今天的主要任务是学习一下比较常用的文件读入写入手段,并尝试自己自建一个网站。
接下来首先是一个比较笼统的文件读写自我学习总结:
文件读写是一个比较常见且十分基本的文件操作,当我们想要知道一个文本中的内容时,我们会采取读入的方式,以获取其中的信息,而想要在其中添加东西时,我们采用写入的方式,为文件注入新鲜血液!
我学习的是比较常见的一些文件读写方式;
首先我们为了验证读写,我们新建一个文本文件:
我们的命名为“test.txt“;
在这个文件中我们事先输入一些信息,我的输入如下: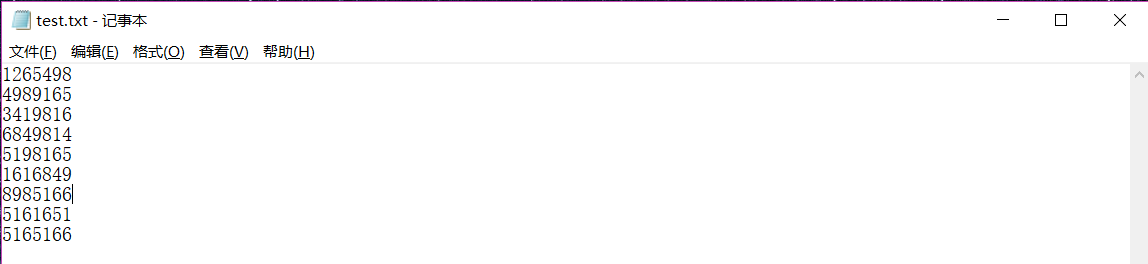
然后我们编写程序:
with open('test.txt') as f: contents = f.read() print (contents) print ('------------') print (contents.rstrip()) print ('------------')
用with open+"文件名"打开文件
再用函数.read()读入,最终我们可以将文本文件整个读出并打印出来:
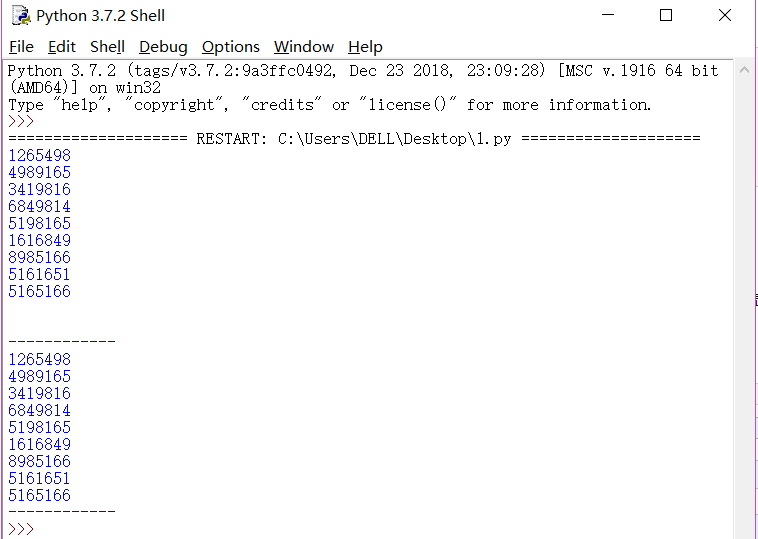
当然上例中我还运用了.rstrip()这个函数,它的作用是删除字符串后面的空白,也就是上面看到的,第二段中下方无空白显示!!
第二段代码:
with open('test.txt') as f: for line1 in f: print (line1) print ('------------') for line2 in f: print (line2.rstrip())
这段代码运用了逐行分行的形式,对其进行读取:
nice~
接下来还有代码可以探究:
with open('test.txt') as f: lines = f.readlines() # 读取文本中所有内容,并保存在一个列表中,列表中每一个元素对应一行数据 print (lines) print ('------------') for line in lines: print (line.rstrip()) print ('------------') pi_str = ''for line in lines: pi_str += line.rstrip() print (pi_str)
它的读取先是将文件中数据保存在列表中——
lines = f.readlines()
由于我的文本中有回车换行,故第一个输出有“ ”换行符,
在最后,还有讨论它的字符串意义,运用字符串相加~
效果: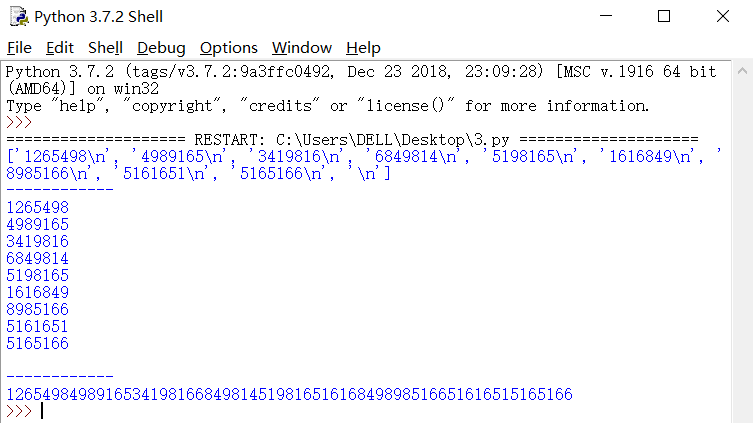
最后一个我们讨论写入,
上代码:
filename = 'test.txt' with open(’test.txt‘,'w') as f: # 如果filename不存在会自动创建, 'w'表示写数据,写之前会清空文件中的原有数据! f.write("I am new in here. ") f.write("The life is short ,so I learn Python. ")
这是全部读取在全部修改的范例,最终原文件中的数据会被销毁,替换为刚输入的两句话:
运行成功!
当我们再次打开“test.txt”,出现的画面是:
nice~
当然也可以不改变原来的数据,只要输入下方代码即可:
filename = 'test.txt' with open(filename,'a') as f: # 'a'表示append,即在原来文件内容后继续写数据(不清楚原有数据) f.write("I extremely know I am a handsome boy in this world! ")
非常常见的.append()函数,令人熟悉哈哈哈!
效果:
非常棒哈哈~
甚至,我们强大的python第三方库有库可以做到文件的读入写入!
我们下面用pandas库和numpy库进行数据处理:
我们进行实例实验:
这里有个excel表格,里面有较多数据:
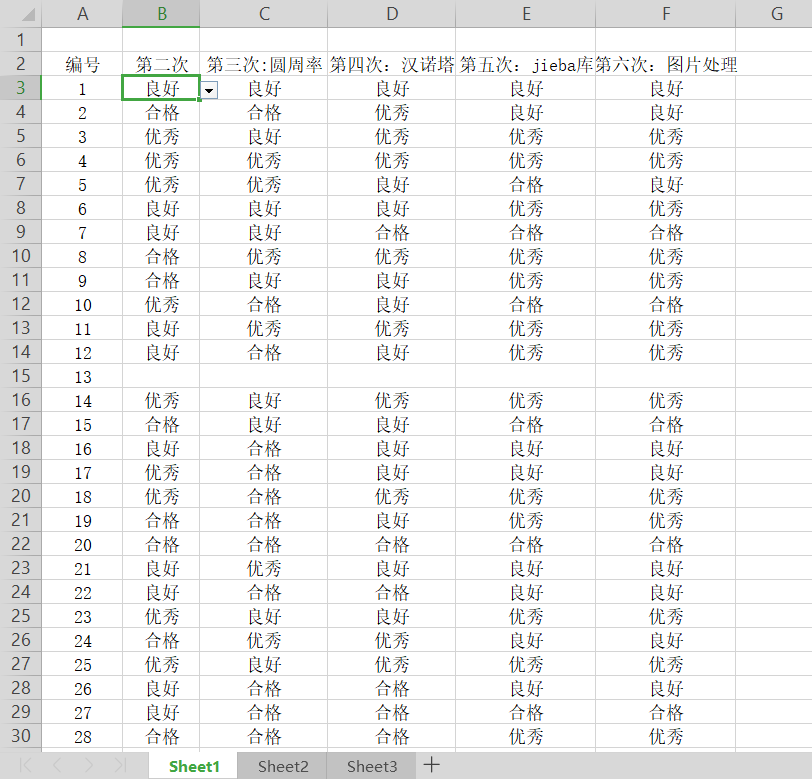
我们将其读入;
代码:
import numpy as np import pandas as pd df = pd.read_excel(r'C:UsersDELLDocumentsWeChat Filesgjw1411459440FileStorageFile2019-04Python成绩登记信计(2).xlsx', na_values=['NA'],columns=list('ABCD')) print(df) df.to_csv('d:\test.csv') df1 = pd.read_csv(r'd:\test.csv') print(df1)
找到excel文件地址之后就开始用numpy做数组运算然后用pandas库将它们变成二维数组表格输出:
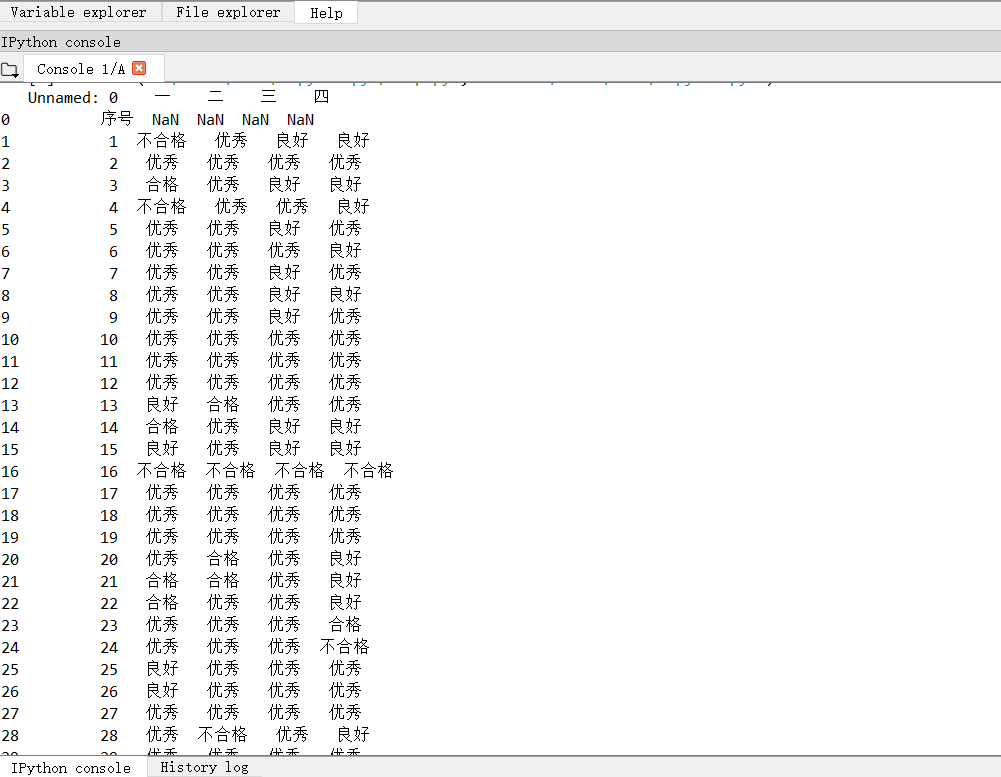
(spyder读取结果)
我们上述代码还有一个步骤:另存为.csv文件,我们保存在了D盘,让我们看看成功没?
nice!成功!
于是我们可以用这个通用文本操作啦~不再惧怕有office的版权保护啦!
我们还有一个任务是将.csv文件中的汉字数据转换为数字数据,也就是将“优秀”变成“90”分,“良好”变成“80”分,“及格”变成“60”分,而“不及格”变成“0”分……
我们的做法是在.csv文件中写入替换;
我用了spyder进行的实验,下面是其中的代码:
# -*- coding: utf-8 -*- """ Spyder Editor This is a temporary script file. """ import numpy as np import pandas as pd grade = pd.read_excel(r'C:UsersDELLDocumentsWeChat Filesgjw1411459440FileStorageFile2019-04Python成绩登记信计(2).xlsx') print(grade) for i in range(len(grade.index)): for j in range(1, len(grade.columns)): if grade.iloc[i, j] == '优秀': grade.iat[i, j] = 90 elif grade.iloc[i, j] == '良好': grade.iat[i, j] = 80 elif grade.iloc[i, j] == '合格': grade.iat[i, j] = 60 else: grade.iat[i, j] = 0 grade.to_csv('d:\test1.csv') gra=pd.read_csv(r'd:\test1.csv') print(gra)
效果如下:
nice~保存路径是在D盘~
当我们想要将他用网页端显示出来,我们要运用CGI;
什么是CGI ?
CGI(Common Gateway Interface)也叫通用网关接口,它是一个web服务器主机提供信息服务的标准接口,只要遵循这个接口,web服务器就能获取客户端提交的信息,转交给服务端的CGI程序进行处理,然后将处理结果返回给客户端。CGI通讯是由两部分组成的:一部分是用户的浏览器显示的页面,也就是html页面,另一部分则是运行在服务器上的CGI程序。
那么我们来通过自己的勤奋双手,打造一个属于自己的CGI文件叭~
那么在这之前我们先做一些必要的准备工作:
1. 首先,在我的电脑里找一个目录,新建一个文件夹,叫做“www”,在“www”文件夹下面新建一个目录,叫做“cgi-bin”,我直接建立在了d盘的根目录下;
2. 使用管理员打开cmd命令行工具,进入到刚才的“www”目录下,注意:是“www”目录;

3. 敲命令“python -m http.server --cgi 5020”将服务器开启,注意:端口5020是可以随意指定的,但是不能与电脑上已经打开的端口冲突,打开正确后显示如下的界面,如果不正确,多半是端口有冲突了,换一个端口就可以了;
成功便会如下显示:

4.打开浏览器输入地址“http://localhost:5020/”如果弹出一下界面就说明服务器开启成功!
有了服务器,让我们先来试试看怎么制作一个简单的网页吧……
我们首先编一个程序:
在刚刚的“www”文件夹中新建一个文件夹“cgi-bin”,将这个.py文件保存在这里,然后打开文件地址作为网址如下图所示:

你就可以打开这个HTTP网页啦~
Ok !原理我们懂了,那我们就开始着手将刚刚的.csv文件转换成http网页吧!
代码如下:
def fill_data(excel, length=4): ''' 函数功能:填充表格的一行数据,返回html格式的字符串text excel: 表格中的一行数据 length: 表格中需要填充的数据个数(即列数),默认为4个 由于生成csv文件时自动增加了1列数据,因此在format()函数从1开始 ''' text = '<tr>' for i in range(length): tmp = '<td align="center">{}</td>'.format(excel[i+1]) text += tmp text += "</tr> " return text def GetCsv(csvFile): ''' 函数功能:打开csv文件并获取数据,返回文件数据 csvFile: csv文件的路径和名称 ''' ls = [] csv = open(csvFile, 'r', encoding="utf-8") for line in csv: line = line.replace(' ', '') ls.append(line.split(',')) return ls def CsvToHtml(csvFile, thNum): ''' csvFile: 需要打开和读取数据的csv文件路径 HTMLFILE: 保存的html文件路径 thNum: csv文件的列数,需注意其中是否包括csv文件第1列无意义的数据, 此处包含因此在调用时需要增加1 ''' csv_list = GetCsv(csvFile) # 获得csv文件数据 print("Content-type:text/html ") print(''' <!DOCTYPE HTML> <html> <body> <meta charset=gbk2313> <h1 align=center>Python成绩表</h2> <table border='blue'> ''') # 写html文件首部 for i in range(1, thNum+1): # 写表格的表头(即第1行) print('<th width="25%">{}</th>'.format(csv_list[0][i])) print("</tr> ") for i in range(1, len(csv_list)): # 写表格的数据,从第2行开始为数据 print(fill_data(csv_list[i], 5)) print("</table> </body> </html>") # 写html文件尾部 CsvToHtml("D:\test1.csv", 5)
我们再将它放置在刚刚的“cgi-bin”中,打开相应网址就能出来啦~

是真滴强!!
OK~今天的分享就到这里了,还有说明问题可以随时问我哦~我理你算我输hh