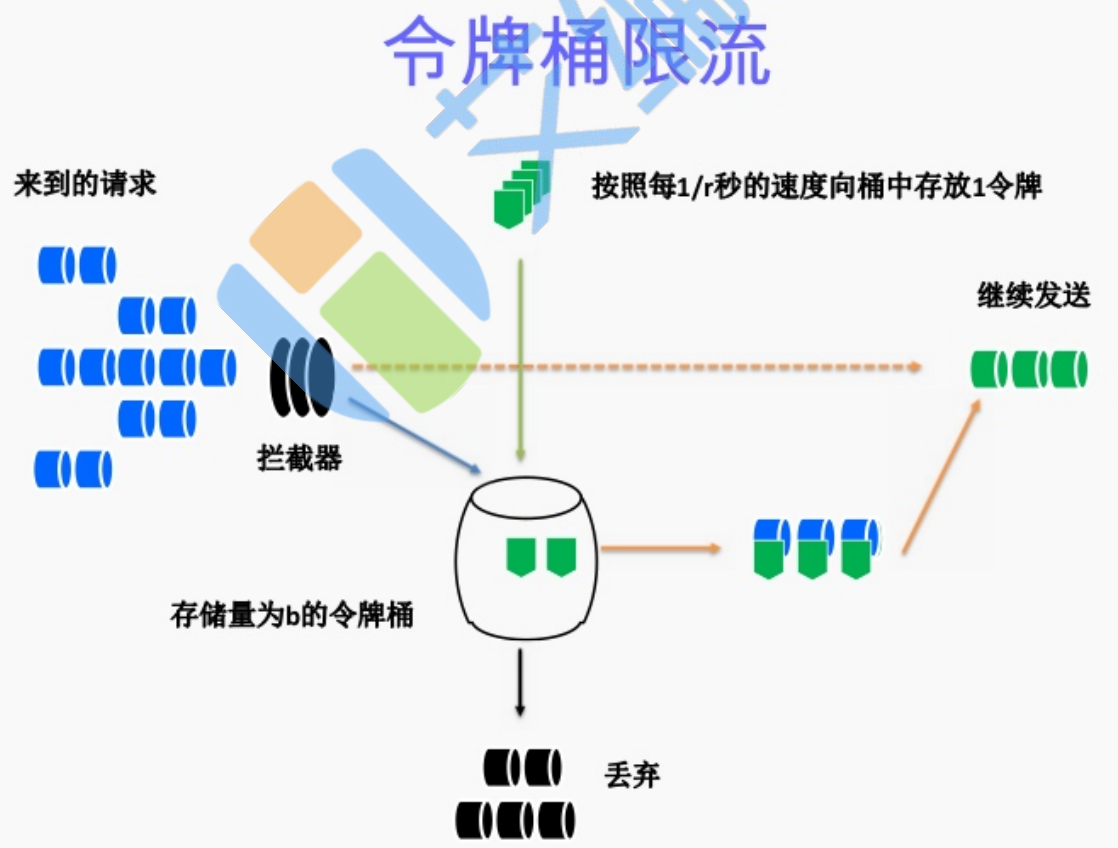
解决方案:令牌桶算法

package com.itheima.limiting.web; import com.google.common.util.concurrent.RateLimiter; import com.itheima.limiting.limiter.JedisLuaLimiter; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class OrderGuavaRateLimitController { // 平滑限流请求 RateLimiter rateLimiter = RateLimiter.create(4); //@GetMapping("/makeorder7") public String makeorder7() throws Exception{ if(!rateLimiter.tryAcquire()){
测试代码
package com.itheima.limiting; import com.itheima.limiting.web.OrderGuavaRateLimitController; import com.itheima.limiting.web.OrderRedisController; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import java.util.concurrent.CountDownLatch; import java.util.concurrent.CyclicBarrier; import java.util.concurrent.TimeUnit; @SpringBootTest class LimitingApplicationTests { @Autowired private OrderRedisController orderRedisController; @Autowired private OrderGuavaRateLimitController orderGuavaRateLimitController; @Test void contextLoads() throws Exception { // 倒计数锁存器 CountDownLatch countDownLatch = new CountDownLatch(50); // 循环屏障 CyclicBarrier cyclicBarrier = new CyclicBarrier(50); for (int i = 0; i < 50; i++) { new Thread(()->{ try{ cyclicBarrier.await(); }catch(Exception ex){ ex.printStackTrace(); } try { //System.out.println(Thread.currentThread().getName() + "===" + orderRedisController.makeorder6("aicode111")); System.out.println(Thread.currentThread().getName() + "===" + orderGuavaRateLimitController.makeorder7()); }catch (Exception ex){ ex.printStackTrace(); } 自定义令牌桶算法 countDownLatch.countDown(); }).start(); } try{ countDownLatch.await(); }catch(Exception ex){ ex.printStackTrace(); } TimeUnit.SECONDS.sleep(1); // System.out.println(Thread.currentThread().getName() + "===" + orderRedisController.makeorder6("aicode111")); System.out.println(Thread.currentThread().getName() + "===" + orderGuavaRateLimitController.makeorder7()); } }
package com.itheima.limiting.limiter; import java.util.Timer; import java.util.TimerTask; import java.util.concurrent.Semaphore; public class MyRateLimiter implements AutoCloseable{ // 定义信号量 并发协同工具 private Semaphore semaphore; // 限制数量 private int limit; // 定时器 private Timer timer; public MyRateLimiter(int limit){ super(); this.limit = limit; this.semaphore = new Semaphore(limit); this.timer = new Timer(); // 放入令牌的时间间隔 long period = 1000L/limit; // 通过定时器。定时放入令牌 timer.scheduleAtFixedRate(new TimerTask() { @Override public void run() { if(semaphore.availablePermits() < limit){ semaphore.release(); 漏桶算法 SpringBoot 结合Aop完成限流策略 原理 首先解释下为何采用Redis作为限流组件的核心。 通俗地讲,假设一个用户(用IP判断)每秒访问某服务接口的次数不能超过10次,那么我们可以在 Redis中创建一个键,并设置键的过期时间为60秒。 当一个用户对此服务接口发起一次访问就把键值加1,在单位时间(此处为1s)内当键值增加到10的时 候,就禁止访问服务接口。PS:在某种场景中添加访问时间间隔还是很有必要的。我们本次不考虑间隔 时间,只关注单位时间内的访问次数。 需求 } } },period,period); } public void acquire() throws InterruptedException{ this.semaphore.acquire(); } public boolean tryAcquire(){ return this.semaphore.tryAcquire(); } public int availablePermits(){ return this.semaphore.availablePermits(); } @Override public void close(){ System.out.println("自动来关闭了.............."); this.timer.cancel(); } }
1 @GetMapping("/makeorder")
2 public synchronized String makeOrder(){
3 long c = ++count;
4 if(c > limit){
5 return "抢购结束,下次在来! count = " + c; 6}
7return"恭喜,抢购成功,count = " + c; 8}
SpringBoot 结合Aop完成限流策略
首先解释下为何采用Redis作为限流组件的核心。
通俗地讲,假设一个用户(用IP判断)每秒访问某服务接口的次数不能超过10次,那么我们可以在
Redis中创建一个键,并设置键的过期时间为60秒。
当一个用户对此服务接口发起一次访问就把键值加1,在单位时间(此处为1s)内当键值增加到10的时 候,就禁止访问服务接口。PS:在某种场景中添加访问时间间隔还是很有必要的。我们本次不考虑间隔 时间,只关注单位时间内的访问次数。
原理已经讲过了,说下需求。
1. 基于Redis的incr及过期机制开发
1. Redis整合
由于我们是基于Redis进行的限流操作,因此需要整合Redis的类库,上面已经讲到,我们是基于
Springboot进行的开发,因此这里可以直接整合RedisTemplate。
1.1 坐标引入
这里我们引入spring-boot-starter-redis的依赖。
到这里,我们正式开始手写限流组件的进程。
项目基于maven构建,主要依赖Spring-boot-starter,我们主要在springboot上进行开发,因此自定义 的开发包可以直接依赖下面这个坐标,方便进行包管理。版本号自行选择稳定版。
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <version>1.4.2.RELEASE</version> </dependency>
2、Redis整合
由于我们是基于Redis进行的限流操作,因此需要整合Redis的类库,上面已经讲到,我们是基于
Springboot进行的开发,因此这里可以直接整合RedisTemplate。
1.1 坐标引入
这里我们引入spring-boot-starter-redis的依赖。
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-redis</artifactId> <version>1.4.2.RELEASE</version> </dependency>
@Configuration @EnableCaching public class RedisCacheConfig { private static final Logger LOGGER = LoggerFactory.getLogger(RedisCacheConfig.class); @Bean public CacheManager cacheManager(RedisTemplate<?, ?> redisTemplate) { CacheManager cacheManager = new RedisCacheManager(redisTemplate); if (LOGGER.isDebugEnabled()) { LOGGER.debug("Springboot Redis cacheManager 加载完成"); } return cacheManager; } @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { RedisTemplate<String, Object> template = new RedisTemplate<>(); template.setConnectionFactory(factory); //使用Jackson2JsonRedisSerializer来序列化和反序列化redis的value值 (默认使用JDK的序列化方式) Jackson2JsonRedisSerializer serializer = new Jackson2JsonRedisSerializer(Object.class); ObjectMapper mapper = new ObjectMapper(); mapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); mapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); serializer.setObjectMapper(mapper); template.setValueSerializer(serializer); //使用StringRedisSerializer来序列化和反序列化redis的key值 template.setKeySerializer(new StringRedisSerializer()); template.afterPropertiesSet(); LOGGER.info("Springboot RedisTemplate 加载完成"); return template; } }
#单机模式redis spring.redis.host=127.0.0.1 spring.redis.port=6379 spring.redis.pool.maxActive=8 spring.redis.pool.maxWait=-1 spring.redis.pool.maxIdle=8 spring.redis.pool.minIdle=0 spring.redis.timeout=10000 spring.redis.password=
#哨兵集群模式 # database name spring.redis.database=0 # server password 密码,如果没有设置可不配 spring.redis.password= # pool settings ...池配置 spring.redis.pool.max-idle=8 spring.redis.pool.min-idle=0 spring.redis.pool.max-active=8 spring.redis.pool.max-wait=-1 # name of Redis server 哨兵监听的Redis server的名称 spring.redis.sentinel.master=mymaster # comma-separated list of host:port pairs 哨兵的配置列表 spring.redis.sentinel.nodes=127.0.0.1:26379,127.0.0.1:26479,127.0.0.1:26579
/** * @author snowalker * @version 1.0 * @date 2018/10/27 1:25 * @className RateLimiter * @desc 限流注解 */ @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface RateLimiter { /** * 限流key * @return */ String key() default "rate:limiter"; /** * 单位时间限制通过请求数 * @return */long limit() default 10; /** * 过期时间,单位秒 * @return */ long expire() default 1; }
@Aspect @Component public class RateLimterHandler { private static final Logger LOGGER = LoggerFactory.getLogger(RateLimterHandler.class); @Autowired RedisTemplate redisTemplate; private DefaultRedisScript<Long> getRedisScript; @PostConstruct public void init() { getRedisScript = new DefaultRedisScript<>(); getRedisScript.setResultType(Long.class); getRedisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("rateLimter.lua"))); LOGGER.info("RateLimterHandler[分布式限流处理器]脚本加载完成"); }
@Pointcut("@annotation(com.snowalker.shield.ratelimiter.core.annotation.RateL
imiter)")
public void rateLimiter() {}
1 @Around("@annotation(rateLimiter)")
这段代码的逻辑为,获取 @RateLimiter 注解配置的属性:key、limit、expire,并通过
redisTemplate.execute(RedisScript script, List keys, Object... args) 方法传递给Lua脚本进行限
流相关操作,逻辑很清晰。
这里我们定义如果脚本返回状态为0则为触发限流,1表示正常请求。
5. Lua脚本
public Object around(ProceedingJoinPoint proceedingJoinPoint,
RateLimiter rateLimiter) throws Throwable {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("RateLimterHandler[分布式限流处理器]开始执行限流操
作");
}
Signature signature = proceedingJoinPoint.getSignature();
if (!(signature instanceof MethodSignature)) {
throw new IllegalArgumentException("the Annotation
@RateLimter must used on method!");
}
/**
* 获取注解参数
*/
// 限流模块key
String limitKey = rateLimiter.key();
Preconditions.checkNotNull(limitKey);
// 限流阈值
long limitTimes = rateLimiter.limit();
// 限流超时时间
long expireTime = rateLimiter.expire();
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("RateLimterHandler[分布式限流处理器]参数值为-
limitTimes={},limitTimeout={}", limitTimes, expireTime);
}
/**
* 执行Lua脚本
*/
List<String> keyList = new ArrayList();
// 设置key值为注解中的值
keyList.add(limitKey);
/**
* 调用脚本并执行
*/
Long result = (Long) redisTemplate.execute(getRedisScript,
keyList, expireTime, limitTimes);
if (result == 0) {
String msg = "由于超过单位时间=" + expireTime + "-允许的请求次数
=" + limitTimes + "[触发限流]";
LOGGER.debug(msg);
return "false";
}
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("RateLimterHandler[分布式限流处理器]限流执行结果-
result={},请求[正常]响应", result);
}
return proceedingJoinPoint.proceed();
}
}
5. Lua脚本
--获取KEY local key1 = KEYS[1] local val = redis.call('incr', key1) local ttl = redis.call('ttl', key1) --获取ARGV内的参数并打印 local expire = ARGV[1] local times = ARGV[2] redis.log(redis.LOG_DEBUG,tostring(times)) redis.log(redis.LOG_DEBUG,tostring(expire)) redis.log(redis.LOG_NOTICE, "incr "..key1.." "..val); if val == 1 then redis.call('expire', key1, tonumber(expire)) else if ttl == -1 then redis.call('expire', key1, tonumber(expire)) end end if val > tonumber(times) then return 0 end return 1
测试
@Controller public class TestController { private static final Logger LOGGER = LoggerFactory.getLogger(TestController.class); @ResponseBody @RequestMapping("ratelimiter") @RateLimiter(key = "ratedemo:1.0.0", limit = 5, expire = 100) public String sendPayment(HttpServletRequest request) throws Exception { return "正常请求"; } }
2018-10-28 00:00:00.602 DEBUG 17364 --- [nio-8888-exec-1] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]开始执行限流操作 2018-10-28 00:00:00.688 DEBUG 17364 --- [nio-8888-exec-1] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]限流执行结果-result=1,请求[正常]响应 2018-10-28 00:00:00.860 DEBUG 17364 --- [nio-8888-exec-3] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]开始执行限流操作 2018-10-28 00:00:01.183 DEBUG 17364 --- [nio-8888-exec-4] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]开始执行限流操作 2018-10-28 00:00:01.520 DEBUG 17364 --- [nio-8888-exec-3] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]限流执行结果-result=1,请求[正常]响应 2018-10-28 00:00:01.521 DEBUG 17364 --- [nio-8888-exec-4] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]限流执行结果-result=1,请求[正常]响应 2018-10-28 00:00:01.557 DEBUG 17364 --- [nio-8888-exec-5] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]开始执行限流操作 2018-10-28 00:00:01.558 DEBUG 17364 --- [nio-8888-exec-5] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]限流执行结果-result=1,请求[正常]响应 2018-10-28 00:00:01.774 DEBUG 17364 --- [nio-8888-exec-7] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]开始执行限流操作 2018-10-28 00:00:02.111 DEBUG 17364 --- [nio-8888-exec-8] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]开始 2018-10-28 00:00:02.169 DEBUG 17364 --- [nio-8888-exec-7] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]限流执行结果-result=1,请求[正常]响应 2018-10-28 00:00:02.169 DEBUG 17364 --- [nio-8888-exec-8] c.s.s.r.core.handler.RateLimterHandler : 由于超过单位时间=100-允许的请求次数=5[触发限流] 2018-10-28 00:00:02.276 DEBUG 17364 --- [io-8888-exec-10] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]开始执行限流操作 2018-10-28 00:00:02.276 DEBUG 17364 --- [io-8888-exec-10] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]参数值为-limitTimes=5,limitTimeout=100 2018-10-28 00:00:02.278 DEBUG 17364 --- [io-8888-exec-10] c.s.s.r.core.handler.RateLimterHandler : 由于超过单位时间=100-允许的请求次数=5[触发限流] 2018-10-28 00:00:02.445 DEBUG 17364 --- [nio-8888-exec-2] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]开始执行限流操作 2018-10-28 00:00:02.445 DEBUG 17364 --- [nio-8888-exec-2] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]参数值为-limitTimes=5,limitTimeout=100 2018-10-28 00:00:02.446 DEBUG 17364 --- [nio-8888-exec-2] c.s.s.r.core.handler.RateLimterHandler : 由于超过单位时间=100-允许的请求次数=5[触发限流] 2018-10-28 00:00:02.628 DEBUG 17364 --- [nio-8888-exec-4] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]开始执行限流操作 2018-10-28 00:00:02.628 DEBUG 17364 --- [nio-8888-exec-4] c.s.s.r.core.handler.RateLimterHandler : RateLimterHandler[分布式限流处理器]参数值为-limitTimes=5,limitTimeout=100 2018-10-28 00:00:02.629 DEBUG 17364 --- [nio-8888-exec-4] c.s.s.r.core.handler.RateLimterHandler : 由于超过单位时间=100-允许的请求次数=5[触发限流]
总结
5、Hystrix或Gateway网关限流
6、Nginx限流
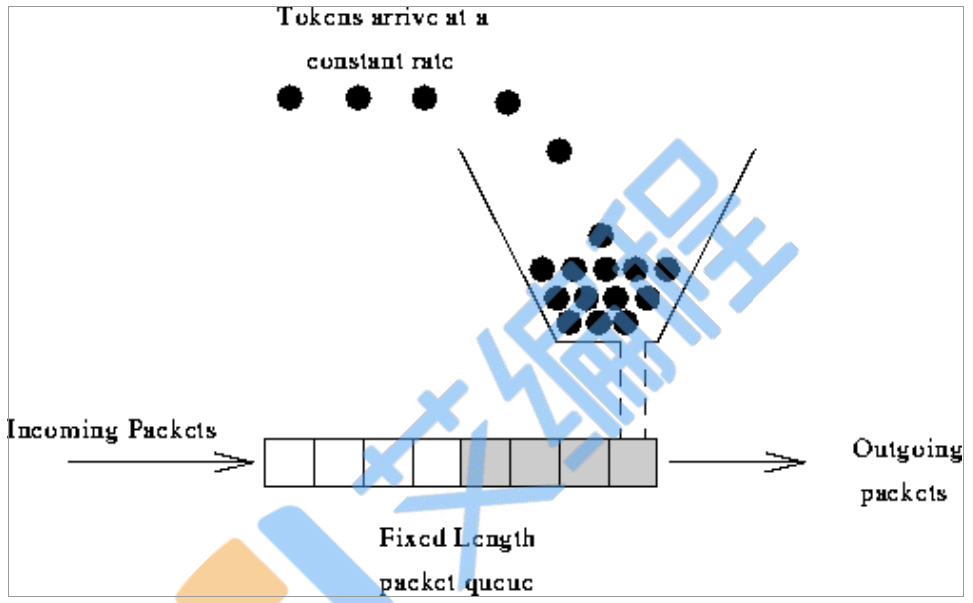
漏桶算法
limit_req_zone 参数配置
Syntax: limit_req zone=name [burst=number] [nodelay];
Default: —
Context: http, server, location
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
第一个参数:$binary_remote_addr 表示通过remote_addr这个标识来做限制,“binary_”的目的 是缩写内存占用量,是限制同一客户端ip地址。 第二个参数:zone=one:10m表示生成一个大小为10M,名字为one的内存区域,用来存储访问的 频次信息。 第三个参数:rate=1r/s表示允许相同标识的客户端的访问频次,这里限制的是每秒1次,还可以有 比如30r/m的。
limit_req zone=one burst=5 nodelay;
例子:
http { limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s; server { location /search/ { limit_req zone=one burst=5 nodelay; } }
limit_req_zone $anti_spider zone=one:10m rate=10r/s; limit_req zone=one burst=100 nodelay; if ($http_user_agent ~* "googlebot|bingbot|Feedfetcher-Google") { set $anti_spider $http_user_agent; }
其他参数
Syntax: limit_req_log_level info | notice | warn | error; Default: limit_req_log_level error; Context: http, server, location
Syntax: limit_req_status code; Default: limit_req_status 503; Context: http, server, location
ngx_http_limit_conn_module 参数配置
Syntax: limit_conn zone number; Default: — Context: http, server, location limit_conn_zone $binary_remote_addr zone=addr:10m; server { location /download/ { limit_conn addr 1; }
limit_conn_zone $binary_remote_addr zone=perip:10m; limit_conn_zone $server_name zone=perserver:10m; server { ... limit_conn perip 10; limit_conn perserver 100; }
Syntax: limit_conn_zone key zone=name:size;
Default: —
Context: http
limit_conn_zone $binary_remote_addr zone=addr:10m;
Syntax: limit_conn_log_level info | notice | warn | error;
Default:
limit_conn_log_level error;
Context: http, server, location
Syntax: limit_conn_status code; Default: limit_conn_status 503; Context: http, server, location
实战
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s; server { location / { limit_req zone=mylimit; } }

实例二 burst缓存处理
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s; server { location / { limit_req zone=mylimit burst=4; } }
实例三 nodelay降低排队时间
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s; server { location / { limit_req zone=mylimit; } } limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s; server { location / { limit_req zone=mylimit burst=4; } }
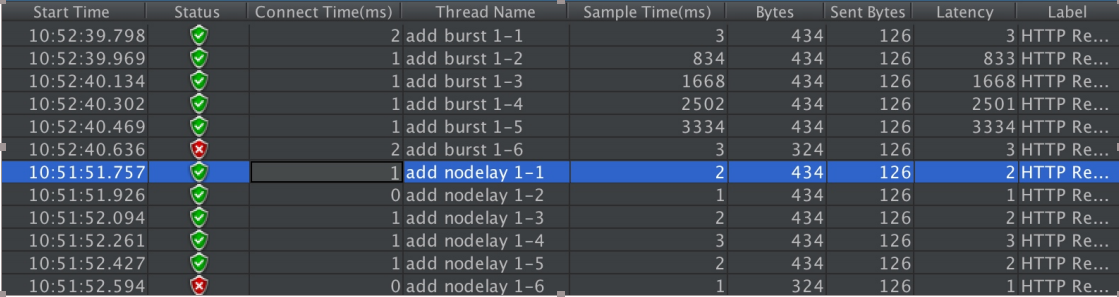
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=2r/s; server { location / { limit_req zone=mylimit burst=4 nodelay; limit_req_status 598; } }
