1. 入门
1. KrakenD简介
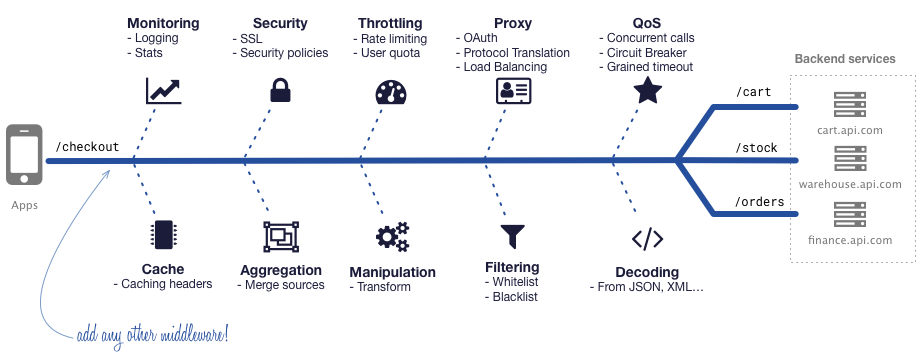
KrakenD是高性能的开源API网关。
它的核心功能是创建一个API,该API充当许多微服务到单个端点的聚合器,为您自动完成繁重的工作:聚合,转换,过滤,解码,限制,身份验证等。
KrakenD 不需要编程,因为它提供了创建端点的声明方式。它具有良好的结构和层次结构,可以使用社区或内部开发的即插即用中间件来扩展其功能。
KrakenD专注于成为一个纯净的API网关,不与HTTP传输层耦合,并且自2017年初以来已在欧洲的大型Internet企业中投入生产。
2. 为什么要使用API网关?
当API内容的使用者(尤其是微服务中的使用者)查询后端服务时,其微服务响应的大小和复杂性会给实现带来很多复杂性和负担。
KrakenD是位于客户端和所有源服务器之间的API网关,添加了一个新层,该层消除了客户端的所有复杂性,仅向它们提供UI所需的信息。
KrakenD可以将许多来源聚合为单个端点,并允许您对响应进行分组,包装,转换和收缩。此外,它支持多种中间件和插件,使您可以扩展功能,例如添加OAuth授权或安全层(SSL,证书,HTTP严格传输安全性,Clickjacking保护,HTTP公钥固定,MIME嗅探预防,XSS保护)。
KrakenD是用Go编写的,支持多种平台,并且基于KrakenD框架。
一个实际的例子
移动开发人员需要构建一个首页,该首页需要来自多个对其后端服务的调用的数据,例如:
1) api.store.server/products
2) api.store.server/marketing-promos
3) api.users.server/users/{id_user}
4) api.users.server/shopping-cart/{id_user}
屏幕很简单,只需要从4个不同的来源检索数据,等待往返,然后从响应中仅选择几个字段即可。代替执行这些调用,移动客户端可以调用KrakenD的单个端点:
1) krakend.server/frontpage/{id_user}
因此,结果如下所示:

通过选择此实现,移动客户端将自己与后端实现隔离。每当后端更改其接口时,移动客户端的API接口就保持不变,并且网关会通过简单的配置更改进行更新。
同时,后端生成的数据量与最终传输到客户端的数据量之间存在大小差异。
2. 安装KrakenD
KrakenD是单个二进制文件,不需要任何外部库即可工作。要安装KrakenD,请在下载部分选择您的操作系统或使用Docker映像。
1. centos安装
rpm -Uvh http://repo.krakend.io/rpm/krakend-repo-0.2-0.x86_64.rpm
yum install -y krakend
systemctl start krakend
2. Fedora安装
rpm -Uvh http://repo.krakend.io/rpm/krakend-repo-0.2-0.x86_64.rpm
dnf install -y krakend
systemctl start krakend
3. docker安装
docker pull devopsfaith/krakend
常用示例
## 拉取镜像运行KrakenD(默认参数)
docker pull devopsfaith/krakend
docker run -p 8080:8080 -v $PWD:/etc/krakend/ devopsfaith/krakend
## 在启用调试(标志-d)的情况下运行:
docker run -p 8080:8080 -v "${PWD}:/etc/krakend/" devopsfaith/krakend run -d -c /etc/krakend/krakend.json
## 检查配置文件的语法
docker run -it -p 8080:8080 -v $PWD:/etc/krakend/ devopsfaith/krakend check --config krakend.json
## 显示帮助:
docker run -it -p 8080:8080 -v $PWD:/etc/krakend/ devopsfaith/krakend --help
3. 使用KrakenD
KrakenD的使用非常简单。它只需要您向配置文件传递路径(定义行为和端点)
在使用前需要确保把KrakenD配置到环境变量上
krakend
API网关构建器
用法:
krakend [命令]
可用命令:
检查验证配置文件是否有效。
help关于任何命令的帮助
运行运行KrakenD服务器。
标志:
-c,--config字符串配置文件名的路径
-d,--debug启用调试
-h,--help krakend的帮助
使用“ krakend [command] --help”可获取有关命令的更多信息。
1. 生成配置文件
生成具有端点定义的配置文件。比较简单的方法就是使用设计器生成配置文件
2. 检查配置文件
## 检查配置文件语法是否正确
krakend check --config krakend.json --debug
3. 运行KrakenD
krakend run -c krakend.json -d
-c是--config的缩写,-d是--debug的缩写
4. 配置文件
1. 配置概述
1. KrakenD的配置文件
KrakenD服务器启动和操作所需的所有配置都是一个配置文件krakend.json。您的实际配置文件可以具有任何名称,可以存储在任何位置或分成多个部分。
提供这种简单的配置机制,版本控制和自动化非常方便。API网关中的任何更改始终在版本控制系统下,并且代码控制网关的状态。
2. 生成配置文件
可以从头开始编写配置文件,也可以重用另一个现有文件作为基础,但是编写第一个配置文件的最简单方法是仅使用在线配置编辑器KrakenDesigner。
KrakenDesigner是一个简单的javascript应用程序,可以帮助您了解API网关的功能,并可以为所有不同的选项设置不同的值。使用此选项,您无需从头开始学习和编写所有属性名称。可以随时下载配置文件,然后再次加载以恢复版本。
Kraken Designer是一个纯静态页面,不会将您的任何配置发送到其他地方,并且随着我们所有软件的发生,它也是开源的,您可以下载它并在自己的Web服务器中运行。请参阅Krakendesigner存储库。
3. 支持的文件格式
配置文件可以写成.json,.toml,.yaml,.yml,.properties,.props,.prop或.hcl。有关更多信息和建议,请参阅支持的文件格式。
4. 验证配置文件的语法
使用以下krakend check命令验证配置文件的语法(而不是逻辑):
krakend check --config ./krakend.toml --debug
Syntax OK!
语法正确时,您会看到消息Syntax OK!,否则显示错误。
您也可以直接启动服务,因为这是在服务器启动之前完成的。
进一步了解 krakend check
2. 文件结构
1. 了解配置文件
所有KrakenD行为都取决于krakend.json文件,因此熟悉此文件的结构非常重要。
2. 配置文件结构
您可以在此文件中放入很多选项,让我们现在仅关注结构:
{
"version": 2,
"endpoints": [...]
"extra_config": {...}
...
}
version:KrakenD文件格式。当前版本是2,1仅用于旧的KrakenD版本(0.3.9及更低版本)。endpoints[]:网关以及所有关联的后端和配置提供的一组端点对象。extra_config{}:与中间件或组件相关的额外配置。例如,您可能要启用日志记录或指标,这是API网关的非核心和可选功能。
3. 该endpoints结构
在中endpoints,您声明一个包含endpoint网关提供的每个URL 的数组。对于每个端点,您需要至少声明一个backend-数据所在的位置-。
看起来像这样:
"endpoints": [
{
"endpoint": "/v1/foo-bar",
"backend": [
{
"url_pattern": "/foo",
"host": [
"https://my.api.com"
]
},
{
"url_pattern": "/bar",
"host": [
"https://my.api.com"
]
}
]
}
]
声明和端点/v1/foo-bar,这是合并来自/foo和的响应的结果/bar。
4. 该extra_config结构
注册组件后,将从中获取其关联的配置extra_config(如果有)。
在extra_config可以出现在不同的层次,而这完全取决于每个组件上。一个文件根级别的extra_config 通常会在服务级别设置值,这会全局影响网关。另一方面,某些组件会在一个endpoint或多个backend``定义extra_config,因此其功能仅特定于后端或端点行为。例如,您可能只想将速率限制设置为特定的端点或后端。
每个外部组件都有责任定义一个命名空间,该命名空间将用作检索配置的键。例如,gologging中间件希望找到一个密钥github_com/devopsfaith/krakend-gologging:
{
"version": 2,
"extra_config": {
"github_com/devopsfaith/krakend-gologging": {
"level": "WARNING",
"prefix": "[KRAKEND]",
"syslog": false,
"stdout": true
}
}
}
根据正式的KrakenD组件,名称空间使用库路径作为的键,extra_config因为这被认为是一种好习惯。当位于extra_config文件根目录(服务级别)中时,命名空间不使用任何点(请注意github_com)以避免解析器出现问题,但是当extra_config置于endpoint级别或什至backend级别时,这些点就会出现。
以下代码是定义两个同时进行的速率限制策略的示例:特定端点的限制为5000 reqs / s,但是其后端之一最多接受100 reqs / s。
{
"version": 2,
"endpoints": [
{
"endpoint": "/limited-to-5000-per-second",
"extra_config": {
"github.com/devopsfaith/krakend-ratelimit/juju/router": {
"maxRate": 5000
}
},
"backend":
[{
"host": [
"http://slow.backend.com/"
],
"url_pattern": "/slow/endpoint",
"extra_config": {
"github.com/devopsfaith/krakend-ratelimit/juju/proxy": {
"maxRate": 100,
"capacity": 1
}
}
},
{
"host": [
"http://fast.backend.com/"
],
"url_pattern": "/fast/endpoint"
}]
...
}
}
5. 示例文件
检查这个更大的示例文件(随KrakenD分发),您可以在其中看到有关如何修改应用程序标题,配置断路器或施加速率限制的示例。
3. 多个配置文件
灵活的配置

该灵活的配置组件包括在KrakenD API网关,并允许您配置文件成若干块分割为更自然的组织。
启用灵活配置后,KrakenD假定您的配置文件是一个模板,需要在启动时进行编译。这样,您就有机会生成一个更复杂的配置文件,该文件利用变量并从外部文件中获取内容。
1. 何时使用弹性配置
模板系统使您可以灵活地使用配置文件。它非常方便:
- 将大
krakend.json文件分成几部分 - 在配置中注入变量
- 使用占位符和可重复使用的代码块
- 拥有go模板系统的全部功能!
2. 要求
使用“灵活配置”的唯一要求是以配置JSON格式编码配置文件,因为该软件包尚不支持其他格式。
3. 用法
运行krakend时,软件包的激活通过环境变量进行,如下所示:
FC_ENABLE=1让KrakenD知道您正在使用灵活配置。您可以使用1或任何其他值(但0不会禁用它!)。带有-c标志传递的文件是基本模板。FC_SETTINGS=dirname:包含所有设置文件的目录的路径。FC_PARTIALS=dirname:目录路径,配置文件中包含部分文件。不评估部分文件,它们仅插入占位符中。FC_TEMPLATES=dirname:配置文件中包含带有子模板的目录的路径。这些使用Go模板系统进行评估。FC_OUT:出于调试目的,将处理灵活配置的结果配置保存在给定的文件名中。否则,最终文件将不可见。
例如,假设您决定按照以下方式组织配置:
.
└── config
├── krakend.json
├── partials
│ └── static_file.tmpl
├── templates
│ └── environment.tmpl
└── settings
└── db.json
然后,您可以使用以下命令从终端运行KrakenD:
$ FC_ENABLE=1
FC_SETTINGS="$PWD/config/settings"
FC_PARTIALS="$PWD/config/partials"
FC_TEMPLATES="$PWD/config/templates"
krakend run -c "$PWD/config/krakend.json"
1. 模板语法
带有-c标志传递的配置文件被视为Go模板,您可以利用模板引擎带来的所有功能。数据评估或控制结构容易被识别,因为它们被{{和}}包围。分隔符之外的所有其他文本将原样复制到输出中。
这些都是语法的可能性:
{{ .file.key }}:key在设置中插入a的值file{{ marshall .file.key }}:key在设置中的下方插入JSON结构file{{ include "file.txt" }}:将file.txt中的完整内容填入此处模板{{ template "file.tmpl" context }}:处理Go模板file.tmpl,使其点({{ . }})context
有关更多说明和示例,请参见下文。
2. 从设置文件插入值
在FC_SETTINGS目录中,您可以保存.json具有数据结构的不同文件,这些文件可以在模板中引用。
例如,如果您的文件settings/db.json包含以下内容:
{
"host": "192.168.1.23",
"port": 8766,
"pass": "a-p4ssw0rd",
"label": "production"
}
您可以使用以下语法访问特定设置:{{ .db.host }}。
表明模板中的值为db.json中的host值即为192.168.1.23
3. 从设置文件插入结构
当您需要插入JSON结构(多个元素)而不是单个值时,需要使用marshall。
{{ marshal .db }}
该示例将写入db.json文件的全部内容。
4. 包括一个外部文件
要就地插入外部部分文件的内容,请使用:
{{ include "partial_file_name.txt" }}
不解析部分模板内的内容,而是将其原样插入纯文本中。假定该文件位于中定义的目录中,FC_PARTIALS并且可以具有任何名称和扩展名。
5. 包含并处理子模板
尽管include仅仅是为了粘贴纯文本文件的内容,但是却template为您提供了Go模板化的所有功能(文档)。语法如下:
{{ template "template_name.tmpl" context }}
模板template_name.tmpl被执行和处理。的值context在模板中作为上下文传递,这意味着子模板可以使用点来访问它{{ . }}。此上下文变量可以是一个对象,例如{{ template "environment" .db.label }},但也可以是另一种类型,例如字符串: {{ template "environment" "production" }}`。
Go模板允许您引入方便的条件条件或循环之类的内容,并允许您创建功能强大的配置。
6. 测试配置
由于配置现在由几部分组成,因此很容易在某个时候犯错误。使用该krakend check命令测试所有文件的语法是否正确,并注意输出以确认没有任何错误。
您可能还希望使用该标志FC_OUT在已知路径中写入最终文件的内容,因此可以检查其内容:
FC_ENABLE=1
FC_SETTINGS="$PWD/config/settings"
FC_PARTIALS="$PWD/config/partials"
FC_TEMPLATES="$PWD/config/templates"
FC_OUT=out.json
krakend check -d -c "$PWD/config/krakend.json"
出现错误时,输出将包含帮助您解决问题的信息,例如:
ERROR parsing the configuration file: loading flexible-config settings:
- backends.json: invalid character '}' looking for beginning of object key string
7. 灵活的配置示例
为了演示灵活配置的用法,我们将分几部分重组配置文件。这是一个简单的示例,用于了解模板系统的基础知识,并且无意显示组织和拆分文件的好方法:
.
└── config
├── krakend.json
├── partials
│ └── rate_limit_backend.tmpl
└── settings
├── endpoint.json
└── service.json
局部/rate_limit_backend.tmpl
在此文件中,我们为后端编写了速率限制配置的内容。如果按原样包含此文件,则将其插入:
"github.com/devopsfaith/krakend-ratelimit/juju/proxy": {
"maxRate": "100",
"capacity": "100"
}
settings / service.json
在设置目录中,我们写入其值可以作为变量访问的所有文件。
{
"port": 8090,
"default_hosts": [
"https://catalog-api-01.srv",
"https://catalog-api-02.srv",
"https://catalog-api-03.srv"
],
"extra_config": {
"github_com/devopsfaith/krakend-httpsecure": {
"allowed_hosts": [],
"ssl_proxy_headers": {
"X-Forwarded-Proto": "https"
},
"ssl_certificate": "/opt/rsa.cert",
"ssl_private_key": "/opt/rsa.key"
}
}
}
设置/ endpoint.json
该文件声明了以单个后端为基础的两个端点:
{
"example_group": [
{
"endpoint": "/users/{id}",
"backend": "/v1/users?userId={id}"
},
{
"endpoint": "/posts/{id}",
"backend": "/posts?postId={id}"
}
]
}
krakend.json
最后,介绍基本模板。它使用插入其他文件的内容include,使用设置文件中声明的变量,并使用写入json内容marshal。
看一下突出显示的行:
{
"version": 2,
"port": {{ .service.port }},
"extra_config": {{ marshal .service.extra_config }},
"host": {{ marshal .service.default_hosts }},
"endpoints": [
{{ range .endpoint.example_group }}
{
"endpoint": "{{ .endpoint }}",
"backend": [
{
"url_pattern": "{{ .backend }}"
}
]
},
{{ end }}
{
"endpoint": "/limited-endpoint",
"backend": [
{
"url_pattern": "/v1/slow-backend",
"extra_config": {
{{ include "rate_limit_backend.tmpl" }}
}
}
]
}
]
}
- 在
.service.port从取service.json文件。 - 该
extra_config在第三行被插入作为使用JSON对象marshal函数从service.json为好。 - A
range迭代在endpoint.json和键下找到的数组example_group。范围内的变量是相对于example_group内容的。 - 最后,
include底部的会按原样插入内容。
请注意,有一个{{ range }}。如果要在模板而不是基本文件中使用它,则需要使用将该子文件包含在子模板中{{ template "template.tmp" .endpoint.example_group }}。
要解析配置,请使用:
FC_ENABLE=1
FC_SETTINGS="$PWD/config/settings"
FC_PARTIALS="$PWD/config/partials"
krakend check -d -c "$PWD/config/krakend.json"
4. KrakenD文件支持的格式
默认情况下json,预期的配置文件格式为,但是如果找到以下扩展名之一,则KrakenD可以解析不同的格式:
.json.toml.yaml.yml.properties.props.prop.hcl
不过,我们的建议是选择JSON。
使用以下命令验证语法(而非逻辑) krakend check
为什么选择json?
您可以自由选择YAML,TOML或为您提供最大的便利。但是,当选择除以外的文件格式时,请记住以下逻辑json。
使用UI:如果打算使用KrakenDesigner生成或编辑配置文件,则输入和输出始终是.json文件。
灵活的配置:如果要将配置文件分成不同的部分,或者在配置内部使用变量,则需要灵活的配置JSON。
文档:今天,文档和存储库中的所有示例均以JSON格式显示,因此重用代码段总是更方便。
5. 命令行命令
1. 运行KrakenD
要启动KrakenD,您需要run使用配置文件的路径来调用命令。您还可以指定端口(默认为8080)
krakend run -c krakend.json
# or
krakend run --config /path/to/krakend.json
# or
krakend run --config /path/to/krakend.json -p 8080
krakend run不带标志的命令将提醒您需要配置文件的路径:
krakend run
Please, provide the path to your config file
显示帮助:
krakend run -h
`7MMF' `YMM' `7MM `7MM"""Yb.
MM .M' MM MM `Yb.
MM .d" `7Mb,od8 ,6"Yb. MM ,MP'.gP"Ya `7MMpMMMb. MM `Mb
MMMMM. MM' "'8) MM MM ;Y ,M' Yb MM MM MM MM
MM VMA MM ,pm9MM MM;Mm 8M"""""" MM MM MM ,MP
MM `MM. MM 8M MM MM `Mb.YM. , MM MM MM ,dP'
.JMML. MMb..JMML. `Moo9^Yo..JMML. YA.`Mbmmd'.JMML JMML..JMMmmmdP'
_______________________________________________________________________
Version: 1.0.0
The API Gateway builder
Usage:
krakend [command]
Available Commands:
check Validates that the configuration file is valid.
help Help about any command
run Run the KrakenD server.
Flags:
-c, --config string Path to the configuration filename
-d, --debug Enable the debug
-h, --help help for krakend
Use "krakend [command] --help" for more information about a command.
例
启动服务的最常见方式是:
krakend run --config krakend.json
要在其他端口中启动KrakenD服务(该端口也可以在配置文件中设置):
krakend run --config path/to/krakend.json --port 8888
在开发和测试阶段,增加日志的详细程度
2. 校验
该krakend check命令验证传递的配置。由于KrakenD没有执行严格的解析,因此配置文件中的错别字可能会被遮盖。为了完全验证您的配置,建议使用该--debug标志。
./krakend check -h
`7MMF' `YMM' `7MM `7MM"""Yb.
MM .M' MM MM `Yb.
MM .d" `7Mb,od8 ,6"Yb. MM ,MP'.gP"Ya `7MMpMMMb. MM `Mb
MMMMM. MM' "'8) MM MM ;Y ,M' Yb MM MM MM MM
MM VMA MM ,pm9MM MM;Mm 8M"""""" MM MM MM ,MP
MM `MM. MM 8M MM MM `Mb.YM. , MM MM MM ,dP'
.JMML. MMb..JMML. `Moo9^Yo..JMML. YA.`Mbmmd'.JMML JMML..JMMmmmdP'
_______________________________________________________________________
Version: 1.0.0
Validates that the active configuration file has a valid syntax to run the service.
Change the configuration file by using the --config flag
Usage:
krakend check [flags]
Aliases:
check, validate
Examples:
krakend check -d -c config.json
Flags:
-h, --help help for check
Global Flags:
-c, --config string Path to the configuration filename
-d, --debug Enable the debug
需要将路径传递到配置文件
krakend check
Please, provide the path to your config file
例
我们将在演示中使用此配置
{
"version": 2,
"name": "My lovely gateway",
"port": 8080,
"cache_ttl": "3600s",
"timeout": "3s",
"extra_config": {
"github_com/devopsfaith/krakend-gologging": {
"level": "ERROR",
"prefix": "[KRAKEND]",
"syslog": false,
"stdout": true
}
},
"endpoints": [
{
"endpoint": "/supu",
"method": "GET",
"backend": [
{
"host": [
"http://127.0.0.1:8080"
],
"url_pattern": "/__debug/supu",
"extra_config": {
"github.com/devopsfaith/krakend-martian": {
"fifo.Group": {
"scope": ["request", "response"],
"aggregateErrors": true,
"modifiers": [
{
"header.Modifier": {
"scope": ["request", "response"],
"name" : "X-Martian",
"value" : "ouh yeah!"
}
},
{
"body.Modifier": {
"scope": ["request"],
"contentType" : "application/json",
"body" : "eyJtc2ciOiJ5b3Ugcm9jayEifQ=="
}
},
{
"header.RegexFilter": {
"scope": ["request"],
"header" : "X-Neptunian",
"regex" : "no!",
"modifier": {
"header.Modifier": {
"scope": ["request"],
"name" : "X-Martian-New",
"value" : "some value"
}
}
}
}
]
}
},
"github.com/devopsfaith/krakend-circuitbreaker/gobreaker": {
"interval": 60,
"timeout": 10,
"maxErrors": 1
}
}
}
]
},
{
"endpoint": "/github/{user}",
"method": "GET",
"backend": [
{
"host": [
"https://api.github.com"
],
"url_pattern": "/",
"whitelist": [
"authorizations_url",
"code_search_url"
],
"disable_host_sanitize": true,
"extra_config": {
"github.com/devopsfaith/krakend-martian": {
"fifo.Group": {
"scope": ["request", "response"],
"aggregateErrors": true,
"modifiers": [
{
"header.Modifier": {
"scope": ["request", "response"],
"name" : "X-Martian",
"value" : "ouh yeah!"
}
},
{
"body.Modifier": {
"scope": ["request"],
"contentType" : "application/json",
"body" : "eyJtc2ciOiJ5b3Ugcm9jayEifQ=="
}
},
{
"header.RegexFilter": {
"scope": ["request"],
"header" : "X-Neptunian",
"regex" : "no!",
"modifier": {
"header.Modifier": {
"scope": ["request"],
"name" : "X-Martian-New",
"value" : "some value"
}
}
}
}
]
}
},
"github.com/devopsfaith/krakend-ratelimit/juju/proxy": {
"maxRate": 2,
"capacity": 2
},
"github.com/devopsfaith/krakend-circuitbreaker/gobreaker": {
"interval": 60,
"timeout": 10,
"maxErrors": 1
}
}
}
]
},
{
"endpoint": "/show/{id}",
"backend": [
{
"host": [
"http://showrss.info/"
],
"url_pattern": "/user/schedule/{id}.rss",
"encoding": "rss",
"group": "schedule",
"whitelist": ["items", "title"],
"extra_config": {
"github.com/devopsfaith/krakend-ratelimit/juju/proxy": {
"maxRate": 1,
"capacity": 1
},
"github.com/devopsfaith/krakend-circuitbreaker/gobreaker": {
"interval": 60,
"timeout": 10,
"maxErrors": 1
}
}
},
{
"host": [
"http://showrss.info/"
],
"url_pattern": "/user/{id}.rss",
"encoding": "rss",
"group": "available",
"whitelist": ["items", "title"],
"extra_config": {
"github.com/devopsfaith/krakend-ratelimit/juju/proxy": {
"maxRate": 2,
"capacity": 2
},
"github.com/devopsfaith/krakend-circuitbreaker/gobreaker": {
"interval": 60,
"timeout": 10,
"maxErrors": 1
}
}
}
],
"extra_config": {
"github.com/devopsfaith/krakend-ratelimit/juju/router": {
"maxRate": 50,
"clientMaxRate": 5,
"strategy": "ip"
}
}
}
]
}
禁用调试
krakend check --config krakend.json
Parsing configuration file: krakend.json
Syntax OK!

开启调试
krakend check -c krakend.json -d
Parsing configuration file: krakend.json
Parsed configuration: CacheTTL: 1h0m0s, Port: 8080
Hosts: []
Extra (1):
github_com/devopsfaith/krakend-gologging: map[level:ERROR syslog:false stdout:true prefix:[KRAKEND]]
Endpoints (3):
Endpoint: /supu, Method: GET, CacheTTL: 1h0m0s, Concurrent: 1, QueryString: []
Extra (0):
Backends (1):
URL: /__debug/supu, Method: GET
Timeout: 3s, Target: , Mapping: map[], BL: [], WL: [], Group:
Hosts: [http://127.0.0.1:8080]
Extra (2):
github.com/devopsfaith/krakend-martian: map[fifo.Group:map[scope:[request response] aggregateErrors:true modifiers:[map[header.Modifier:map[value:ouh yeah! scope:[request response] name:X-Martian]] map[body.Modifier:map[scope:[request] contentType:application/json body:eyJtc2ciOiJ5b3Ugcm9jayEifQ==]] map[header.RegexFilter:map[header:X-Neptunian regex:no! modifier:map[header.Modifier:map[scope:[request] name:X-Martian-New value:some value]] scope:[request]]]]]]
github.com/devopsfaith/krakend-circuitbreaker/gobreaker: map[timeout:10 maxErrors:1 interval:60]
Endpoint: /github/:user, Method: GET, CacheTTL: 1h0m0s, Concurrent: 1, QueryString: []
Extra (0):
Backends (1):
URL: /, Method: GET
Timeout: 3s, Target: , Mapping: map[], BL: [], WL: [authorizations_url code_search_url], Group:
Hosts: [https://api.github.com]
Extra (3):
github.com/devopsfaith/krakend-martian: map[fifo.Group:map[modifiers:[map[header.Modifier:map[name:X-Martian value:ouh yeah! scope:[request response]]] map[body.Modifier:map[scope:[request] contentType:application/json body:eyJtc2ciOiJ5b3Ugcm9jayEifQ==]] map[header.RegexFilter:map[scope:[request] header:X-Neptunian regex:no! modifier:map[header.Modifier:map[scope:[request] name:X-Martian-New value:some value]]]]] scope:[request response] aggregateErrors:true]]
github.com/devopsfaith/krakend-ratelimit/juju/proxy: map[maxRate:2 capacity:2]
github.com/devopsfaith/krakend-circuitbreaker/gobreaker: map[interval:60 timeout:10 maxErrors:1]
Endpoint: /show/:id, Method: GET, CacheTTL: 1h0m0s, Concurrent: 1, QueryString: []
Extra (1):
github.com/devopsfaith/krakend-ratelimit/juju/router: map[maxRate:50 clientMaxRate:5 strategy:ip]
Backends (2):
URL: /user/schedule/{{.Id}}.rss, Method: GET
Timeout: 3s, Target: , Mapping: map[], BL: [], WL: [items title], Group: schedule
Hosts: [http://showrss.info]
Extra (2):
github.com/devopsfaith/krakend-circuitbreaker/gobreaker: map[interval:60 timeout:10 maxErrors:1]
github.com/devopsfaith/krakend-ratelimit/juju/proxy: map[maxRate:1 capacity:1]
URL: /user/{{.Id}}.rss, Method: GET
Timeout: 3s, Target: , Mapping: map[], BL: [], WL: [items title], Group: available
Hosts: [http://showrss.info]
Extra (2):
github.com/devopsfaith/krakend-ratelimit/juju/proxy: map[maxRate:2 capacity:2]
github.com/devopsfaith/krakend-circuitbreaker/gobreaker: map[interval:60 timeout:10 maxErrors:1]
Syntax OK!
6. 服务配置
1. 为HTTPS和HTTP / 2启用TLS
在KrakenD上使用TLS时,有两种不同的策略:
- 在KrakenD中将TLS用于HTTPS和HTTP / 2
- 在KrakenD的前面使用带有TLS终端的平衡器(例如,ELB,HAproxy)
如果您想在KrakenD中启用TLS,则需要tls在服务级别(配置文件的根目录)添加至少包含公钥和私钥的密钥。添加TLS时,KrakenD 仅使用TLS进行侦听,并且不接受到纯HTTP的流量。
2. TLS的简单配置
要使用TLS启动KrakenD,您需要生成证书并提供公钥和私钥:
{
"version": 2,
"tls": {
"public_key": "/path/to/cert.pem",
"private_key": "/path/to/key.pem"
}
}
3. TLS的完整配置
TLS配置的所有可接受的选项是:
public_key:公钥或相对于当前工作目录(CWD)的绝对路径private_key:私钥或相对于当前工作目录(CWD)的绝对路径
加上这些可选的:
disabled(布尔值):禁用TLS的临时标志(例如:在开发过程中)min_version(字符串):最低TLS版本(之一SSL3.0,TLS10,TLS11或TLS12)max_version(字符串):最大TLS版本(之一SSL3.0,TLS10,TLS11或TLS12)curve_preferences(整数数组):曲线首选项的所有标识符的列表(23用于CurveP256,24CurveP384或25CurveP521)prefer_server_cipher_suites(布尔值):强制使用服务器提供的密码套件之一,而不是使用客户端提出的密码套件。cipher_suites(整数数组):密码套件列表(请参见下文)。密码套件及其值的列表为:5:TLS_RSA_WITH_RC4_128_SHA10:TLS_RSA_WITH_3DES_EDE_CBC_SHA47:TLS_RSA_WITH_AES_128_CBC_SHA53:TLS_RSA_WITH_AES_256_CBC_SHA60:TLS_RSA_WITH_AES_128_CBC_SHA256156:TLS_RSA_WITH_AES_128_GCM_SHA256157:TLS_RSA_WITH_AES_256_GCM_SHA38449159:TLS_ECDHE_ECDSA_WITH_RC4_128_SHA49161:TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA49162:TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA49169:TLS_ECDHE_RSA_WITH_RC4_128_SHA49170:TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA49171:TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA49172:TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA49187:TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA25649191:TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA25649199:TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA25649195:TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA25649200:TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA38449196:TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA38452392:TLS_ECDHE_RSA_WITH_CHACHA20_POLY130552393:TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305
7. Endpoints
1. 端点速率限制
限制端点是路由器速率的责任,它允许您设置KrakenD端点每秒接受的最大请求数。默认情况下,端点可以处理的请求数没有限制。
要指定速率限制,您需要在所需的端点中添加配置。
在路由器级别,您可以根据以下内容设置端点的速率限制:
- 端点在一秒内接受的最大请求数(
maxRate) - 端点每个客户端接受的最大请求数(
clientMaxRate)
1. 端点速率限制(maxRate)
当您要设置端点可以在1秒的窗口内处理的最大请求数时,请启用此选项。
设置后,每个KrakenD实例都会在内存中保留一个更新的计数器,其中包含该端点每秒处理的请求数。
maxRate配置中不存在或"maxRate": 0等同于无限制。
如果maxRate达到限制怎么办?
如果API用户达到端点中的既定限制,则KrakenD开始拒绝请求。用户看到HTTP状态代码503 Service Unavailable。
2. 每个客户的端点速率限制(clientMaxRate)
每个客户端的费率类似于maxRate,但clientMaxRate建立用户配额。
无需计算与端点的所有连接,而是clientMaxRate为每个客户端和端点保留一个计数器。请记住,每个KrakenD实例都会为每个客户端在内存中保留其计数器。
范例:
clientMaxRate : 10
允许200个不同的客户(具有不同的IP)访问受限的KrakenD端点,以产生以下总流量:
200 IPs x 10 req/s = 2000req/s
clientMaxRate配置中不存在或"clientMaxRate": 0等同于无限制。
客户识别策略
有两种客户识别策略:
-
"strategy": "ip"当限制适用于客户端的IP时,每个IP均被视为不同的用户。 -
"strategy": "header"当用于标识用户的标准来自key标头内部的值时。通过这种策略,key必须存在。- 例如,设置
"key": "X-TOKEN"为使用X-TOKEN标头作为唯一的用户标识符。
- 例如,设置
如果clientMaxRate达到限制怎么办?
如果API用户(IP或标头策略)达到端点中的既定限制,那么KrakenD将开始拒绝对该特定客户端的请求。用户看到HTTP状态代码429 Too Many Requests。
3. clientMaxRate和maxRate 配置示例
以下示例演示了具有多个端点的配置,每个端点设置不同的限制:
/happy-hour设置时无限制使用的端点0。- 一个
/happy-hour-2终点也是无限的,因为它不设置速率配置。 - A
/limited-endpoint的上限为50请求/秒,其用户最多可以达到5请求/秒(其中用户是不同的IP) - A
/user-limited-endpoint不受全局限制,但每个用户(标识为,每个用户X-Auth-Token最多可以完成10次请求/秒)
{
"version": 2,
"endpoints": [
{
"endpoint": "/happy-hour",
"extra_config": {
"github.com/devopsfaith/krakend-ratelimit/juju/router": {
"maxRate": 0,
"clientMaxRate": 0
}
}
...
},
{
"endpoint": "/happy-hour-2",
...
},
{
"endpoint": "/limited-endpoint",
"extra_config": {
"github.com/devopsfaith/krakend-ratelimit/juju/router": {
"maxRate": 50,
"clientMaxRate": 5,
"strategy": "ip"
}
},
...
},
{
"endpoint": "/user-limited-endpoint",
"extra_config": {
"github.com/devopsfaith/krakend-ratelimit/juju/router": {
"clientMaxRate": 10,
"strategy": "header",
"key": "X-Auth-Token"
}
},
...
}
2. 配置响应
KrakenD允许您直接对响应进行几种操作,只需将它们添加到配置文件中即可。您也可以添加自己的或第三方中间件来扩展此行为。
KrakenD操作以度量nanoseconds,您可以在基准中找到每个响应操作的基准
默认情况下,以下操作可用:
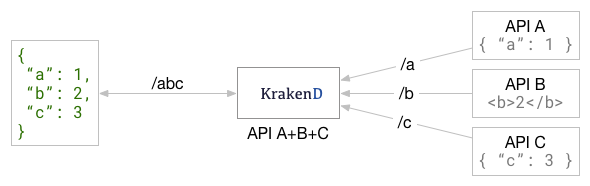
1. 合并中
创建KrakenD终结点时,如果特定终结点从2个或更多后端源(API)馈送,则它们将在对客户端的单个响应中自动合并。例如,假设你有3个不同的API服务暴露的资源/a,/b和/c你想在KrakenD端点的所有共同暴露出他们/abc。这是您将得到的:
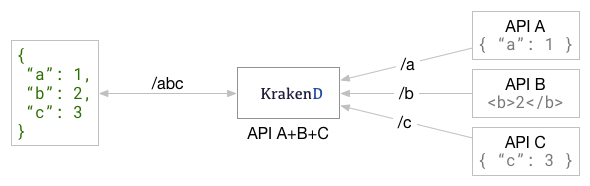
合并操作以首先实现用户体验和响应的方式来实现。它尽最大努力从相关的后端获取所有必需的部分,并尽快返回组成的对象。
通过简单地将多个后端添加到端点中,即可自动进行合并操作。
上图的配置可能是这样的:
"endpoints": [
{
"endpoint": "/abc",
"timeout": "800ms",
"method": "GET",
"backend": [
{
"url_pattern": "/a",
"encoding": "json",
"host": [
"http://service-a.company.com"
]
},
{
"url_pattern": "/b",
"encoding": "xml",
"host": [
"http://service-b.company.com"
]
},
{
"url_pattern": "/c",
"encoding": "json",
"host": [
"http://service-c.company.com"
]
}
]
}
1. 合并超时
请记住,为了避免任何降级的用户体验,在所有后端决定响应之前,KrakenD不会永远被卡住。在网关中,快速失败胜于缓慢成功,KrakenD将确保这种情况发生,因为它将应用超时策略。这将使您的用户在高负载峰值,网络错误或任何使后端承受压力的其他问题期间安全。
该timeout值可以引入每个端点内部,也可以全局放置timeout在配置文件的根目录中。最具体的定义总是会覆盖通用的定义。
2. 触发超时或后端失败时会发生什么?
如果KrakenD正在等待后端响应并达到超时,则响应将是不完整的,并且会丢失发生超时之前无法获取的任何数据。另一方面,在超时发生之前可以有效检索的所有部分都将出现在响应中。
如果响应缺少部分,则缓存头将不存在,因为我们不希望客户端缓存不完整的响应。
在任何时候,x-krakend-completedKrakenD返回的标头都包含一个布尔值,告诉您所有后端是否都返回了其内容(x-krakend-completed: true)或部分响应(x-krakend-completed: false)。
3. 合并示例
想象一下具有以下配置的端点:
...
"endpoints": [
{
"endpoint": "/users/{user}",
"method": "GET",
"timeout": "800ms"
"backend": [
{
"url_pattern": "/users/{user}",
"host": [
"https://jsonplaceholder.typicode.com"
]
},
{
"url_pattern": "/posts/{user}",
"host": [
"https://jsonplaceholder.typicode.com"
]
}
]
}
当用户调用endpoint时/users/1,KrakenD将发送两个请求,在乐观的情况下,它将收到以下响应:
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "Sincere@april.biz",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
和
{
"userId": 1,
"id": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit",
"body": "quia et suscipit
suscipit recusandae consequuntur expedita et cum
reprehenderit molestiae ut ut quas totam
nostrum rerum est autem sunt rem eveniet architecto"
}
有了这些“部分响应”和给定的配置,KrakenD将返回以下响应:
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "Sincere@april.biz",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
},
"userId": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit",
"body": "quia et suscipit
suscipit recusandae consequuntur expedita et cum
reprehenderit molestiae ut ut quas totam
nostrum rerum est autem sunt rem eveniet architecto"
}
2. 过滤
创建KrakenD端点时,您可以决定仅显示来自后端响应的部分字段。您可能有许多不同的原因想要使用此功能,但是我们强烈建议您使用它来节省用户的带宽并增加负载和渲染时间。
您可以使用两种不同的策略来过滤内容:
- 黑名单
- 白名单
请参阅过滤文档
3. 分组
KrakenD能够将您的后端响应分组到不同的对象内。换句话说,当您group为后端设置属性时,KrakenD不会将所有响应属性都放置在响应的根目录中,而是会创建一个新键值来存放
当不同的后端响应可能具有冲突的键名(例如:所有响应都包含一个id具有不同值的)时,将后端响应封装在每个组中尤其有趣。
请参阅分组文档
4. 映射(重新命名)
KrakenD还能够设置所生成响应的字段名称,因此您组成的响应将尽可能接近您的用例,而无需在任何后端更改一行。
在mapping截面图中,原始字段名称带有所需的名称。
请参阅映射文档
5. 目标(或捕获)
在许多API实现中,经常将重要数据始终封装在通用字段(如数据,响应或内容)中,因为还有其他字段显示状态代码和其他元数据。有时我们既不想让客户端处理此问题,也不想在所有配置中拖动该第一级容器。
在后端设置目标时,这些通用容器(目标)会消失,所有内容都将提取到根中,因为它永远不存在。由于此捕获操作是在白名单或映射之类的其他选项之前进行的,因此您不能忘记和操作数据。
请参阅目标文档
6.集合或数组操作
KrakenD期望所有后端在响应中返回对象。有时后端的整个响应都在数组内,而有时需要对数组本身的字段进行操作。
在任何情况下,对数组的操作都与对象不同。
请参阅收藏文档
3. 参数转发
KrakenD是一个API网关,在转发查询字符串,Cookie和标头时,通过将参数转发到后端,它的行为不像常规代理。
数据转发的默认策略如下:
您可以根据需要更改此行为,并定义允许通过哪些元素。
1. 可选查询字符串转发
默认情况下,KrakenD 不会将任何查询字符串参数发送到后端,从而避免了后端污染。这意味着,如果端点/foo接收到查询字符串,则其/foo?a=1&b=2所有声明的后端都不会看到a或b。
在属性列表querystring_params中endpoint配置允许你声明可选的查询字符串参数。当配置中存在此列表时,转发策略的行为就像白名单:将querystring_params列表中声明的所有匹配参数转发到后端,其余参数丢弃。
参数始终是可选的,用户可以传递它们的子集,全部或不传递。
例如,让我们?a=1&b=2转到后端:
{
"version": 2,
"endpoints": [
{
"endpoint": "/v1/foo",
"querystring_params": [
"a",
"b"
],
"backend": [
{
"url_pattern": "/catalog",
"host": [
"http://some.api.com:9000"
]
}
]
}
]
}
使用此配置,给定一个类似的请求http://krakend:8080/v1/foo?a=1&b=2&evil=here,后端将接收a和b,但是evil丢失。
另外,如果类似http://krakend:8080/v1/foo?a=1这样的请求不包含b,则后端请求中也只会缺少此参数。
发送所有查询字符串参数
虽然默认策略阻止发送无法识别的查询字符串参数,但将星号设置*为参数名称会使网关将任何查询字符串转发到后端:
"querystring_params":[
"*"
]
启用通配符会污染您的后端,因为最终用户或恶意攻击者发送的任何查询字符串都会通过网关并影响后面的后端。我们的建议是让网关知道API协定中的查询字符串,并在列表中指定它们,即使列表很长,也不要使用通配符。如果决定使用通配符,请确保您的后端可以处理来自客户端的滥用尝试。
强制查询字符串参数
当您的后端需要查询字符串参数,并且您想使它们在KrakenD中成为必需时,请{variables}在端点定义中使用占位符。变量可以作为查询字符串参数的一部分注入后端。例如:
{
"endpoint": "/v3/{channel}/foo",
"backend": [
{
"host": ["http://backend"],
"url_pattern": "/foo?channel={channel}"
}
]
}
该参数是强制性的,就像channel服务器未提供时提供的for值一样404。
通过上面的配置,可以向KrakenD端点发出请求,例如http://krakend/v3/iOS/foo?limit=10&evil=here仅使用channel查询字符串来调用后端:
/foo?channel=iOS
但是,querystring_params也可以在此配置中添加,从而创建可选参数和强制参数的特殊情况!您将传递url_pattern在用户输入中硬编码并生成的查询字符串。在这种奇怪的情况下,发生的情况是,如果用户传递在其中声明的单个可选查询字符串参数,则querystring_params必填值将丢失。如果请求不包含任何已知的可选参数,则使用必需值。例如:
{
"endpoint": "/v3/{channel}/foo",
"querystring_params": [
"page",
"limit"
],
"backend": [
{
"host": ["http://backend"],
"url_pattern": "/foo?channel={channel}"
}
]
}
随着http://krakend/v3/iOS/foo?limit=10&evil=here后端接收:
/foo?limit=10
channel这里没有强制性!因为limit已经声明了可选参数。
另一方面,http://krakend/v3/iOS/foo?evil=here产生:
/foo?channel=foo
没有传递可选参数,因此使用必需参数。
阅读/__debug/endpoint以了解如何测试查询字符串参数。
2.Header转发
KrakenD 默认情况下不将客户端标头发送到后端。使用headers_to_pass。
声明要通过headers_to_pass选项传递给后端的客户端发送的标头列表。
来自浏览器或移动客户端的客户端请求通常包含许多标头,包括cookie。客户端发送的的各种头的典型例子Host,Connection,Cache-Control,Cookie...和很长很长等等。后端通常不需要任何返回内容。
KrakenD仅将这些基本标头传递给后端:
Accept-Encoding: gzip
Host: localhost:8080
User-Agent: KrakenD Version 1.0.0
X-Forwarded-For: ::1
使用时headers_to_pass,请考虑将所有这些标头替换为声明的标头。
将传递User-Agent给后端的示例:
{
"version": 2,
"endpoints": [
{
"endpoint": "/v1/foo",
"headers_to_pass": [
"User-Agent"
],
"backend": [
{
"url_pattern": "/catalog",
"host": [
"http://some.api.com:9000"
]
}
]
}
]
}
此设置将后端接收的标头更改为:
Accept-Encoding: gzip
Host: localhost:8080
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36
X-Forwarded-For: ::1
阅读/__debug/endpoint以了解如何测试Header。
将所有客户端标头发送到后端
虽然默认策略阻止转发无法识别的标头,但是将星号设置*为参数名称会使网关将任何标头转发到后端,包括cookie:
"headers_to_pass":[
"*"
]
启用通配符会污染您的后端,因为最终用户或恶意攻击者发送的任何标头都将通过网关并影响后面的后端。我们的建议是让网关知道API协定中的头,并在列表中指定它们,即使列表很长,也不要使用通配符。如果决定使用通配符,请确保您的后端可以处理来自客户端的滥用尝试。
3. Cookies转发
Cookie只是在Cookie标头内部传递的某些内容。如果您想让Cookie到达您的后端,请像在任何其他标头一样添加Cookie标头下的headers_to_pass标头。
这样做时,您所有的cookie都会发送到端点内的所有后端。明智地使用此选项!
例:
{
"version": 2,
"endpoints": [
{
"endpoint": "/v1/foo",
"headers_to_pass": [
"Cookie"
],
"backend": [
{
"url_pattern": "/catalog",
"host": [
"http://some.api.com:9000"
]
}
]
}
]
}
4. 调试EndPoint
当启动服务器时使用-d参数时将开启/__debug即调试Endpoint功能
端点可以用作伪后端,对于查看网关和后端之间的交互非常有用,因为它的活动是使用DEBUG日志级别在日志中打印。
在开发时,使用/ __ debug /endpoint将KrakenD本身添加为另一个后端,这样您就可以准确地看到后端接收的header头和查询请求参数。
调试端点可能为您省去很多麻烦,因为当不存在特定的header头或请求参数时,您的应用程序可能无法正常工作。也许您依靠的是客户端发送的内容,但这不是网关发送的内容。请记住:这不是代理。
例如,您的客户端可能正在发送Content-Type或Accept标头,而这些标头可能是后端正常运行所必需的,但是除非网关识别这些标头(它们在中headers_to_pass),否则它们永远不会到达后端。查看日志中的特定标题和参数可以消除所有疑问,并且您可以轻松地重现调用和条件。
调试端点配置示例
以下配置演示了如何通过使用/__debug端点测试后端发送和接收哪些header头和查询字符串参数。
我们将测试以下端点:
-
/default-behavior:没有转发客户标头,查询字符串或cookie。 -
/optional-params:转发已知参数和标头
- 识别
a并b作为查询字符串 - 识别
User-Agent并Accept转发标题
- 识别
-
/mandatory/{variable}:查询字符串参数取自端点中的变量或其他查询字符串参数
要立即对其进行测试,请将此文件的内容保存在中,krakend-test.json并使用-d标志启动服务器:
{
"version": 2,
"port": 8080,
"host": ["http://127.0.0.1:8080"],
"endpoints": [
{
"endpoint": "/default-behavior",
"backend": [
{
"url_pattern": "/__debug/default"
}
]
},
{
"endpoint": "/optional-params",
"querystring_params": [
"a",
"b"
],
"headers_to_pass": [
"User-Agent",
"Accept"
],
"backend": [
{
"url_pattern": "/__debug/optional"
}
]
},
{
"endpoint": "/mandatory/{variable}",
"backend": [
{
"url_pattern": "/__debug/qs?mandatory={variable}"
}
]
}
]
}
启动服务器:
krakend run -d -c krakend-test.json
现在我们可以测试端点的行为是否符合预期:
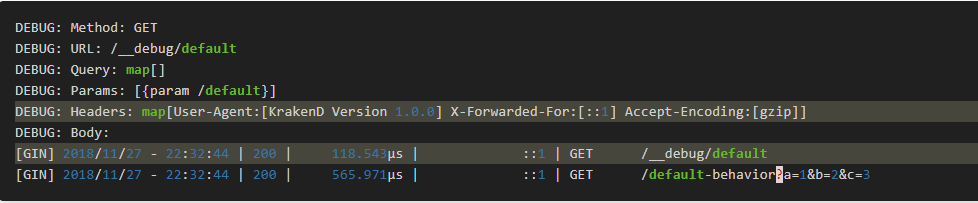
默认行为:
curl -i 'http://localhost:8080/default-behavior?a=1&b=2&c=3'
在KrakenD日志,我们可以看到a,b和c不会出现在后台的呼叫,无论它的头。该curl命令会自动发送Accept和User-Agent标头,但它们也不在后端调用中,相反,我们会看到网关设置的KrakenD User-Agent:
现在,让我们重复相同的请求,但是重复到/optional-params端点:
curl -i 'http://localhost:8080/optional-params?a=1&b=2&c=3'
在KrakenD日志中,我们现在可以看到User-Agentand Accept存在(因为它们是通过curl隐式发送的),并且a和b正在到达后端(但不是c`)

最后,让我们注意一下在后端定义(/mandatory/{variable}端点)中插入强制查询字符串时会发生什么:
curl -i 'http://localhost:8080/mandatory/foo?a=1&b=2&c=3'
如我们所见,后端包括?mandatory=foo在后端定义中手动编写的变量:

5. 安全
KrakenD已实施了几种安全策略,这些策略通过krakend-httpsecure控制。要启用它们,您仅需要根据级别添加extra_config在 endpoint级别或服务(根)级别。
下面的示例描述了本文后面介绍的选项:
"extra_config": {
"github_com/devopsfaith/krakend-httpsecure": {
"allowed_hosts": [
"host.known.com:443"
],
"ssl_proxy_headers": {
"X-Forwarded-Proto": "https"
},
"ssl_redirect": true,
"ssl_host": "ssl.host.domain",
"ssl_port": "443",
"ssl_certificate": "/path/to/cert",
"ssl_private_key": "/path/to/key",
"sts_seconds": 300,
"sts_include_subdomains": true,
"frame_deny": true,
"custom_frame_options_value": "ALLOW-FROM https://example.com",
"hpkp_public_key": "pin-sha256="base64=="; max-age=expireTime [; includeSubDomains][; report-uri="reportURI"]",
"content_type_nosniff": true,
"browser_xss_filter": true,
"content_security_policy": "default-src 'self';"
}
参见下文,此配置文件中描述了不同的选项。
1. 一般安全
1. 按主机限制连接
定义KrakenD应该接受其请求的主机白名单。
当请求到达KrakenD时,它将确认HostHTTP标头的值是否在白名单中。如果是这样,它将进一步处理该请求。如果主机不在白名单中,则KrakenD只会拒绝该请求。
该列表必须包含所允许的标准域名以及原始端口。当列表为空时,接受任何主机。
2. 点击劫持保护
采用 frame_deny
KrakenD通过添加突破框架策略来遵循OWASP的建议。
您可以X-Frame-Options使用(默认行为)custom_frame_options_value值添加标题,DENY甚至设置自定义值。
查看OWASP Clickjacking备忘单,以获取有关页眉及其建议值的更多详细信息。
3. MIME嗅探预防
采用 content_type_nosniff
启用此功能将防止用户的浏览器将文件解释为HTTP标头中内容类型所声明的以外的内容。
4. 跨站点脚本(XSS)保护
采用 browser_xss_filter
此功能启用了用户浏览器中的跨站点脚本(XSS)筛选器。
2. HTTPS
1. HTTP严格传输安全性(HSTS)
采用 sts_seconds
OWASP将HSTS定义为
HTTP严格传输安全性(HSTS)是一种Web安全策略机制,有助于保护网站免受协议降级攻击和cookie劫持。它允许Web服务器声明Web浏览器(或其他符合要求的用户代理)应仅使用安全的HTTPS连接与其进行交互,而绝不能通过不安全的HTTP协议进行交互。HSTS是IETF标准的跟踪协议,在RFC 6797中指定。服务器通过在HTTPS连接上提供标头(严格传输安全)来实现HSTS策略(忽略HTTP上的HSTS标头)。
通过设置Strict-Transport-Security标头的最大使用期限来启用此策略。设置为0禁用HSTS。使用sts_seconds设置。
2. HTTP公钥固定(HPKP)
采用 hpkp_public_key
OWASP将HPKP定义为
HTTP公钥固定(HPKP)是一种安全机制,它允许HTTPS网站使用错误签发或欺诈性的证书来阻止攻击者的冒用。(例如,有时攻击者可能会破坏证书颁发机构,然后可能将证书误发布为Web来源。)
必须谨慎使用此功能,因为主机有可能通过固定到一组无效的公用密钥散列来使其自身不可用。
3. OAuth2
KrakenD支持客户端凭据授予。
如果您需要授权KrakenD访问后端服务,请使用此功能。
请参阅Odocs2客户端凭据的特定文档
6. 响应内容类型
KrakenD支持使用JSON以外的其他内容类型将响应发送回客户端。支持的内容类型列表取决于所使用的路由器软件包。
1. 支持的编码
网关可以使用多种内容类型,甚至允许您的客户端选择如何使用内容。output_encoding可以为每个端点选择以下策略:
json:端点始终以JSON格式返回响应给客户端。negotiate:允许客户端通过解析其Accept标头进行选择。KrakenD可以返回:- JSON格式
- XML格式
- RSS
- YAML。
string:将整个响应视为一个简单的字符串no-op:无编码,无解码。请参阅其文档。
每个端点声明都可以定义应使用的编码器,如本示例所示。默认情况下,当output_encoding省略时,KrakenD会退回到JSON:
...
"endpoints": [
{
"endpoint": "/a",
"output_encoding": "negotiate",
"backend": [
{
"url_pattern": "/a"
}
]
},
{
"endpoint": "/b",
"output_encoding": "string",
"backend": [
{
"url_pattern": "/b"
}
]
},
{
"endpoint": "/c",
"backend": [
{
"url_pattern": "/c"
}
]
}
...
请注意,端点未/c使用JSON,因为尚未定义任何编码。
2. 使用框架中的其他路由器
如果您决定使用KrakenD框架而不是内部使用gin路由器的KrakenD API网关(KrakenD-CE)来构建自己的网关,则可以使用以下路由器和输出编码:
Gin
基于Gin的KrakenD路由器包含以下输出编码:
jsonstringnegotiateno-op
基于Mux
KrakenD框架支持的基于多路复用器的路由器有:
- Mux
- Gorilla
- Negroni
- Chi
- httptreemux
它们包括以下输出编码:
jsonstringno-op
7. 无操作(仅代理)
直接使用代理到后端 no-op
KrakenD no-op(no-operation)是一种特殊的编码类型,它通过将客户端的请求原样传递给后端来充当代理,反之亦然。
使用no-op代理请求
设置时no-op,KrakenD不会检查请求body或以任何方式处理请求。相反,当no-op接收到对端点的请求时,KrakenD会将其直接转发到后端,而无需对其进行任何操作。
所述代理管(这是从KrakenD到后端)被标记做无操作,这意味着KrakenD不聚集内容,过滤器,操纵或任何本管期间执行的其他功能的。同样重要的是要注意,仅接受一个后端,因为合并操作发生在proxy pipe期间。
采用相同的原理,当后端产生响应时,它将按原样传递回客户端,并保留其形式:主体,标头,状态码等。
另一方面,路由器管道的功能(从客户端到KrakenD)保持不变,这意味着,例如,您仍然可以对最终用户进行速率限制或要求JWT授权以举几个例子。
1. 关键概念
在关键概念的no-op是:
- KrakenD端点就像常规代理一样工作
- 该路由器管功能是可用的(例如,速率限制端点)
- 该代理管的功能被禁用(汇总/合并,过滤器,操纵,body检查,并发...)
- 传递到后端的标头仍需要在下声明
headers_to_pass,因为它们首先到达路由器层。 - 后端响应和标头保持不变(包括状态码)
- 主体无法更改,只能由后端设置
1:1端点与后端之间的关系(每个端点一个后端)。
2. 何时使用 no-op
使用no-op时,你需要一对客户端和后台之间没有任何KrakenD操作。
例子:
- 您想
Cookie直接从后端设置一个给客户端。 - 您需要保持后端标头不变。
3. 如何使用 no-op
要声明的是直接去,因为他们是你的后端端点需要定义no-op编码都在endpoint 和的backend部分,具体是:
"output_encoding": "no-op"在endpoint部分中添加"encoding": "no-op"在backend部分中添加
使用无操作编码时,请记住端点只能有一个后端,因为KrakenD不会检查或处理响应(不会发生合并)。另外,其他管道选项(例如并发请求,断路器或特定于代理管道的后端速率限制)不可用(但仍具有端点速率限制->路由器管道)。
4. 例
以下代码片段显示了按原样传递给后端的端点。请注意,端点和后端都有no-op编码。后端使用KrakenD的调试端点在控制台中捕获请求:
{
"endpoint": "/auth/login",
"output_encoding": "no-op",
"backend": [
{
"encoding": "no-op",
"host": [ "localhost:8080" ],
"url_pattern": "/__debug/login"
}
]
}
8. 顺序代理(链要求)
消费者使用KrakenD API可能获得的最佳体验是,让系统同时从不同的后端同时获取所有数据。但是,有时您需要延迟后端调用,直到您可以注入上一个调用的结果作为输入为止。
顺序代理允许您链接后端请求。
1. 链接请求
启用顺序代理所需要做的就是在端点定义中添加以下配置:
"endpoint": "/hotels/{id}",
"extra_config": {
"github.com/devopsfaith/krakend/proxy": {
"sequential": true
}
}
当启用顺序代理时,url_pattern每个后端可以使用一个新的变量引用RESP以前的API调用的ONSE。该变量具有以下构造:
{resp0_XXXX}
哪里0是特定的索引后端要存取(backend阵列),并在那里XXXX为你想从以前的调用注入的属性名称。
2. 例
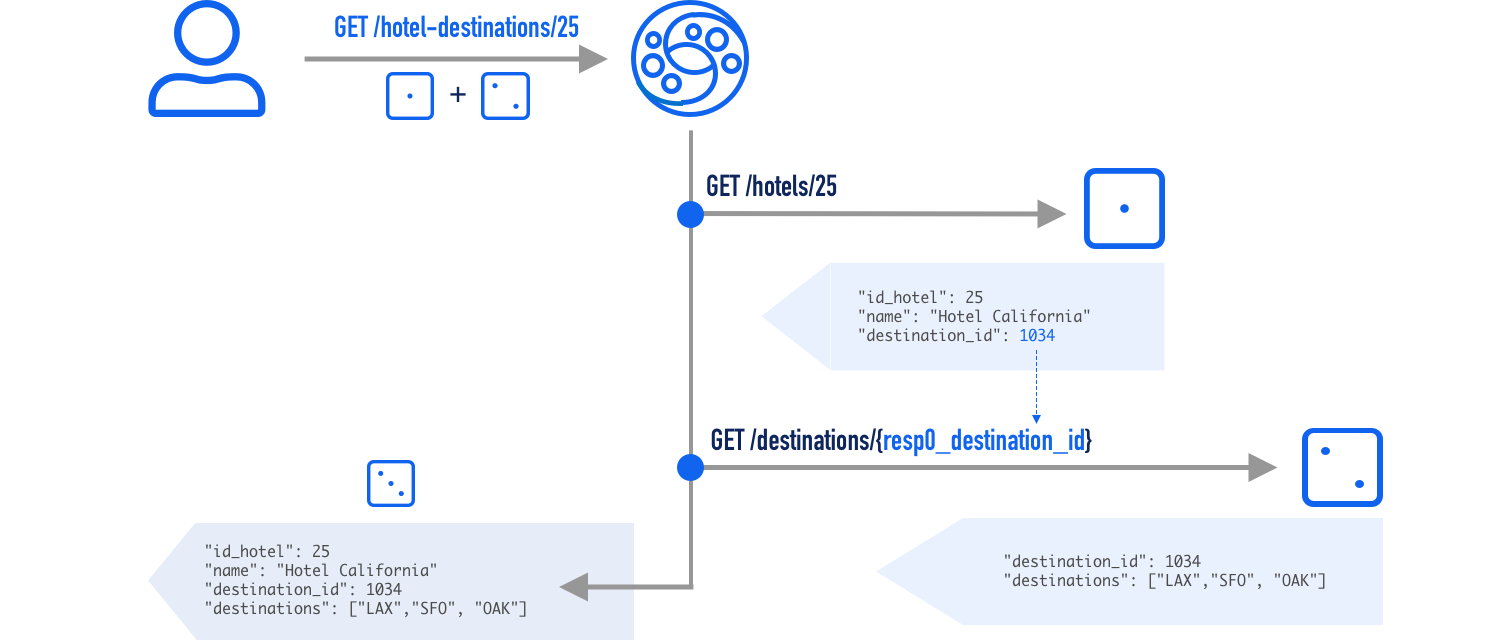
通过图形示例更容易理解:
KrakenD调用一个后端/hotels/{hotel_id},该后端返回所请求酒店的数据。当我们请求酒店ID时25,后端服务会以酒店数据作为响应,其中包括destination_id关系标识符。的输出GET /hotels/25如下所示
{
"hotel_id": 25,
"name": "Hotel California",
"destination_id": 1034
}
KrakenD等待后端的响应并寻找该字段destination_id。然后将值插入到的下一个后端调用中/destinations/{destination_id}。在这种情况下,下一个调用为GET /destinations/1034,响应为:
{
"destination_id": 1034,
"destinations": [
"LAX",
"SFO",
"OAK"
]
}
现在KrakenD既有后端的响应,又可以合并数据,将以下对象返回给用户:
{
"hotel_id": 25,
"name": "Hotel California",
"destination_id": 1034,
"destinations": [
"LAX",
"SFO",
"OAK"
]
}
此示例所需的配置为:
"endpoint": "/hotel-destinations/{id}",
"backend": [
{ <--- Index 0
"host": [
"https://hotels.api"
],
"url_pattern": "/hotels/{id}"
},
{ <--- Index 1
"host": [
"https://destinations.api"
],
"url_pattern": "/destinations/{resp0_destination_id}"
}
],
"extra_config": {
"github.com/devopsfaith/krakend/proxy": {
"sequential": true
}
}
此处的关键是{resp0_destination_id}指向destination_id索引为索引的后端0(列表中的第一个)的变量。
9. 静态响应(存根)
静态代理-添加静态/存根数据
在静态代理是处理不完全和其他类型的退化响应客户的援助。启用后,当后端的行为落在所选策略中时,静态代理会在最终响应中注入静态数据。
一种典型的情况是某些后端发生故障而端点变得不完整,但是您宁愿为该部分提供存根响应。当您的应用程序不能很好地处理降级的响应时,可以使用静态数据。
另一个示例场景是创建一个指向尚未完成的后端的端点,该端点的功能尚未投入生产,但是您的客户端应用程序需要使用后端开发人员并开始使用静态响应。
还有许多其他方案,这就是为什么KrakenD提供几种策略可用来决定是否注入静态数据的原因。无论如何,请记住,此功能的主要目标是支持与尚未准备好妥善处理降级响应的客户端有关的极端情况。
1. 静态响应策略
支持的静态数据注入策略如下:
always:无论如何都将静态数据注入响应中。success:在所有后端均未失败时注入数据。complete:在没有任何错误,所有后端都做出响应并且响应成功合并时插入数据errored:在某些后端发生故障时插入数据,并返回显式错误。incomplete:某些后端未达到合并操作(超时或其他原因)时。
注意不同的策略,因为它们可能会产生细微的差异。与这些策略相关的代码是:
func staticAlwaysMatch(_ *Response, _ error) bool { return true }
func staticIfSuccessMatch(_ *Response, err error) bool { return err == nil }
func staticIfErroredMatch(_ *Response, err error) bool { return err != nil }
func staticIfCompleteMatch(r *Response, err error) bool { return err == nil && r != nil && r.IsComplete }
func staticIfIncompleteMatch(r *Response, _ error) bool { return r == nil || !r.IsComplete }
2. 冲突处理
在所有后端合并发生之后,将处理静态代理,这意味着,如果您的静态数据具有与现有响应冲突的键,则这些键将被覆盖。
由于静态数据是最后计算的部分,因此始终具有优先级。当端点聚合来自多个源的数据时,如果未group为每个后端使用,则所有响应都将直接合并到根中。静态数据也会在根目录中进行合并,因此在设置的内容时请data务必小心,以确保您不会替换有价值的信息。
3. 添加静态响应
要在任何添加静态的回应endpoint一个extra_config条目,如下所示:
"extra_config": {
"github.com/devopsfaith/krakend/proxy": {
"static": {
"strategy": "errored",
"data": {
// YOUR STATIC JSON OBJECT GOES HERE
}
}
}
}
内部strategy键选择适合您的使用案例的策略之一(always,success,complete,errored或incomplete),和里面data你需要为它返回添加的JSON对象。
4. 静态代理示例
当后端返回错误时,以下/static端点将{"errored": {"foo": 42, "bar": "foobar"} }返回。
请注意示例中的两件事,试图避免冲突。首先,每个后端使用一个group,因此,当后端正常工作时,其响应位于键“ foo”或“ bar”内。如果“ foo”和“ bar”使用相同的键,则使用此策略是没有问题的。
其次,当两个后端之一发生故障时,它将创建一个新的组“ oh-snap”(请参阅参考资料data)。
"endpoints": [
{
"endpoint": "/static",
"backend": [
{
"host": [
"http://your.backend"
],
"url_pattern": "/foo",
"group": "foo"
},
{
"host": [
"http://your.backend"
],
"url_pattern": "/bar",
"group": "bar"
}
],
"extra_config": {
"github.com/devopsfaith/krakend/proxy": {
"static": {
"strategy": "errored",
"data": {
"oh-snap": {
"id": 42,
"bar": "foobar"
}
}
}
}
}
},
10. 检查请求和响应
使用通用表达语言(CEL)检查请求和响应
有时候,您可能希望在网关中包含其他逻辑,以决定是否必须满足请求。
该通用表达式语言(CEL) 中间件使谷歌的CEL规范 ,它实现表达式求通用语义,并且是一个非常简单而强大的选项,请求和响应过程中的完全控制。
启用CEL组件后,可以设置检查请求和响应的任意数量的表达式。
然后,在运行时期间,当表达式返回时false,由于条件失败,KrakenD不会返回内容。否则,如果返回所有表达式,则将提供true内容。
CEL表达式的语法与C / C ++ / Java / JavaScript中的表达式相似,并且计算为布尔条件。例如:
'::1' in req_headers['X-Forwarded-For']
此表达式检查请求标头是否X-Forwarded-For包含字符串::1(请求来自本地主机)。
CEL表达式可以在后端和端点的请求或响应期间使用。流程为:
- 请求端点评估
- 请求后端评估(N次)
- 响应后端评估(N次)
- 响应端点评估(可以评估所有合并的数据)
1. 在请求中添加逻辑
如果要添加一些逻辑来决定是否继续将请求提供给端点或不代理给下一个后端,请使用req_*变量。
CEL变量
以下数据已注入CEL评估程序以进行检查:
要求
req_method:此端点的方法是什么,例如:GETreq_path:用于访问此端点的路径,例如::/fooreq_params:具有随请求发送的所有参数的对象,例如:req_params.foo.varreq_headers:包含所有标头的数组,例如:req_headers['X-Forwarded-For']now:包含当前时间戳的对象,例如:timestamp(now).getDayOfWeek()
回应
resp_completed:布尔值是否已成功检索所有数据resp_metadata_status:返回带有StatusCode的整数resp_metadata_header:返回包含响应的所有标头的数组resp_data:具有响应中捕获的所有数据的对象now:包含当前时间戳记的对象
JWT拒绝器
在JWT令牌验证期间,也可以使用CEL表达式。使用JWT 变量访问其元数据。例如:
has(JWT.user_id) && has(JWT.enabled_days) && (timestamp(now).getDayOfWeek() in JWT.enabled_days)
本示例检查JWT令牌是否包含元数据user_id并 enabled_days带有宏has(),然后检查今天的工作日是否在允许查看端点的允许日期之一之内。
2. CEL语法
查看语言定义
11. lua脚本
使用Lua脚本进行转换
使用Lua编写脚本是扩展业务逻辑的另一种选择,并且与CEL,Martian或其他Go插件和中间件等其余选项兼容。
如果您对Lua的了解比对Go的熟悉,那么本模块可以帮助您解决一些需要使用脚本的解决方案的特殊情况。在网关中引入Lua脚本不需要重新编译KrakenD,但是与Go不同,Lua脚本是实时解释的。
对于性能优先的用户,Go插件比Lua脚本提供更好的结果。
1. 组态
KrakenD在运行krakend的根文件夹中查找lua脚本。您需要在配置中指定将在Krakend中加载哪些lua脚本,以及几个选项。该extra_config可以设为endpoint级别或backend级别。
"extra_config": {
"github.com/devopsfaith/krakend-lua": {
"sources": ["file1.lua"],
"md5": {
"file1.lua": "49ae50f58e35f4821ad4550e1a4d1de0"
},
"pre": "pre",
"post": "post",
"live": false,
"skip_next": true
}
}
sources:包含将要处理的所有文件的数组md5:(可选)每个文件的md5sum必须与磁盘中找到的文件匹配。用于确保文件没有被第三方修改。pre并post包含在每个步骤中开始执行的代码。post仅在backend部分中可用。live:在每次执行中实时重载脚本skip_next:仅在backend部分中设置时,将查询跳过到下一个后端。
2. 支持的Lua类型(备忘单)
在KrakenD上运行Lua脚本时,可以在编码中使用两种不同的类型。根据要放置脚本的管道的位置,可以使用一种proxy或多种router类型:
End User <--[router]--> KrakenD <--[proxy]--> Services
这两种类型的描述如下:
- 路由器:路由器层是最终用户和KrakenD之间发生的事情
- 代理:代理层位于KrakenD和您的服务之间
proxy 类型
当您需要拦截KrakenD和您的服务之间的请求和响应时,请使用此类型。
请求
需要修改KrakenD将要针对后端服务执行的请求的脚本。
load(静态)method(动态)path(动态)query(动态)url(动态)params(动态)headers(动态)body(动态)
示例:通过访问请求获取req:url()器,通过访问设置器req:url("foo")。
响应
需要修改KrakenD将要从后端服务获得的请求的脚本。
load(静态)isComplete(动态)statusCode(动态)data(动态)headers(动态)body(动态)
router 类型
当您需要编写路由器层脚本,最终用户与KrakenD之间的流量脚本时,请使用此类型。
ctx
load(静态)method(动态)query(动态)url(动态)params(动态)headers(动态)body(动态)
3. 其他助手(备忘单)
脚本中提供了以下帮助程序:
table
get(动态)set(动态)len(动态)
list
get(动态)set(动态)len(动态)
http_response
new(静态)statusCode(动态)headers(动态)body(动态)
12. 健康endpoint
添加健康端点
如果将平衡器(例如ELB)放在KrakenD的前面,则可以使用TCP端口检查来检查KrakenD的运行状况。另一方面,如果需要像Kubernetes 这样的HTTP终结点,/health或者/ping像Kubernetes 这样的系统中需要HTTP终结点,则可以采用不同的方法。
尽管没有默认的运行状况检查实现,但是可以使用不同的策略来实现结果。例如:
/health在配置中添加具有存根数据的端点(请参见下面的示例)/__debug/使用所需的日志级别启用端点,并将其用作运行状况检查。- 使用静态火星修饰符,并将任何静态文件用作
/health。 - 将传递
/health给另一个后端(尽管您正在检查后端,而不是KrakenD)
添加/health具有存根数据的端点
最简单的选择是使用静态代理功能。通过这种技术,我们将添加一个使用了无法访问的(和伪造的)后端的端点。由于无法从KrakenD中获取数据,因此该策略always将确保我们返回所需的所需静态数据。
{
"version": 2,
"port": 8080,
"endpoints": [
{
"endpoint": "/health",
"extra_config": {
"github.com/devopsfaith/krakend/proxy": {
"static": {
"data": {
"status": "OK"
},
"strategy": "always"
}
}
},
"backend": [
{
"url_pattern": "/",
"host": [
"http://fake-backend"
]
}
]
}
]
}
在前面的示例中,{ "status": "OK" }每次/health调用端点时都返回一个:
curl http://localhost:8080/health
{"status":"OK"}
8. backend
1. backend概述
“后端”的概念指的是原始服务器,它提供了填充端点所需的数据。
后端可以是您网络外部我们内部的任何服务器,只要KrakenD可以访问它即可。例如,您可以创建从内部服务器获取数据的端点,并通过从外部API(例如Github,Facebook或任何其他服务)添加第三方数据来丰富端点。
使用backend密钥在每个端点内部声明后端。
简单的例子
在下面的例子中,KrakenD提供了一个端点/v1/products,当同时要求所连接到这两个服务的每个下宣布host领域(但刚采摘各自使用负载均衡的一个),并返回给出合并后的内容/products/_catalog/all和/marketing/offers这两种不同的服务。
...
"endpoints": [
{
"endpoint": "/v1/products",
"method": "GET",
"backend": [
{
"url_pattern": "/products/_catalog/all",
"host": [
"https://products-01.myapi.com:8000",
"https://products-02.myapi.com:8000"
"https://products-03.myapi.com:8000"
]
},
{
"url_pattern": "/marketing/offers",
"host": [
"https://marketing.myapi.com:8000"
]
}
]
},
...
2. 数据处理
1. 筛选
提供KrakenD端点时,您可以决定仅显示来自后端响应的字段子集,或更改所提供内容的结构。您可能有许多不同的原因想要使用此功能,但是我们强烈建议您使用它来节省用户的带宽并增加负载和渲染时间。
您可以使用两种不同的策略来过滤内容:
- 黑名单
- 白名单
2. 黑名单
可以将黑名单过滤器读取为不显示此过滤器。KrakenD将从响应中删除列表中定义的所有匹配字段,并将显示不匹配的字段。使用黑名单排除响应中的某些字段。
要在响应中将某个字段列入黑名单,请在所需endpoint配置下添加一个blacklist数组,其中包含您不想显示的所有字段。例如:
"blacklist": [
"token",
"CVV"
]
嵌套字段(点运算符)
您选择的黑名单字段也可以是嵌套字段。使用点作为电平分隔符。例如a1,以下JSON响应中的字段{ "a": { "a1": 1 } }可以被列入黑名单a.a1。
同样值得一提的是,该运算符仅适用于对象,不适用于数组。使用集合时[],请参见处理数组的特殊情况。
例如,{ "a": [ { "a1": 1 } ] }不能将其列入黑名单,a.a1因为a1它在数组内。
黑名单示例
我们将使用JSONPlaceholder伪造的API,以便您可以实时查看后端的输出。
我们想要设置一个KrakenD端点,该端点返回特定用户的帖子,但是我们已经看到后端响应包含太多数据,因为我们的用例不需要bodyand userId字段,并且我们希望响应更快更轻。
接受类似URL的KrakenD端点/posts/1定义如下:
{
"endpoint": "/posts/{user}",
"method": "GET",
"backend": [
{
"url_pattern": "/posts/{user}",
"host": [
"https://jsonplaceholder.typicode.com"
],
"blacklist": [
"body",
"userId"
]
}
]
}
现在,当调用KrakenD端点时/posts/1,您将获得的响应如下:
{
"id": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"
}
与后端响应相比,您会看到字段body和userId不再存在。
3. 白名单
黑名单过滤器可以被视为唯一显示此过滤器的过滤器。设置白名单时,KrakenD将仅在端点响应中包括与您选择的字段完全匹配的字段。使用白名单严格定义要在响应中显示的字段。
您选择的白名单字段也可以是嵌套字段。使用点作为电平分隔符。例如a1,以下JSON响应中的字段{ "a": { "a1": 1 } }可以白名单为a.a1。
白名单示例
我们将重复在黑名单中所做的相同练习以获得相同的输出。我们只想从后端获取idand title字段。
{
"endpoint": "/posts/{user}",
"method": "GET",
"backend": [
{
"url_pattern": "/posts/{user}",
"host": [
"https://jsonplaceholder.typicode.com"
],
"whitelist": [
"id",
"title"
]
}
]
}
现在,当调用KrakenD端点时/posts/1,您将获得的响应如下:
{
"id": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"
}
就像我们对黑名单所做的一样。
4. 白名单还是黑名单?
过滤时,需要在黑名单和白名单之间进行选择。这两种操作不能并存,因为它们的行为是相互矛盾的。没有什么可以阻止您玩一会儿,看看将它们混合后会发生什么,但是请确保这只是实验!
从性能的角度来看,黑名单的速度略快于白名单。
5. 分组
KrakenD能够将您的后端响应分组到不同的对象内。换句话说,当您group为后端设置属性时,KrakenD不会将所有响应属性都放置在响应的根目录中,而是会创建一个新密钥并将响应放置在内部。
当不同的后端响应可能具有冲突的键名(例如:所有响应都包含一个id具有不同值的)时,将后端响应封装在每个组中尤其有趣。
当对不同的后端响应进行分组时,不要共享相同的组名,因为最慢的后端将用相同的组覆盖响应。组名称对于同一端点中的每个后端都应该是唯一的,但这不是强制性的。
6. 分组示例
以下代码是一个端点,该端点从两个不同的后端获取数据,但其中一个响应封装在字段内last_post。
{
"endpoint": "/users/{user}",
"method": "GET",
"backend": [
{
"url_pattern": "/users/{user}",
"host": [
"https://jsonplaceholder.typicode.com"
]
},
{
"url_pattern": "/posts/{user}",
"host": [
"https://jsonplaceholder.typicode.com"
],
"group": "last_post"
}
]
}
这将生成如下响应:
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "Sincere@april.biz",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
},
"last_post": {
"id": 1,
"userId": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit",
"body": "quia et suscipit
suscipit recusandae consequuntur expedita et cum
reprehenderit molestiae ut ut quas totam
nostrum rerum est autem sunt rem eveniet architecto"
}
}
7. 映射
映射(也称为重命名)使您可以更改生成的响应的字段名称,因此您组成的响应将尽可能接近您的用例,而无需在任何后端上更改行。
在mapping截面图中,原始字段名称带有所需的名称。
映射示例:
email我们不想显示该字段,而是要为其命名personal_email:
{
"endpoint": "/users/{user}",
"method": "GET",
"backend": [
{
"url_pattern": "/users/{user}",
"host": [
"https://jsonplaceholder.typicode.com"
],
"mapping": {
"email": "personal_email"
}
}
]
}
会生成这样的响应:
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"personal_email": "Sincere@april.biz",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
8. 目标
在许多API实施中,经常将所需数据始终封装在通用字段(如数据或内容)中,并且您不希望在响应中包含此级别。 当您要捕获这些通用容器中的内容并将其提取到根本不存在的根目录时,以及要使用其他操作选项时,请使用捕获。捕获发生在白名单或映射之类的其他选项之前。 捕获选项使用配置文件中的属性目标。
捕获目标示例
给定一个后端端点,这种响应包含一个级别data:
{
"apiVersion":"2.0",
"data": {
"updated":"2010-01-07T19:58:42.949Z",
"totalItems":800,
"startIndex":1,
"itemsPerPage":1,
"items":[]
}
}
并使用此KrakenD配置
{
"endpoint": "/foo",
"method": "GET",
"backend": [
{
"url_pattern": "/bar",
"target": "data"
}
]
}
网关将生成如下响应:
{
"updated":"2010-01-07T19:58:42.949Z",
"totalItems":800,
"startIndex":1,
"itemsPerPage":1,
"items":[]
}
9. 集合
使用集合(或数组)是一种特殊的操作情况。关于集合,有两种不同的方案:
- 当整个后端响应位于数组而不是对象内部时
- 当您想操作集合时(例如:类似的路径
data.item[N].property)
当后端响应位于数组内部时
KrakenD希望所有后端都返回一个对象作为响应。例如,包含对象的JSON响应封装在花括号中{}。例如:
{ "a": true, "b": false }
当您的API不返回对象而是集合([]或数组)时,您需要使用显式声明它,"is_collection": true以便KrakenD可以将其转换为对象以进行进一步操作。JSON收集响应的示例是:
[ {"a": true }, {"b": false} ]
在这种情况下,请在backend键中添加属性,"is_collection": true以便KrakenD可以将此集合转换为对象。
默认情况下,KrakenD 在响应中添加collection 为key来包含集合数据,例如:
{
"collection": [
{"a": true },
{"b": false}
]
}
您可以collection使用mapping属性将默认键名重命名为其他名称(上面的文档,下面的示例)。
以下是一个基于收集响应的真实示例,请复制并粘贴以在您的环境中进行测试:
"endpoints": [
{
"endpoint": "/posts",
"backend": [
{
"url_pattern": "/posts",
"host": ["http://jsonplaceholder.typicode.com"],
"sd": "static",
"is_collection": true,
"mapping": {
"collection": "myposts"
}
}
]
}
]
响应将如下所示:
{
"myposts": [
{
...
},
{
...
}
}
当您需要操纵数组时
所有数据操作操作(例如白名单,黑名单等)都希望在响应中找到对象。当一个对象嵌套在另一个对象中时,您可以直接过滤,但是等式中存在数组时,KrakenD需要平整结构。
参见平面图文档
操纵Lua
可以使用Lua脚本转换后端响应。
请参阅Lua脚本文档
3. 限速后端
1. 限速后端
无论用户在路由器级别生成多少活动,您都可能希望限制KrakenD与后端的连接。配置与路由器的配置类似,但是直接在backend部分而不是中进行声明endpoint。
该参数在krakend.json配置文件中定义如下:
...
{
"endpoint": "/products/{cat_id}",
"backend": [
{
"host": [
"http://some.api.com/"
],
"url_pattern": "/catalog/category/{cat_id}.rss",
"encoding": "rss",
"extra_config": {
"github.com/devopsfaith/krakend-ratelimit/juju/proxy": {
"maxRate": 1,
"capacity": 1
}
}
}
...
您可以设置两个参数:
maxRate:您希望在此后端中接受的每秒最大请求数。capacity:根据容量令牌桶算法有bucket capacity == tokens added per second这么KrakenD能够允许在请求速率一些爆裂。推荐值是容量== maxRate
2. 比较maxRateVSclientMaxRate
该maxRate(可无论是在路由器和代理层)是你有超过您允许多少流量打后端或端点精确控制的绝对数量。在最终的DDoS中,maxRate由于无法接受超出允许范围的流量,因此可以有所帮助。但是另一方面,单个主机可能会滥用系统,从而占用该配额的很大一部分。
这clientMaxRate是每个客户端的限制,如果您只想控制总流量,则它无济于事,因为后端或端点支持的总流量取决于不同请求客户端的数量。DDoS会很高兴地通过,但另一方面,您可以将任何特定的滥用者限制在其配额范围内。
根据您的用例,您将需要决定是使用一个,另一个,两个还是不使用(最快!)
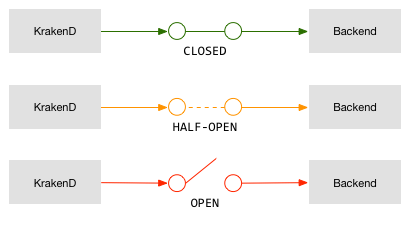
4. 断路器
为了保持KrakenD的响应能力和弹性,我们在处理管道的多个点上添加了Circuit Breaker中间件。多亏了此组件,当KrakenD要求的吞吐量超过实际API堆栈无法正常交付的吞吐量时,Circuit Breaker机制将检测到故障,并通过不发送可能会失败的请求来防止对服务器造成压力。通过防止过多的请求因超时等而失败,它对于处理网络和其他通信问题也很有用。
该断路器是一个非常简单的状态机的请求和响应,监控所有后端的失败,当他们达到配置的阈值断路器将禁止发送更多的流量到苦难后端的中间。
断路器是对您的后台的一种保护措施,可避免级联故障。
1. 怎么运行的
断路器通过一系列请求保留与您的后端的连接状态,当它在给定的时间间隔()内看到配置的连续故障数(maxErrors)时,interval它将停止与下一个后端的所有交互。 N秒(timeout)。等待该时间窗口后,系统将允许单个连接再次尝试系统:如果失败,它将再次等待N秒,如果成功,它将返回到正常状态,并且系统被认为是健康的。
断路器具有三种不同的内部状态,最简单的想象方式就像在电路中一样:
断路器
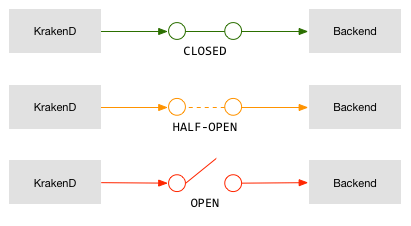
CLOSED:这是正常状态。当电路闭合时,电流不间断地流动,并允许与后端的连接。OPEN:当电路断开时,不允许与后端的连接。HALF-OPEN:当系统遇到重复的问题时,仅允许进行必要的连接以测试后端。
这就是状态改变的方式:
断路器过渡
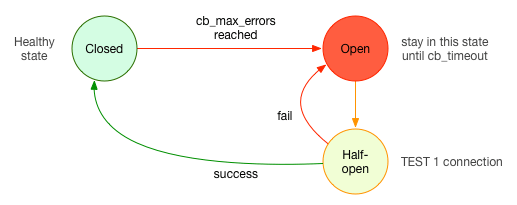
CLOSED:在初始状态下,系统运行状况良好,并且正在向后端发送连接。OPEN:当来自后端(maxErrors)的支持的错误达到连续数量时,系统更改为,OPEN并且没有其他连接发送到后端。系统将保持OPEN状态N秒钟(timeout)。HALF-OPEN:超时后,它将更改为此状态并允许一个连接通过。如果连接成功,状态将变为,CLOSED并且后端将再次恢复正常。但是,如果失败,它将切换回OPEN另一个超时。
2. 配置断路器
得益于断路器中间件,KrakenD默认提供了断路器。与所有其他中间件一样,您需要github.com/devopsfaith/krakend-circuitbreaker/gobreaker在extra_config密钥内自己的名称空间中设置其值。
以下配置是有关如何向后端添加断路器功能的示例:
"endpoints": [
{
"endpoint": "/myendpoint",
"method": "GET",
"backend": [
{
"host": [
"http://127.0.0.1:8080"
],
"url_pattern": "/mybackend-endpoint",
"extra_config": {
"github.com/devopsfaith/krakend-circuitbreaker/gobreaker": {
"interval": 60,
"timeout": 10,
"maxErrors": 1,
"logStatusChange": true
}
}
}
]
...
5. 并发请求
并发请求是一种出色的技术,可通过多次并行请求相同的信息来提高响应时间并降低错误率。当第一个后端返回信息时,其余线程将被取消。
这在很大程度上取决于您的配置,但是对于当今使用的同一应用程序,将响应时间提高75%或更多并不罕见。
使用并发请求时,后端服务必须能够处理其他负载。如果是这种情况,并且您的请求是幂等的,则可以concurrent_calls按以下方式使用:
...,
"endpoints": [
{
"endpoint": "/products",
"method": "GET",
"concurrent_calls": 3,
"backend": [
{
"host": [
"http://server-01.api.com:8000",
"http://server-02.api.com:8000"
],
"url_pattern": "/foo",
...
在上面的示例中,当用户调用/products端点时,KrakenD将打开三个与后端的不同连接,并返回第一个最快的成功响应。
请注意,尽管此后端只有两个服务器来处理负载,但该服务器concurrent_calls设置为三台。这两个设置无关,并且KrakenD将针对这两个服务器打开三个连接。哪个服务器接收1,2或全部接收三个,取决于内部负载均衡器的决定。
1. 理想的数字是concurrent_calls多少?
没有建议的数量,因为这最终取决于服务的行为方式以及每种服务所拥有的资源数量。
不过,我们可以说,如果您对此功能感兴趣的话,这3是一个不错的选择,因为它可以提供优异的结果,而无需将资源加倍。
一般来说,如果您在云上工作,启用此功能会更安全,因为您可以轻松地增加资源(但要注意成本)。如果您的硬件有限(内部部署),则在未进行适当的负载测试之前,请勿在生产中激活此功能。
2. concurrent_calls工作如何?
KrakenD最多向concurrent_calls您的后端发送N个请求,以向端点发出相同请求。收到第一个成功的响应后,KrakenD取消其余请求,并忽略之前的任何失败。仅在全部concurrent_calls失败的情况下,端点也接收失败。
这种策略的明显折衷是后端服务负载的增加,因此请确保您的基础架构已为此做好准备。但是,您的用户喜欢它:更少的错误,更快的响应!
并发请求的影响
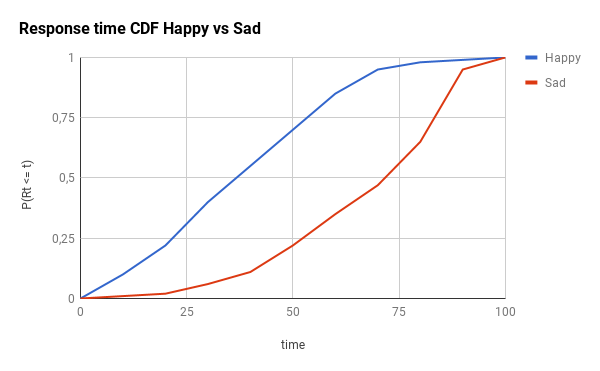
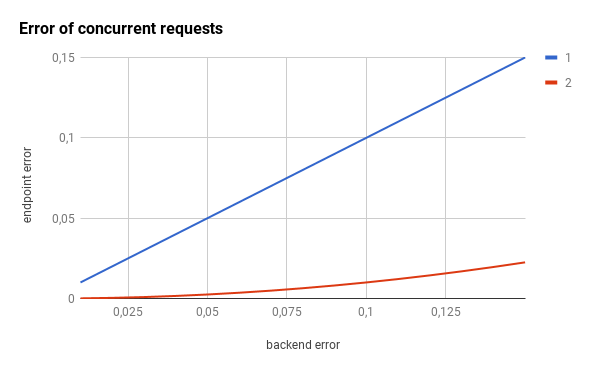
为了演示此组件的影响,让我们想象两个不同的场景:乐观的场景和悲观的场景。在这里,你有CDF(累积分布)和PDF(概率分布),这两种情况(时间范围只是一个占位符,用于无论你的实际响应时间值,只需更换100你的max_response_time):

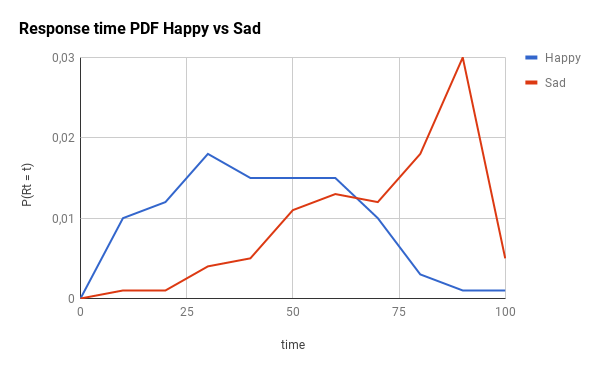
提醒一下:对于CDF图,线的左侧越多越好。对于PDF图形,左侧越多,峰越窄越好。
下图是在满意的情况下使用不同的并发级别的效果(注意响应时间如何集中在的20%左右max_response_time):
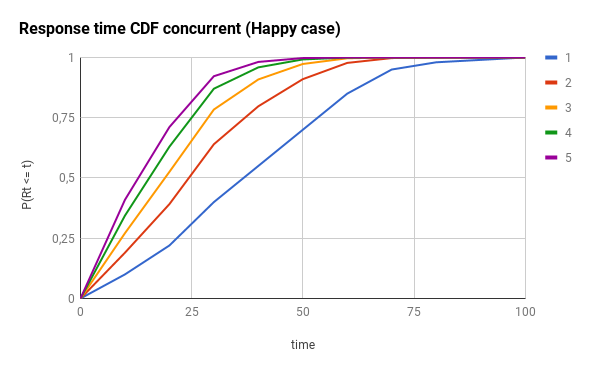
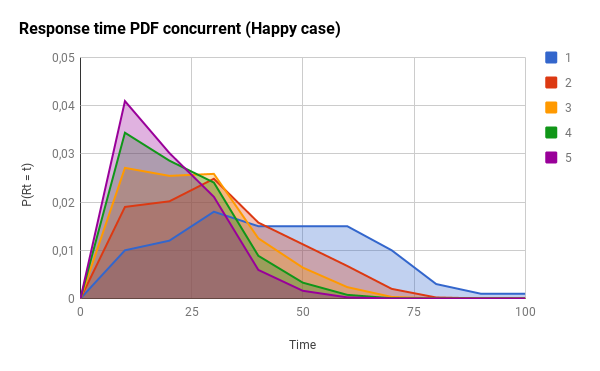
在这里,您将得到悲观情况的影响:
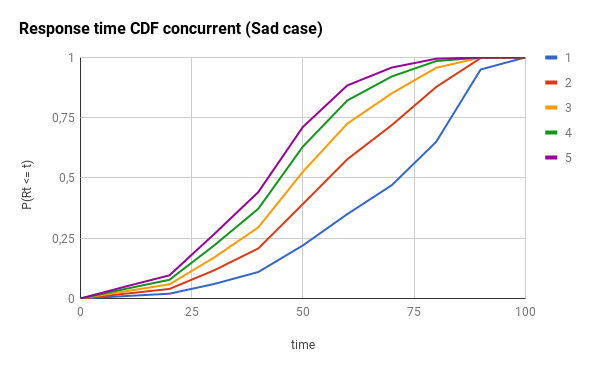
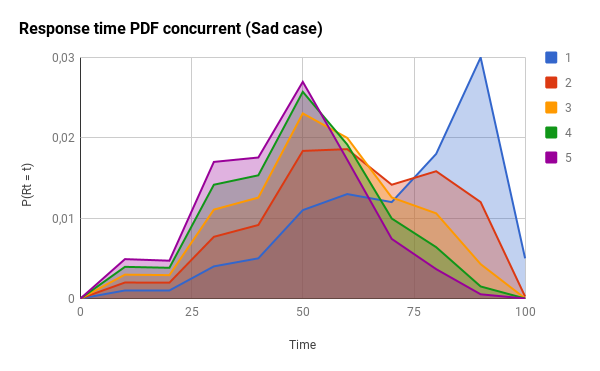
并发请求组件还可以将暴露的终结点的错误率降低几个数量级。
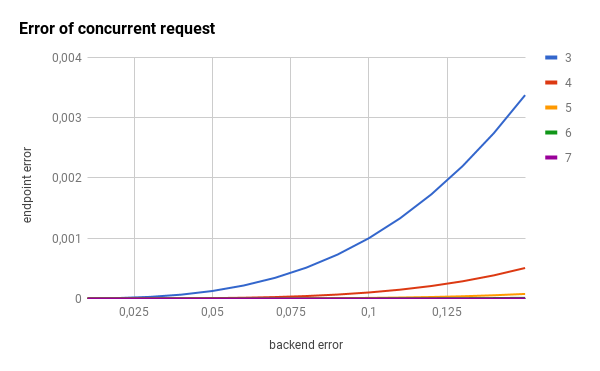
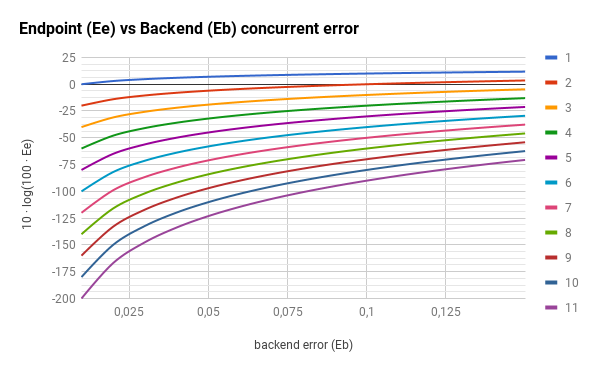
由于先前图形的比例尺隐藏了巨大的影响,因此让我们使用对数比例尺:
6.支持的后端编码
KrakenD可以解析来自使用多种内容类型或编码的混合后端的响应,例如:
- JSON格式
- XML格式
- RSS
- 字符串
此外,可以使用特殊情况的No-op(代理),但不能用于合并内容。
每个后端声明可以设置一个不同的编码器来处理响应,而且KrakenD仍可以透明地使用混合内容,并在端点中返回统一编码。
下面的例子演示了如何终点/abc是在拉取三个不同的服务和URL /a,/b以及/c和聚合他们的响应数据
...
"endpoints": [
{
"endpoint": "/abc",
"backend": [
{
"url_pattern": "/a",
"encoding": "json",
"host": [
"http://service-a.company.com"
]
},
{
"url_pattern": "/b",
"encoding": "xml",
"host": [
"http://service-b.company.com"
]
},
{
"url_pattern": "/c",
"encoding": "rss",
"host": [
"http://service-c.company.com"
]
}
]
}
...
如您所见,encoding在每个后端都有声明,可以使用具有不同内容类型的服务。端点/abc改为使用您选择的编码(例如JSON)。
7. 缓存后端响应
有时,您可能想重用后端的先前响应,而不是通过网络再次请求相同的信息。在这种情况下,可以为所需的后端响应启用内存中缓存。
此缓存技术仅适用于KrakenD和您的微服务端点之间的流量,而不适用于最终用户端点的缓存系统。要启用缓存,您只需要在配置文件中添加httpcache中间件。
启用后,已配置后端的所有连接都会在内存中缓存一段时间,该时间是从Cache-Control响应头中检索到的时间。
由于KrakenD需要在到期期间将所有返回的数据保留在内存中,因此该选项会大大增加负载和内存消耗。明智地使用!
如果启用此模块,则需要非常了解响应大小,缓存时间和呼叫的命中率。
使用中间件backend在您的部分中启用后端服务的缓存krakend.json:
"github.com/devopsfaith/krakend-httpcache": {}
除了简单包含之外,中间件不需要其他配置。
看一个例子:
...
"backend": [
{
"url_pattern": "/",
"host": ["http://my-service.tld"],
"extra_config": {
"github.com/devopsfaith/krakend-httpcache": {}
}
}
]
8. 路由阴影或镜像
有时候,您一直在使用新版本的微服务,完整的重构,危险的更改或任何其他有价值的更改,都需要谨慎进行,并且将其投入使用太冒险了,因为可能存在影响您的问题终端用户。
该交通阴影或流镜像功能,您可以测试在生产新的后端通过发送流量他们副本,但忽略了他们的反应。
当您将后端作为影子后端添加到任何端点时,KrakenD会照常继续将请求发送到所有后端,但是标记为“ 影子”的响应将被忽略,并且不会在响应中返回或合并。
将流量镜像到微服务可以使您从观察生产行为的有趣角度测试新的后端。例如,您可以:
- 通过检查其日志来测试应用程序错误
- 测试应用程序的性能
- 强调新服务器
- 检索其他所有有趣的数据,这些数据只有在生产中正在运行时才能看到。
要将后端定义为影子后端,只需添加标记,如下所示:
"extra_config": {
"github.com/devopsfaith/krakend/proxy": {
"shadow": true
}
}
通过此更改,包含该标志的后端进入生产,但是KrakenD忽略其响应。
示例
以下示例显示了一个从v1到更改的后端v2,但是我们仍然不确定在生产环境中进行此更改的影响,因此我们希望首先将请求的副本发送到v2,但是让最终用户继续接收v1仅来自以下方面的回复:
{
"endpoint": "/user/{id}",
"timeout": "150ms",
"backend": [
{
"host": [ "http://my.api.com" ],
"url_pattern": "/v1/user/{id}"
},
{
"host": [ "http://my.api.com" ],
"url_pattern": "/v2/user/{id}"
"extra_config": {
"github.com/devopsfaith/krakend/proxy": {
"shadow": true
}
}
}
]
},
9. 数组操作
1. 数组操作-flatmap
平面图中间件允许您通过将数组结构展平和扩展为对象来操作数组,反之亦然。该过程由flatmap组件自动完成,使您可以专注于要执行的操作类型。
请使用常规的数据处理操作(例如)
target,blacklist或whitelist在适合的情况下使用,因为它们的计算成本较低。
仅当您需要操作数组时,flatmap组件才有意义,而不是所有对象的通用解决方案。
flatmap组件是krakend代理操作的一部分,因此需要作为配置extra_config内部包含backend。您可以执行两种不同类型的操作:
在flatmap_filter数组内部,您定义了要应用的操作序列。
2. flatmap配置
flatmap配置需要一个包含要执行的操作序列的数组。每一个操作定义与含有两个属性的对象:type和args。
组件结构如下:
"extra_config": {
"github.com/devopsfaith/krakend/proxy": {
"flatmap_filter": [
{
"type": "move",
"args": ["target_in_collection", "destination_in_collection"]
},
{
"type": "del",
"args": ["target_in_collection"]
}
]
}
}
1. 运作方式
两种类型的操作定义如下:
-
移动
:将集合移动或重命名为另一个。
"type": "move""args": ["target_in_collection", "destination_in_collection"]
-
删除
:删除收藏集
"type": "del""args": ["target_in_collection_to_delete"]
移动和删除都适用于参数中的最后一项。例如,删除后的a.b.c删除将c保留a.b在响应中。
2. 将flatmap与其他操作混合
当启用flatmap过滤器,操作group和target保持他们的功能,但是whitelist,blacklist和mapping被忽略。
3. 数据表示形式 args
args进行操作的参数()的格式非常简单。简而言之,对象嵌套用点表示,而数组的索引用数字或通配符表示其所有项。所以:
- 键由点运算符分隔
. - 通配符
*匹配任何类型的键值(属性名称,集合键名称或其索引) - A
number标识集合的最后一个位置是N-1,0它是它的起始位置。
举例说明
我们将使用基本的JSON结构作为数据表示的示例,请参见下文:
{
"a": [
{
"b1": [
{
"c": 1,
"d": "foo"
},
{
"c": 2,
"d": "bar"
}
],
"b2": true
},
{
"b1": [
{
"c": 3,
"d": "vaz"
}
]
}
]
}
观察结果
从这个例子中注意到……
a和b1是包含对象的数组。b2,c并且d是基本类型- 由于
a是数组("a": []),因此我们需要使用flatmap组件。如果它是一个对象("a": {}),我们将使用黑名单或白名单
代表一些价值
现在我们已经熟悉了结构,让我们表示相同的值:
| 符号 | 值 |
|---|---|
a |
内容一:[{"b1": [{"c": 1,"d": "foo"},{"c": 2,"d": "bar"}],"b2": true}, {"b1": [{"c": 3,"d": "vaz"}]}] |
a.1 |
第二对象一个键值:{"b1": [ { "c": 3, "d": "vaz" } ]} |
a.0.b1.0.d |
foo |
a.1.b1.0.d |
vaz |
a.*.b1.*.d |
3个匹配的值:foo,bar,vaz |
a.*.*.*.d |
3个匹配的值:foo,bar,vaz |
有关操作的实际示例
以上示例结构的一些单独操作:
| 目标 | 目的地 | 正确? | 注释 |
|---|---|---|---|
"a.*.b1.*.c" |
"a.*.b1.*.d" |
正确 | 重命名c为d |
"a.*.b1.*.c" |
"a.*.c" |
错误 | 缺少水平 |
"a.b1.c" |
"c" |
错误 | 之后缺少阵列 a |
"a.0.b1.0.c" |
"c" |
正确 | 仅从c第一项和第一项中提取 |
"a.*.b1.c" |
"c" |
错误 | 目标不正确,b1周围有一个数组c |
"a.*.b1.c" |
"a.*.b1.*.d.*.e" |
错误 | 目标不正确,b1周围有一个数组c |
"a.*.b1.*.c" |
"a.*.b1.*.c.d.e.f.g" |
正确 | 添加其他级别 |
"a.*.b1.*.c" |
"a.*.x.*.c" |
错误 | 错误,重命名x为不在最后位置的元素 |
"a.*.b1.*.c" |
"a.*.x.*.c.d.e.f.g" |
错误 | 错误,重命名x为不在最后位置的元素 |
"a.*.b1.*.c" |
"a.*.b1.*.d.*.e" |
错误 | 不正确,目标路径比源路径具有更多的通配符 |
配置实例
下面的示例演示如何通过执行以下操作来修改集合:
"extra_config": {
"github.com/devopsfaith/krakend/proxy": {
"flatmap_filter": [
{
"type": "move",
"args": ["schools.42.students", "alumni"]
},
{
"type": "del",
"args": ["schools"]
},
{
"type": "del",
"args": ["alumni.*.password"]
},
{
"type": "move",
"args": ["alumni.*.PK_ID", "alumni.*.id"]
}
]
}
}
我们在这里做了什么?
为了执行以下操作,需要执行以下4个操作序列:
- 提取所有
students的的43rd学校(数组从0开始),把他们下一个新的属性alumni - 摆脱所有剩余的学校
- 删除
password数组中具有属性的所有项目 - 将所有具有属性的项目重命名
PK_ID为id
有关更多示例,请参见测试文件。
10. 抓换请求和响应
1. 使用Martian修改请求和响应
使用krakend-martian组件,您可以通过配置文件中的简单DSL定义来转换请求和响应。Martian works 与CEL验证完美结合。
当您想要拦截最终用户的请求并在将内容传递给后端之前进行修改时,请使用Martian。同样,反过来,在将后端响应传递给用户之前,先对其进行转换。
Martian works 强大,给您无尽的可能性来控制网关进出的内容。典型的Martian works 场景的一些示例是:
- 在网关处理期间设置新的cookie
- 添加,删除或更改特定的headers
- 在发出后端请求之前查询字符串添加(例如,设置API密钥)
与Martian works 可以进行四种不同类型的互动:
- 修饰符:更改请求或响应的状态。例如,您想要在将请求发送到后端之前在请求中添加自定义header。
- 过滤器:添加条件以执行包含的修饰符
- 组:捆绑多个操作以按照组中指定的顺序执行
- 验证者:根据预期跟踪网络流量
2. 转换请求和响应
在配置extra_config中endpoint使用名称空间的下添加Martian修饰符github.com/devopsfaith/krakend-martian。
您的配置必须如下所示:
"endpoint": "/foo",
"extra_config": {
"github.com/devopsfaith/krakend-martian": {
// modifier configuration here
}
}
修改器配置
在以下示例中,您会发现所有修饰符都有一个名为的配置键scope。范围表示当应用调节剂,它可以是含有一个阵列request,response或二者。每个修改器中的其余键取决于修改器本身。
3. 转换header
所述header.Modifier注入具有特定值的报头。例如,以下配置X-Martian在请求和响应中都添加了header。
"endpoint": "/foo",
"extra_config": {
"github.com/devopsfaith/krakend-martian": {
"header.Modifier": {
"scope": ["request", "response"],
"name": "X-Martian",
"value": "true"
}
}
}
4. 修改body
通过,body.Modifier您可以修改请求和响应的主体。body的内容必须以编码base64。
以下修饰符将请求和响应的主体设置为{"msg":"you rock!"}。请注意,该body字段已base64编码。
"extra_config": {
"github.com/devopsfaith/krakend-martian":
{
"body.Modifier": {
"scope": ["request","response"],
"body": "eyJtc2ciOiJ5b3Ugcm9jayEifQ=="
}
}
}
5. 转换URL
将url.Modifier让您在URL中更改设置。例如:
"endpoint": "/foo",
"extra_config": {
"github.com/devopsfaith/krakend-martian": {
"url.Modifier": {
"scope": ["request"],
"scheme": "https",
"host": "www.google.com",
"path": "/proxy",
"query": "testing=true"
}
}
}
6. 注入查询字符串参数
在querystring.Modifier允许修改注射密钥对的查询字符串。如果您希望网关向后端发送一些额外的信息,则可能会很有用,例如:
{
extra_config": {
"github.com/devopsfaith/krakend-martian": {
"querystring.Modifier": {
"scope": ["request"],
"name": "api-key",
"value": "some.api.key.here"
}
}
}
}
7. 复制header
尽管没有广泛使用,但是它们header.Copy使您可以使用其他名称来复制header。
{
extra_config": {
"github.com/devopsfaith/krakend-martian": {
"header.Copy": {
"scope": ["request", "response"],
"from": "Original-Header",
"to": "Copy-Header"
}
}
}
}
8. 连续应用多个修改器
上面的所有示例在请求或响应中执行单个修改。但是,fifo.Group允许您创建连续执行的修饰符列表。当使用多个修饰符时,该组是必需的,并且将以下所有操作封装在modifiers数组中执行。即使列表中只有一个修饰符,也可以使用FIFO组。
用法示例(修改body,并设置header):
"extra_config": {
"github.com/devopsfaith/krakend-martian": {
"fifo.Group": {
"scope": ["request", "response"],
"aggregateErrors": true,
"modifiers": [
{
"body.Modifier": {
"scope": ["request"],
"body": "eyJtc2ciOiJ5b3Ugcm9jayEifQ=="
}
},
{
"header.Modifier": {
"scope": ["request", "response"],
"name": "X-Martian",
"value": "true"
}
}
]
}
}
}
9. 所有martian修改器,验证器和过滤器
martian库带有+25个可以使用的修饰符,我们没有在文档中列出所有选项。相反,我们提供了使用火星人时关键的修饰符。
有关修饰符和用法的完整列表,请参见Google的Martian存储库。这些是KrakenD-CE中包含的软件包:
- github.com/google/martian/body
- github.com/google/martian/cookie
- github.com/google/martian/fifo
- github.com/google/martian/header
- github.com/google/martian/martianurl
- github.com/google/martian/port
- github.com/google/martian/priority
- github.com/google/martian/stash
- github.com/google/martian/status
10. 建立新的修饰符
有时候,您想创建一个新的修饰符来覆盖您的特定用例并执行一些其他动态操作。创建更多的修饰符是一个简单的过程,仅make在编码后才需要网关。
没有什么比演示如何创建新修饰符的示例更好。我们的SRE总监(不熟悉Go的人)经历了创建新修改器的过程,该修改器将针对Marvel API自动进行身份验证,添加了API密钥,时间戳和计算得出的哈希值。
在此处阅读(包含源代码):Marvel示例:添加自动API身份验证
11. 消息队列--RabbitMQ
API网关与AMQP消息传递集成
AMQP组件允许通过API网关向队列发送消息和从队列接收消息。
队列的配置是一个简单的过程。要将端点连接到消息传递系统,只需要extra_config在名称空间github.com/devopsfaith/krakend-amqp/consume或中包含密钥github.com/devopsfaith/krakend-amqp/produce。
该集成的参数遵循AMQP规范。要了解某个参数的含义,请参阅《AMQP完整参考指南》。
KrakenD为您创建交换和队列。
常用设定
使用者和生产者都具有以下共同的配置密钥:
name- 字符串作为队列名称exchange- 字符串交换名称(topic如果已经存在,则必须具有类型)。routing_key-[] 字串durable- 建议使用booltrue,但要视使用情况而定。delete- 建议在使用者断开连接时避免布尔值false删除exclusive- 布尔no_wait- 布尔
以下配置演示了消费者和生产者如何创建整个发布/订阅模式。
1. 消费者
当KrakenD端点插入其AMQP后端时,使用者从队列中检索消息。建议将使用者连接到GET端点。
单个端点可以使用来自N个队列的消息,或者可以通过添加具有正确队列名称的N个后端来使用同一队列的N条消息。
例
运行使用者的所需配置为:
"backend": [
{
"host": [
"amqp://guest:guest@myqueue.host.com:5672"
],
"disable_host_sanitize": true,
"extra_config": {
"github.com/devopsfaith/krakend-amqp/consume": {
"name": "queue-1",
"exchange": "some-exchange",
"durable": true,
"delete": false,
"exclusive": false,
"no_wait": true,
"no_local": false,
"routing_key": ["#"],
"prefetch_count": 10
}
}
}
消费者设置
使用者的参数的完整列表为:
- 上面的所有常用设置以及:
prefetch_count- 整数prefetch_size- 整数no_local- 布尔
2. 生产者
生产者将消息发布到消息传递系统以供您异步使用。建议将生产者插入POST端点。
值得一提的是,生产者需要您在请求中传递一个正文,并且端点应声明,headers_to_pass以便生产者知道header。
运行生产者所需的配置如下:
"endpoint": "/producer",
"headers_to_pass": [ "...", "..." ],
"backend": [
{
"host": [
"amqp://guest:guest@myqueue.host.com:5672"
],
"disable_host_sanitize": true,
"extra_config": {
"github.com/devopsfaith/krakend-amqp/produce": {
"name": "queue-1",
"exchange": "some-exchange",
"durable": true,
"delete": false,
"exclusive": false,
"no_wait": true,
"mandatory": true,
"immediate": false
}
}
}
生产者设置
生产者参数的完整列表为:
- 上面的所有常用设置以及:
prefetch_count- 整数prefetch_size- 整数mandatory- 布尔immediate- 布尔
此外,以下这些项目是可以在端点URL中存在并传递给生产者的参数键:
exp_key- 字符串reply_to_key- 字符串msg_id_key- 字符串priority_key- 字符串 -请求参数的关键字,用作生成的消息的优先级值。routing_key- 字符串 -请求参数的关键字,用作生成的消息的路由值。
例如,endpoint可以将URL声明为/produce/{a}/{b}/{id}/{prio}/{route},并且生产者知道如何使用以下配置来映射它们:
{
...
"exp_key":"a",
"reply_to_key":"b",
"msg_id_key":"id",
"priority_key":"prio",
"routing_key":"route"
}
12 . 发布者/订阅者
使用发布者/订阅作为后端
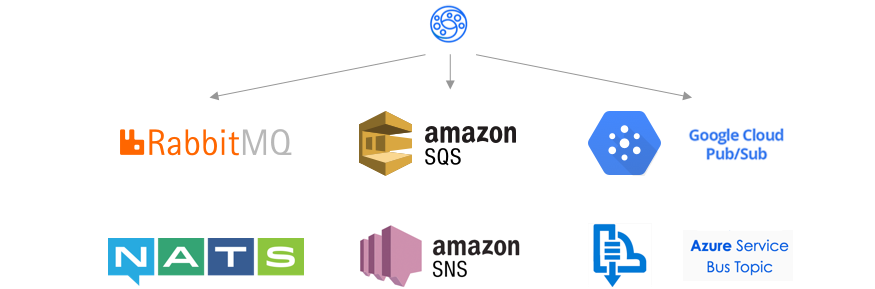
从KrakenD 1.0开始,您可以将端点连接到多个发布/订阅后端,从而帮助您与事件驱动的体系结构集成。例如,前端客户端可以使用REST接口将事件推送到队列。或者,客户端可以使用REST端点,该端点插入到后端中推送的最后一个事件。您甚至可以验证消息和格式,因为可以使用所有KrakenD可用的中间件。支持的后端技术的列表是:
- AWS SNS(简单通知服务)和SQS(简单队列服务)
- Azure Service Bus主题和订阅
- GCP PubSub
- NATS.io
- RabbitMQ
1. 组态
要将发布/订阅功能添加到后端extra_config,请在的下方包含以下名称空间backend:
对于订户:
"github.com/devopsfaith/krakend-pubsub/subscriber": {
"subscription_url": "schema://url"
}
对于发布者:
"github.com/devopsfaith/krakend-pubsub/publisher": {
"topic_url": "schema://url"
}
具体schema://url取决于您要连接的后端类型,如下所述:
2. GCP PubSub
Google的Cloud Pub / Sub是一项完全托管的实时消息传递服务,可让您在独立的应用程序之间发送和接收消息。
如Google文档所述,要连接到GCP PubSub,连接使用环境中的默认凭据。
您需要使用的架构是:
- 主题:
"gcppubsub://projects/myproject/topics/mytopic"或简称"gcppubsub://myproject/mytopic" - 订阅:
"gcppubsub://projects/myproject/subscriptions/mysub"或简称"gcppubsub://myproject/mysub"
3. NATS
NATS.io是一个简单,安全,高性能的开源消息传递系统,适用于云本机应用程序,IoT消息传递和微服务架构。
架构: nats://mysubject
URL主机+路径用作主题。不支持查询参数。
4. AWS SNS
Amazon Simple Notification Service(SNS)是一项高可用性,持久性,安全性,完全托管的发布/ 订阅消息服务,使您能够解耦微服务,分布式系统和无服务器应用程序。Amazon SNS提供有关高吞吐量,基于推送的多对多消息传递架构的主题:awssns:///sns-topic-arn
对于SNS主题,URL的host + path用作主题Amazon资源名称(ARN)。由于ARN在其中带有“:”,并且URL主机名中的端口前面带有“:”,因此请将主机保留为空白并将ARN放在路径中(例如awssns:///arn:aws:service:region:accountid:resourceType/resourcePath)。
5. AWS SQS
Amazon Simple Queue Service(SQS)是一项完全托管的消息队列服务,使您能够解耦和扩展微服务,分布式系统和无服务器应用程序。
架构: awssqs://sqs-queue-url
对于SQS主题和订阅,URL的host + path会自动以“ https://”作为前缀,以创建队列URL。
6. Azure Service Bus主题和订阅
Microsoft Azure Service Bus支持一组基于云的,面向消息的中间件技术,包括可靠的消息队列和持久的发布/订阅消息。这些“代理”消息传递功能可以认为是解耦消息传递功能,这些功能支持使用Service Bus消息传递工作负载进行发布-订阅,时间解耦和负载平衡方案。
架构:
- 话题:
azuresb://mytopic - 订阅:
azuresb://mytopic?subscription=mysubscription
URL的主机+路径用作主题名称。对于订阅,必须在“ subscription”查询参数中提供订阅名称。
7. rabbitmq
RabbitMQ是最受欢迎的开源消息代理之一。
架构:
- 话题:
rabbit://myexchange - 订阅:
rabbit://myqueue
对于主题,URL的主机+路径用作交换名称。对于预订,URL的主机+路径用作队列名称。不支持查询参数。
13. Lambda函数
与AWS Lambda函数集成

Lambda集成允许您在KrakenD端点调用上调用Amazon Lambda函数。lambda函数返回的内容可以像其他后端一样对待和处理。
发送到Lambda函数的有效负载来自请求,并且取决于endpoint:
- 方法
GET:有效负载包含请求的所有参数。 - 非
GET方法:有效负载由请求中主体的内容定义。
您无需在中间设置Amazon API Gateway,因为KrakenD会为您完成这项工作。
1. Lambda配置
包含要求您使用名称空间extra_config在backend部分的代码中添加代码github.com/devopsfaith/krakend-lambda。
支持的参数是:
function_name:在AWS服务中保存的lambda函数的名称。function_param_name:{placeholder}设置函数名称的端点。您必须在两者之间选择function_name,function_param_name但不能两者都选择。region:该AWS标识符区域(例如:us-east-1,eu-west-2等)max_retries:在成功响应之前,您要执行功能的最长时间。endpoint:一个可选参数,用于自定义要调用的Lambda端点。当使用Localstack进行测试时很有用。
认证方式
KrakenD计算机需要在默认文件中拥有AWS凭证~/.aws/credentials。
设置凭据时,请确保在提供了凭据的KrakenD框中可调用lamdba。这意味着要让IAM用户具有策略和执行角色,以使您可以调用该功能
2. 例子
将Lambda关联到后端
当KrakenD端点连接到同一Lambda时,请使用以下配置:
"backend": [
{
"github.com/devopsfaith/krakend-lambda": {
"function_name": "lambda-function",
"region": "us-west1",
"max_retries": 1
}
}
从网址中获取lambda
当Lambda的名称取决于端点中传递的参数时,请改用以下配置:
"endpoint": "/call-a-lambda/{lambda},
"backend": [
{
"github.com/devopsfaith/krakend-lambda": {
"function_param_name": "lambda",
"region": "us-west1",
"max_retries": 1
}
}
在此示例中,function_param_name告诉我们在端点中设置lambda的占位符。在这种情况下,{lambda}。
在代码之后,调用GET /call-a-lambda/my-lambda将产生my-lambda对AWS中函数的调用。
14. 返回后端错误
返回后端错误的详细信息
当您愿意操纵或聚合数据时,KrakenD关于错误和状态代码的策略是向客户端隐藏任何后端详细信息。其背后的理念是客户必须与其基础服务脱钩。
另一方面,如果您的端点没有任何操作地连接到单个后端,则使用no-op编码将响应原样返回给客户端,并保留其形式:主体,标头,状态代码等。
您可以覆盖隐藏后端错误详细信息的默认策略。
1. 显示后端错误
如果您希望向客户端显示这些详细信息,则可以选择在网关响应中显示它们。为此,请return_error_details在后端配置中启用该选项,然后所有错误将显示在所需的密钥中。
将以下配置放入backend配置中:
"extra_config": {
"github.com/devopsfaith/krakend/http": {
"return_error_details": "backend_alias"
}
}
请注意,return_error_details为此后端设置了别名。
2. 后端失败的响应
当后端发生故障时,您会发现一个名为error_+ 的对象,backend_alias其中包含后端的详细错误。错误返回的结构包含状态码和主体:
"error_backend_alias": {
"http_status_code": 404,
"http_body": "404 page not found\n"
}
如果没有错误,则key将不存在。
3. 例
以下配置设置了一个具有两个后端的端点,这些端点通过两个不同的键返回其错误:
{
"endpoint": "/detail_error",
"backend": [
{
"host": ["http://127.0.0.1:8081"],
"url_pattern": "/foo",
"extra_config": {
"github.com/devopsfaith/krakend/http": {
"return_error_details": "backend_a"
}
}
},
{
"host": ["http://127.0.0.1:8081"],
"url_pattern": "/bar",
"extra_config": {
"github.com/devopsfaith/krakend/http": {
"return_error_details": "backend_b"
}
}
}
]
}
假设您backend_b失败了,但您的backend_a工作正常。客户端响应可能如下所示:
{
"error_backend_b": {
"http_status_code": 404,
"http_body": "404 page not found\n"
},
"foo": 42
}
9. 授权
1. JWT令牌概述
该JSON网络令牌规范是行业标准,以双方之间安全地在债权。该JWT是包含由受信任的机构签署的属性的键值对编码的JSON对象。
当JWT保护一组特定的端点时,对API网关的请求必须提供令牌。令牌的验证在每个请求中进行,包括签名的检查以及(可选)确保其发行者,角色和受众足以访问端点的保证。
仅在令牌有效并通过所有检查的情况下,用户才有权访问端点并继续请求。
KrakenD JWT实现
KrakenD同时实现了JWT签名和JWT验证模型,以保护端点免受那些无权使用该信息的不受欢迎用户的攻击,从而增强了安全性。
但是,像KrakenD 这样的无状态系统不会发行令牌。
2. JWT验证
JWT验证可屏蔽任意数量的所需端点,从而强制向API网关的请求以提供第三方发出的令牌。令牌的验证在每个请求中进行,包括签名的检查以及(可选)确保其发行者,角色和受众足以访问端点的保证。
JOSE组件**是负责验证令牌。
需要JWT验证的典型请求在Authorization标头中包含带有令牌的承载:
GET /resource HTTP/1.1
Host: krakend.example.com
Authorization: Bearer eyJhbGciOiJIUzI1NiIXVCJ9...TJVA95OrM7E20RMHrHDcEfxjoYZgeFONFh7HgQeyJhbGciOiJIUzI1NiJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IktyYWtlbkQiLCJpYXQiOjE1MTYyMzkwMjJ9.NVFYj2MhyvJjMESOg4ktIOfzak2ekD7IrCa9-UiO4QA
还有cookie?是的,您还可以在cookie中发送验证令牌。
我们认为JWT令牌在格式正确,由公认的发行者签名,未过期,有一些主张且未标记为已撤消时有效。
当您为最终用户生成令牌时,请确保设置低有效期限。令牌应该寿命短,建议在几分钟或几小时内过期。
1. 基本的JWT验证
JWT验证是针对每个端点的,并且必须存在于需要它的每个端点定义中。如果几个端点需要JWT验证,请考虑使用灵活的配置以避免重复声明。
通过在所需的的"github.com/devopsfaith/krakend-jose/validator"内部添加名称空间来启用JWT验证。extra_config``endpoint
例如,为了保护端点/protected/resource:
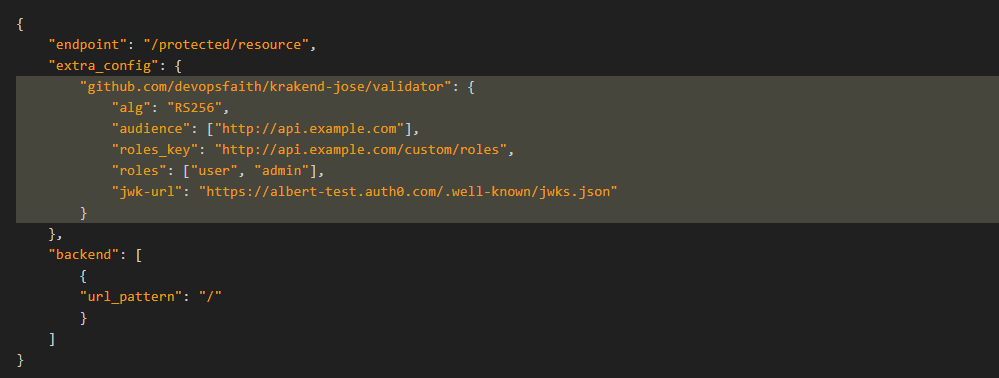
此配置确保:
- 令牌格式正确,没有过期
- 令牌具有有效的签名
- 用户的角色为
user或或admin(取自名为的JWT有效负载中的键http://api.example.com/custom/roles) - 令牌不会在Bloomfilter中被吊销(请参阅吊销令牌)。
JWT验证设置
以下设置可用于JWT验证。字段alg和jwk-url是必填字段,其余的键可以根据您的最佳方便添加或不添加。
将它们添加到"github.com/devopsfaith/krakend-jose/validator"名称空间下:
alg:识别的字符串。发行者使用的哈希算法。通常RS256。jwk-url:字符串。带有用于验证令牌的真实性和完整性的公共密钥的JWK端点的URL。cache:布尔值。将此值设置true为在接下来的15分钟内将JWK公钥存储在内存中,并避免锤击密钥服务器(为提高性能而建议使用)。高速缓存可以同时存储多达100个不同的公共密钥。audience:清单。当您要拒绝不包含列表受众的令牌时设置。roles_key:传递角色时,JWT有效负载内的键名称指定用户的角色。roles:清单。设置后,将拒绝不具有所列角色中至少一个的JWT令牌。issuer:字符串。设置后,与发行人不匹配的令牌将被拒绝。cookie_key:字符串。添加未在标头中传递时包含令牌的cookie的键名disable_jwk_security:布尔值。如果为true,则禁用JWK客户端的安全性,并允许不安全的连接(纯HTTP)下载密钥。jwk_fingerprints:字符串列表。用于固定证书并避免中间人攻击的指纹列表(证书的唯一标识符)。以base64格式添加指纹。cipher_suites:整数列表。覆盖默认密码套件。除非您有旧版JWK,否则无需添加此值。
有关公认的算法和密码套件的完整列表,请向下滚动至文档末尾。
以下示例包含每个可用的选项:
"endpoint": "/foo"
"extra_config": {
"github.com/devopsfaith/krakend-jose/validator": {
"alg": "RS256",
"jwk-url": "https://url/to/jwks.json",
"cache": true,
"audience": [
"audience1"
],
"roles_key": "department",
"roles": [
"sales",
"development"
],
"issuer": "http://my.api.com",
"cookie_key": "TOKEN",
"disable_jwk_security": true,
"jwk_fingerprints": [
"S3Jha2VuRCBpcyB0aGUgYmVzdCBnYXRld2F5LCBhbmQgeW91IGtub3cgaXQ=="
],
"cipher_suites": [
10, 47, 53
]
}
}
2. 一个完整的运行示例
该KrakenD游乐场演示了如何使用保护JWT端点,包括准备使用用一个例子来自Auth0单页的应用。要尝试,请克隆游乐场并按照自述文件进行操作。
3. 支持的哈希算法和密码套件
散列算法
该alg字段的接受值为:
EdDSA:EdDSAHS256:HS256-使用SHA-256的HMACHS384:HS384-使用SHA-384的HMACHS512:HS512-使用SHA-512的HMACRS256:RS256-使用SHA-256的RSASSA-PKCS-v1.5RS384:RS384-使用SHA-384的RSASSA-PKCS-v1.5RS512:RS512-使用SHA-512的RSASSA-PKCS-v1.5ES256:ES256-使用P-256和SHA-256的ECDSAES384:ES384-使用P-384和SHA-384的ECDSAES512:ES512-使用P-521和SHA-512的ECDSAPS256:PS256-使用SHA256和MGF1-SHA256的RSASSA-PSSPS384:PS384-使用SHA384和MGF1-SHA384的RSASSA-PSSPS512:PS512-使用SHA512和MGF1-SHA512的RSASSA-PSS
密码套件
密码套件的可接受值为:
5:TLS_RSA_WITH_RC4_128_SHA10:TLS_RSA_WITH_3DES_EDE_CBC_SHA47:TLS_RSA_WITH_AES_128_CBC_SHA53:TLS_RSA_WITH_AES_256_CBC_SHA60:TLS_RSA_WITH_AES_128_CBC_SHA256156:TLS_RSA_WITH_AES_128_GCM_SHA256157:TLS_RSA_WITH_AES_256_GCM_SHA38449159:TLS_ECDHE_ECDSA_WITH_RC4_128_SHA49161:TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA49162:TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA49169:TLS_ECDHE_RSA_WITH_RC4_128_SHA49170:TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA49171:TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA49172:TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA49187:TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA25649191:TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256
默认套件为:
49199:TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA25649195:TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA25649200:TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA38449196:TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA38452392:TLS_ECDHE_RSA_WITH_CHACHA20_POLY130552393:TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305
3. JWT签名
JWT签名组件旨在创建一个端点包装,当您的应用程序返回纯文本令牌时,该包装返回签名的令牌。令牌返回给使用您的密钥签名的用户,该密钥可以保存在网关或受信任的计算机中。使用令牌签名,您就可以控制私钥,并且无需信任外部源即可为您保留私钥。
该JOSE组件负责签署令牌。
1. 要求
您需要一个后端(不是KrakenD),该后端公开一个能够发出令牌的端点,以及另一个用于刷新令牌的端点。
例如,您的后端可能有一个类似的终结点/token-issuer,当接收到POST能够识别用户的正确参数时,会返回如下内容:
curl -X POST --data '{"user":"john","pass":"doe"}' https://backend/token-issuer
{
"access_token": {
"aud": "http://api.example.com",
"iss": "https://myapp.example.com",
"sub": "1234567890qwertyuio",
"jti": "mnb23vcsrt756yuiomnbvcx98ertyuiop",
"roles": ["role_a", "role_b"],
"exp": 1735689600
},
"refresh_token": {
"aud": "http://api.example.com",
"iss": "https://myapp.example.com",
"sub": "1234567890qwertyuio",
"jti": "mnb23vcsrt756yuiomn12876bvcx98ertyuiop",
"exp": 1735689600
},
"exp": 1735689600
}
2. 基本的JWT签名
当您的应用程序知道如何发行令牌时,可以在将其自动通过网关传递给用户之前对其进行签名。为了实现这一点,我们仅发布KrakenD一个名为/ token的新端点(选择您的名字),而不是发布在/ token-issuer下生成普通令牌的内部后端。该端点转发在POST中接收到的数据(在示例中选择),并在后端回复时返回签名的令牌。
例如,在上面的普通令牌中,我们希望对键“ access_token”和“ refresh_token”进行签名,以便没有人可以修改其内容。我们需要这样的配置:
"endpoint": "/token",
"method": "POST",
"backend": [
{
"host": [ "https://backend" ],
"url_pattern": "/token-issuer"
}
],
"extra_config": {
"github.com/devopsfaith/krakend-jose/signer": {
"alg": "HS256",
"kid": "sim2",
"keys-to-sign": ["access_token", "refresh_token"],
"jwk-url": "http://backend/jwk/symmetric.json"
}
}
...
请注意,提供了JSON Web密钥来对内容进行签名。生成密钥并保存在安全的地方。
这里发生的是,用户/token向网关请求a ,并且将发行委托给后端。使用纯令牌的后端响应是使用您的私有JWK签名的。然后用户收到签名的令牌,例如:
{
"access_token": "eyJhbGciOiJIUzI1NiIsImtpZCI6InNcdTIifQ.eyJhdWQiOiJodHRwOi8vYXBpLmV4YW1wbGUuY29tIiwiZXhwIjoxNzM1Njg5NjAwLCJpf1MiOiJodHRwczovL2tyYWtlbmQuaW8iLCJqdGkiOiJtbmIyM3Zjf1J0NzU2eXVcd21uYnZjeDk4ZXJ0eXVcd3AiLCJyb2xlcyI6WyJyb2xlX2EiLCJyb2xlX2IiXSwif1ViIjoiMTIzNDU2Nzg5MHF3ZXJ0eXVcdyJ9.htgbhantGcv6zrN1i43Rl58q1sokh3lzuFgzfenI0Rk",
"exp": 1735689600,
"refresh_token": "eyJhbGciOiJIUzI1NiIsImtpZCI6InNcdTIifQ.eyJhdWQiOiJodHRwOi8vYXBpLmV4YW1wbGUuY29tIiwiZXhwIjoxNzM1Njg5NjAwLCJpf1MiOiJodHRwczovL2tyYWtlbmQuaW8iLCJqdGkiOiJtbmIyM3Zjf1J0NzU2eXVcd21uMTI4NzZidmN4OThlcnR5dWlvcCIsInN1YiI6IjEyMzQ1Njc4OTBxd2VydHl1aW8ifQ.4v36tuYHe4E9gCVO-_asuXfzSzoJdoR0NJfVQdVKidw"
}
3. 一个完整的运行示例
该KrakenD游乐场演示了如何在签署令牌/token端点,包括准备使用的例子。要尝试,请克隆游乐场并按照自述文件进行操作。
4. JWT签名设置
以下设置可用于签署JWT:
alg:识别的字符串。发行者使用的哈希算法。通常RS256。jwk-url:字符串。带有用于签署令牌的私钥的JWK端点的URL。kid:字符串。密钥ID成员的目的是匹配特定的密钥,因为jwk-url可能包含多个密钥。keys-to-sign:字符串列表。需要签名的所有特定密钥的列表。
可选的:
full:布尔值。使用JSON格式,而不是JWT提供的紧凑格式。disable_jwk_security:布尔值。如果为true,则禁用JWK客户端的安全性,并允许不安全的连接(纯HTTP)下载密钥。jwk_fingerprints:字符串列表。用于固定证书并避免中间人攻击的指纹列表(证书的唯一标识符)。以base64格式添加指纹。cipher_suites:整数列表。覆盖默认密码套件。除非您有旧版JWK,否则无需添加此值。
以下示例包含每个可用的选项:
"endpoints": [
{
"endpoint": "/token",
"method": "POST",
"extra_config": {
"github.com/devopsfaith/krakend-jose/signer": {
"alg": "HS256",
"jwk-url": "http://backend/jwk/symmetric.json",
"keys-to-sign": [
"access_token",
"refresh_token"
],
"kid": "sim2",
"cipher_suites": [
5,
10
],
"jwk_fingerprints": [
"S3Jha2VuRCBpcyB0aGUgYmVzdCBnYXRld2F5LCBhbmQgeW91IGtub3cgaXQ=="
],
"full": true,
"disable_jwk_security": true
}
}
}
]
4. 销毁令牌
吊销有效令牌
API网关授权根据您的条件提供有效令牌的用户,但是在某些时候,您可能想改变主意并决定撤销应该仍然有效的令牌。
吊销有效令牌的示例可能是您的应用程序的管理员决定用户不再能够登录到系统,或者您想要为子集或所有用户强制重新协商令牌,因为您不打算这样做。等待到期。
KrakenD集成了Bloomfilter组件,该组件允许您以优化的方式存储令牌以撤销后续请求。激活bloomfilter时,将像bloomfilter一样将令牌检查为黑名单,并且如果用户的令牌与bloomfilter匹配,则不允许访问。
bloomfilter组件具有以下功能:
- 将列入黑名单的令牌保存在内存中
- 通过RPC接口单独或批量管理令牌。
- 检查令牌并放弃对肯定消息的访问
1. 为什么选择bloomfilters?
Bloomfilters非常适合以很少的内存消耗支持大量拒绝令牌。例如,任何大小的1亿个令牌消耗约0.5GB RAM(999,925,224个令牌中的误报率为1),并且查找在恒定时间内完成(k个哈希)。使用键值或关系数据库无法获得这些数字。
令牌位于内存中,直接位于拒绝器界面中,因此系统可以快速解决匹配问题。
2. 额外资源
如果您想通过示例学习bloomfilters,请查看以下资源:
3. 集群中的令牌到期
所有的KrakenD节点都是无状态的,并且各自动作。每个节点都需要接收有关需要在每个本地Bloomfilter中插入的任何令牌的RPC通知。服务运行时,bloomfilter会更新,但是节点之间的同步级别取决于您如何将它们推送到群集中。该系统最终是一致的。
该组件为您提供了Bloomfilter管理,但是您仍然需要实现管理部分,该管理部分用作这些令牌的源以及对它们的推送(例如,队列和使用者)。
5. OAuth 2.0客户端token
通过OAuth 2.0客户端凭据,Grant KrakenD可以向您的授权服务器请求访问令牌,以访问受保护的资源。
客户端凭据授权KrakenD作为客户端访问受保护的资源。不要将此与授权最终用户混淆(请参阅JWT)。
成功地为后端设置客户端凭据意味着KrakenD可以获取受保护的内容,但是提供给最终用户的端点将是公共的,除非您使用JWT保护它。
1. 配置OAuth2客户端token
要使用客户端凭证访问受保护的资源,请在每个backend适当的下方添加extra_config。
使用的名称空间是"github.com/devopsfaith/krakend-oauth2-clientcredentials"。下面的示例配置:
{
"endpoint": "/endpoint",
"backend": [
{
"url_pattern": "/protected-resource",
"extra_config": {
"github.com/devopsfaith/krakend-oauth2-clientcredentials": {
"client_id": "YOUR-CLIENT-ID",
"client_secret": "YOUR-CLIENT-SECRET",
"token_url": "https://your.custom.identity.service.tld/token_endpoint",
"endpoint_params": {
"audience": ["YOUR-AUDIENCE"]
}
}
}
}
]
}
该组件的设置为:
client_idstring:提供给Auth服务器的客户端IDclient_secretstring:提供给Auth服务器的秘密字符串token_urlstring:令牌协商发生的端点URLscopes:string,optional所需范围的逗号分隔列表,例如:scopeA,scopeBendpoint_paramslist,可选:请求令牌时要包含在有效负载中的任何其他参数。例如,经常添加audience请求参数,该参数表示应为其发出令牌的目标API。
2. Auth0整合
以下示例演示了满足Auth0要求的完整配置。它基本上与我们上面显示的配置相同,但有一些附加功能,在代码后进行了解释:
{
"endpoint": "/endpoint",
"backend": [
{
"url_pattern": "/backend",
"extra_config": {
"github.com/devopsfaith/krakend-oauth2-clientcredentials": {
"client_id": "YOUR-CLIENT-ID",
"client_secret": "YOUR-CLIENT-SECRET",
"token_url": "https://custom.auth0.tld/token_endpoint",
"endpoint_params": {
"client_id": ["YOUR-CLIENT-ID"],
"client_secret": ["YOUR-CLIENT-SECRET"],
"audience": ["YOUR-AUDIENCE"]
}
},
"github.com/devopsfaith/krakend-martian": {
"fifo.Group": {
"scope": ["request", "response"],
"aggregateErrors": false,
"modifiers": [
{
"header.Modifier": {
"scope": ["request"],
"name" : "Accept",
"value" : "application/json"
}
}
]
}
}
}
}
]
}
上面的代码适用于Auth0。与基本示例的区别在于:
- id和secret作为传递
endpoint_params,因为auth0忽略auth标头,并希望将凭据作为JSON数据或表单主体发送。 - 的
Accept发送给auth0的请求时,需要报头。该krakend-martian组件将请求修改到后端以执行此操作。
10. 服务发现
1. 服务发现概述
服务发现使客户端能够自动检测和定位企业网络上的服务。无需定义指向后端的IP或主机名的静态列表,您可以使用服务发现提供程序并使KrakenD与之交互以动态获取主机。
1. 静态解析
该static决议是默认的服务发现选择。它使用配置文件中声明的主机列表,并且KrakenD必须能够通过主机名,DNS或IP直接访问它们。列表中所有服务器之间的所有必要连接均经过负载平衡。
使用"sd": "static"配置文件中是可选的。
"backend": [
{
"url_pattern": "/some-url",
"sd": "static",
"host": [
"http://my-service-01.api.com:9000",
"http://my-service-02.api.com:9000"
]
}
]
2. DNS SRV
将使用针对KrakenD的典型服务发现集成DNS SRV。它是许多其他系统工作使用的市场标准,例如Kubernetes,Mesos,Haproxy,Nginx plus,AWS ECS,Linkerd等。
最典型的设置是KrakenD + Consul(请参阅标准查找)。
请参阅DNS SRV服务发现
3. etcd
KrakenD可以监视etcd安装中的键的值,并在更改时重新配置自身。
与etcd的集成使您可以设置分布式键值存储并配置详细信息,例如超时,保持活动状态和证书。
查看etcd服务发现
4. Eureka
支持Netflix Eureka客户端。该软件包是Schibsted工程师提供的开源软件。
请参阅Eureka服务发现
2. SD with DNS SRV (e.g. Consul)
这DNS SRV是Kubernetes,Mesos,Haproxy,Nginx plus,AWS ECS,Linkerd等系统使用的市场标准。
要将Consul集成为Service Discovery或任何其他DNS SRV兼容的系统,您只需设置两个密钥:
"sd": "dns":设置服务发现= DNS SRV"host": []:提供解析的所有名称的列表
这些密钥需要在backend配置部分中添加。host如果host配置的根级别中还有另一个密钥,则可以跳过该密钥。
例如:
...
"backend": [
{
"url_pattern": "/foo",
"sd": "dns",
"host": [
"api-catalog.service.consul.srv"
],
"disable_host_sanitize": true
}
]
...
3. 使用etcd进行服务发现
etcd服务发现集成使您可以使用现有的etcd设置执行主机解析。
集成etcd由krakend-etcd组件控制,并为etcd添加了客户端和订户功能。
1. 启用etcd
要启用etcd,请在配置文件的根目录中添加必要的设置:
{
"version": 2,
"extra_config": {
"github_com/devopsfaith/krakend-etcd": {
"machines": [
"https://192.168.1.100:4001",
"https://192.168.1.101:4001"
],
"dial_timeout": "5s",
"dial_keepalive": "30s",
"header_timeout": "1s",
"cert": "/path/to/cert",
"key": "/path/to/cert-private-key",
"cacert": "/path/to/CA-cert"
}
},
...
}
github_com/devopsfaith/krakend-etcd命名空间中唯一的必需键是machines,因此集成知道etcd的位置。配置中的其余键是可选的。
如果钥匙丢失的超时和保持活动将采取示值,和证书(cert,key,和cacert)不是,如果你使用普通的连接需要。
现在,您可以使用etcd后端了。
2. 使用etcd解析后端
启用集成后,在backend配置部分中添加以下密钥。host如果host配置的根级别中还有另一个密钥,则可以跳过该密钥。
"sd": "etcd":将etcd设置为服务发现"host": []:您要解决的所有服务的列表
例如,为单个后端设置服务发现:
...
"backend": [
{
"url_pattern": "/foo",
"sd": "etcd",
"host": [
"api-catalog"
],
"disable_host_sanitize": true
}
]
...
4. Eureka
Netflix服务Eureka的用户在我们的krakend-contrib存储库中列出了几个用户贡献的集成。
集成未与KrakenD-CE版本捆绑在一起,但可以将它们添加到项目中并轻松进行自定义构建。
- schibsted / krakend-eureka:Eureka客户Schibsted从2017年开始投入生产。
- joaoqalves / krakend-尤里卡:Eureka客户贡献的若昂阿尔维斯
11. 交通管理
1. 速率限制
节流概述
KrakenD提供了几种保护您的基础架构使用的方法,这些方法可能在不同的层次上起作用。
最重要的限制类型是速率限制,该速率限制使您可以限制最终用户的流量或KrakenD的后端服务流量。该速率限制主要包括以下目的:
- 避免对大量后端请求施加压力或使后端服务泛滥(代理速率限制)
- 为您的公开API建立使用配额(路由器速率限制)
- 为您的API创建简单的QoS策略
速率限制是断路器功能的补充。
1. 速率限制的类型
速率限制有两个不同的层:
- 路由器层:为到达KrakenD端点的最终用户设置最大吞吐量。
- 代理层:设置KrakenD和您的后端服务之间的最大吞吐量
要深入研究代码,请参阅速率限制中间件
限制集群速率
由于KrakenD是无状态API网关,并且没有任何集中化功能,因此这些限制将分别应用于每个KrakenD的运行实例。例如,如果您在中将端点限制为100 reqs / s,krakend.json并且您的集群部署了3个KrakenD实例,那么您的生态系统将限制为300 reqs / s。如果添加第四个节点,那么此限制将增加到400 reqs / s。
2. 断路器
所述断路器是一个状态机的请求,并且观察后端的失败的响应之间。当后端似乎出现故障时,KrakenD会停止发送更多流量,以避免在遭受痛苦的后端承受压力,直到后端被认为已恢复为止。
断路器是对堆栈的自动保护措施,可避免级联故障。
见断路器
3. 超时和空闲请求
KrakenD允许您微调用于访问后端的HTTP服务器和HTTP客户端的超时。根据IDLE连接,每个后端都有大量的IDLE连接,它直接影响代理层的性能。
2. 脚本程序探测
控制漫游器流量

脚本程序检测程序模块检查到网关的传入连接,以确定是否由脚本程序建立,从而帮助您检测和拒绝进行抓取,内容盗窃和形成垃圾邮件的僵尸程序。
通过检查User-Agent并将其值与您提供的一组配置规则进行比较来检测Bot。脚本检测程序模块未设置任何初始规则,这取决于您决定用例的最佳规则,并选择对脚本程序的限制或宽松程度。
由于脚本检测程序模块的配置非常灵活,因此您可以将其用于其他用途,而不仅仅是丢弃脚本程序请求。例如,您可以为移动应用程序User-Agent设置白名单规则,该规则将被允许与KrakenD交互并丢弃其余流量。
配置脚本检测规则
脚本检测程序的配置规则必须包含在文件根目录extra_config的命名空间github_com/devopsfaith/krakend-botdetector中krakend.json。
例如:
"extra_config": {
"github_com/devopsfaith/krakend-botdetector": {
"whitelist": ["MyAndroidClient/1.0", "Pingdom.com_bot_version_1.1"],
"blacklist": ["a", "b"],
"patterns": [
"(Pingdom.com_bot_version_).*",
"(facebookexternalhit)/.*"
],
"cacheSize": 0
}
}
脚本检测程序模块中的可用配置选项为:
whitelist:具有可连接的受信任用户代理的完全匹配的阵列。blacklist:不想要的机器人的精确匹配数组,可立即拒绝。patterns:包含定义脚本机器人的所有正则表达式的数组。匹配的脚本机器人被拒绝。cacheSize:有助于加快脚本检测速度的LRU缓存的大小。
请注意,whitelist和和blacklist都不希望使用正则表达式,而是文字字符串。此设计的目的是获得最佳性能,因为比较文字字符串比评估正则表达式要快得多。
另一方面,该patterns属性需要正则表达式。该语法与Perl,Python和其他语言使用的常规语法相同。更准确地说,它是RE2接受的语法
规则评估的顺序是依次的:whitelist-> blacklist-> patterns。当用户代理在任何先前的评估中匹配时,执行结束,并且连接被接受(白名单)或被拒绝(黑名单和模式)。
建立您的脚本检测规则
对抗垃圾邮件,蜘蛛,报废,盗窃和机器人攻击是一个问题。您可以选择不同的角度来使用机器人检测模块来对抗它。
也许您想让大量困扰机器人的正则表达式列表成为可能,并启用缓存。
或者,也许您只需要一个否定模式就可以丢弃所有您不知道合法的东西。
无论您决定设置什么规则,请记住,白名单和黑名单要快但不灵活,需要您设置确切的用户代理。另一方面,正则表达式非常方便,但是与之相比,评估它们的成本更高。
缓存
根据大量模式评估每个用户代理可能是一项耗时的操作。即使是几毫秒,您也可以通过设置来启用缓存,cacheSize并避免重新处理之前检查过的User-Agent。每毫秒都很重要!
LRU缓存系统是内存中的,不需要运行单独的服务器集,从而减少了操作麻烦。既没有缓存过期时间,也没有明确的缓存逐出。当/如果高速缓存已满,则最近使用最少的(LRU)元素将自动替换为新元素。一个兆字节的数量级应该足以保存不同的User-Agent请求和组合。
设置cacheSize一个具有固定缓存大小的整数,或者0禁用缓存。
3. 请求超时
超时时间
作为KrakenD,API网关可以与其他服务进行通信,因此能够控制不同方面的等待时间至关重要。KrakenD将允许您微调这些设置。
超时可以应用于:
- 整个管道的持续时间(从用户请求到用户响应)
- HTTP请求相关的超时
此外,您可以控制最大IDLE连接数。
1. 管道超时
1. 全局超时
首先,根目录级别中的timeout键krakend.json用于在管道的整个持续时间内(并且不仅限于与后端的连接)应用默认超时。超时考虑了请求,数据获取,操作和任何其他中间件之间的所有时间。您可以看到这是最终用户超时。
{
"version": 2,
"timeout": "2000ms",
...
}
2. 端点特定的超时
即使timeout根级别中的值也为所有端点设置了默认超时,您以后可以在任何特定端点上覆盖它。
为此,只需将其放在所需的端点内:
{
"version": 2,
"timeout": "2000ms",
"endpoints": [
{
"endpoint": "/splash",
"method": "GET",
"timeout": "1s"
...
}
]
}
上面的示例将对/splash端点使用1秒超时,对所有其他端点使用2000毫秒。
3. 达到超时时间会怎样?
当达到管道超时时,请求将被取消,并且用户会收到HTTP状态代码 500 Internal Server Error
2. HTTP请求超时
除了整个管道的超时,您还可以配置特定的HTTP层超时。下面的所有设置都与管道超时一样工作。如果将此值放置在端点中,它们将覆盖全局设置。
1. HTTP读取超时
读取整个HTTP请求(包括正文)的最大持续时间。
此超时不能使处理程序在每个请求正文的可接受截止日期上做出每个请求的决定。
{
"version": 2,
"read_timeout": "1s"
}
2. HTTP写超时
超时写入响应之前的最大持续时间。
每当读取新的请求标头时,都会将其重置。像HTTP读取超时一样,它也不允许处理程序根据每个请求做出决策。
{
"version": 2,
"write_timeout": "0s" (no timeout)
}
3. HTTP空闲超时
启用保持活动后,等待下一个请求的最长时间。
如果IdleTimeout为零,则使用ReadTimeout的值。如果两者均为零,则使用ReadHeaderTimeout。
{
"version": 2,
"idle_timeout": "0s" (no timeout)
}
4. HTTP读取header头超时
读取请求标头所允许的时间。
读取标头后,将重置连接的读取截止时间,处理程序可以决定对主体来说太慢的速度。
{
"version": 2,
"read_header_timeout": "10ms"
}
3. 时间单位
您可以使用以下任何单位来指定超时的时间单位是整数(不是float):
- 纳秒:
ns - 微秒:
us或µs - 毫秒:
ms - 秒:
s
它也可用,尽管您永远不要使用它们:
- 分钟:
m - 小时:
h
不同单位的等效超时示例包括:
"timeout": "1s",
"timeout": "1000ms",
"timeout": "1000000us",
"timeout": "1000000000ns",
4. 最大IDLE连接
每个后端都有大量的IDLE连接,直接影响代理层的性能。这就是为什么您可以使用该max_idle_connections设置控制号码的原因。例如:
{
"version": 2,
"max_idle_connections": 150,
...
}
到达时,KrakenD将关闭处于“保持活动”状态的空闲连接max_idle_connections。如果在配置文件中未设置任何值,则KrakenD默认使用250 。
每个生态系统都需要有自己的环境,请牢记以下几点:
- 如果您将数字设置得很高,则
max_idle_connections可能会耗尽系统的端口限制。 - 如果将数字设置得很低,则会频繁创建新的连接,并且连接重用率会降低。
有关传输层的更多信息,请参见MaxIdleConnsPerHost
12. 日志记录,指标和跟踪
1. 日志
服务启动时,如果未设置日志记录配置,则使用KrakenD框架的基本日志记录器功能将所有日志事件发送到标准输出。在这种情况下,报告级别为,DEBUG并且不向日志添加前缀。
扩展日志记录功能
不同的日志记录组件使您可以扩展日志记录功能,例如将事件发送到syslog,选择详细级别或使用Graylog扩展日志格式(GELF)。除此之外,还有许多出口商可以发送您的日志。
使用改进的日志记录gologging。
该组件gologging通过以下功能扩展了默认日志记录功能:
- 选择写入标准输出
- 选择写入系统日志
- 在日志行中添加前缀
- 选择报告级别
- 选择使用预定义或自定义格式
启用 gologging
要享受扩展的日志记录功能,需要在krakend.json配置中添加该组件。在根级别将其名称空间添加到extra_config中:
{
"version": 2,
"extra_config": {
"github_com/devopsfaith/krakend-gologging": {
"level": "INFO",
"prefix": "[KRAKEND]",
"syslog": true,
"stdout": true,
"format": "custom",
"custom_format": "%{message}"
}
}
上面的代码段显示了您可以配置的四个选项,下面进行说明。
设置报告级别
使用定义您希望在日志中看到的严重性level。公认的详细程度从高到低都有:
DEBUGINFOWARNINGERRORCRITICAL
写入系统日志或标准输出
对于每个触发的日志事件,输出可以写入syslog,stdout或两者。接受的值是布尔值。设置为true时,日志将写入所选目标:
"syslog": true"stdout": true
为所有行添加前缀
此外,您可能希望选择在每个记录的行中添加一个字符串,以便稍后可以使用外部工具快速过滤消息。
"prefix": "[ANY STRING]"
预定义和自定义格式
如果要遵循其他记录模式,则可以。
"format": "custom"
有效格式是: - default - logstash -custom
如果选择custom格式,则可以使用以下custom_format字段:
"custom_format": "%{message}"
使用的模式与go-logging库相同
Logstash
如果要使用通过标准输出的Logstash标准进行登录,您必须添加krakend-logstash集成在你的根目录krakend.json,里面的extra_config部分。将gologging要启用太大需求。
例如:
"extra_config": {
"github_com/devopsfaith/krakend-logstash": {
"enabled": true
}
"github_com/devopsfaith/krakend-gologging": {
"level": "INFO",
"prefix": "[KRAKEND]",
"syslog": false,
"stdout": true,
"format": "logstash"
}
}
2. 指标
指标中间件在其他端口中提供新服务,并/__stats/通过所有KrakenD指标的集合公开端点:
http://localhost:8080/__stats/
启用指标
为了向您的KrakenD安装添加度量,请在配置文件的根目录下添加github_com/devopsfaith/krakend-metrics到名称空间extra_config中,例如:
{
"version": 2,
"extra_config": {
"github_com/devopsfaith/krakend-metrics": {
"collection_time": "60s",
"proxy_disabled": false,
"router_disabled": false,
"backend_disabled": false,
"endpoint_disabled": false,
"listen_address": ":8090"
},
...
}
中间件的选项是:
collection_time:收集指标的时间窗口。默认为60秒。proxy_disabled:跳过代理层中发生的所有指标(针对您的后端的流量)router_disabled:跳过路由器层中发生的所有指标(KrakenD端点中的活动)backend_disabled:跳过后端层中发生的所有指标。endpoint_disabled:不发布/__stats/端点。指标无法通过端点访问,但仍会收集。listen_address:更改度量标准终结点所在的侦听地址。默认为:8090。
3. 追踪
从单个整体应用程序迁移到分布式微服务体系结构提出了新的挑战。可观察性和网络连接是在这种新情况下成功的关键,因此需要新的监视工具。这些工具必须至少提供选项,以检测问题的根本原因,监视和监视不同分布式事务的详细信息以及性能和延迟优化。
Opencensus导出器允许您将跟踪发送到其中一些开源和专用工具,因此您可以跟踪网关的活动以及派生到后端的请求。
启用跟踪对于详细了解网关内部以及用户,网关和您的服务之间的情况很关键。
支持以下跟踪导出器:
- Jaeger
- Zipkin
- AWS X-Ray
4. Graylog和GELF格式
由于krakend-gelf集成,KrakenD支持将GELF格式的结构化事件发送到Graylog群集。
GELF的设置非常简单,只需设置两个参数即可:
address:Graylog群集(或接收GELF输入的任何其他服务)的地址(包括端口)。enable_tcp:设置为false(推荐)以使用UDP。使用TCP时,性能可能会受到影响。
启用GELF
添加krakend-gelf集成在你的根目录krakend.json,里面的extra_config部分。将gologging要启用太大需求。
例如:
"extra_config": {
"github_com/devopsfaith/krakend-gelf": {
"address": "myGraylogInstance:12201",
"enable_tcp": false
}
"github_com/devopsfaith/krakend-gologging": {
"level": "INFO",
"prefix": "[KRAKEND]",
"syslog": false,
"stdout": true
}
}
5. Logstash
如果要通过stdout使用Logstash标准进行日志记录,则必须在extra_config部分的krakend.json的根级别中添加krakend-logstash集成。还需要启用gologging
例如:
"extra_config": {
"github_com/devopsfaith/krakend-logstash": {
"enabled": true
}
"github_com/devopsfaith/krakend-gologging": {
"level": "INFO",
"prefix": "[KRAKEND]",
"syslog": false,
"stdout": true,
"format": "logstash"
}
}
6. 将日志,指标和跟踪导出到多个服务提供者
Opencensus导出器是一个组件,可让您将数据导出到开源和私有的多个提供程序。
当您想在Opencensus的其中一个受支持的导出器中查看数据时,您会感兴趣。例如,您可能想将指标发送给Prometheus。这就像在您的krakend.json文件的根目录中添加此代码段一样简单:
"extra_config": {
"github_com/devopsfaith/krakend-opencensus": {
"exporters": {
"prometheus": {
"port": 9091
"namespace": "krakend"
}
}
}
}
配置
尽管可以在同一配置中添加多个导出器,但Opencensus仅需要一个导出器即可工作。每个导出器都有自己的配置,这在自己的部分中进行了描述。
默认情况下,所有导出器都对每秒接收到的请求进行100%采样,但是可以通过指定更多配置来更改此设置:
"github_com/devopsfaith/krakend-opencensus": {
"sample_rate": 100,
"reporting_period": 1,
"enabled_layers": {
"backend": true,
"router": true
},
"exporters": {
"prometheus": {
"port": 9091
}
}
}
-
sample_rate是抽样请求的百分比。值100表示所有请求都已导出(100%)。如果您正在处理大量流量,则可能只需要采样一部分正在进行的操作。 -
reporting_period是两次报告之间经过的秒数 -
exporters是您要使用的所有导出器的键值。有关基础密钥,请参见每个导出器配置。 -
enabled_layers让您指定要导出的数据。默认情况下,所有层均启用:
- 使用
backend报告KrakenD与您的服务活动 - 使用
router报告最终用户和KrakenD之间的活动
- 使用
7. 将指标导出到Prometheus
Prometheus是一个开源系统监视和警报工具包。
Opencensus导出器允许您将数据推送到Prometheus。启用它只需要将Opencensus中间件与prometheus导出程序一起包含在配置的根级别中。指定port运行Prometheus的位置namespace(可选),然后Prometheus将开始接收数据。
"github_com/devopsfaith/krakend-opencensus": {
"exporters": {
"prometheus": {
"port": 9091,
"namespace": "krakend"
}
}
}
portPrometheus监听端口namespace设置指标所属的命名空间。可选字段。
另请参阅可以声明的Opencensus模块的其他设置。
8. 将指标和事件导出到InfluxDB
InfluxDB是一个时间序列数据库,旨在处理较高的写入和查询负载。
Opencensus导出器允许您将数据导出到InfluxDB以监视指标和事件。启用它只需要您influxdb在opencensus模块中添加导出器。
以下配置片段将数据发送到您的InfluxDB:
"github_com/devopsfaith/krakend-opencensus": {
"exporters": {
"influxdb": {
"address": "http://192.168.99.100:8086",
"db": "krakend",
"timeout": "1s"
},
}
}
address是安装InfluxDB的URL(包括端口)db是数据库名称timeout是您等待Influx响应的最长时间
另请参阅可以声明的Opencensus模块的其他设置。
9. 将日志导出到Zipkin
Zipkin是一个分布式跟踪系统。它有助于收集解决服务体系结构中的延迟问题所需的时序数据。
Opencensus导出器允许您将数据导出到Zipkin。启用它只需要您zipkin在opencensus模块中添加导出器。
以下配置片段将数据发送到您的Zipkin:
"github_com/devopsfaith/krakend-opencensus": {
"exporters": {
"zipkin": {
"collector_url": "http://192.168.99.100:9411/api/v2/spans",
"service_name": "krakend"
},
}
}
collector_url是您的Zipkin接受跨度的URL(包括端口和路径)service_name在Zipkin中注册的服务名称
另请参阅可以声明的Opencensus模块的其他设置。
10. 将日志导出到Jaeger
Jaeger是一个开源,端到端的分布式跟踪系统,使您可以监视复杂的分布式系统中的事务并进行故障排除。
Opencensus导出器允许您将数据导出到Jaeger。启用它只需要您jaeger在opencensus模块中添加导出器。
以下配置片段将数据发送到Jaeger:
"github_com/devopsfaith/krakend-opencensus": {
"exporters": {
"jaeger": {
"endpoint": "http://192.168.99.100:14268",
"serviceName":"krakend"
},
}
}
endpoint是您的Jaeger所在的URL(包括端口)serviceName在Jaeger中注册的服务名称
另请参阅可以声明的Opencensus模块的其他设置。
11. 将日志导出到AWS X-Ray
AWS X-Ray是Amazon提供的一项服务,当请求在您的应用程序中传播时,它提供端到端视图,并显示应用程序的基础组件的地图。
Opencensus导出器允许您将数据导出到AWS X-Ray。启用它只需要您xray在opencensus模块中添加导出器。
以下配置片段将数据发送到您的X-Ray:
"github_com/devopsfaith/krakend-opencensus": {
"exporters": {
"xray": {
"version": "latest",
"region": "eu-west-1",
"use_env": false,
"access_key_id": "myaccesskey",
"secret_access_key": "mysecretkey"
},
}
}
version:要使用的AWS X-Ray服务的版本。region:AWS地理区域。use_env:从环境变量获取trueAWS凭证(access_key_id和secret_access_key)时。那就不要指定它们。access_key_id:您提供的访问密钥ID。use_env未设置或设置为时需要false。secret_access_key:您提供的亚马逊秘密访问密钥。use_env未设置或设置为时需要false。
另请参阅可以声明的Opencensus模块的其他设置。
12. 将指标,日志和事件导出到Google Stackdriver
Google Stackdriver汇总了来自基础架构的指标,日志和事件,为开发人员和操作员提供了丰富的可观察信号集,可加快根本原因分析并缩短平均解决时间(MTTR)。
Opencensus导出器允许您将数据导出到Google Stackdriver。启用它只需要您stackdriver在opencensus模块中添加导出器。
以下配置片段将数据发送到您的X-Ray:
"github_com/devopsfaith/krakend-opencensus": {
"exporters": {
"stackdriver": {
"project_id": "my-krakend-project",
"metrics_prefix": "krakend",
"default_labels": {
"env": "production"
}
}
}
}
project_id:您的Google Cloud项目的标识符。metrics_prefix:可以添加到所有指标中以更好地组织的前缀。default_labels:在此处输入将默认分配给报告指标的任何标签,以便以后可以在Stack Driver上进行过滤。在示例中,我们env使用值设置了标签production。
另请参阅可以声明的Opencensus模块的其他设置。
12. 导出到logger
Opencensus可以将数据作为另一个导出器导出到系统记录器。
启用它只需要您logger在opencensus模块中添加导出器。
以下配置片段可启用记录器:
"github_com/devopsfaith/krakend-opencensus": {
"exporters": {
"logger": {
"stats": true,
"spans": true
}
}
}
stats:是否记录统计信息spans:是否记录跨度
另请参阅可以声明的Opencensus模块的其他设置。
13. 集群
1. 高可用性集群
KrakenD群集由同时运行并协同工作的多个KrakenD实例组成,以提供更高的可靠性,更高的吞吐量,可伸缩性和故障转移。
KrakenD群集运行与您今天使用的相同KrakenD开源软件来启动单个实例。因此,无需许可证即可操作大型企业级API网关。
KrakenD集群的好处
拥有KrakenD集群可立即带来以下好处:
- 更高的吞吐量和容量:拥有更多KrakenD节点可以扩展API可以处理的请求数量。
- 即插即用节点:添加更多节点不需要任何协调或过程,在旅途中旋转更多服务器而不会中断服务。
- 无限的可扩展性和零协调:与其他具有共享状态(和集中式协调)的网关不同,每个KrakenD节点都是无状态的。期望分布式,自治和独立的节点之间不会进行通信或协调,从而为您提供无限的可伸缩性。
- 高可用性和故障转移:如果服务器因任何原因死亡或实例发生故障,群集中的其余成员将继续提供服务,而不会影响全局可用性。
- 监视:所有KrakenD节点分别向InfluxDB,Prometheus或您选择的任何其他可用集成报告。您的指标收集系统将具有所有节点的汇总指标。
- 没有单点故障:完全分布式的群集,没有任何可以关闭网关的外部依赖项(例如,数据库故障)
- 易于配置和维护:仅需使用相同配置文件副本来旋转服务器的集群,就不可能拥有更简单的解决方案。
2. 设置集群
硬件随时可能发生故障,而网关是至关重要的部分,足以保证服务的冗余性。拥有运行该服务的计算机集群可确保高可用性。
KrakenD节点是无状态的,它们不将数据或应用程序状态存储到持久性存储中。而是,配置文件中存在任何配置数据和应用程序状态。由于节点不容纳任何东西,因此它们随时都可以消耗和更换。
运行集群
运行机器集群是一个简单的过程,仅需要两个条件:
- 在机器前安装平衡器(例如,ELB,Haproxy)
- 运行两个或多个KrakenD服务
如果您在云中,则可以使用ELB或类似工具进行工作。本地用户可以使用HAProxy。安装好负载均衡器后,注册所有KrakenD实例,以便它们开始接收流量。
当KrakenD的所有所需节点都运行时,每个实例都会遵循其配置,并将跟踪和指标报告给您选择的服务。
有关部署KrakenD的最佳实践,请参阅部署KrakenD
14. 部署最佳实践
设置KrakenD实例集群是一个简单的过程,但是这里有一些建议可以帮助您入门。
使用HTTP2
在平衡器和KrakenD API网关之间启用HTTP2,以获得最佳性能。
SSL协议
在负载均衡器中添加SSL证书,并在负载均衡器和KrakenD之间使用内部证书。
启用指标和日志记录
确保您对正在发生的事情具有可见性。选择您可以发送指标并启用它们的任何系统。至少启用一个WARNING级别的日志记录。
启动命令
将输出重定向到/dev/null。使用运行服务
krakend run -c krakend.json >/dev/null 2>&1
命名配置
name在配置文件中添加包含有用信息的密钥,以便您可以确定集群正在运行哪个特定版本。例如:
{
"version": 2,
"name": "Production Cluster rev-db6a182"
}
无论您在其中写入什么类型的信息,name都可以想象得到。您写入的任何值都可以在度量标准中进行检查。
15. 开发工具
使用KrakenD进行开发时,有一些资源可以使您的生活更轻松。这些工具只能在开发中使用,绝不能在生产中使用
热加载配置
使用Reflex的Docker镜像监视配置目录并在配置更改时重新加载KrakenD。这在您进行开发时非常方便,因为它允许您测试新的更改,而不必手动重新启动,从而使过程不再那么繁琐。
基于配置生成可视化界面
该config2dot是读取配置文件后自动创建图形的工具krakend.json。
调试活动
krakend-memviz
将请求/响应快照的DOT文件导出器添加到代理堆栈中,以进行调试和开发。请勿在生产中使用此功能,因为它会影响您的性能。
krakend-spew
记录看到的每个实体:显示整个流程传递的请求和响应。请勿在生产中使用此功能,因为它会影响您的性能。
转储存储在的文件中<pipe>_<base64_endpoint/backend_name>_<timestamp>.txt。例如:
$ ls
2,0K 25 sep 19:12 backend_L3VzZXJzL3t7Lk5pY2t9fQ==_1537895547814979000.txt
1,8K 25 sep 19:12 backend_LzIuMC91c2Vycy97ey5OaWNrfX0=_1537895547800941000.txt
92K 25 sep 19:12 client_aHR0cHM6Ly9hcGkuYml0YnVja2V0Lm9yZy8yLjAvdXNlcnMva3BhY2hh_1537895547798571000.txt
92K 25 sep 19:12 client_aHR0cHM6Ly9hcGkuYml0YnVja2V0Lm9yZy8yLjAvdXNlcnMva3BhY2hh_1537895547800824000.txt
104K 25 sep 19:12 client_aHR0cHM6Ly9hcGkuZ2l0aHViLmNvbS91c2Vycy9rcGFjaGE=_1537895547814647000.txt
1,9K 25 sep 19:12 client_basic_aHR0cHM6Ly9hcGkuYml0YnVja2V0Lm9yZy8yLjAvdXNlcnMva3BhY2hh_1537895547796264000.txt
1,9K 25 sep 19:12 client_basic_aHR0cHM6Ly9hcGkuYml0YnVja2V0Lm9yZy8yLjAvdXNlcnMva3BhY2hh_1537895547798755000.txt
2,7K 25 sep 19:12 client_basic_aHR0cHM6Ly9hcGkuZ2l0aHViLmNvbS91c2Vycy9rcGFjaGE=_1537895547812621000.txt
2,3K 25 sep 19:12 proxy_L25pY2svOm5pY2s=_1537895547815244000.txt
66K 25 sep 19:12 router_L25pY2sva3BhY2hh_1537895547816402000.txt
16. 扩展KrakenD
KrakenD作方式以及原理

在开始研究KrakenD框架代码之前,花几分钟时间了解系统的主要部分,其工作方式以及其背后的原理。
KrakenD规则
让我们从编写KrakenD的规则开始,因为它们回答了架构设计问题:
- 反应是关键
- 反应性是关键(是的,这非常重要)
- 快速失败比缓慢失败更好(多说一次!)
- 越简单越好
- 一切都是可插拔的
- 每个请求必须在其请求范围的上下文中进行处理
KrakenD内部状态
当您启动KrakenD时,系统会经历两个不同的内部状态:building和working。让我们看看在每种状态下会发生什么。
building
building状态管理服务启动并在系统开始接收流量之前对其进行准备。在building状态期间,发生三件事:
- 解析配置以修复系统行为
- 中间件的准备
- 管道施工
A pipe是接收请求消息,对其进行处理并生成响应消息和错误的功能。KrakenD路由器将管道绑定到所选的传输层(例如HTTP,gRPC)。
当构建状态完成时,由于所有映射都是直接在内存中进行的,因此KrakenD服务不需要为关联的处理程序函数计算任何路由或查找。
working
工作状态是系统准备就绪并可以处理请求时。当它们到达时,路由器已经具有请求与处理程序功能的映射,并触发了管道执行。代理是管道的步骤,用于在其余过程中进行操作,汇总和其他数据处理。
由于处理程序功能已在上一步中,因此KrakenD不会根据端点数量或用户请求的URI的基数来影响性能。
重要的packages
KrakenD框架由一组软件包组成,这些软件包被设计为构建块,用于在暴露的端点与后端所服务的一个或多个API资源之间创建管道和处理器。

最重要的软件包是:
- 在
config包定义的服务。 - 在
router包设立暴露到客户端的端点。 - 在
proxy软件包添加了所需的中间件和组件,以进一步处理后端发送的请求和接收到的响应,并管理与这些后端的连接。
框架的其余软件包包含一些用于其他任务的帮助程序和适配器,例如编码,日志记录或服务发现。
此外,KrakenD-CE在其范围和软件包中捆绑了许多中间件和组件。这些软件包和其他软件包在我们的KrakenD Contrib存储库中列出。
config包
该config软件包包含服务描述所需的结构。
该ServiceConfig结构定义了整个服务。在使用它之前对其进行初始化,以确保所有参数均已标准化并应用了默认值。
该config软件包还为文件配置解析器和基于Viper库的解析器定义了一个接口。
router包
该router软件包包含一个接口和KrakenD路由器层的几种实现,这些层使用mux来自net/http和httprouter包装在gin框架中的路由器。
路由器层负责设置HTTP(S)服务,绑定在ServiceConfig结构上定义的端点,并将HTTP请求转换为代理请求,然后再将任务委派给内部层(代理)。内部代理层返回代理响应后,路由器层会将其转换为适当的HTTP响应并将其发送给用户。
该层可以轻松扩展为使用您选择的任何HTTP路由器,框架或中间件。路线图中将添加用于其他协议(Thrift,gRPC,AMQP,NATS等)的传输层适配器。一如既往,欢迎PR!
proxy包
该proxy软件包是大多数KrakenD组件和功能所在的位置。它定义了两个重要的接口,这些接口设计为可堆叠的:
- 代理是将给定上下文和请求转换为响应的功能。
- 中间件是一种函数,它接受一个或多个代理并返回一个包装它们的代理。
该层将从外层(路由器)收到的请求转换为对后端服务的单个或多个请求,处理响应并返回单个响应。
中间件会生成自定义代理,这些自定义代理将根据配置中定义的工作流进行链接,直到每个可能的分支以与传输相关的代理结尾。这些生成的代理中的每个代理都可以转换输入,甚至克隆输入几次,然后将其传递给链中的下一个元素。最后,他们还可以修改接收到的响应或将各种功能添加到生成的管道的响应。
KrakenD框架提供了代理堆栈工厂的默认实现。
可用的中间件
- 在
balancing中间件使用一些策略选择后端主机查询。 - 在
concurrent中间件通过发送几个并发请求到该链的下一步骤,并返回使用超时用于消除所产生的工作负荷的第一个成功的响应性提高QoS。 - 在
logging中间件记录所接收的请求和响应。 - 在
merging中间件是一个叉和联接中间件。它旨在将请求的流程分为多个并发流程,每个流程针对一个不同的后端,并将从这些创建的管道中接收到的所有响应合并到一个流程中。像它一样,它应用超时concurrent。 - 在
http中间件完成通过更换从所定义的用户请求中提取的参数所接收的代理请求URLPattern。
可用代理
在http代理转换代理请求到HTTP一个,将其发送到使用后端API HTTPClientFactory,解码与返回的HTTP响应Decoder与一个,操纵响应数据EntityFormatter,并返回它给调用者。
proxy包中的其他组件
代理程序包还定义了EntityFormatter,该块负责启用强大而快速的响应操作。
编写自定义插件

KrakenD的模块化设计使您可以通过添加自定义代码来扩展其功能。作为工程师,总是很想开始编写代码,但是大多数情况下不需要编写任何代码。现有的模块,中间件和插件几乎可以满足每个人的需求。
重要的是,如果您要进行复杂的业务逻辑检查和转换,除了核心功能之外,还可以为此设计特定的脚本,而无需编译Go代码。例如el表达式,Martian转换或Lua脚本。 让我们开始构建自定义代码!
让我们开始构建自定义代码!
从哪里开始定制
插件一词出现在Internet上的许多地方,但是当我们谈论插件时,我们指的是Go plugins。
middleware != plugin
KrakenD API网关是一个框架以及许多其他片段和存储库的组合,它们可以在一个最终的二进制文件中进行编译。我们将这些部分称为中间件,组件,模块或程序包__(ツ)_ /。
插件是一个软链接库,因此是一个单独的.so文件,与KrakenD一起运行时,它可以参与处理。
插件和中间件是紧密的概念,但不要混淆它们。中间件在KrakenD二进制文件中编译,而插件则在另一个二进制文件中编译。
插件允许您将自定义功能“拖放”到KrakenD中,但仍使用官方二进制文件。自定义中间件需要编译您的KrakenD版本。
扩展KrakenD的方法
您要么编写插件,要么编写中间件。这是三个选项:
- 在路由器层中编写和注入插件
- 在代理层中编写和注入插件
- 编写一个全新的中间件并使用它编译KrakenD
选择哪个取决于您要完成的工作。一个简单的方向可以是:
您要在KrakenD开始处理之前修改用户的请求吗?
- 选择路由器插件。
您是否要更改KrakenD与后端服务的交互方式?
- 选择代理插件。
您是否要更改管道的内部,添加工具,集成等?
- 编写您的自定义中间件。
请求和响应顺序
进一步阅读之前,建议阅读的内容是“ 了解全局 ”,并特别标识重要的软件包。
简而言之,请求-响应的顺序如下:
- 最终用户将一个HTTP请求发送给KrakenD。
- 路由器通过处理程序功能将HTTP请求转换为多个http或非http代理请求。
proxy管道获取所有请求的数据,进行操作,聚合……并将上下文返回给router。router将代理响应转换回HTTP响应。
编写和注入插件
下图显示了上述顺序。请注意两个蓝点:
- http处理程序(路由器)
- http客户端(代理)
17. 常见问题
当backend 返回一个200状态时,我得到一个状态201
例如:
2017/01/19 - 10:31:27 | 200 | 1.134431ms | ::1 | POST /users
说明
默认情况下,如果后端返回200或201,则网关将始终发送HTTP状态200。如果您需要其他行为,则可以注入自己的HTTPStatusHandler实现。查看此问题评论以获取更多详细信息。
我得到一个500状态时,后端返回什么,但200,201还是重定向
例如:
2017/01/19 - 10:31:37 | 500 | 1.007191ms | ::1 | POST /users_ko
说明
默认情况下,如果后端返回高于400的任何状态,则网关将始终发送HTTP状态500。如果需要其他行为,则可以注入自己的HTTPStatusHandler实现。查看此问题评论以获取更多详细信息。
我发现503日志中经常出现错误
例如:
2016/11/13 - 18:01:18 | 200 | 5.352143ms | ::1 | GET /frontpage
2016/11/13 - 18:01:18 | 503 | 5.662µs | ::1 | GET /frontpage
2016/11/13 - 18:01:18 | 503 | 5.662µs | ::1 | GET /frontpage
该maxRate设置定义在一秒钟内允许到端点或后端的最大请求数。达到此数字后,后续连接将被拒绝并503报错。此限制是可选的,通常是为了避免重击自己的后端并损害其稳定性而设置的。
说明
增加maxRate数量或禁用它(maxRate = 0)。可以为所有端点全局设置此设置,也可以为每个端点单独覆盖此设置。
请记住:快速失败总是比使基础结构过载并降低整个服务的质量更好。
我的回应是空的
做出回应的主要原因是:
- 连接后端时超时。如果后端在您通过
timeout变量设置的时间内没有响应,则KrakenD服务将断开连接并返回空响应。通常以毫秒为单位写入此变量。 - 无效的JSON / XML。当后端收到格式错误的对象作为响应并且无法对其进行解码时。
请参阅下面的解决方案。
解决超时问题的方法
只要有可能,就在后端中添加缓存层,扩展基础结构等,以便可以在适当的时间内回答请求。增加timeout变量是一种选择,但应始终是您的最后选择。如果您的后端无法在短时间内响应,请考虑一下,当您增加超时时间时,您真正要做的是阻止等待后端的连接。内存消耗将增加,并且您可以打开的连接数是有限的。在网关中,您的重点应该是尽快释放连接。
2000ms不建议使用上面的值。
解决无效响应的方法。
确保您的后端源返回有效的Json / Xml /…数据。尝试使用任何在线服务来检查返回内容的有效性和格式。如果您的API响应是一个集合,例如:响应位于方括号内[],则请确保Treat the response as a collection, not an object.在表单中标记该选项。
保留端点
以下名称不能用作端点名称,因为它们是保留名称:
/__debug/
/__stats/
/favicon.ico
初步翻译结束,翻译版本是V1.0.0,就这样吧