五、GoogleProtobuf
本文代码仓库:码云
1、编码与解码
- 编写网络应用程序时,因为数据在网络中传输的都是二进制字节码数据,在发送数据时就需要编码,接收数据时就需要解码
codec(编解码器) 的组成部分有两个:decoder(解码器)和encoder(编码器)。encoder负责把业务数据转换成字节码数据,decoder负责把字节码数据转换成业务数据。

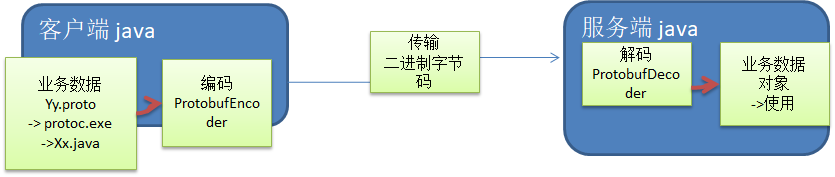
Netty本身的编解码的机制和问题分析(为什么要引入Protobuf)
- Netty 提供的编码器
- StringEncoder,对字符串数据进行编码
- ObjectEncoder,对 Java 对象进行编码
- Netty 提供的解码器
- StringDecoder, 对字符串数据进行解码
- ObjectDecoder,对 Java 对象进行解码
- Netty 本身自带的 ObjectDecoder 和 ObjectEncoder 可以用来实现 POJO 对象或各种业务对象的编码和解码,底层使用的仍是 Java 序列化技术 , 而Java 序列化技术本身效率就不高,存在如下问题
- 无法跨语言
- 序列化后的体积太大,是二进制编码的 5 倍多。
- 序列化性能太低
- 引出 新的解决方案 [Google 的 Protobuf]
2、Protobuf简介
首先Protobuf是用来将对象序列化的,相类似的技术还有Json序列化等等。它是一种高效的结构化数据存储格式,可以用于结构化数据串行化(序列化)。它很适合做数据存储或RPC(远程过程调用)数据交换格式。目前很多公司 http+json =》 tcp+protobuf
- Protobuf 是以 message 的方式来管理数据的
- 支持跨平台、跨语言,即[客户端和服务器端可以是不同的语言编写的] (支持目前绝大多数语言,例如 C++、C#、Java、python 等
- 高性能,高可靠性
- 使用 protobuf 编译器能自动生成代码,Protobuf 是将类的定义使用.proto 文件进行描述。说明,在idea 中编写 .proto 文件时,会自动提示是否下载 .ptotot 编写插件. 可以让语法高亮。
- 然后通过 protoc.exe 编译器根据.proto 自动生成.java 文件
3、proto文件格式
首先我们需要在.proto文件中定义好实体及他们的属性,再进行编译成java对象为我们所用。下面将介绍proto文件的写法。
文件头
就想我们写java需要写package包名一样,.proto文件也要写一些文件的全局属性,主要用于将.proto文件编译成Java文件。
实例 | 介绍 |
|---|---|
syntax="proto3"; | 声明使用到的protobuf的版本 |
optimize_for=SPEED; | 表示 |
java_package="com.mical.netty.pojo"; | 表示生成Java对象所在包名 |
java_outer_classname="MyWorker"; | 表示生成的Java对象的外部类名 |
我们一般将这些代码写在proto文件的开头,以表明生成Java对象的相关文件属性。
定义类和属性
syntax = "proto3"; //版本
option optimize_for = SPEED; //加快解析
option java_outer_classname = "MyDataInfo"; //生成的外部类名,同时也是文件名
message Student { //会在StudentPojo 外部类生成一个内部类Student,他是真正发送的pojo对象
int32 id = 1; //Student类中有一个属性名字为ID,类型为int32(protobuf类型),1表示序号,不是值
string name = 2;
}
enum DateType {
StudentType = 0; //在proto3中,要求enum的编号从0开始
WorkerType = 1;
}
如上图所示,我们在文件中不但声明了protobuf的版本,还声明了生成java对象的类名。当生成java对象后,MyDataInfo将是对象的类名,同时,它使用message声明了Student这个内部类,使用enum声明了DataType这个内部枚举类。就像下面这个样子
messag:声明类。enum:声明枚举类。
public final class MyDataInfo {
public static final class Student { }
public enum DataType { }
}
然后需要注意的是,protobuf中的变量类型和其他语言的声明有所不同。下面是类型的对照表。
| .proto类型 | java类型 | C++类型 | 备注 |
|---|---|---|---|
| double | double | double | |
| float | float | float | |
| int32 | int | int32 | 使用可变长编码方式。编码负数时不够高效——如果你的字段可能含有负数,那么请使用sint32。 |
| int64 | long | int64 | 使用可变长编码方式。编码负数时不够高效——如果你的字段可能含有负数,那么请使用sint64。 |
| unit32 | int[1] | unit32 | 总是4个字节。如果数值总是比总是比228大的话,这个类型会比uint32高效。 |
| unit64 | long[1] | unit64 | 总是8个字节。如果数值总是比总是比256大的话,这个类型会比uint64高效。 |
| sint32 | int | int32 | 使用可变长编码方式。有符号的整型值。编码时比通常的int32高效。 |
| sint64 | long | int64 | 使用可变长编码方式。有符号的整型值。编码时比通常的int64高效。 |
| fixed32 | int[1] | unit32 | |
| fixed64 | long[1] | unit64 | 总是8个字节。如果数值总是比总是比256大的话,这个类型会比uint64高效。 |
| sfixed32 | int | int32 | 总是4个字节。 |
| sfixed64 | long | int64 | 总是8个字节。 |
| bool | boolean | bool | |
| string | String | string | 一个字符串必须是UTF-8编码或者7-bit ASCII编码的文本。 |
| bytes | ByteString | string | 可能包含任意顺序的字节数据 |
类型关注之后,我们看到代码中string name = 2,它并不是给name这个变量赋值,而是给它标号。每个类都需要给其中的变量标号,且需要注意的是类的标号是从1开始的,枚举的标号是从0开始的。
复杂对象
当我们需要统一发送对象和接受对象时,就需要使用一个对象将其他所有对象进行包装,再获取里面的某一类对象。
syntax = "proto3"; //版本
option optimize_for = SPEED; //加快解析
option java_outer_classname = "MyDataInfo"; //生成的外部类名,同时也是文件名
message MyMessage {
//定义一个枚举类型
enum DateType {
StudentType = 0; //在proto3中,要求enum的编号从0开始
WorkerType = 1;
}
//用data_type来标识传的是哪一个枚举类型
DateType data_type = 1;
//标识每次枚举类型最多只能出现其中的一个类型,节省空间
oneof dataBody {
Student stuent = 2;
Worker worker = 4;
}
}
message Student { //会在StudentPojo 外部类生成一个内部类Student,他是真正发送的pojo对象
int32 id = 1; //Student类中有一个属性名字为ID,类型为int32(protobuf类型),1表示序号,不是值
string name = 2;
}
message Worker {
string name = 1;
int32 age = 2;
}
这里面我们定义了MyMessage、Student、Worker三个对象,MyMessage里面持有了一个枚举类DataType和,Student、Worker这两个类对象中的其中一个。这样设计的目的是什么呢?当我们在发送对象时,设置MyMessage里面的对象的同时就可以给枚举赋值,这样当我们接收对象时,就可以根据枚举判断我们接受到哪个实例类了。
protoc.exe --java_out=. Student.proto 使用生成,java文件
4、Netty中使用Protobuf
-
需要给发送端的
pipeline添加编码器:ProtobufEncoder。bootstrap.group(group) .channel(NioSocketChannel.class) .handler(new ChannelInitializer<SocketChannel>() { @Override protected void initChannel(SocketChannel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); pipeline.addLast("encoder", new ProtobufEncoder()); pipeline.addLast(new ProtoClientHandler()); } }); -
需要在接收端添加解码器:
ProtobufDecoderserverBootstrap.group(bossGroup, workerGroup) .channel(NioServerSocketChannel.class) .handler(new LoggingHandler()) .option(ChannelOption.SO_BACKLOG, 128) .childOption(ChannelOption.SO_KEEPALIVE, true) .childHandler(new ChannelInitializer<SocketChannel>() { @Override protected void initChannel(SocketChannel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); //需要指定对哪种对象进行解码 pipeline.addLast("decoder", new ProtobufDecoder(MyDataInfo.MyMessage.getDefaultInstance())); pipeline.addLast(new ProtoServerHandler()); } }) -
在发送时,如何构造一个具体对象呢?以上面复杂对象为例,我们主要构造的是
MyMessage对象,设置里面的枚举属性,和对应的对象。MyDataInfo.MyMessage build = MyDataInfo.MyMessage. newBuilder(). setDataType(MyDataInfo.MyMessage.DateType.StudentType) .setStuent(MyDataInfo.Student .newBuilder() .setId(5) .setName("王五") .build()) .build(); -
在接收对象时,我们就可以根据枚举变量去获取实例对象了。
MyDataInfo.MyMessage message = (MyDataInfo.MyMessage) msg; MyDataInfo.MyMessage.DateType dataType = message.getDataType(); switch (dataType) { case StudentType: MyDataInfo.Student student = message.getStuent(); System.out.println("学生Id = " + student.getId() + student.getName()); case WorkerType: MyDataInfo.Worker worker = message.getWorker(); System.out.println("工人:name = " + worker.getName() + worker.getAge()); case UNRECOGNIZED: System.out.println("输入的类型不正确"); }
原文链接:https://blog.csdn.net/qq_35751014/article/details/104537327
本文在原文的基础的添加了一些自己的笔记和理解